Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
In questa esercitazione si usa il portale di Azure per creare una pipeline di Azure Data Factory che eseguirà un notebook di Databricks nel cluster dei processi Databricks Passa anche i parametri Azure Data Factory al notebook di Databricks durante l'esecuzione.
In questa esercitazione vengono completati i passaggi seguenti:
Creare una fabbrica di dati.
Creare una pipeline che usa l'attività dei notebook di Databricks.
Attivare un'esecuzione della pipeline.
Monitorare l'esecuzione della pipeline.
Se non si ha una sottoscrizione Azure, creare un account free prima di iniziare.
Nota
Per informazioni dettagliate su come usare l'attività notebook di Databricks, tra cui l'uso di librerie e il passaggio di parametri di input e output, vedere la documentazione relativa all'attività notebook di Databricks.
Prerequisiti
- Azure Databricks spazio di lavoro. Creare un'area di lavoro di Databricks o usarne una esistente. Crei un notebook Python nella tua area di lavoro Azure Databricks. Poi, esegui il notebook e passagli i parametri usando Azure Data Factory.
Creare una data factory
Avviare Microsoft Edge o Google Chrome Web browser. Attualmente, l'interfaccia utente di Data Factory è supportata solo in Microsoft Edge e nei Web browser Google Chrome.
Selezionare Crea una risorsa nel menu del portale di Azure, quindi selezionare Analytics>Data Factory:
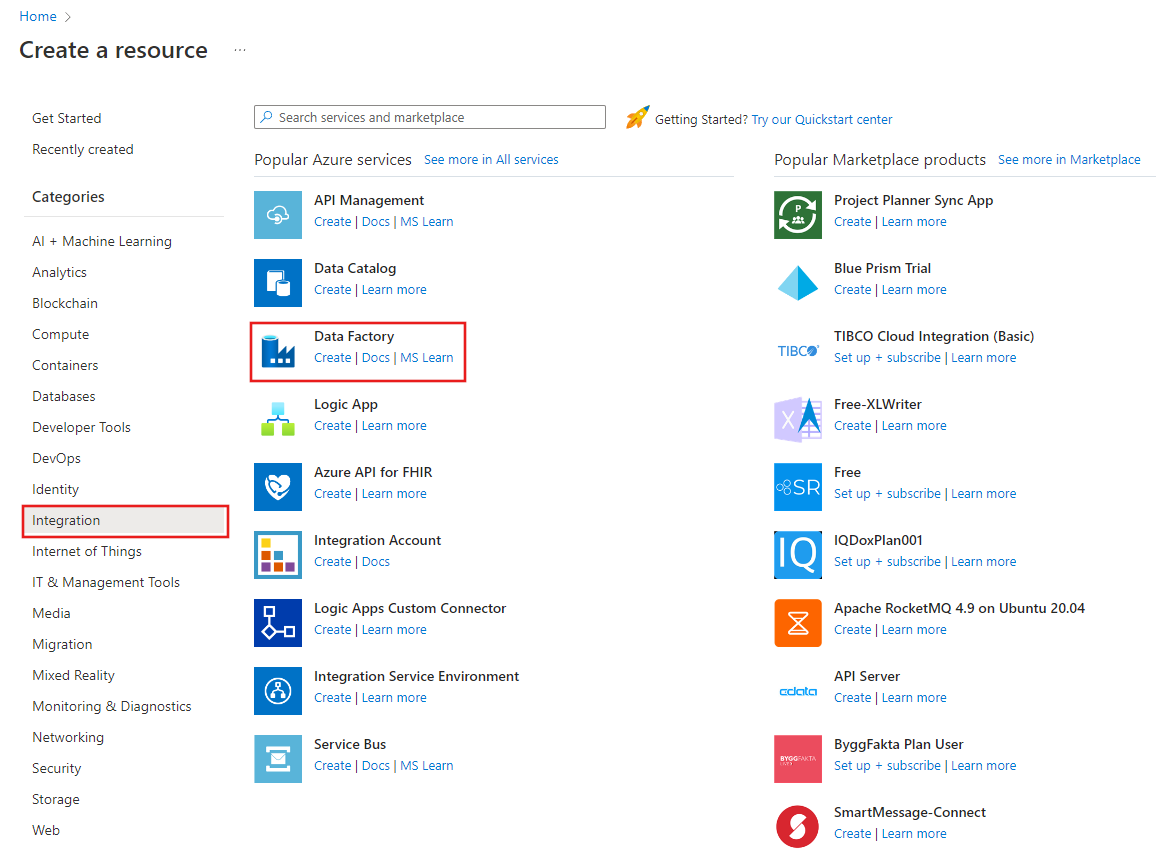
Nella pagina Crea data factory, in Basics selezionare la scheda Azure Subscription in cui si vuole creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
Selezionare un gruppo di risorse esistente dall'elenco a discesa.
Selezionare Crea nuovo e immettere il nome di un nuovo gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere Utilizza i gruppi di risorse per gestire le risorse Azure.
In Area selezionare la località per la data factory.
L'elenco mostra solo i percorsi supportati da Data Factory e dove verranno archiviati i metadati Azure Data Factory. Gli archivi dati associati (ad esempio Archiviazione di Azure e database SQL di Azure) e i calcoli (ad esempio Azure HDInsight) usati da Data Factory possono essere eseguiti in altre aree.
Inserire ADFTutorialDataFactory nel campo Nome.
Il nome della data factory Azure deve essere globalmente univoco. Se viene visualizzato l'errore seguente, modifica il nome del data factory, ad esempio utilizzando <tuonome>ADFTutorialDataFactory. Per le regole di denominazione per gli elementi di Data Factory, vedere l'articolo Data Factory - Regole di denominazione.
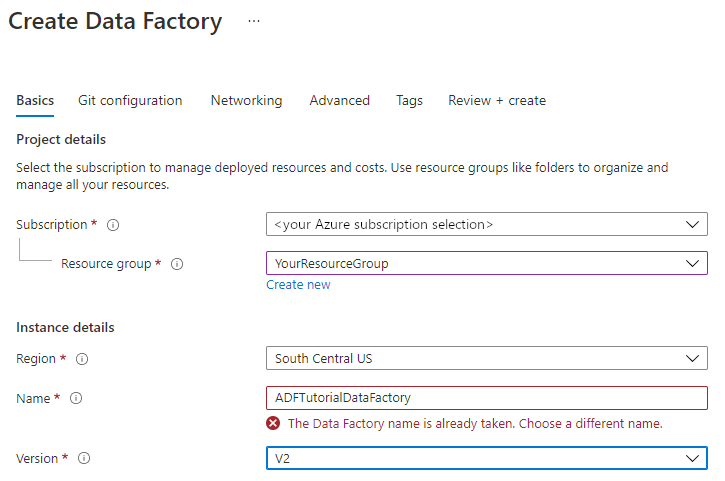
Per Versione selezionare V2.
Selezionare Avanti: Configurazione Git e quindi selezionare Configura Git in un secondo momento .
Selezionare Rivedi e crea e quindi, una volta superata la convalida, selezionare Crea.
Al termine della creazione, selezionare Vai alla risorsa per passare alla pagina Data Factory. Selezionare il riquadro Aprire Azure Data Factory Studio per avviare l'applicazione interfaccia utente Azure Data Factory in una scheda separata del browser.

