Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Apache Spark è un motore di analisi unificato per l'elaborazione di dati su larga scala. Esplora dati di Azure è un servizio di analisi dei dati veloce e completamente gestito per l'analisi in tempo reale di volumi elevati di dati.
Il connettore Kusto per Spark è un progetto open source che può essere eseguito in qualsiasi cluster Spark. Implementa una sorgente e un ricevitore di dati per trasferire dati tra i cluster di Azure Data Explorer e Spark. Usando Azure Esplora dati e Apache Spark, è possibile creare applicazioni veloci e scalabili destinate a scenari basati sui dati. Ad esempio, Machine Learning (ML), Extract-Transform-Load (ETL) e Log Analytics. Con il connettore, Azure Data Explorer diventa un archivio dati valido per le operazioni di origine e sink Spark standard, come la scrittura, la lettura e lo streaming di scrittura.
È possibile scrivere in Azure Data Explorer tramite l'inserimento in coda o l'inserimento in streaming. La lettura da Azure Data Explorer supporta il pruning delle colonne e il pushdown dei predicati, che filtra i dati in Azure Data Explorer, riducendo il volume dei dati trasferiti.
Nota
Per informazioni sull'uso del connettore Synapse Spark per Azure Esplora dati, vedere Connettersi ad Azure Esplora dati con Apache Spark per Azure Synapse Analytics.
Questo argomento descrive come installare e configurare il connettore Spark di Azure Esplora dati e spostare i dati tra cluster Di Azure Esplora dati e Apache Spark.
Nota
Anche se alcuni degli esempi seguenti fanno riferimento a un cluster Spark di Azure Databricks, il connettore Spark di Azure Data Explorer non ha dipendenze dirette da Databricks o da altre distribuzioni Spark.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
- Un cluster e un database di Azure Data Explorer. Creare un cluster e un database.
- Un cluster Spark
- Installare la libreria dei connettori:
- Librerie predefinite per Spark 2.4+Scala 2.11 o Spark 3+scala 2.12
- Repository Maven
- Maven 3.x installato
Suggerimento
Sono supportate anche le versioni di Spark 2.3.x, ma potrebbero essere necessarie alcune modifiche nelle dipendenze pom.xml.
Come creare il connettore Spark
A partire dalla versione 2.3.0 sono stati introdotti nuovi ID artefatti che vanno a sostituire spark-kusto-connector: kusto-spark_3.0_2.12 destinati a Spark 3.x e Scala 2.12.
Nota
Le versioni precedenti alla 2.5.1 non funzionano più per l'inserimento in una tabella esistente. Si prega di fare l’aggiornamento a una versione successiva. Questo passaggio è facoltativo. Se si usano librerie predefinite, ad esempio Maven, vedere Configurazione del cluster Spark.
Prerequisiti di compilazione
Fare riferimento a questa origine per la compilazione del connettore Spark.
Per le applicazioni Scala e Java che utilizzano le definizioni dei progetti Maven, collega l'applicazione con l'ultimo artefatto. Trova l'artefatto più recente su Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Se non si usano librerie predefinite, è necessario installare le librerie elencate nelle dipendenze, incluse le librerie Kusto Java SDK seguenti. Per trovare la versione corretta da installare, consultare il pom della versione pertinente:
Per compilare file con estensione jar ed eseguire tutti i test:
mvn clean package -DskipTestsPer compilare file con estensione jar, eseguire tutti i test e installare i file con estensione jar nel repository Maven locale:
mvn clean install -DskipTests
Per maggiori informazioni, vedere Uso del connettore.
Configurazione del cluster Spark
Nota
È consigliabile usare la versione più recente del connettore Spark Kusto quando si eseguono i passaggi seguenti.
