series_mv_ee_anomalies_fl()
La funzione series_mv_ee_anomalies_fl() è una funzione definita dall'utente che rileva anomalie multivariate in serie applicando un modello envelope ellittico da scikit-learn. Questo modello presuppone che l'origine dei dati multivariati sia una distribuzione normale multidimensionale. La funzione accetta un set di serie come matrici dinamiche numeriche, i nomi delle colonne delle caratteristiche e la percentuale prevista di anomalie dell'intera serie. La funzione crea una busta elliptica multidimensionale per ogni serie e contrassegna i punti che rientrano all'esterno di questa normale busta come anomalie.
Prerequisiti
- Il plug-in Python deve essere abilitato nel cluster. Questa operazione è necessaria per Python inline usato nella funzione .
- Il plug-in Python deve essere abilitato nel database. Questa operazione è necessaria per Python inline usato nella funzione .
Sintassi
T | invoke series_mv_ee_anomalies_fl(, features_cols anomaly_col [ , score_col [, anomalies_pct ]])
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Digita | Obbligatorio | Descrizione |
|---|---|---|---|
| features_cols | dynamic |
✔️ | Matrice contenente i nomi delle colonne utilizzate per il modello di rilevamento anomalie multivariato. |
| anomaly_col | string |
✔️ | Nome della colonna in cui archiviare le anomalie rilevate. |
| score_col | string |
Nome della colonna in cui archiviare i punteggi delle anomalie. | |
| anomalies_pct | real |
Numero reale nell'intervallo [0-50] che specifica la percentuale prevista di anomalie nei dati. Valore predefinito: 4%. |
Definizione di funzione
È possibile definire la funzione incorporando il codice come funzione definita da query o creandola come funzione archiviata nel database, come indicato di seguito:
Definire la funzione usando l'istruzione let seguente. Non sono necessarie autorizzazioni.
Importante
Un'istruzione let non può essere eseguita autonomamente. Deve essere seguita da un'istruzione di espressione tabulare. Per eseguire un esempio funzionante di series_mv_ee_anomalies_fl(), vedere Esempio.
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
Esempio
Nell'esempio seguente viene usato l'operatore invoke per eseguire la funzione .
Per usare una funzione definita da query, richiamarla dopo la definizione della funzione incorporata.
// Define function
let series_mv_ee_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct);
let code = ```if 1:
from sklearn.covariance import EllipticEnvelope
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
dff = df[features_cols]
ellipsoid = EllipticEnvelope(contamination=anomalies_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
ellipsoid.fit(dffe)
df.loc[i, anomaly_col] = (ellipsoid.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = ellipsoid.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores')
| extend anomalies=series_multiply(80, anomalies)
| render timechart
Output
La tabella normal_2d_with_anomalies contiene un set di 3 serie temporali. Ogni serie temporale ha una distribuzione normale bidimensionale con anomalie giornaliere aggiunte rispettivamente a mezzanotte, 8:00 e 14:00. È possibile creare questo set di dati di esempio usando una query di esempio.
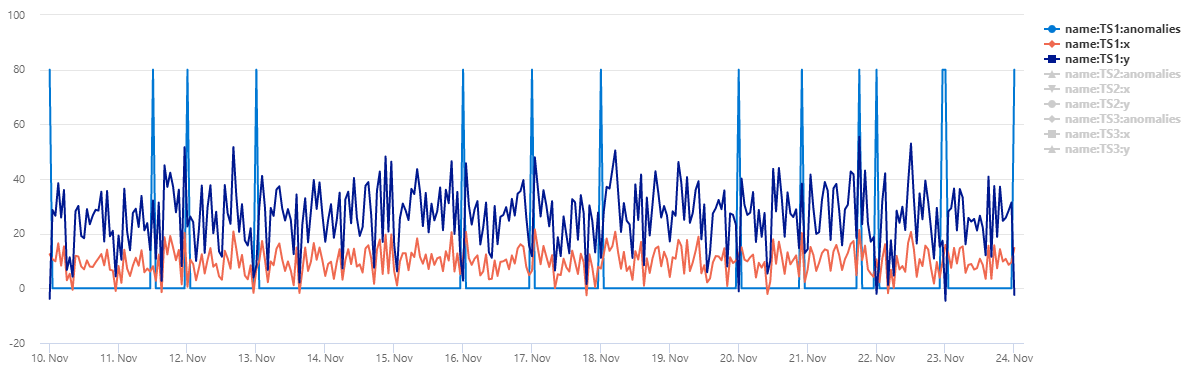
Per visualizzare i dati come grafico a dispersione, sostituire il codice di utilizzo con quanto segue:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_ee_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
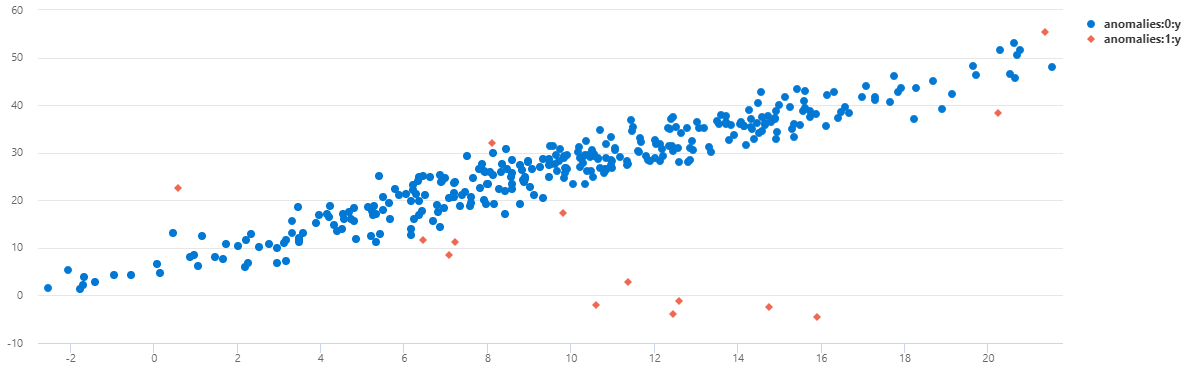
È possibile notare che in TS1 la maggior parte delle anomalie di mezzanotte è stata rilevata usando questo modello multivariato.
Creare un set di dati di esempio
.set normal_2d_with_anomalies <|
//
let window=14d;
let dt=1h;
let n=toint(window/dt);
let rand_normal_fl=(avg:real=0.0, stdv:real=1.0)
{
let x =rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand()+rand();
(x - 6)*stdv + avg
};
union
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(10, 5)
| extend y=iff(hourofday(t) == 0, 2*(10-x)+7+rand_normal_fl(0, 3), 2*x+7+rand_normal_fl(0, 3)) // anomalies every midnight
| extend name='TS1'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(15, 3)
| extend y=iff(hourofday(t) == 8, (15-x)+10+rand_normal_fl(0, 2), x-7+rand_normal_fl(0, 1)) // anomalies every 8am
| extend name='TS2'),
(range s from 0 to n step 1
| project t=startofday(now())-s*dt
| extend x=rand_normal_fl(8, 6)
| extend y=iff(hourofday(t) == 16, x+5+rand_normal_fl(0, 4), (12-x)+rand_normal_fl(0, 4)) // anomalies every 4pm
| extend name='TS3')
| summarize t=make_list(t), x=make_list(x), y=make_list(y) by name
Questa funzionalità non è supportata.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per