Creare servizi collegati
In questa sezione, si crea un servizio collegato a Databricks. Questo servizio collegato contiene le informazioni di connessione al cluster Databricks:
Creare un servizio collegato Azure Databricks
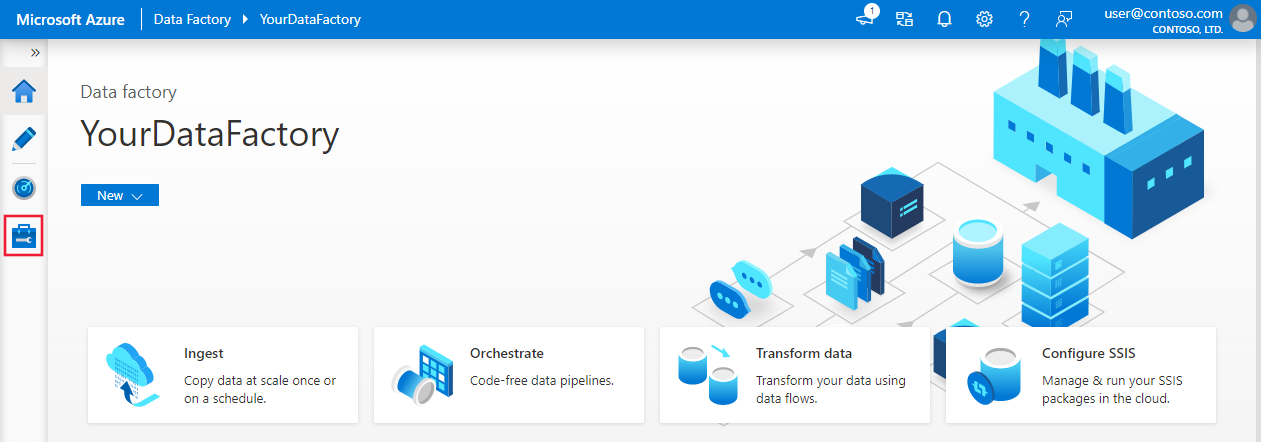
Nella home page passare alla scheda Gestisci nel pannello sinistro.
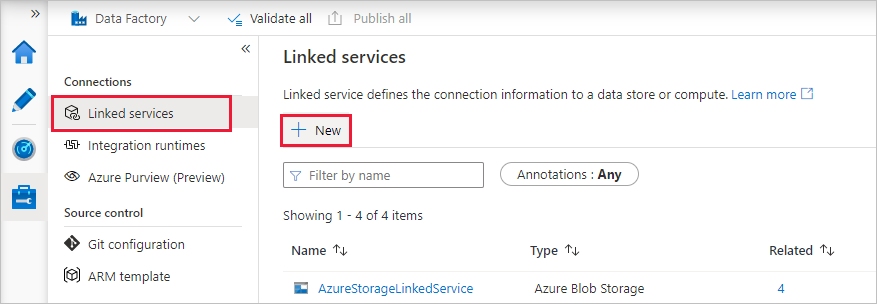
Selezionare Servizi collegati in Connessioni e quindi + Nuovo.
Nella finestra Nuovo servizio collegato selezionare Compute>Azure Databricks e quindi selezionare Continue.

