Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questo connettore può essere usato in Intelligenza in tempo reale in Microsoft Fabric. Usare le istruzioni in questo articolo con le eccezioni seguenti:
- Se necessario, creare database usando le istruzioni riportate in Creare un database KQL.
- Se necessario, creare tabelle usando le istruzioni riportate in Creare una tabella vuota.
- Ottenere URI di query o inserimento usando le istruzioni in URI di copia.
- Eseguire query in un set di query KQL.
Azure Esplora dati è un servizio di analisi dei dati rapido e completamente gestito. Offre un'analisi in tempo reale su grandi volumi di dati trasmessi da molte origini, ad esempio applicazioni, siti Web e dispositivi IoT. Con Azure Esplora dati è possibile esplorare in modo iterativo i dati e identificare modelli e anomalie per migliorare i prodotti, migliorare le esperienze dei clienti, monitorare i dispositivi e migliorare le operazioni. Consente di esplorare nuove domande e ottenere risposte in pochi minuti.
Azure Data Factory è un servizio di integrazione dei dati completamente gestito e basato sul cloud. È possibile usarlo per popolare il database Esplora dati di Azure con i dati del sistema esistente. Consente di risparmiare tempo durante la creazione di soluzioni di analisi.
Quando si caricano dati in Azure Esplora dati, Data Factory offre i vantaggi seguenti:
- Installazione semplice: ottenere una procedura guidata intuitiva e in cinque passaggi senza script necessari.
- Supporto avanzato per l'archivio dati: supporto predefinito per un set completo di archivi dati locali e basati sul cloud. Per un elenco dettagliato, vedere la tabella degli archivi dati supportati.
- Sicuro e conforme: i dati vengono trasferiti tramite HTTPS o Azure ExpressRoute. La presenza di un servizio globale garantisce che i dati non oltrepassino mai il confine geografico.
- Prestazioni elevate: la velocità di caricamento dei dati è fino a 1 gigabyte al secondo (GBps) in Azure Esplora dati. Per altre informazioni, vedere attività Copy prestazioni.
In questo articolo si usa lo strumento Copia dati di Data Factory per caricare i dati da Amazon Simple Storage Service (S3) in Azure Esplora dati. È possibile seguire un processo simile per copiare dati da altri archivi dati, ad esempio:
- Archivio BLOB di Azure
- Database SQL di Azure
- Azure SQL Data Warehouse
- Google BigQuery
- Oracolo
- File system
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
- Un cluster e un database di Esplora dati di Azure. Creare un cluster e un database.
- Origine dei dati.
Creare una data factory
Accedere al portale di Azure.
Nel riquadro sinistro selezionare Crea una risorsa>.

Nel riquadro Nuova data factory specificare i valori per i campi nella tabella seguente:
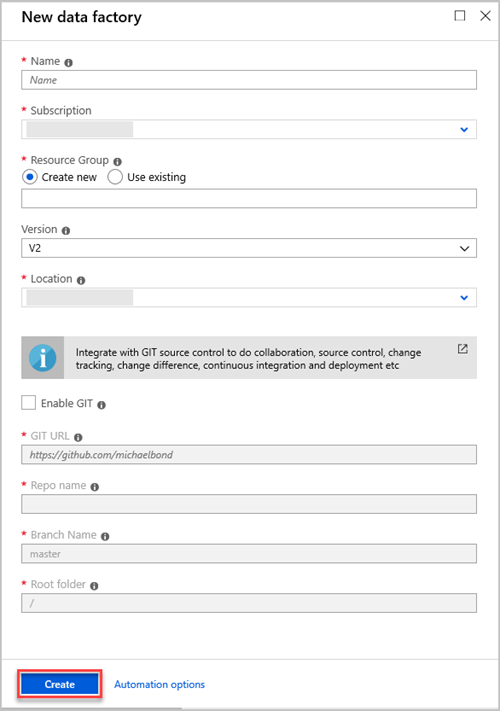
Impostazione Valore da immettere Nome Nella casella immettere un nome univoco globale per la data factory. Se viene visualizzato un errore, il nome della data factory "LoadADXDemo" non è disponibile, immettere un nome diverso per la data factory. Per le regole sulla denominazione degli artefatti di Data Factory, vedere Regole di denominazione di Data Factory. Abbonamento Nell'elenco a discesa selezionare la sottoscrizione di Azure in cui creare la data factory. Gruppo di risorse Selezionare Crea nuovo e quindi immettere il nome di un nuovo gruppo di risorse. Se si dispone già di un gruppo di risorse, selezionare Usa esistente. Versione Nell'elenco a discesa selezionare V2. Ubicazione Nell'elenco a discesa, seleziona la posizione per la data factory. Nell'elenco vengono visualizzati solo i percorsi supportati. Gli archivi dati usati dalla data factory possono esistere in altre posizioni o aree. Seleziona Crea.
Per monitorare il processo di creazione, selezionare Notifiche sulla barra degli strumenti. Dopo aver creato la data factory, selezionarla.
Viene visualizzato il riquadro Data Factory .