Configurare le seguenti impostazioni del cluster Spark, in base al cluster Azure Databricks Spark 3.0.1 e Scala 2.12:
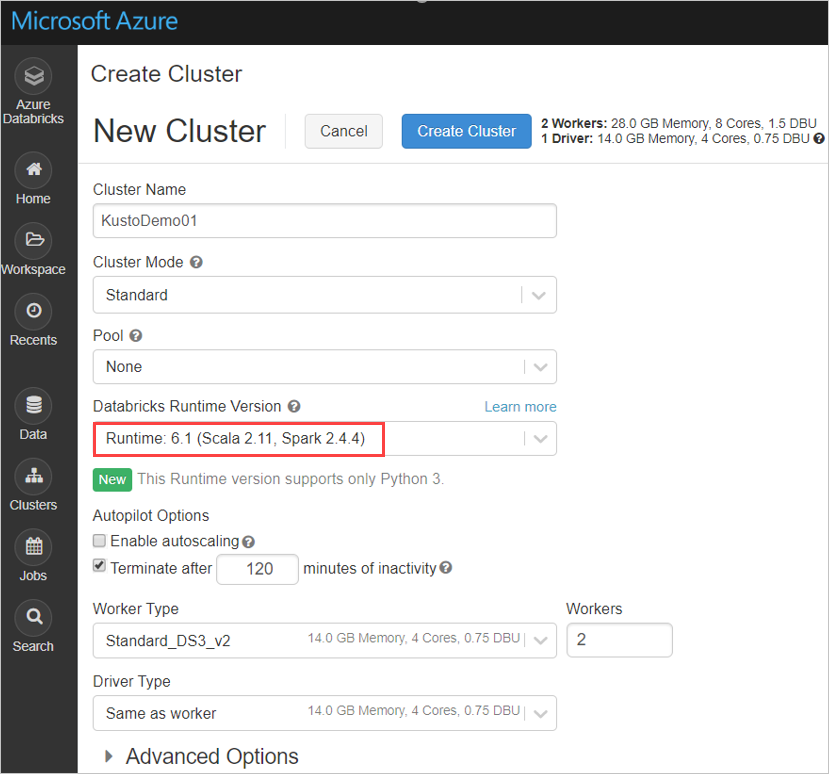
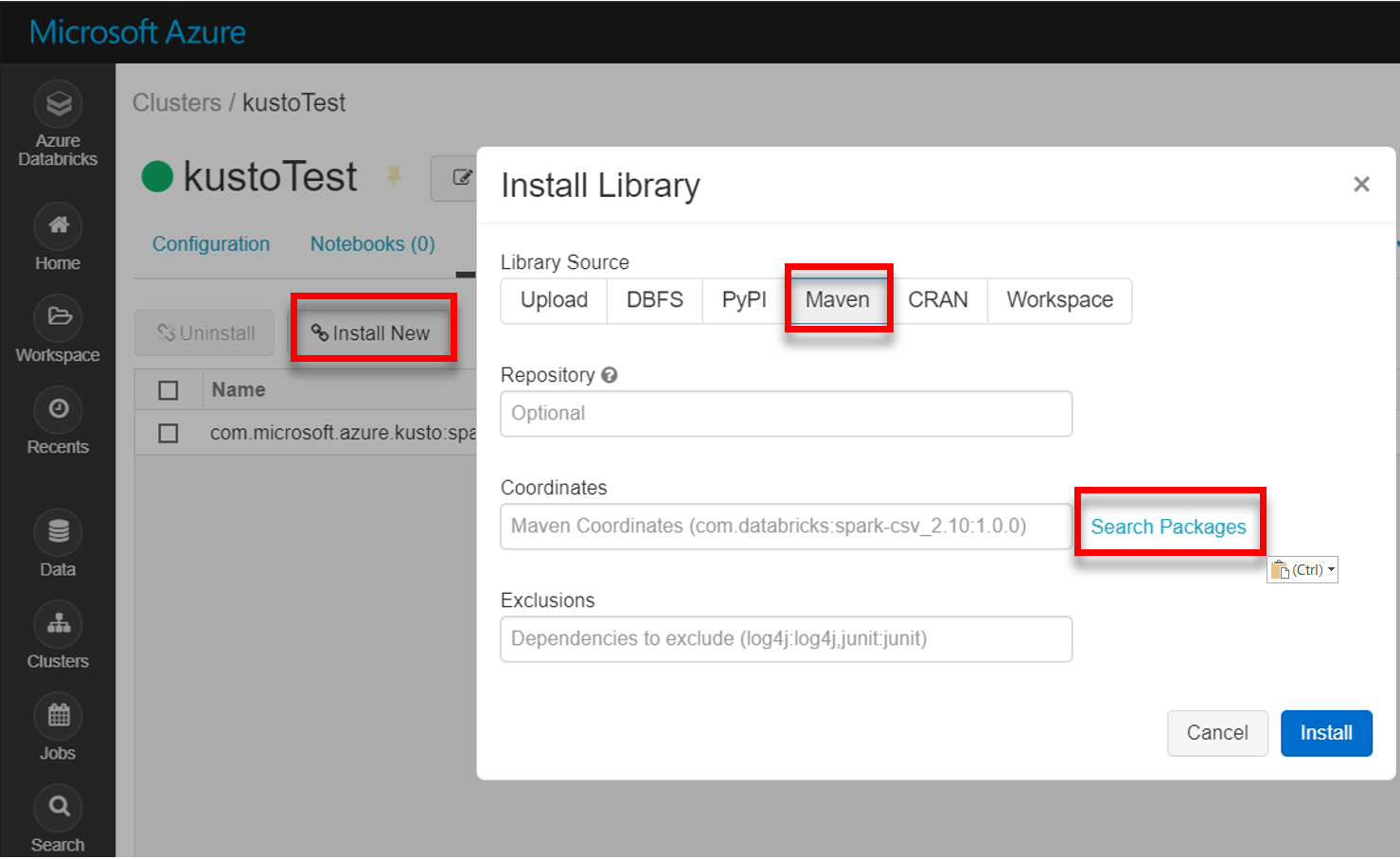
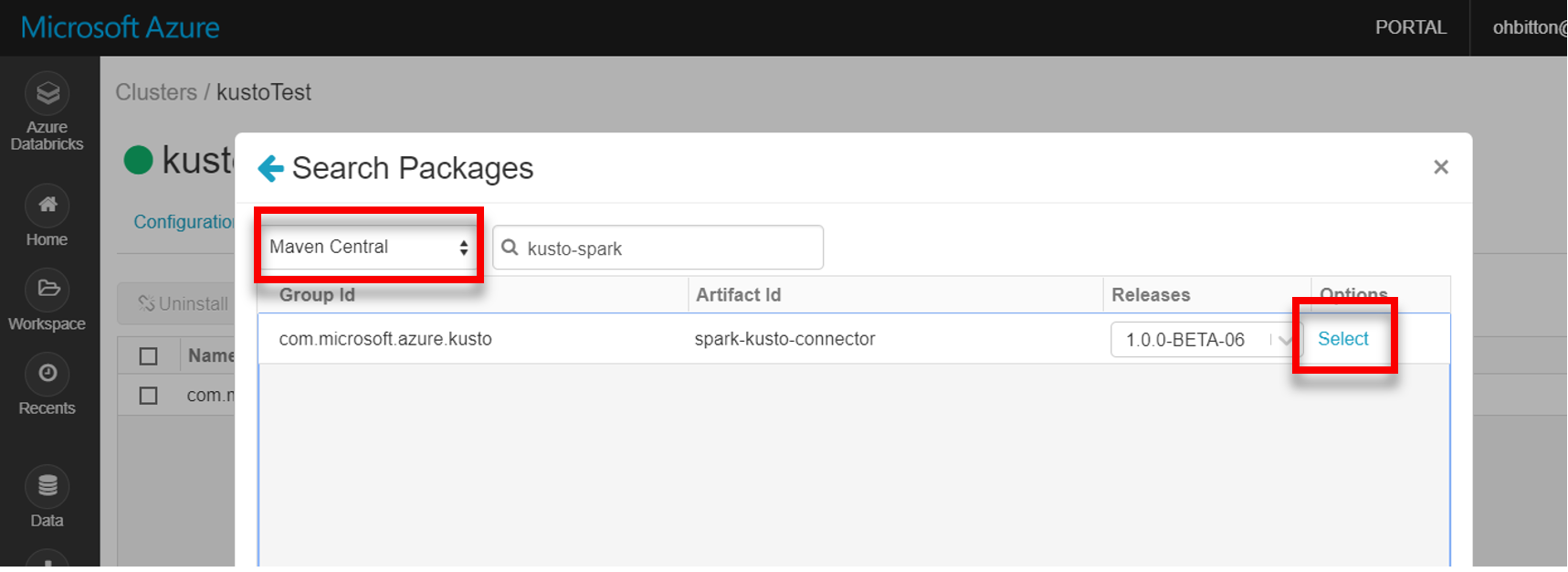
Installare la libreria spark-kusto-connector più recente da Maven:
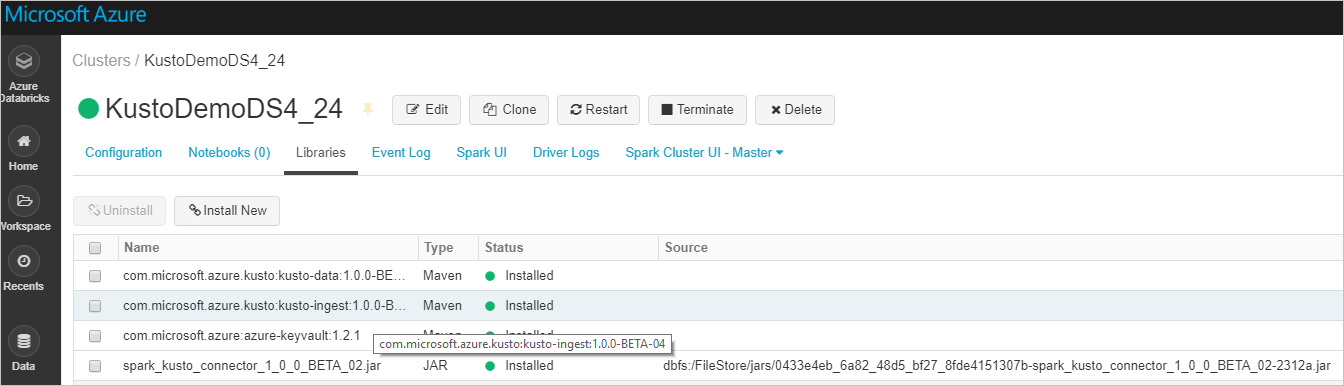
Verificare che tutte le librerie necessarie siano installate:
Per l'installazione con un file JAR, verificare che siano state installate altre dipendenze:
Autenticazione
Il connettore Kusto Spark consente di eseguire l'autenticazione con l’ID Microsoft Entra usando uno dei metodi seguenti:
- Un’Applicazione Microsoft Entra
- Un Token di accesso di Microsoft Entra
- Autenticazione del dispositivo (per scenari di non produzione)
- Un Azure Key Vault Per accedere alla risorsa Azure Key Vault, installare il pacchetto azure-keyvault e fornire le credenziali dell'applicazione.
