Argomenti avanzati di SAP CDC
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto ciò che riguarda lo spostamento dei dati, l'analisi in tempo reale, l'intelligence aziendale e la creazione di report. Informazioni su come avviare una nuova versione di valutazione gratuitamente!
Informazioni sugli argomenti avanzati per il connettore SAP CDC, ad esempio l'integrazione dei dati basata sui metadati, il debug e altro ancora.
Parametrizzazione di un flusso di dati di mapping di SAP CDC
Uno dei principali punti di forza delle pipeline e dei flussi di dati di mapping in Azure Data Factory e Azure Synapse Analytics è il supporto per l'integrazione dei dati basata sui metadati. Con questa funzionalità è possibile progettare una pipeline parametrizzata (o pochi) che può essere usata per gestire l'integrazione di potenzialmente centinaia o persino migliaia di origini. Il connettore SAP CDC è stato progettato con questo principio: tutte le proprietà pertinenti, indipendentemente dal fatto che sia l'oggetto di origine, la modalità di esecuzione, le colonne chiave e così via, possono essere fornite tramite parametri per ottimizzare la flessibilità e riutilizzare il potenziale di flussi di dati di mapping SAP CDC.
Per comprendere i concetti di base relativi ai flussi di dati di mapping parametrizzanti, leggere Parametrizzazione dei flussi di dati di mapping.
Nella raccolta di modelli di Azure Data Factory e Azure Synapse Analytics è disponibile una pipeline di modelli e un flusso di dati che illustra come parametrizzare l'inserimento di dati SAP CDC.
Parametrizzazione della modalità di origine ed esecuzione
I flussi di dati di mapping non richiedono necessariamente un artefatto set di dati: le trasformazioni di origine e sink offrono un tipo di origine (o tipo sink) inline. In questo caso, tutte le proprietà di origine definite in un set di dati ADF possono essere configurate nelle opzioni Origine della trasformazione di origine (o scheda Impostazioni della trasformazione sink). L'uso di un set di dati inline offre una panoramica migliore e semplifica la parametrizzazione di un flusso di dati di mapping poiché la configurazione completa dell'origine (o sink) viene mantenuta in un'unica posizione.
Per SAP CDC, le proprietà più comunemente impostate tramite i parametri sono disponibili nelle opzioni Origine schede e Ottimizza. Quando il tipo di origine è Inline, le proprietà seguenti possono essere parametrizzate nelle opzioni Di origine.
- Contesto ODP: i valori dei parametri validi sono
- ABAP_CDS per le visualizzazioni di ABAP Core Data Services
- BW per SAP BW o SAP BW/4HANA InfoProviders
- HANA per le visualizzazioni delle informazioni di SAP HANA
- SAPI per SAP DataSources/Extractors
- quando il server di replica SLT (SAP Landscape Transformation Replication Server) viene usato come origine, il nome del contesto ODP è SLT~<Queue Alias>. Il valore alias della coda è disponibile in Dati di amministrazione nella configurazione SLT nell'area di comando SLT (SAP transaction LTRC).
- ODP_SELF e RANDOM sono contesti ODP usati per la convalida tecnica e i test e in genere non sono pertinenti.
- Nome ODP: specificare il nome ODP da cui estrarre i dati.
- Modalità di esecuzione: i valori dei parametri validi sono
- fullAndIncrementalLoad per Full nella prima esecuzione, quindi incrementale, che avvia un processo di acquisizione dei dati di modifica ed estrae uno snapshot completo dei dati corrente
- fullLoad per Full in ogni esecuzione, che estrae uno snapshot di dati completo corrente senza avviare un processo di acquisizione dei dati di modifica.
- incrementalLoad per le modifiche incrementali, che avvia un processo di acquisizione dei dati di modifica senza estrarre uno snapshot completo corrente.
- Colonne chiave: le colonne chiave vengono fornite come matrice di stringhe (con virgolette doppie). Ad esempio, quando si usa SAP table VBAP (elementi dell'ordine di vendita), la definizione della chiave deve essere ["VBELN", "POSNR"] (o ["MANDT","VBELN","POSNR"] nel caso in cui il campo client venga preso in considerazione anche.
Parametrizzazione delle condizioni di filtro per il partizionamento di origine
Nella scheda Ottimizza è possibile definire uno schema di partizionamento di origine (vedere ottimizzazione delle prestazioni per carichi completi o iniziali) tramite parametri. In genere, sono necessari due passaggi:
- Definire un parametro per lo schema di partizionamento di origine a livello di pipeline.
