Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come iniziare una prova gratuita!
L'attività Processo di Azure Databricks in una pipeline esegue i processi Databricks nell'area di lavoro di Azure Databricks, inclusi i processi serverless. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate. Azure Databricks è una piattaforma gestita per l'esecuzione di Apache Spark.
È possibile creare un processo di Databricks direttamente tramite l'interfaccia utente di Azure Data Factory Studio.
Aggiungere un'attività di lavoro per Azure Databricks a una pipeline utilizzando l'interfaccia utente
Per usare un'attività di lavoro per Azure Databricks in una pipeline, seguire questi passaggi:
Cercare Processo nel riquadro Attività della pipeline e trascinare un'attività Processo nell'area di disegno della pipeline.
Selezionare la nuova attività Processo nell'area di disegno, se non è già selezionata.
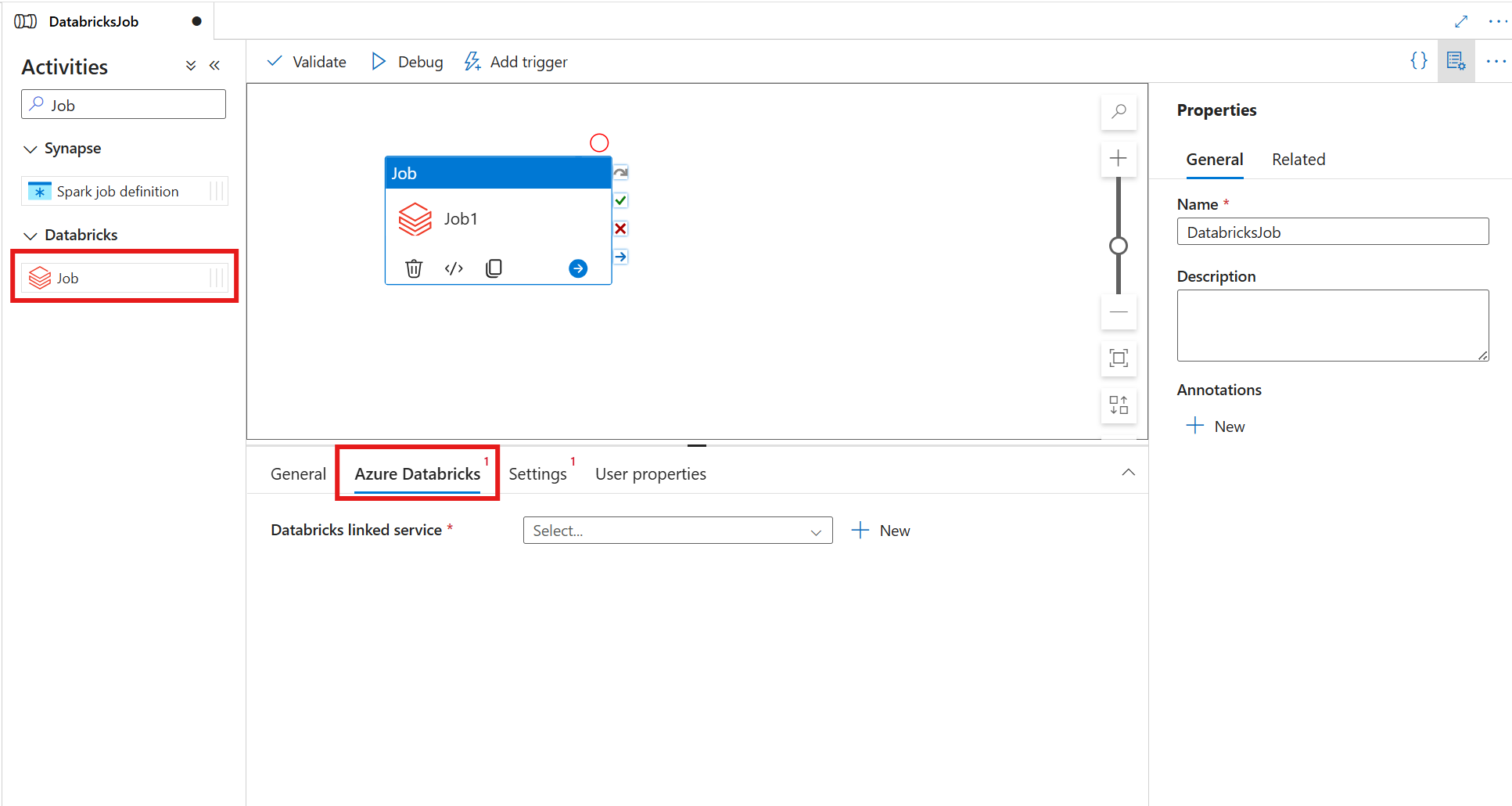
Selezionare la scheda Azure Databricks per selezionare o creare un nuovo servizio collegato di Azure Databricks.
Annotazioni
L'attività Processo di Azure Databricks viene eseguita automaticamente nei cluster serverless, per cui non è necessario specificare un cluster nella configurazione del servizio collegato. Scegliere invece l'opzione Serverless .