Autenticazione dell’applicazione Microsoft Entra
L'autenticazione dell'applicazione Microsoft Entra è il metodo di autenticazione più semplice e comune ed è consigliato per il connettore Kusto Spark.
Accedere alla sottoscrizione di Azure usando l'interfaccia della riga di comando di Azure. Eseguire quindi l'autenticazione nel browser.
az loginScegli la sottoscrizione per ospitare l'account principale. Questo passaggio è necessario quando si hanno più sottoscrizioni.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCreare l'entità servizio. In questo esempio l'entità servizio viene chiamata
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Dai dati JSON restituiti copiare
appId,passwordetenantper un uso futuro.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Hai creato la tua applicazione Microsoft Entra e il principale del servizio.
Il connettore Spark usa le seguenti proprietà dell'app Entra per l'autenticazione:
| Proprietà | Stringa di opzione | Descrizione |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Identificatore dell'applicazione client di Microsoft Entra. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Autorità di autenticazione di Microsoft Entra. ID (tenant) di Microsoft Entra directory. Facoltativo - il valore predefinito è microsoft.com. Per maggiori informazioni, vedere Microsoft Entra authority. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Chiave dell'applicazione per il client Microsoft Entra. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Se possiedi già un "accessToken" creato con accesso a Kusto, questo può essere utilizzato anche dal connettore per l'autenticazione. |
Nota
Le versioni precedenti dell'API (prima della 2.0.0) hanno la seguente denominazione: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Privilegi di Kusto
Concedere i seguenti privilegi sul sistema Kusto in base all'operazione di Spark che si vuole eseguire.
| Operazione Spark | Privilegi |
|---|---|
| Lettura - Modalità singola | Lettore |
| Lettura - forzare la modalità distribuita | Lettore |
| Write - modalità in coda con l'opzione di creazione tabella CreateTableIfNotExist | Amministratore |
| Scrittura - modalità in coda con l'opzione di creazione della tabella FailIfNotExist | Ingestor |
| Scrittura - TransactionalMode | Amministratore |
Per maggiori informazioni sui ruoli principali, vedere Che cos'è il controllo degli accessi in base al ruolo?. Per la gestione dei ruoli di sicurezza, vedere Gestione dei ruoli di sicurezza.
Sink Spark: scrittura in Kusto
Impostazione dei parametri sink:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Scrivere un DataFrame Spark nel cluster Kusto in modalità batch:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()In alternativa, usare la sintassi semplificata:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Scrivere dati di streaming:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Fonte Spark: lettura in corso da Kusto
Durante la lettura di piccole quantità di dati, definire la query sui dati:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Facoltativo: se si fornisce l'archivio BLOB temporaneo (e non Kusto), i BLOB vengono creati sotto la responsabilità dell'utente chiamante. Ciò comprende il provisioning dell'archiviazione, la rotazione delle chiavi di accesso e l'eliminazione di elementi temporanei. Il modulo KustoBlobStorageUtils contiene funzioni helper per l'eliminazione di BLOB in base alle coordinate di account e contenitori e alle credenziali dell'account oppure a un URL SAS con autorizzazioni di scrittura, lettura ed elenco. Quando il RDD corrispondente non è più necessario, ogni transazione archivia gli artefatti BLOB temporanei in una directory separata. Questa directory viene registrata nei log delle informazioni sulle transazioni di lettura sul nodo Driver Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Nell'esempio precedente, non si accede al Key Vault utilizzando l'interfaccia del connettore; viene utilizzato un metodo più semplice per utilizzare i segreti di Databricks.
Leggere da Kusto.
Se fornisci l'archivio BLOB temporaneo, leggi da Kusto come segue:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Se Kusto fornisce l'archiviazione BLOB temporanea, leggi da Kusto come segue:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)