- Inserire il parametro di partizionamento nel flusso di dati di mapping.
Formato JSON di uno schema di partizionamento
Il formato nel passaggio 1 segue lo standard JSON, costituito da una matrice di definizioni di partizione, ognuna delle quali è una matrice di singole condizioni di filtro. Queste condizioni sono oggetti JSON con una struttura allineata alle opzioni di selezione cosiddette in SAP. Infatti, il formato richiesto dal framework ODP SAP è fondamentalmente uguale ai filtri DTP dinamici in SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Ad esempio:
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
corrisponde a una clausola SQL WHERE ... WHERE "VBELN" = '0000001000'o
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
corrisponde a una clausola SQL WHERE ... WHERE "VBELN" BETWEEN '000000000' AND '0000001000'
Una definizione JSON di uno schema di partizionamento contenente due partizioni sembra così come segue
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
dove la prima partizione contiene anni fiscali (GJAHR) 2011 fino al 2015 e la seconda partizione contiene anni fiscali 2016 fino al 2020.
Nota
Azure Data Factory non esegue controlli su queste condizioni. Ad esempio, è responsabilità dell'utente assicurarsi che le condizioni di partizione non si sovrapponga.
Le condizioni di partizione possono essere più complesse, costituite da più condizioni di filtro elementari. Non esistono congiunzioni logiche che definiscono in modo esplicito come combinare più condizioni elementari all'interno di una partizione. La definizione implicita in SAP è la seguente (solo per le selezioni, ovvero "sign": "I" - per escludere):
- incluse le condizioni ("segno": "I") per lo stesso nome del campo vengono combinate con OR (mentalmente, inserire parentesi quadre intorno alla condizione risultante)