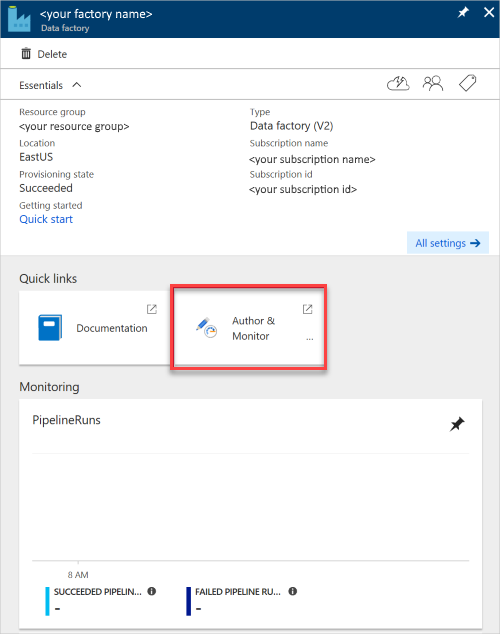
Per aprire l'applicazione in un riquadro separato, selezionare il riquadro Autore e monitoraggio .
Caricare dati in Azure Esplora dati
È possibile caricare dati da molti tipi di archivi dati in Azure Esplora dati. Questo articolo illustra come caricare i dati da Amazon S3.
È possibile caricare i dati in uno dei modi seguenti:
- Nel riquadro sinistro dell'interfaccia utente di Azure Data Factory selezionare l'icona Autore . Questa operazione è illustrata nella sezione "Creare una data factory" di Creare una data factory usando l'interfaccia utente di Azure Data Factory.
- Nello strumento Copia dati di Azure Data Factory, come illustrato in Usare lo strumento Copia dati per copiare i dati.
Copiare dati da Amazon S3 (origine)
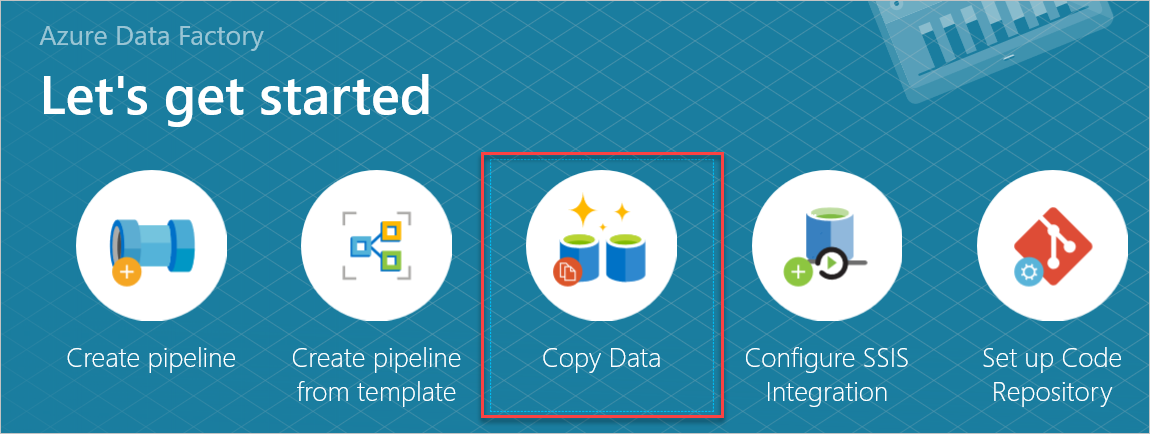
Nel riquadro Attività iniziali aprire lo strumento Copia dati selezionando Copia dati.
Nel riquadro Proprietà immettere un nome nella casella Nome attività e quindi selezionare Avanti.
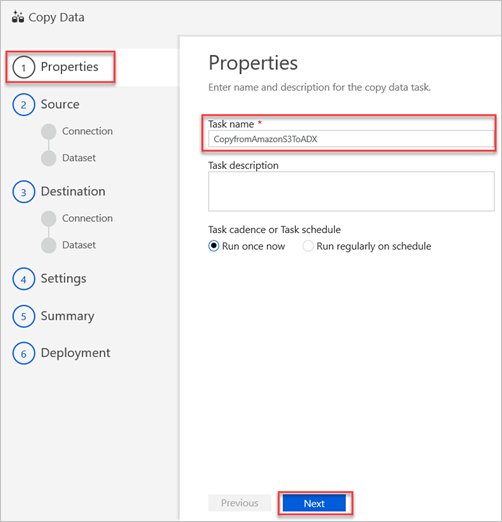
Nel riquadro Archivio dati di origine selezionare Crea nuova connessione.
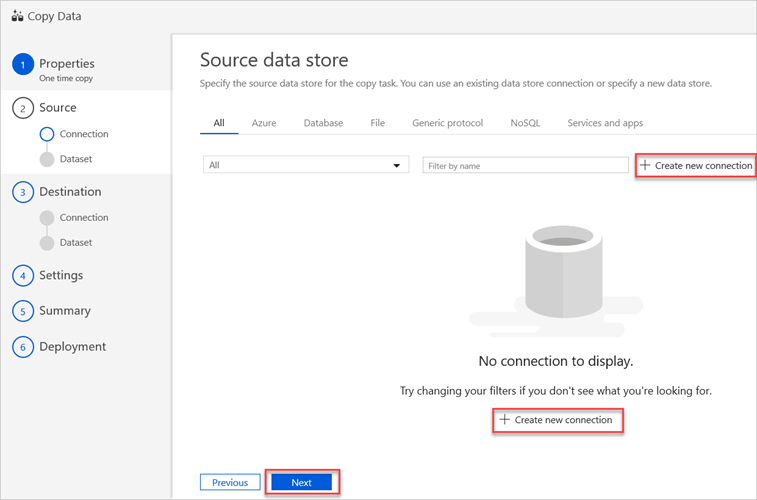
Selezionare Amazon S3 e quindi continua.
