Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In questa esercitazione si usa il portale di Azure per creare una pipeline di Data Factory che trasforma i dati con un'attività Hive in un cluster HDInsight che si trova in una rete virtuale di Azure. In questa esercitazione vengono completati i passaggi seguenti:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted
- Creare servizi collegati Archiviazione di Azure e Azure HDInsight.
- Creare una pipeline con un'attività Hive.
- Attivare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline
- Verificare l'output
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Account di archiviazione di Azure. Creare uno script Hive e caricarlo nell'archivio di Azure. L'output dello script Hive viene archiviato in questo account di archiviazione. In questo esempio, il cluster HDInsight usa questo account di archiviazione di Azure come risorsa di archiviazione primaria.
Rete virtuale di Azure. Se non è disponibile una rete virtuale di Azure, crearla seguendo queste istruzioni. In questo esempio, il cluster HDInsight si trova in una rete virtuale di Azure. Ecco una configurazione di esempio della rete virtuale di Azure.
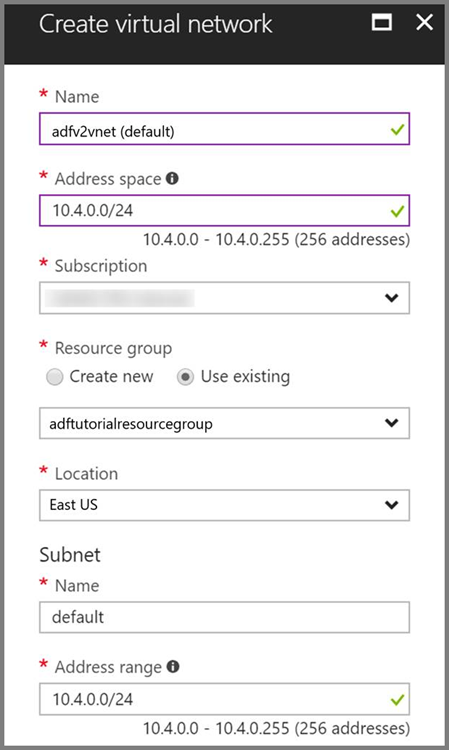
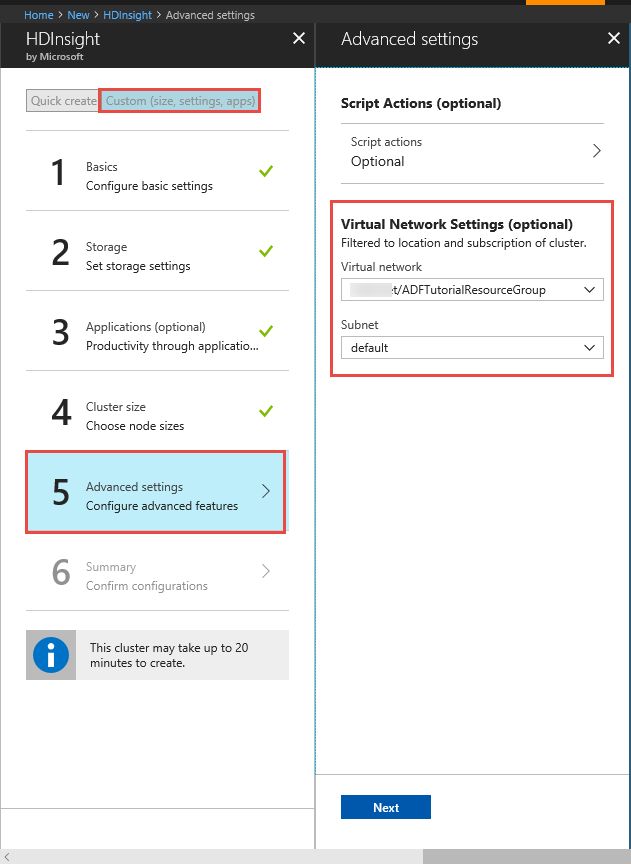
Cluster HDInsight. Creare un cluster HDInsight e aggiungerlo alla rete virtuale creata nel passaggio precedente seguendo questo articolo: Estendere Azure HDInsight usando Rete virtuale di Azure. Ecco una configurazione di esempio di HDInsight in una rete virtuale.
Azure PowerShell. Seguire le istruzioni in Come installare e configurare Azure PowerShell.
Una macchina virtuale. Creare una macchina virtuale (VM) di Azure e aggiungerla alla stessa rete virtuale che contiene il cluster HDInsight. Per informazioni dettagliate, vedere come creare macchine virtuali.