Nella finestra Nuovo servizio collegato completare la procedura seguente:
In Nome immettere AzureDatabricks_LinkedService.
Selezionare l'area di lavoro Databricks appropriata in cui verrà eseguito il notebook.
In Select cluster (Seleziona cluster) selezionare New job cluster (Nuovo cluster di processo).
Per l'URL dell'area di lavoro di Databricks, le informazioni devono essere popolate automaticamente.
Per Tipo di autenticazione, se si seleziona Access Token, generarlo dall'area di lavoro Azure Databricks. La procedura è disponibile qui. Per Identità del servizio gestito e Identità gestita assegnata dall'utente, concedi il ruolo di collaboratore a entrambe le identità nel menu Controllo accessi della risorsa di Azure Databricks.
Per versione del cluster, selezionare la versione da usare.
Per Tipo di nodo cluster selezionare Standard_D3_v2 nella categoria Utilizzo generico (HDD) per questa esercitazione.
Per Workers, immettere 2.
Selezionare Crea.

Creare una pipeline
Selezionare il pulsante + (segno più) e quindi selezionare Pipeline dal menu.

Creare un parametro da usare nella pipeline. Successivamente, passerai questo parametro all'attività Notebook di Databricks. Nella pipeline vuota selezionare la scheda Parametri, quindi selezionare + Nuovo e denominarla come 'name'.


Nella casella degli strumenti Attività espandere Databricks. Trascinare l'attività Notebook dalla casella degli strumenti Attività nell'area di progettazione della pipeline.

Nelle proprietà della finestra dell'attività DatabricksNotebook in basso completare questa procedura:
Passare alla scheda Azure Databricks.
Selezionare AzureDatabricks_LinkedService (creato nella procedura precedente).
Passare alla scheda Impostazioni .
Sfoglia per selezionare un percorso del notebook di Databricks. Creiamo un notebook e specifichiamo il percorso qui. Ottenere il percorso del notebook seguendo questi passaggi.
Avviare l'area di lavoro Azure Databricks.
Creare una nuova cartella nell'area di lavoro e chiamarla adftutorial.
Creare un nuovo blocco appunti, che verrà chiamato mynotebook. Fare clic con il pulsante destro del mouse sulla cartella adftutorial e scegliere Crea.
Aggiungere il codice seguente nel notebook "mynotebook" appena creato:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Il Percorso del Blocco Appunti in questo caso è /adftutorial/mynotebook.
Tornare allo strumento di creazione dell'interfaccia utente di Data Factory. Passare alla scheda Impostazioni nell'attività Notebook1 .
a) Aggiungere un parametro all'attività Notebook. Usare lo stesso parametro aggiunto in precedenza alla pipeline.