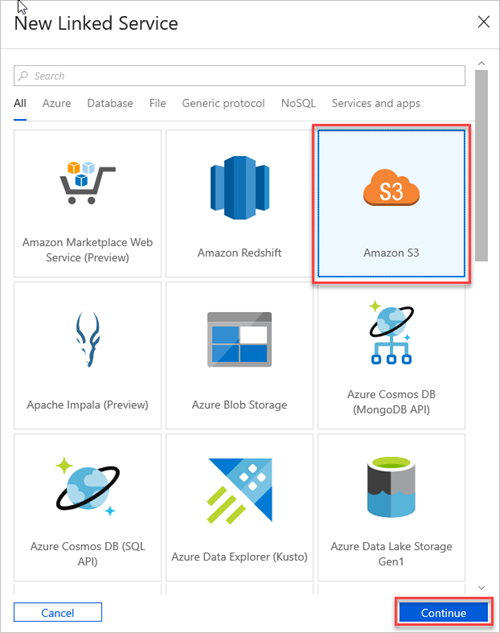
Nel riquadro Nuovo servizio collegato (Amazon S3) eseguire le operazioni seguenti:
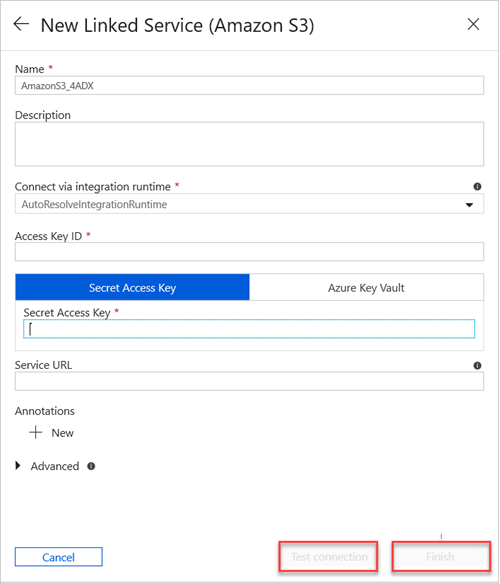
a) Nella casella Nome immettere il nome del nuovo servizio collegato.
b. Seleziona il valore nell'elenco a discesa Connetti tramite runtime di integrazione.
c. Nella casella ID chiave di accesso immettere il valore .
Nota
In Amazon S3, per individuare la chiave di accesso, selezionare il nome utente Amazon sulla barra di spostamento e quindi selezionare My Security Credentials (Credenziali di sicurezza personali).
d. Nella casella Chiave di accesso segreto immettere un valore.
e. Per testare la connessione al servizio collegato creata, selezionare Test connessione.
f. Selezionare Fine.
Nel riquadro Archivio dati di origine viene visualizzata la nuova connessione AmazonS31.
Selezionare Avanti.
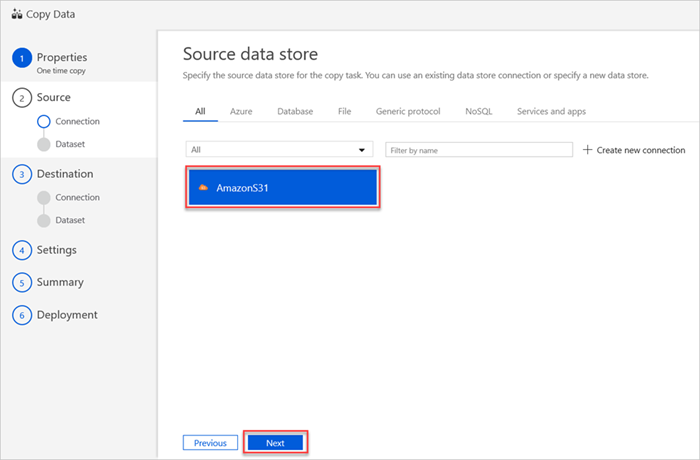
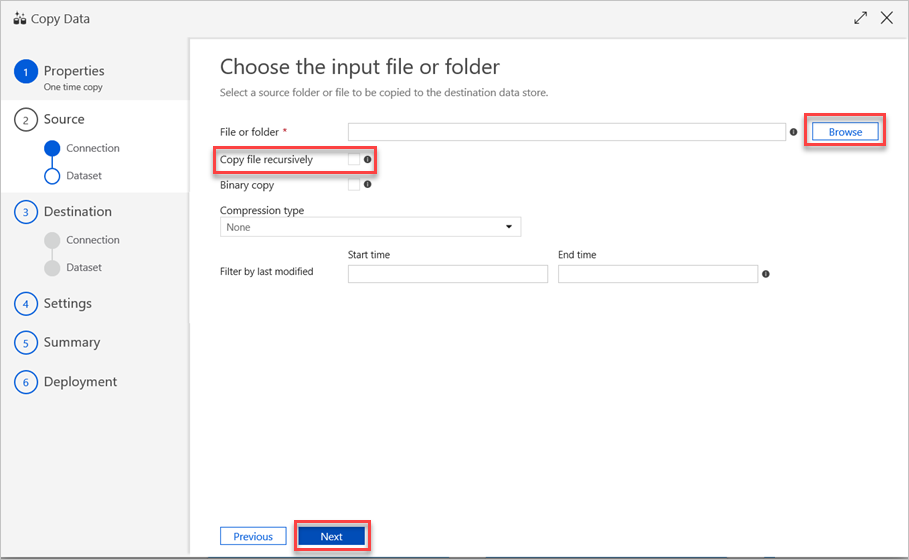
Nel riquadro Scegliere il file di input o la cartella seguire questa procedura:
a) Passare al file o alla cartella che si desidera copiare e quindi selezionarlo.