Caricare lo script Hive nell'account di archiviazione BLOB
Creare un file Hive SQL denominato hivescript.hql con il contenuto seguente:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableNell'Archivio BLOB di Azure creare un contenitore denominato adftutorial, se non esiste.
Creare una cartella denominata hivescripts.
Caricare il file hivescript.hql nella sottocartella hivescripts.
Creare una data factory
Se non è ancora stato creato il data factory, seguire la procedura descritta in Avvio rapido: creare un data factory usando il portale di Azure e Azure Data Factory Studio per crearne uno. Dopo averlo creato, passare alla data factory nel portale di Azure.

Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'applicazione Integrazione dei dati in una scheda separata.
Creare un runtime di integrazione self-hosted
Dato che il cluster Hadoop si trova all'interno di una rete virtuale, è necessario installare un runtime di integrazione self-hosted nella stessa rete virtuale. In questa sezione si crea una nuova VM, si aggiunge la VM alla stessa rete virtuale e vi si installa un runtime di integrazione self-hosted. Il runtime di integrazione self-hosted consente al servizio Data Factory di inviare richieste di elaborazione a un servizio di calcolo come HDInsight all'interno di una rete virtuale, nonché di spostare dati tra archivi dati in una rete virtuale e Azure. Un runtime di integrazione self-hosted viene usato anche quando l'archivio dati o il servizio di calcolo si trova in un ambiente locale.
Nell'interfaccia utente di Azure Data Factory fare clic su Connessioni nella parte inferiore della finestra, passare alla scheda Integration Runtimes (Runtime di integrazione) e fare clic sul pulsante + Nuovo sulla barra degli strumenti.
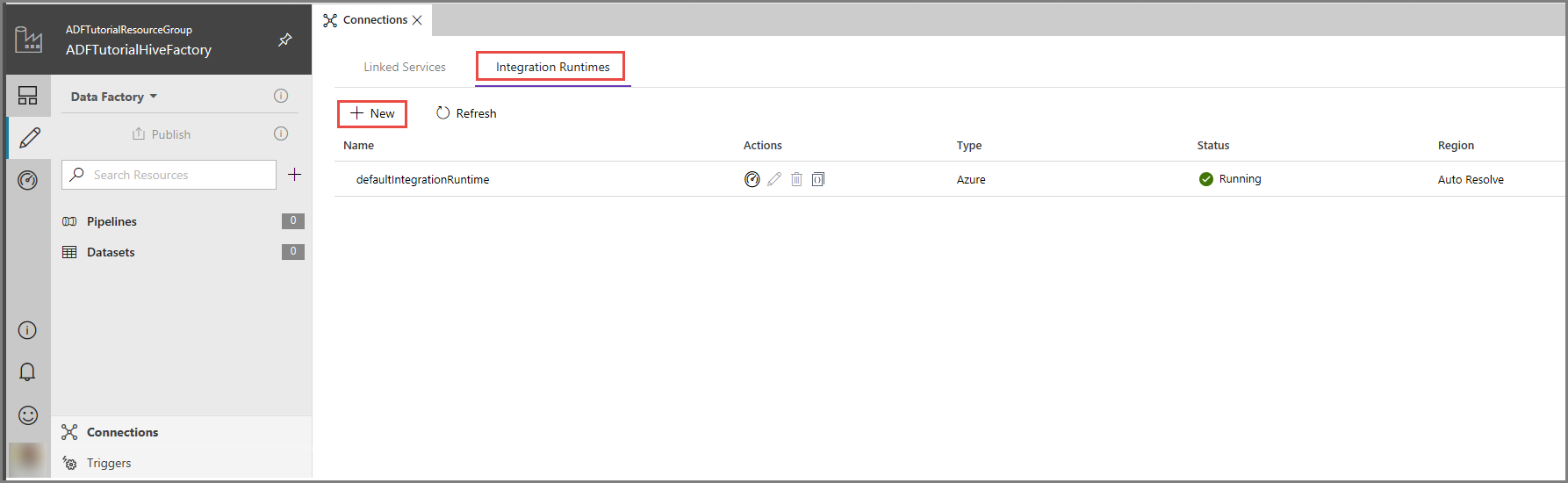
Nella finestra Integration Runtime Setup (Configurazione runtime di integrazione) selezionare l'opzione Perform data movement and dispatch activities to external computes (Eseguire attività di invio e spostamento dati in servizi di calcolo esterni) e fare clic su Avanti.
Selezionare Private Network (Rete privata) e fare clic su Avanti.