- escluse le condizioni ("segno": "E") per lo stesso nome del campo vengono combinate con OR (di nuovo, mentalmente, inserire parentesi quadre intorno alla condizione risultante)
- le condizioni risultanti dei passaggi 1 e 2 sono
- combinato con AND per l'inclusione di condizioni,
- combinato con AND NOT per escludere le condizioni.
Ad esempio, la condizione di partizione
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2020", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" }
]
corrisponde a una clausola SQL WHERE ... WHERE ("BUKRS" = '1000') E ("GJAHR" TRA '2020' E '2025') E NOT ("GJAHR" = '2023')
Nota
Assicurarsi di usare il formato interno SAP per i valori bassi e elevati, includere zero iniziali e date del calendario express come stringa di otto caratteri con il formato "AAAAMMDD".
Inserimento del parametro di partizionamento nel flusso di dati di mapping
Per inserire lo schema di partizionamento in un flusso di dati di mapping, creare un parametro del flusso di dati, ad esempio "sapPartitions"). Per passare il formato JSON a questo parametro, deve essere convertito in una stringa usando la funzione @string():
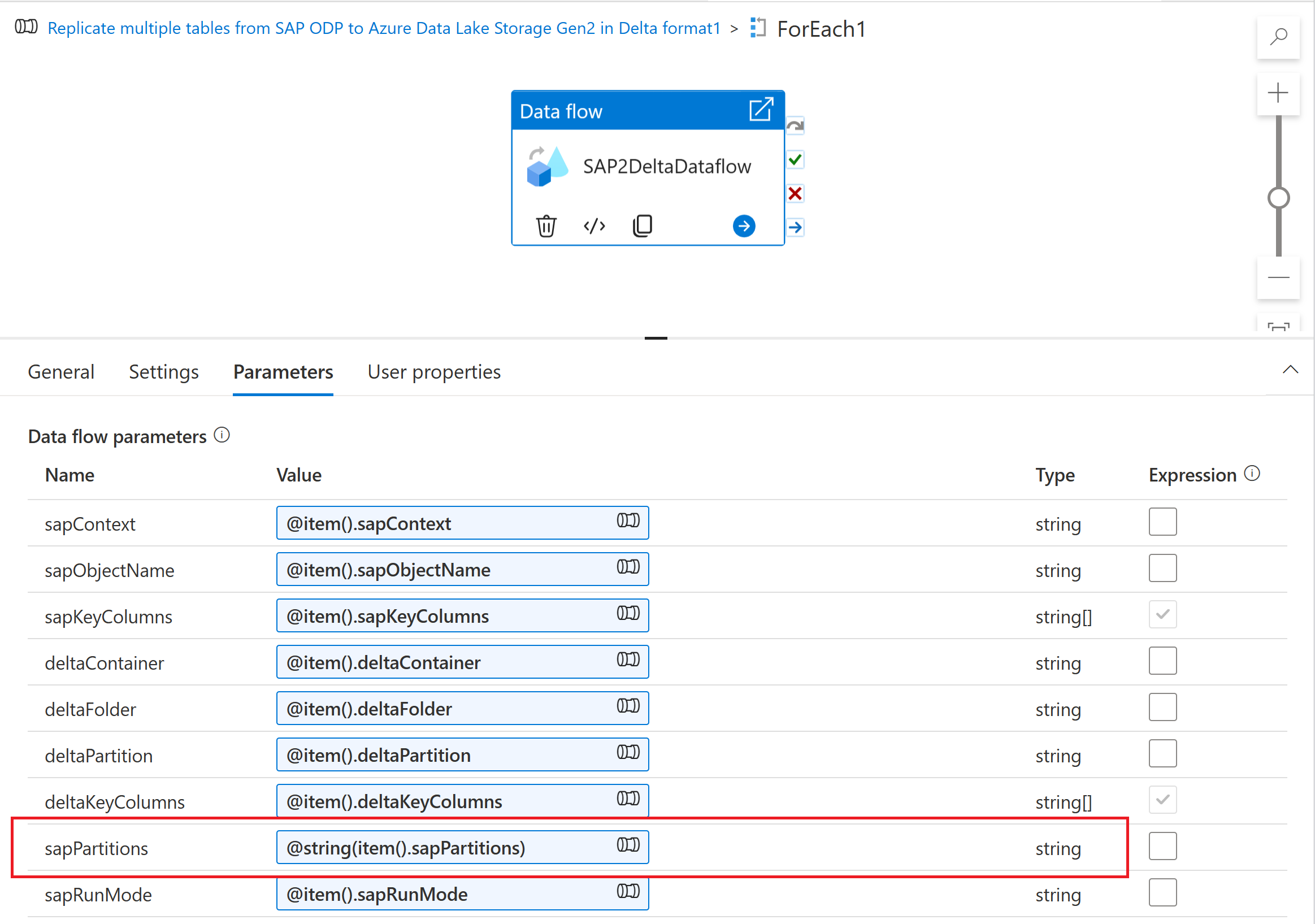
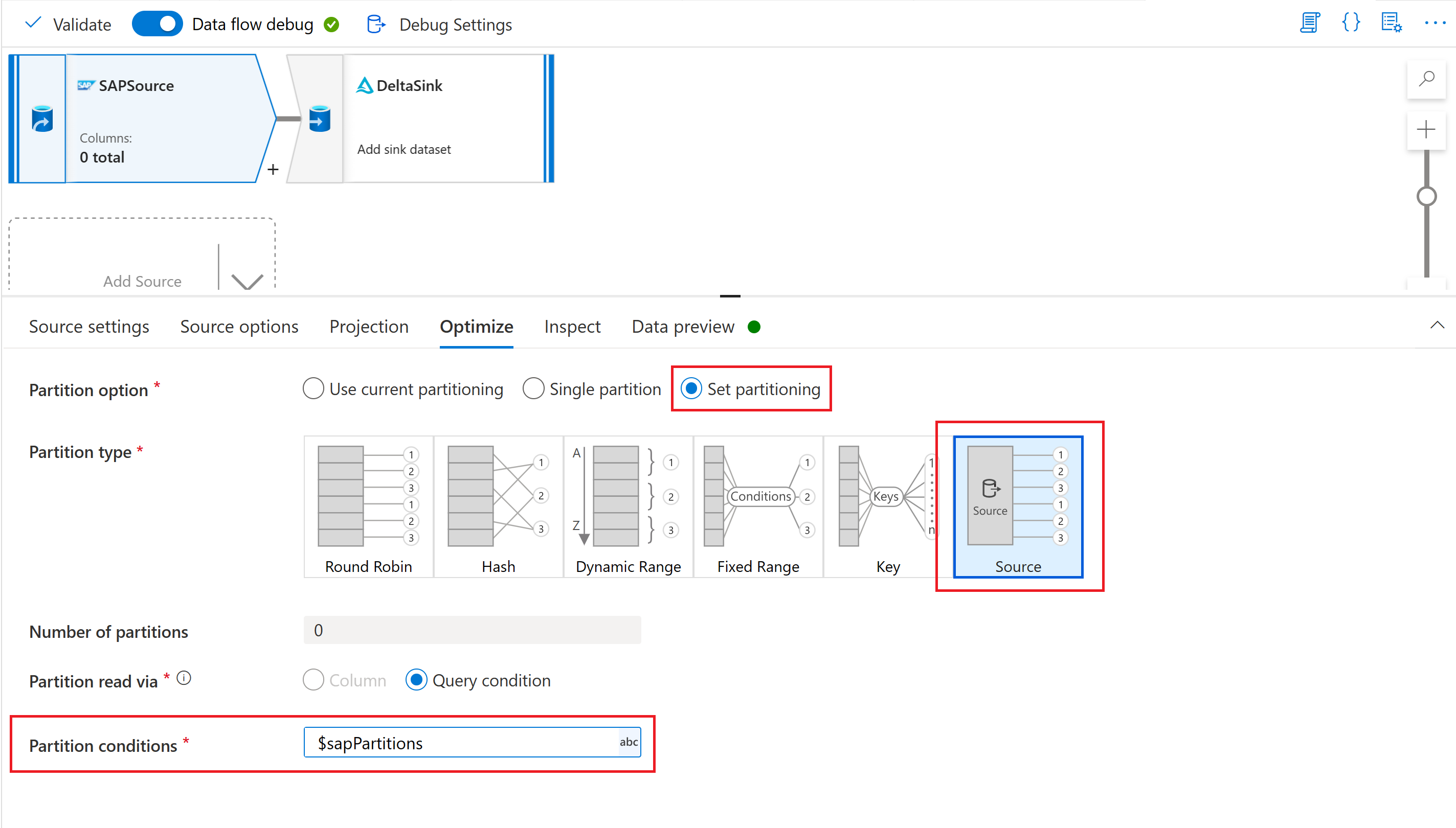
Infine, nella scheda Ottimizza della trasformazione di origine nel flusso di dati di mapping selezionare Tipo di partizione "Origine" e immettere il parametro flusso di dati nella proprietà Condizioni di partizione .
Parametrizzazione della chiave del checkpoint
Quando si usa un flusso di dati parametrizzato per estrarre i dati da più origini SAP CDC, è importante parametrizzare la chiave checkpoint nell'attività del flusso di dati della pipeline. La chiave del checkpoint viene usata da Azure Data Factory per gestire lo stato di un processo di acquisizione dei dati di modifica. Per evitare che lo stato di un processo CDC sovrascriva lo stato di un altro, assicurarsi che i valori della chiave del checkpoint siano univoci per ogni set di parametri usato in un flusso di dati.