b. Selezionare il comportamento di copia desiderato. Assicurarsi che la casella di controllo Copia binaria sia deselezionata.
c. Selezionare Avanti.
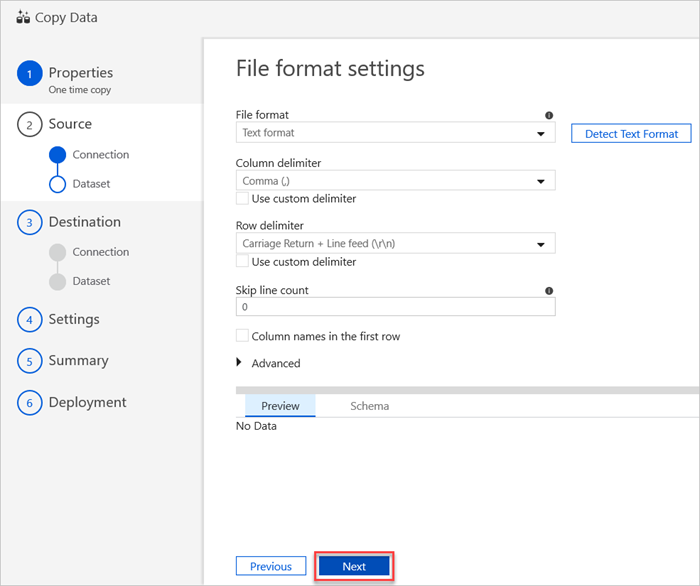
Nel riquadro Impostazioni formato file selezionare le impostazioni pertinenti per il file. e fare quindi clic su Next.
Copiare dati in Azure Esplora dati (destinazione)
Il nuovo servizio collegato Esplora dati di Azure viene creato per copiare i dati nella tabella di destinazione di Azure Esplora dati (sink) specificata in questa sezione.
Nota
Usare l'attività di comando di Azure Data Factory per eseguire i comandi di gestione di Azure Esplora dati e usare uno qualsiasi dei comandi di inserimento da query, ad esempio .set-or-replace.
Creare il servizio collegato Esplora dati di Azure
Per creare il servizio collegato Esplora dati di Azure, seguire questa procedura:
Per usare una connessione all'archivio dati esistente o specificare un nuovo archivio dati, nel riquadro Archivio dati di destinazione selezionare Crea nuova connessione.
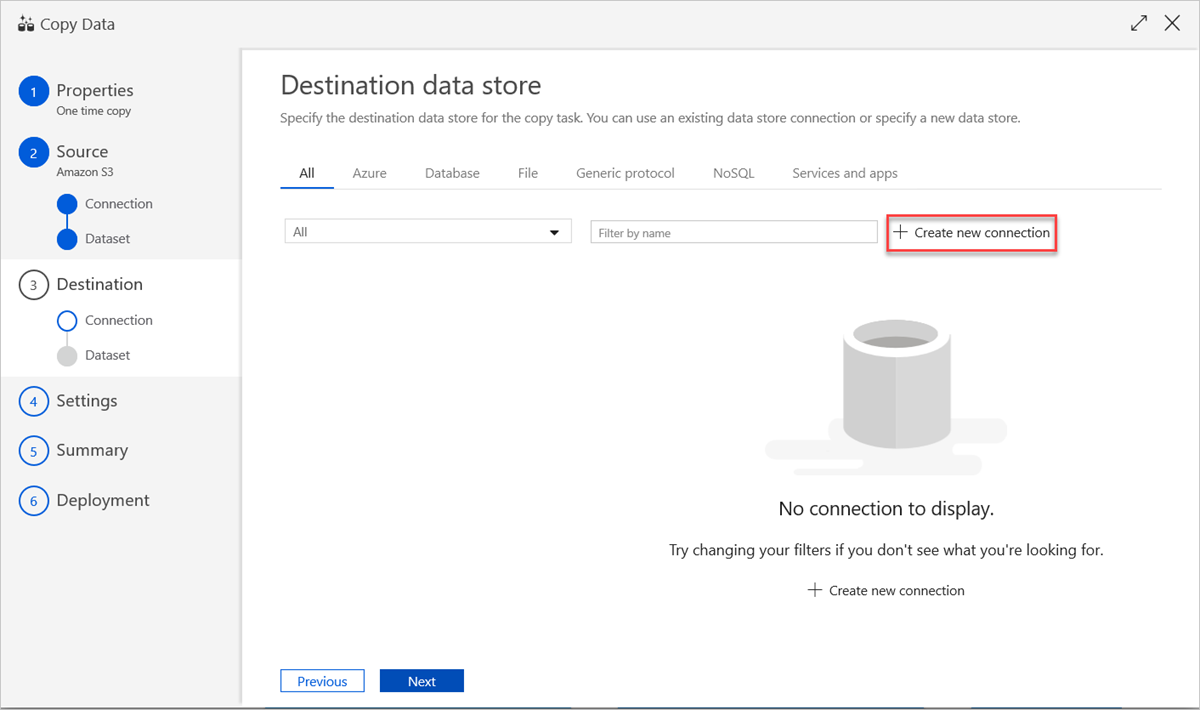
Nel riquadro Nuovo servizio collegato selezionare Azure Esplora dati e quindi selezionare Continua.