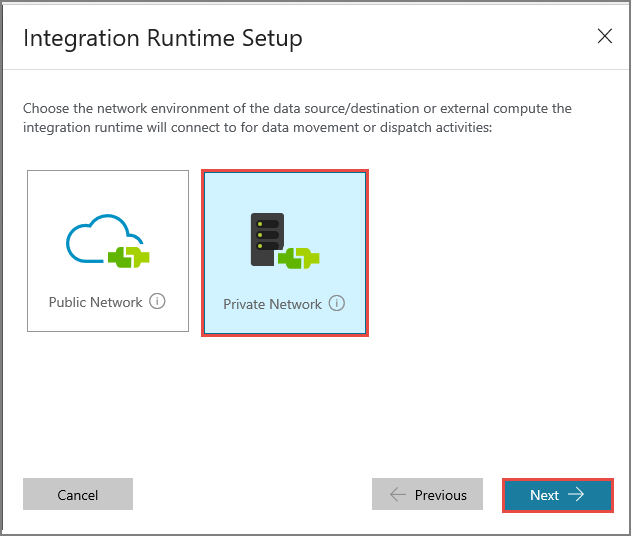
Immettere MySelfHostedIR per Nome, e fare clic su Avanti.
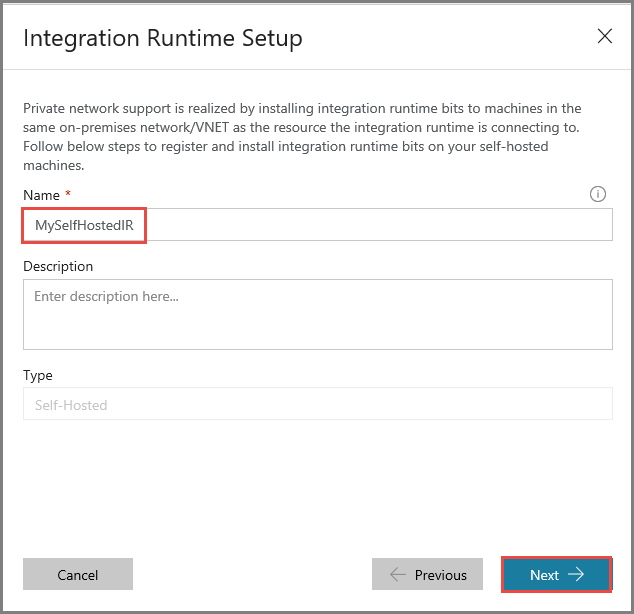
Copiare la chiave di autenticazione per il runtime di integrazione facendo clic sul pulsante di copia e salvarla. Tenere aperta la finestra. Questa chiave verrà usata per registrare il runtime di integrazione installato in una macchina virtuale.
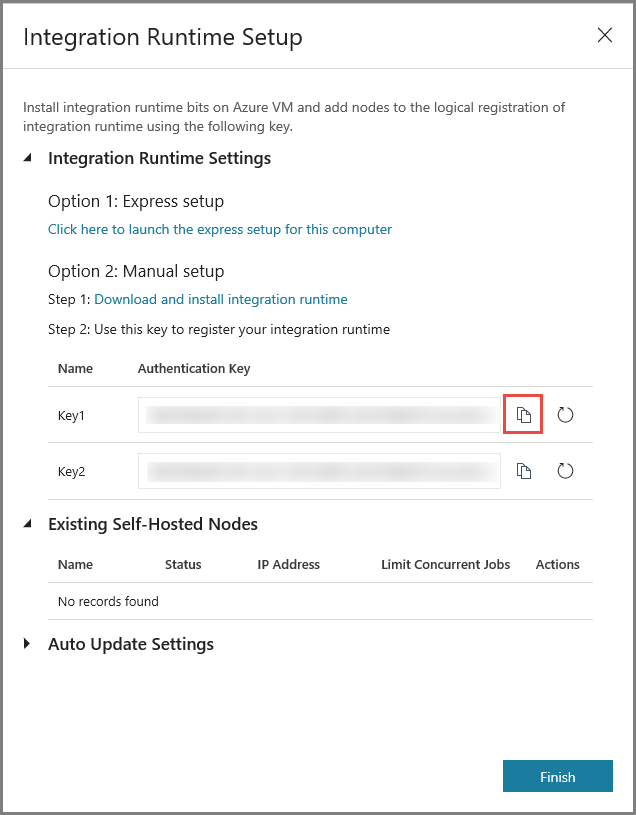
Installare il runtime di integrazione in una macchina virtuale
Nella macchina virtuale di Azure, scaricare il runtime di integrazione self-hosted. Usare la chiave di autenticazione ottenuta nel passaggio precedente per registrare manualmente il runtime di integrazione self-hosted.