Nota
Una procedura consigliata per garantire l'univocità della chiave di checkpoint consiste nell'aggiungere il valore della chiave di checkpoint al set di parametri per il flusso di dati.
Per altre informazioni sulla chiave del checkpoint, vedere Trasformare i dati con il connettore SAP CDC.
Debug
Azure Data Factory le pipeline possono essere eseguite tramite esecuzioni attivate o di debug. Una differenza fondamentale tra queste due opzioni è che il debug esegue il flusso di dati e la pipeline in base alla versione corrente modellata nell'interfaccia utente, mentre viene attivata l'esecuzione dell'ultima versione pubblicata di un flusso di dati e di una pipeline.
Per SAP CDC, è necessario comprendere un aspetto maggiore: per evitare un impatto sulle esecuzioni di debug in un processo di acquisizione dei dati di modifica esistente, il debug usa un valore di "processo sottoscrittore" diverso (vedere Monitorare i flussi di dati SAP CDC) rispetto alle esecuzioni attivate. Pertanto, creano sottoscrizioni separate, ovvero cambiano i processi di acquisizione dei dati, all'interno del sistema SAP. Inoltre, il valore "processo sottoscrittore" per le esecuzioni di debug ha un tempo di vita limitato alla sessione dell'interfaccia utente del browser.
Nota
Per testare la stabilità di un processo di acquisizione dei dati di modifica con SAP CDC in un periodo di tempo più lungo (ad esempio, più giorni), il flusso di dati e la pipeline devono essere pubblicate e le esecuzioni attivate devono essere eseguite.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per