Nel riquadro Nuovo servizio collegato (Azure Esplora dati) seguire questa procedura:
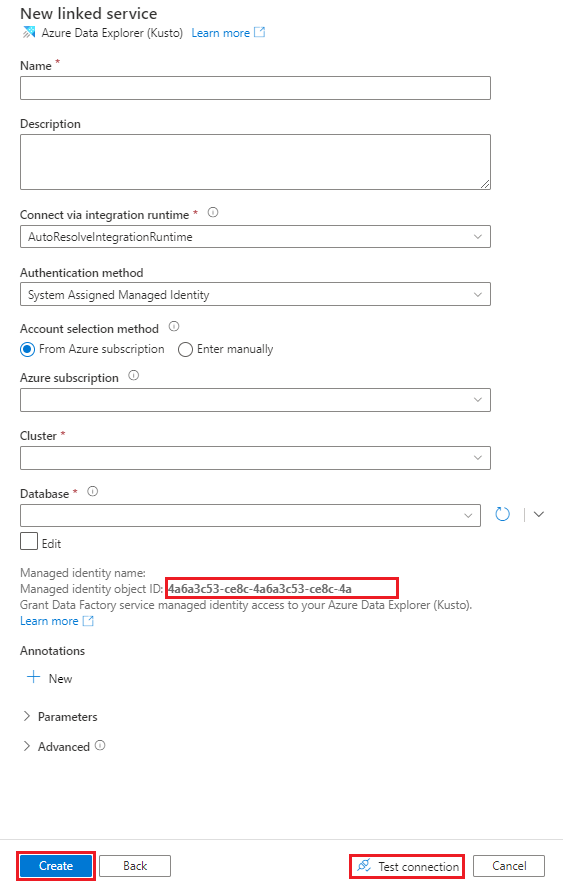
Nella casella Nome immettere un nome per il servizio collegato di Azure Esplora dati.
In Metodo di autenticazione scegliere Identità gestita assegnata dal sistema o Entità servizio.
Per eseguire l'autenticazione con un'identità gestita, concedere all'identità gestita l'accesso al database usando il nome dell'identità gestita o l'ID oggetto identità gestita.
Per eseguire l'autenticazione tramite un'entità servizio:
- Nella casella Tenant immettere il nome del tenant.
- Nella casella ID entità servizio immettere l'ID entità servizio.
- Selezionare Chiave entità servizio e quindi, nella casella Chiave entità servizio immettere il valore per la chiave.
Nota
- L'entità servizio viene usata da Azure Data Factory per accedere al servizio azure Esplora dati. Per creare un'entità servizio, passare a creare un'entità servizio Microsoft Entra.
- Per assegnare autorizzazioni a un'identità gestita o a un'entità servizio o , vedere Gestire le autorizzazioni.
- Non usare il metodo Azure Key Vault o l'identità gestita assegnata dall'utente.
In Metodo di selezione account scegliere una delle opzioni seguenti:
Selezionare Da sottoscrizione di Azure e quindi, negli elenchi a discesa, selezionare la sottoscrizione di Azure e il cluster.
Nota
- Il controllo a discesa Cluster elenca solo i cluster associati alla sottoscrizione.
- Il cluster deve avere lo SKU appropriato per ottenere prestazioni ottimali.
Selezionare Invio manualmente e quindi immettere l'endpoint.
Nell'elenco a discesa Database selezionare il nome del database. In alternativa, selezionare la casella di controllo Modifica e quindi immettere il nome del database.
Per testare la connessione al servizio collegato creata, selezionare Test connessione. Se è possibile connettersi al servizio collegato, nel riquadro viene visualizzato un segno di spunta verde e un messaggio Di connessione riuscito .
Selezionare Crea per completare la creazione del servizio collegato.