b. Assegnare al parametro il nome input e specificare il valore come espressione @pipeline().parameters.name.
Per convalidare la pipeline, selezionare il pulsante Convalida sulla barra degli strumenti. Per chiudere la finestra di convalida, selezionare il pulsante Chiudi .
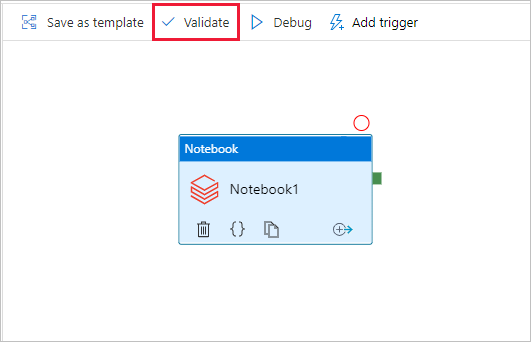
Selezionare Pubblica tutto. L'interfaccia utente di Data Factory pubblica le entità (servizi collegati e pipeline) nel servizio Azure Data Factory.

Attivare un'esecuzione della pipeline
Selezionare Aggiungi trigger sulla barra degli strumenti e quindi selezionare Attiva adesso.
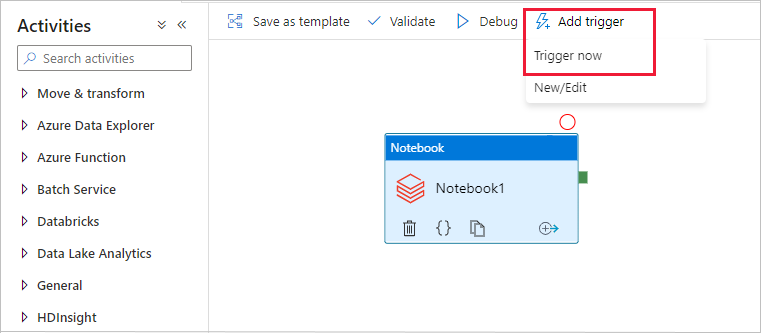
La finestra di dialogo Esecuzione della pipeline chiede il parametro nome. Usare /path/filename come parametro qui. Seleziona OK.

Monitorare l'esecuzione della pipeline
Passare alla scheda Monitoraggio. Verificare che venga visualizzata un'esecuzione della pipeline. Sono necessari circa 5-8 minuti per creare un cluster di lavoro Databricks in cui viene eseguito il notebook.
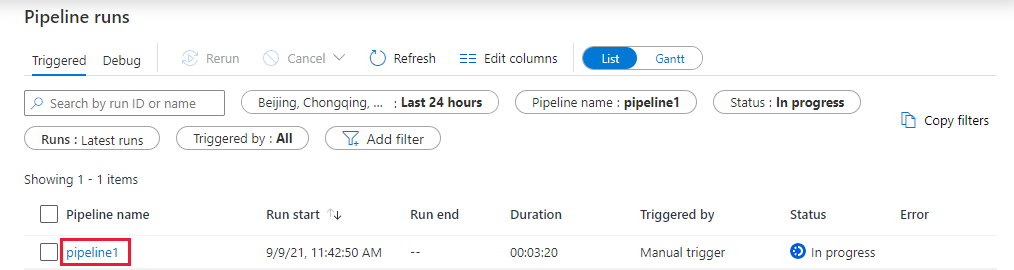
Selezionare periodicamente Aggiorna per controllare lo stato dell'esecuzione della pipeline.
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento pipeline1 nella colonna Nome pipeline.
Nella pagina Esecuzioni attività selezionare Output nella colonna Nome attività per visualizzare l'output di ogni attività ed è possibile trovare il collegamento ai log di Databricks nel riquadro Output per i log Spark più dettagliati.
È possibile tornare alla vista delle esecuzioni della pipeline selezionando il collegamento Tutte le esecuzioni della pipeline nel menu breadcrumb in alto.
Verificare l'output
È possibile accedere all'area di lavoro Azure Databricks, passare a Esecuzioni processi ed è possibile visualizzare lo stato del Job come in attesa di esecuzione, in esecuzione o terminato.
È possibile selezionare il nome del Job e navigare per visualizzare ulteriori dettagli. Al termine dell'esecuzione, è possibile convalidare i parametri passati e l'output del notebook Python.
Riepilogo
La pipeline in questo esempio avvia un'attività dei notebook di Databricks e le passa un parametro. Si è appreso come:
Creare una fabbrica di dati.
Creare una pipeline che usa un'attività dei notebook di Databricks.
Attivare un'esecuzione della pipeline.
Monitorare l'esecuzione della pipeline.