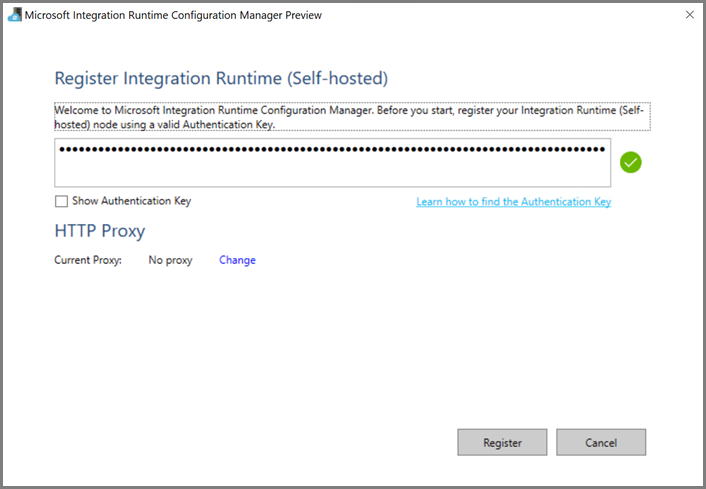
Al termine della registrazione del runtime di integrazione self-hosted verrà visualizzato il messaggio seguente.
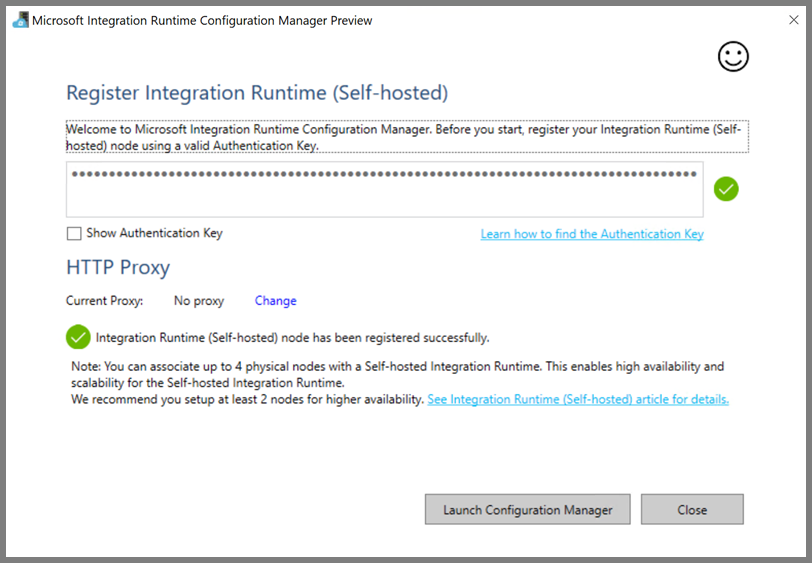
Fare clic su Avvia Configuration Manager. Quando il nodo viene connesso al servizio cloud, viene visualizzata la pagina seguente:
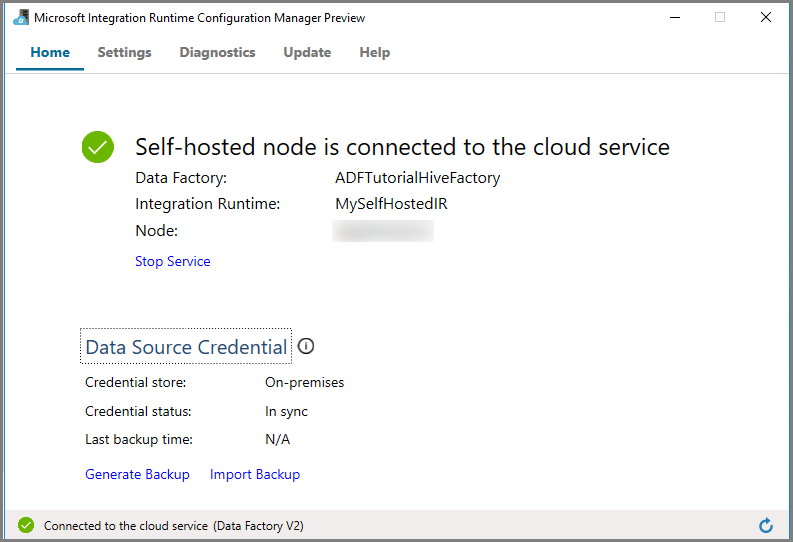
Runtime di integrazione self-hosted nell'interfaccia utente di Azure Data Factory
Nell'interfaccia utente di Azure Data Factory verranno visualizzati il nome e lo stato della VM self-hosted.