Configurare la connessione dati Esplora dati di Azure
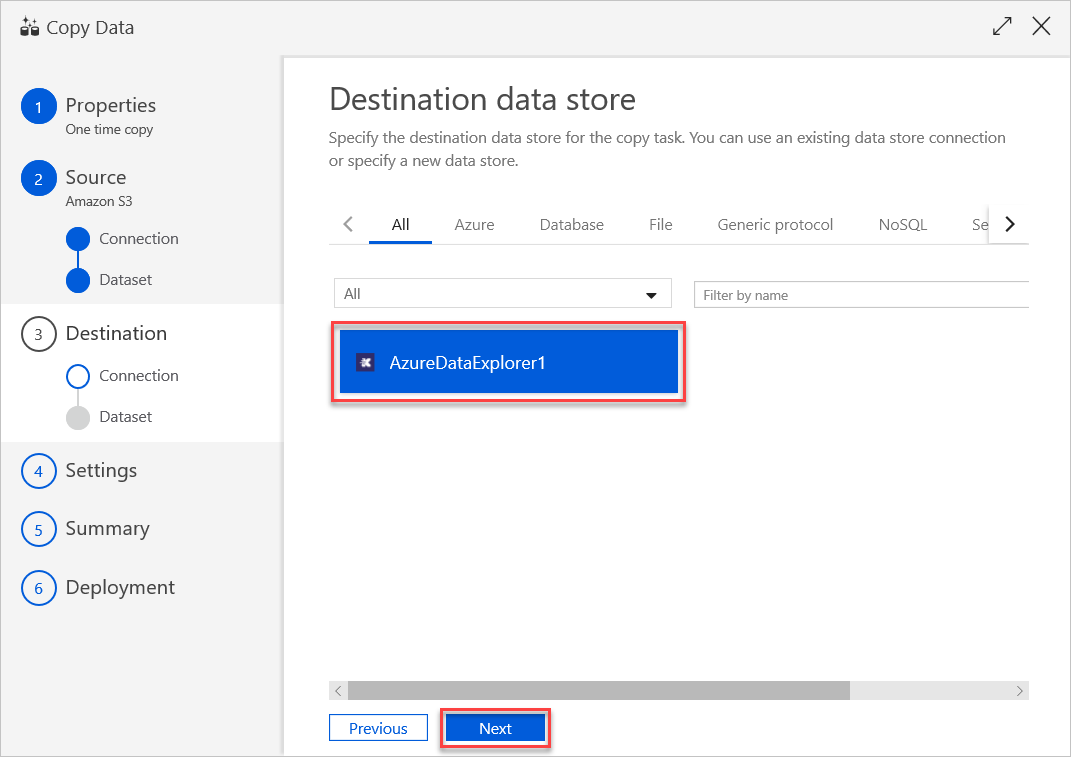
Dopo aver creato la connessione al servizio collegato, viene aperto il riquadro Archivio dati di destinazione e la connessione creata è disponibile per l'uso. Per configurare la connessione, seguire questa procedura:
Selezionare Avanti.
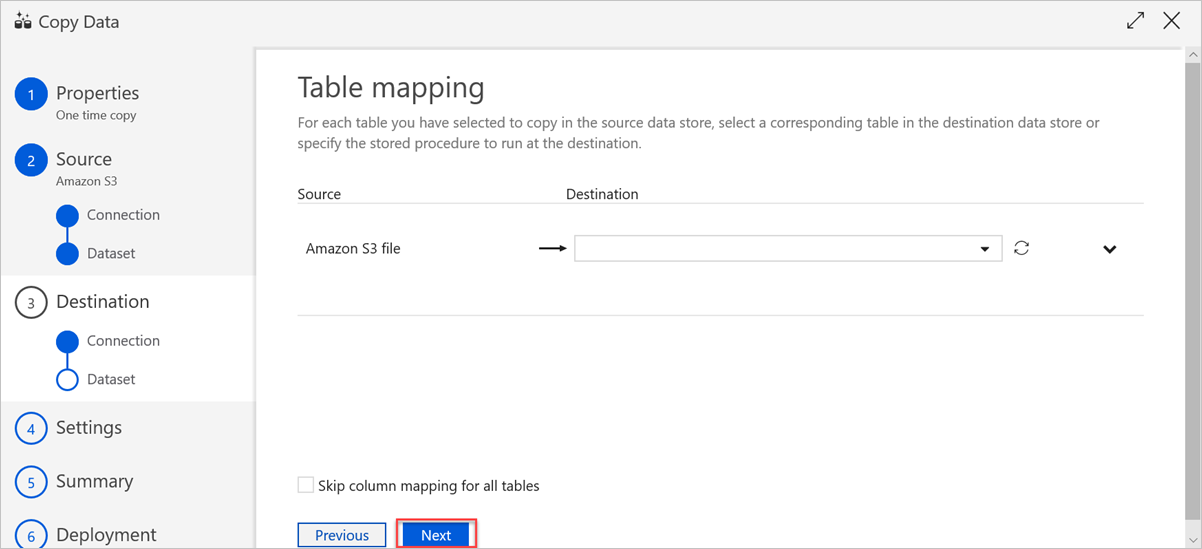
Nel riquadro Mapping tabella impostare il nome della tabella di destinazione e quindi selezionare Avanti.