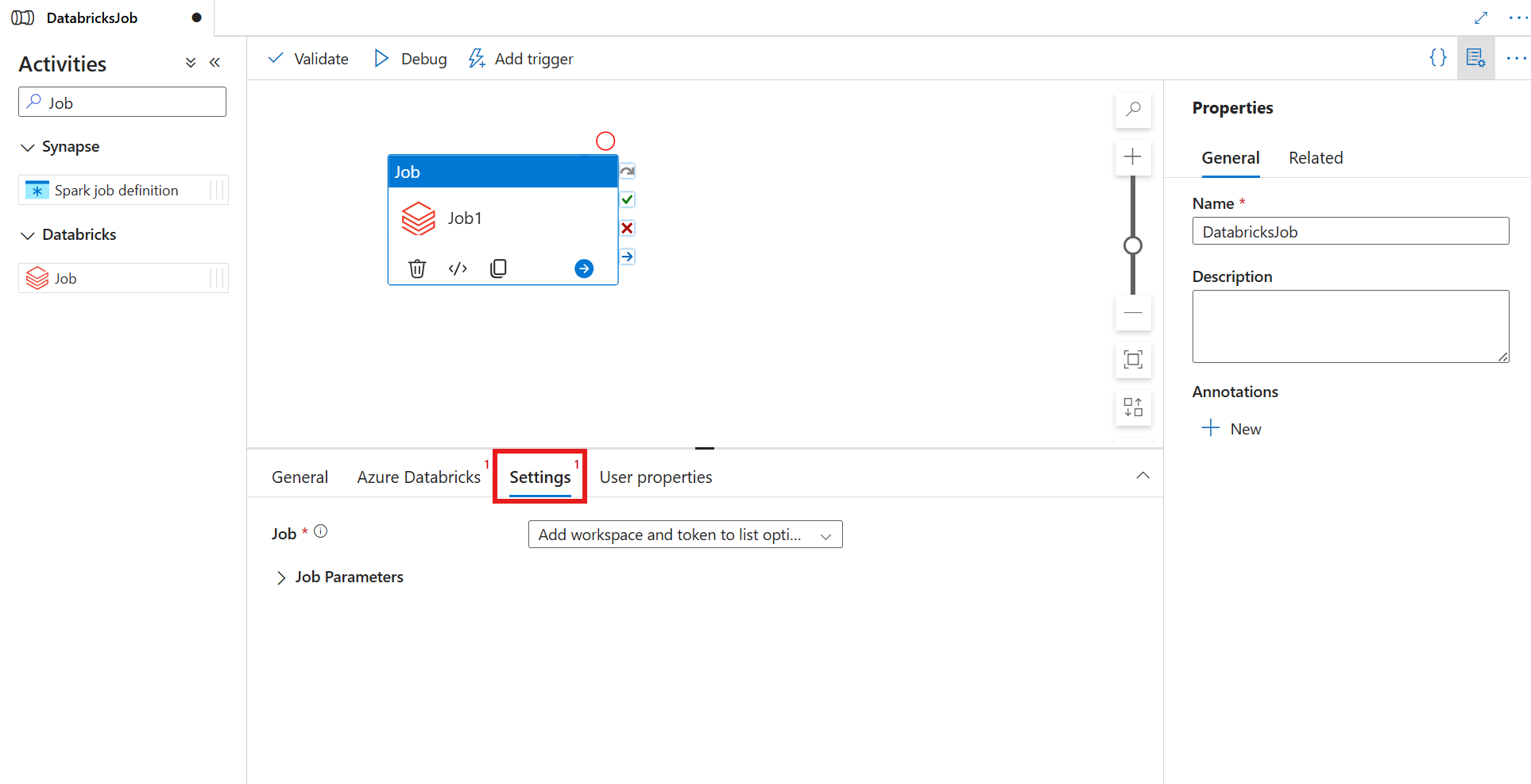
Selezionare la scheda Impostazioni e specificare il processo da eseguire in Azure Databricks, i parametri di base facoltativi da passare al processo e le altre librerie da installare nel cluster per eseguire il processo.


Definizione dell'attività Processo di Databricks
Ecco la definizione JSON di esempio di un'attività Processo di Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksJob",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"jobID": "012345678910112",
"jobParameters": {
"testParameter": "testValue"
},
}
}
}
Proprietà dell'attività Processo di Databricks
La tabella seguente fornisce le descrizioni delle proprietà JSON usate nella definizione JSON:
| Proprietà | Descrizione | Obbligatorio |
|---|---|---|
| nome | Nome dell'attività nella pipeline. | Sì |
| descrizione | Testo che descrive l'attività. | NO |
| tipo | Per l'attività Databricks Job, il tipo di attività è DatabricksJob. | Sì |
| linkedServiceName | Nome del servizio collegato Databricks su cui viene eseguito il processo di Databricks. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| jobId | ID del processo da eseguire nell'area di lavoro di Databricks. | Sì |
| parametriDiLavoro | Matrice di coppie chiave-valore. I parametri del lavoro possono essere usati per ogni esecuzione di un'attività. Se il processo accetta un parametro non specificato, verrà usato il valore predefinito del processo. Per altre informazioni sui parametri, vedere Processi di Databricks. | NO |
Passaggio di parametri tra processi e pipeline
È possibile passare parametri ai processi usando la proprietà jobParameters nell'attività Databricks.
Annotazioni
I parametri del processo sono supportati solo nella versione 5.52.0.0 o successiva di Runtime di integrazione self-hosted.