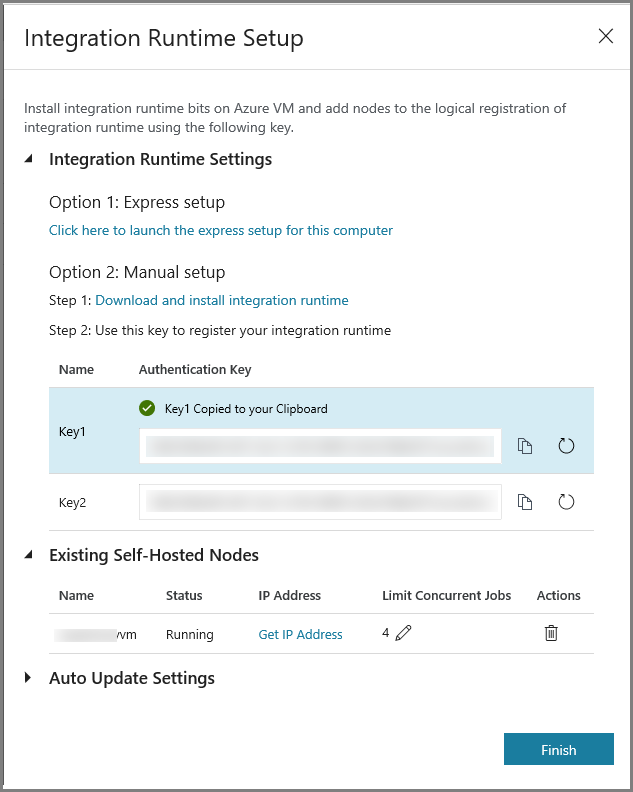
Fare clic su Fine per chiudere la finestra Integration Runtime Setup (Configurazione runtime di integrazione). Il runtime di integrazione self-hosted verrà visualizzato nell'elenco dei runtime di integrazione.

Creare servizi collegati
In questa sezione vengono creati e distribuiti due servizi collegati:
- Un servizio collegato Archiviazione di Azure che collega un account di archiviazione di Azure alla data factory. Questa risorsa di archiviazione è l'archiviazione primaria usata dal cluster HDInsight. In questo caso, l'account di archiviazione di Azure viene usato per archiviare lo script Hive e l'output dello script.
- Un servizio collegato HDInsight. Azure Data Factory invia lo script Hive a questo cluster HDInsight per l'esecuzione.
Creare il servizio collegato Archiviazione di Azure
Passare alla scheda Servizi collegati e fare clic su Nuovo.
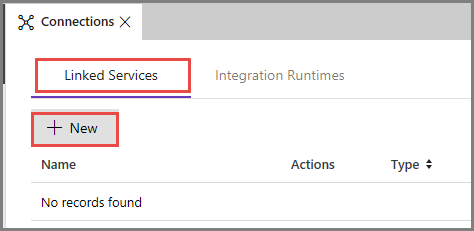
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Archiviazione BLOB di Azure e fare clic su Continua.
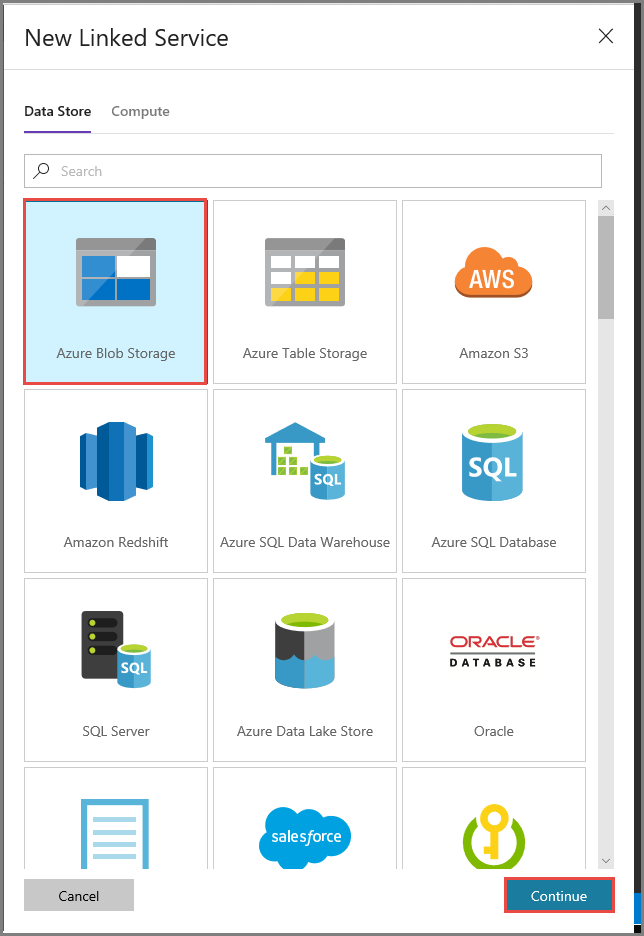
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
Immettere AzureStorageLinkedService per Nome.