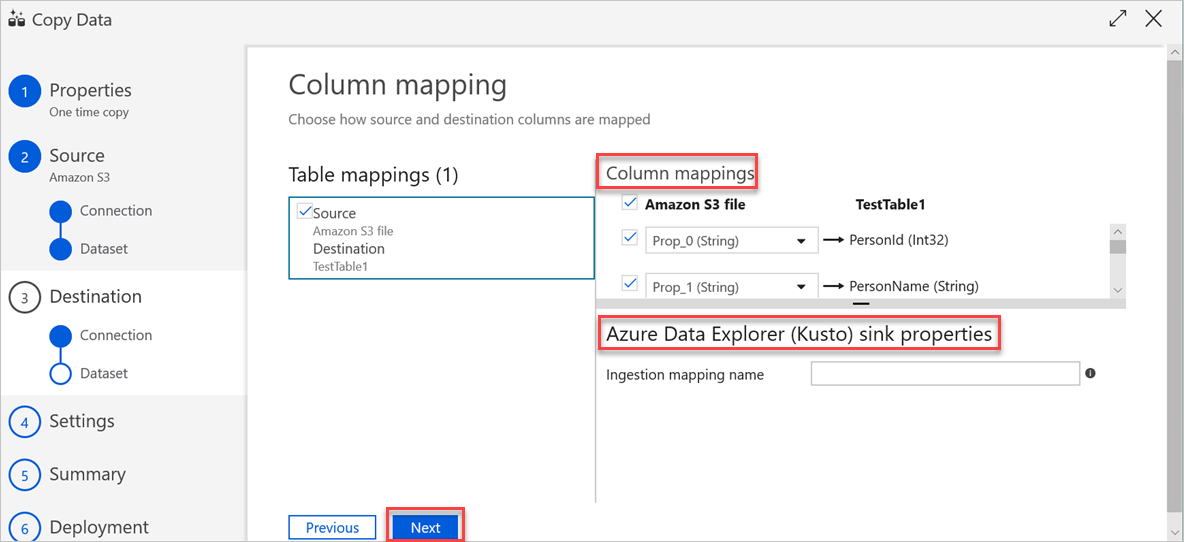
Nel riquadro Mapping colonne sono disponibili i mapping seguenti:
a) Il primo mapping viene eseguito da Azure Data Factory in base al mapping dello schema di Azure Data Factory. Effettuare le operazioni seguenti:
Impostare i mapping delle colonne per la tabella di destinazione di Azure Data Factory. Il mapping predefinito viene visualizzato dall'origine alla tabella di destinazione di Azure Data Factory.
Annullare la selezione delle colonne che non è necessario definire il mapping delle colonne.
b. Il secondo mapping si verifica quando questi dati tabulari vengono inseriti in Azure Esplora dati. Il mapping viene eseguito in base alle regole di mapping CSV. Anche se i dati di origine non sono in formato CSV, Azure Data Factory converte i dati in un formato tabulare. Di conseguenza, il mapping CSV è l'unico mapping pertinente in questa fase. Effettuare le operazioni seguenti:
(Facoltativo) In Azure Esplora dati (Kusto) sink properties (Proprietà sink Kusto) aggiungere il nome del mapping di inserimento pertinente in modo che sia possibile usare il mapping delle colonne.
Se il nome del mapping di inserimento non viene specificato, verrà usato l'ordine di mapping in base al nome definito nella sezione Mapping colonne . Se il mapping in base al nome non riesce, Azure Esplora dati tenta di inserire i dati in un ordine di posizione per colonna, ovvero esegue il mapping in base alla posizione predefinita.
Selezionare Avanti.
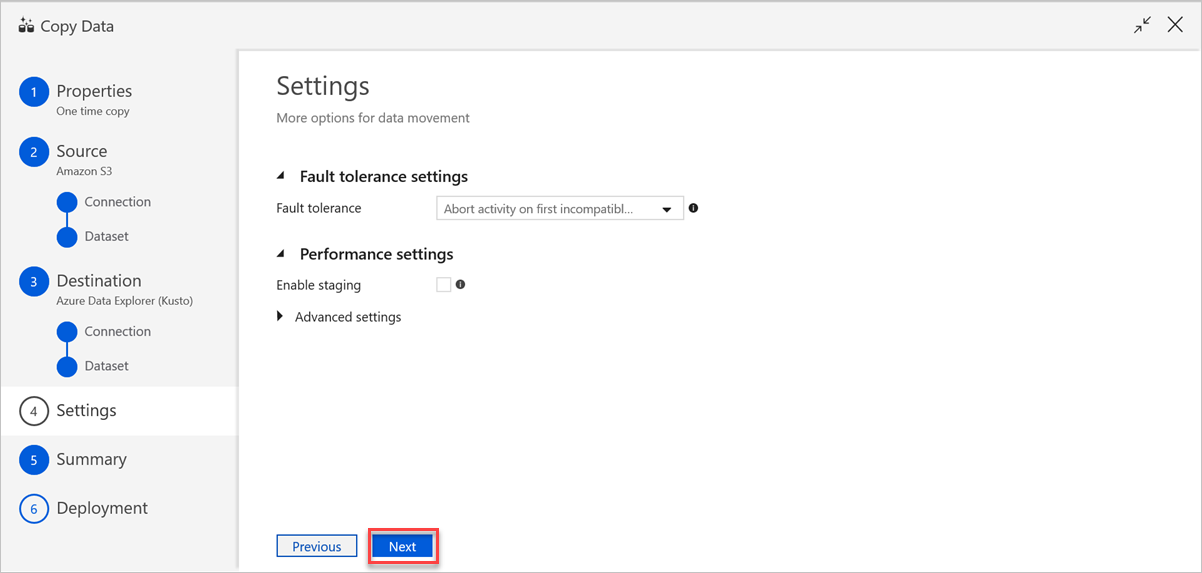
Nel riquadro Impostazioni seguire questa procedura:
a) In Impostazioni di tolleranza di errore immettere le impostazioni pertinenti.
b. In Impostazioni prestazioni, Abilita gestione temporanea non si applica e Le impostazioni avanzate includono considerazioni sul costo. Se non sono previsti requisiti specifici, lasciare invariate queste impostazioni.
c. Selezionare Avanti.