Selezionare MySelfHostedIR per Connect via integration runtime (Connetti tramite runtime di integrazione).
Selezionare il proprio account di archiviazione di Azure per Nome account di archiviazione.
Per testare la connessione all'account di archiviazione, fare clic su Test connessione.
Fare clic su Salva.
Creare un servizio collegato HDInsight
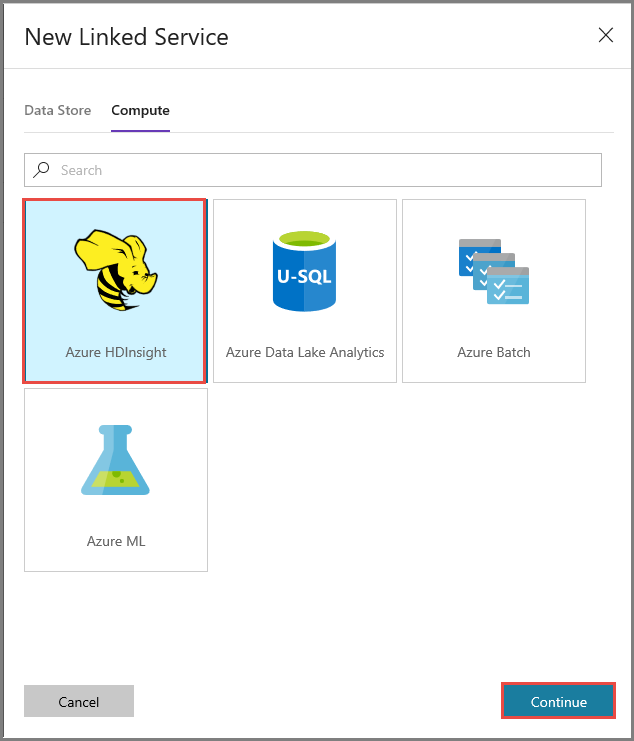
Fare di nuovo clic su Nuovo per creare un altro servizio collegato.
Passare alla scheda Calcolo, selezionare Azure HDInsight e fare clic su Continua.
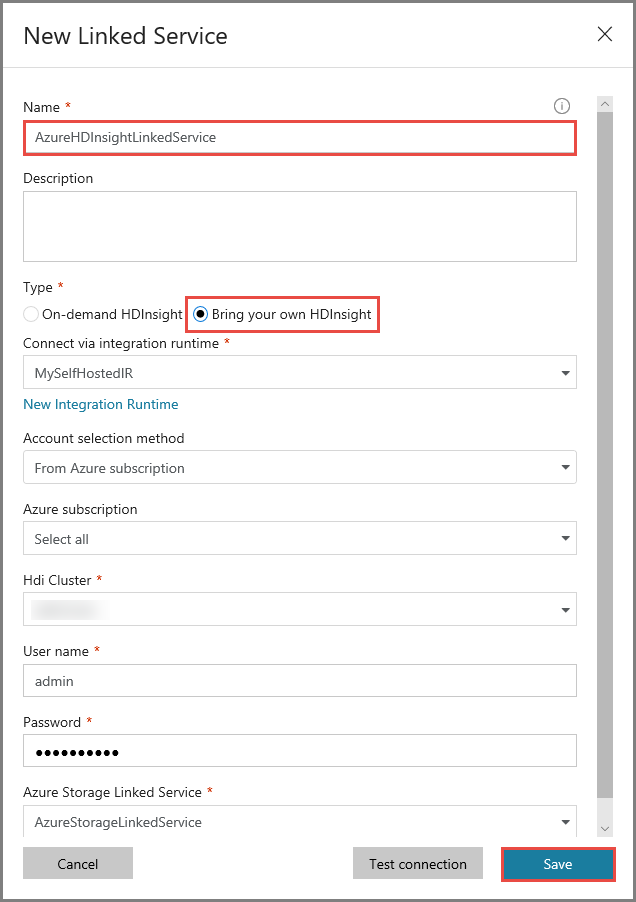
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
Immettere AzureHDInsightLinkedService per Nome.