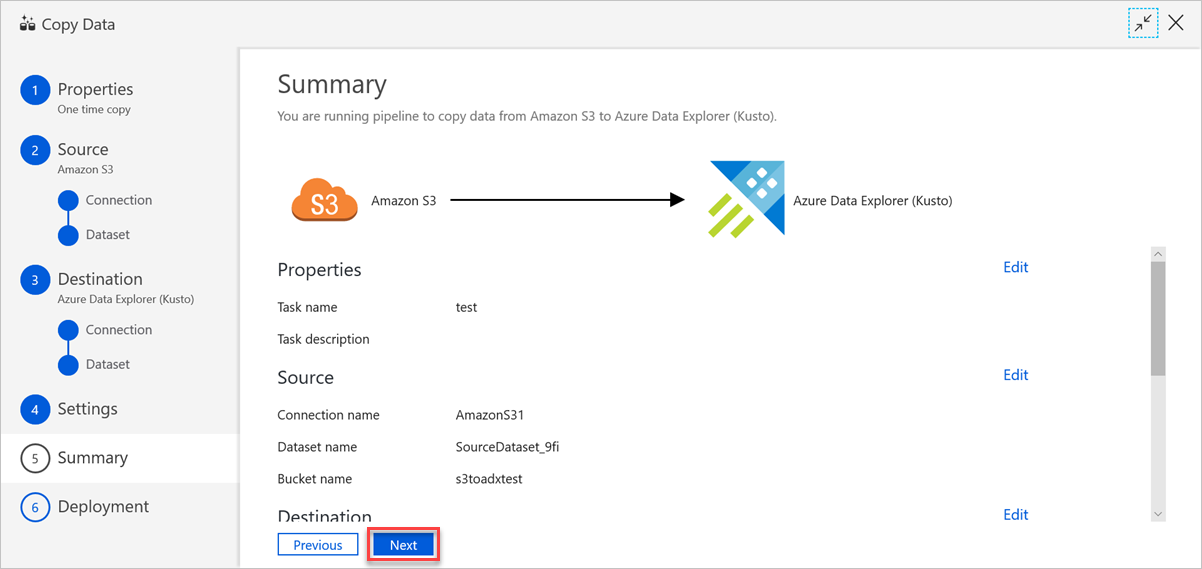
Nel riquadro Riepilogo esaminare le impostazioni e quindi selezionare Avanti.
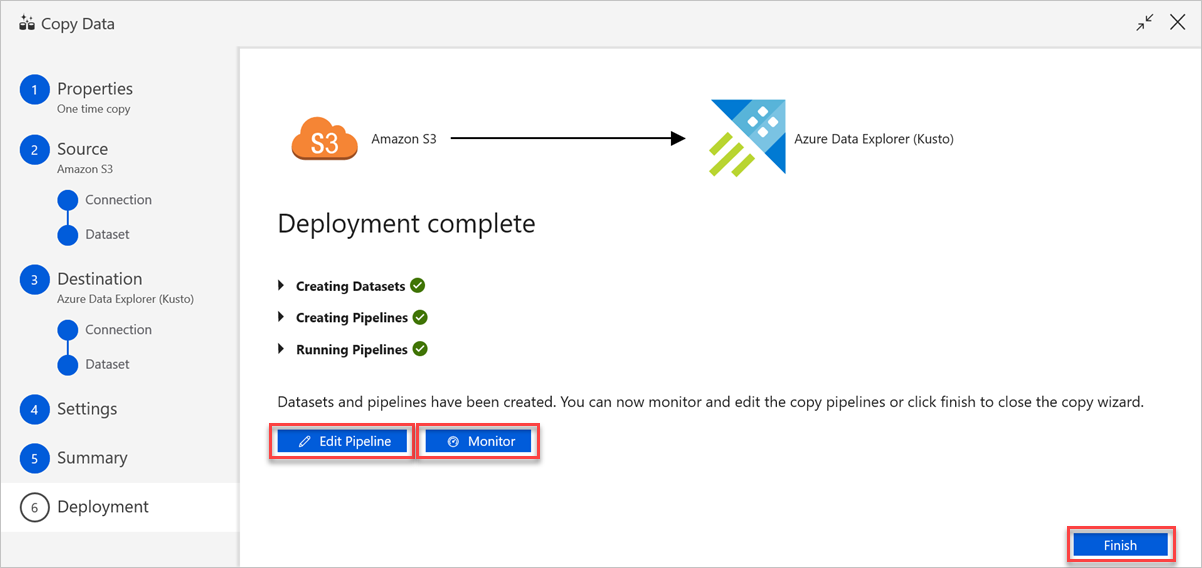
Nel riquadro Distribuzione completata eseguire le operazioni seguenti:
a) Per passare alla scheda Monitoraggio e visualizzare lo stato della pipeline, ovvero lo stato di avanzamento, gli errori e il flusso di dati, selezionare Monitoraggio.
b. Per modificare servizi collegati, set di dati e pipeline, selezionare Modifica pipeline.
c. Selezionare Fine per completare l'attività Copia dati.
Contenuto correlato
- Informazioni sul connettore azure Esplora dati per Azure Data Factory.
- Modificare servizi collegati, set di dati e pipeline nell'interfaccia utente di Data Factory.
- Eseguire query sui dati nell'interfaccia utente Web di Azure Esplora dati.