Selezionare Bring your own HDInsight (Bring Your Own HDInsight).
Selezionare il proprio cluster HDInsight per Hdi cluster (Cluster HDInsight).
Immettere il nome utente per il cluster HDInsight.
Immettere la password dell'utente.
Questo articolo presuppone che sia disponibile l'accesso al cluster tramite Internet, ad esempio che sia possibile connettersi al cluster all'indirizzo https://clustername.azurehdinsight.net. Questo indirizzo usa il gateway pubblico, che non è disponibile se sono stati usati gruppi di sicurezza di rete o route definite dall'utente per limitare l'accesso da Internet. Per consentire a Data Factory di inviare processi al cluster HDInsight nella rete virtuale di Azure, è necessario configurare la rete virtuale di Azure in modo che l'URL possa essere risolto nell'indirizzo IP privato del gateway usato da HDInsight.
Nel portale di Azure aprire la rete virtuale in cui si trova il cluster HDInsight. Aprire l'interfaccia di rete avente il nome che inizia con
nic-gateway-0. Annotarne l'indirizzo IP privato, ad esempio 10.6.0.15.Se la rete virtuale di Azure ha un server DNS, aggiornare il record DNS in modo che l'URL del cluster HDInsight
https://<clustername>.azurehdinsight.netpossa essere risolto in10.6.0.15. Se non è disponibile un server DNS nella rete virtuale di Azure, il problema può essere temporaneamente risolto modificando il file hosts (C:\Windows\System32\drivers\etc) di tutte le VM registrate come nodi del runtime di integrazione self-hosted aggiungendo una voce simile alla seguente:10.6.0.15 myHDIClusterName.azurehdinsight.net
Creare una pipeline
In questo passaggio si crea una nuova pipeline con un'attività Hive. L'attività esegue uno script Hive per restituire i dati da una tabella di esempio e salvarli in un percorso definito dall'utente.
Notare i punti seguenti:
- scriptPath punta al percorso dello script Hive nell'account di archiviazione di Azure usato per MyStorageLinkedService. Per il percorso viene applicata la distinzione tra maiuscole e minuscole.
-
Output è un argomento usato nello script Hive. Usare il formato
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/in modo che l'output punti a una cartella esistente nell'archivio di Azure. Per il percorso viene applicata la distinzione tra maiuscole e minuscole.
Nell'interfaccia utente di Data Factory fare clic su + (segno più) nel riquadro a sinistra e quindi su Pipeline.
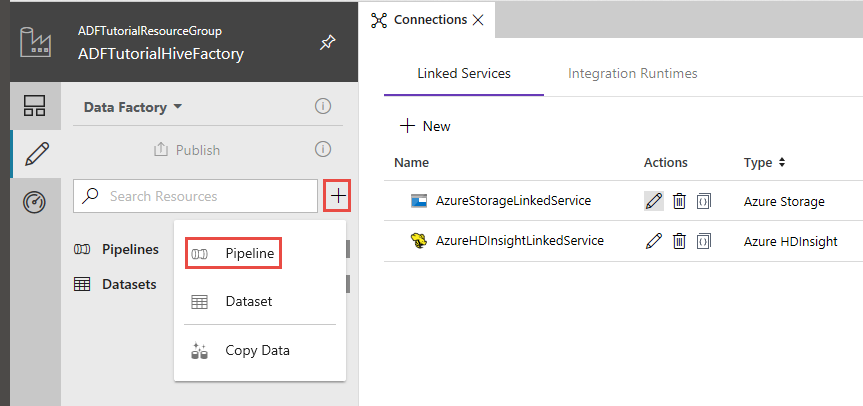
Nella casella degli strumenti Attività espandere HDInsight e trascinare l'attività Hive nell'area di progettazione della pipeline.
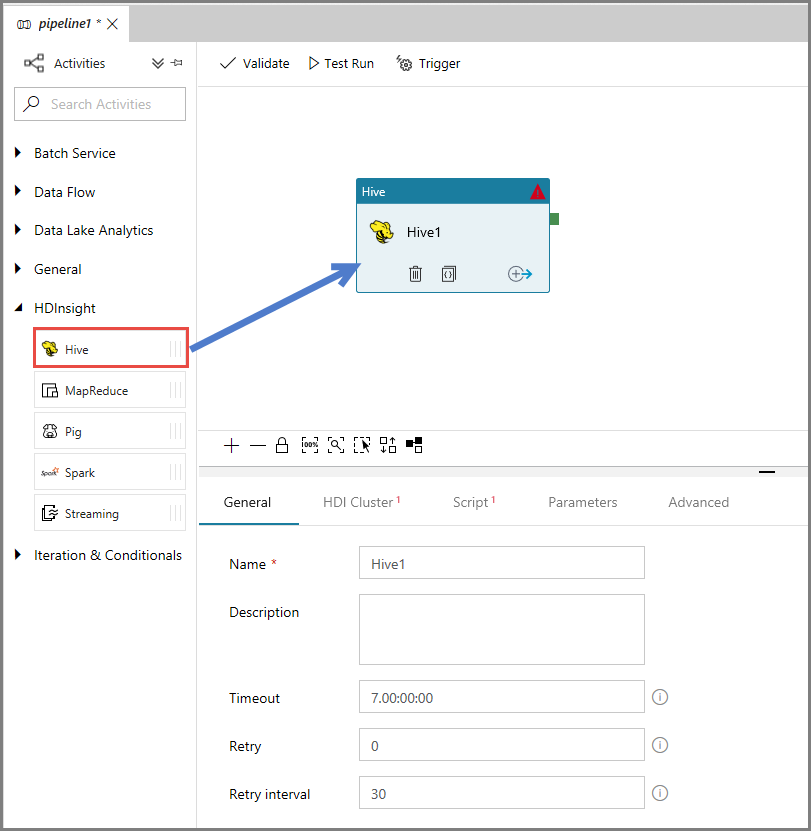
Nella finestra delle proprietà passare alla scheda HDI Cluster (Cluster HDInsight) e selezionare AzureHDInsightLinkedService per HDInsight Linked Service (Servizio collegato HDInsight).

Passare alla scheda Script e seguire questa procedura:
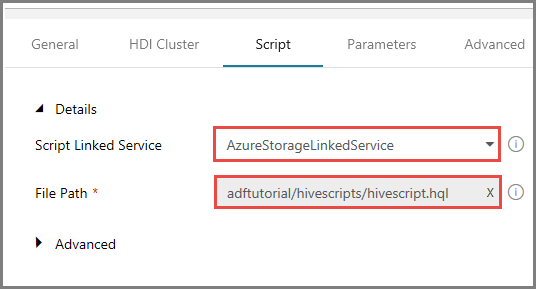
Selezionare AzureStorageLinkedService per Servizio script collegato.
Per Percorso file fare clic su Sfoglia risorsa di archiviazione.
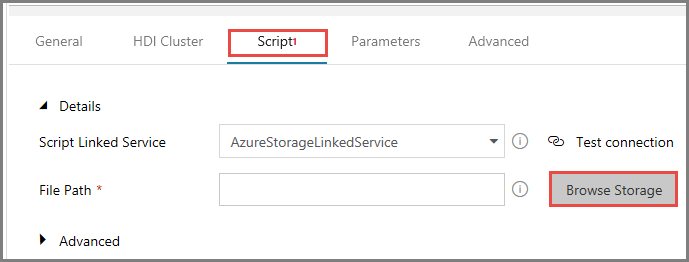
Nella finestra Choose a file or folder (Scegliere un file o una cartella) passare alla cartella hivescripts del contenitore adftutorial, selezionare hivescript.hql e fare clic su Fine.
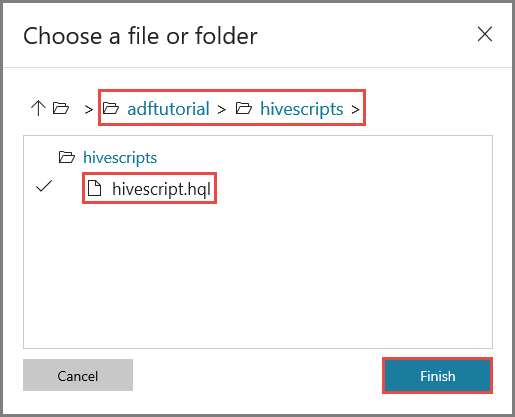
Verificare che in Percorso file venga visualizzato adftutorial/hivescripts/hivescript.hql.
Nella scheda Script espandere la sezione Avanzate.
Fare clic su Auto-fill from script (Compila automaticamente da script) per Parametri.
Immettere il valore per il parametro Output nel formato seguente:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Ad esempio:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.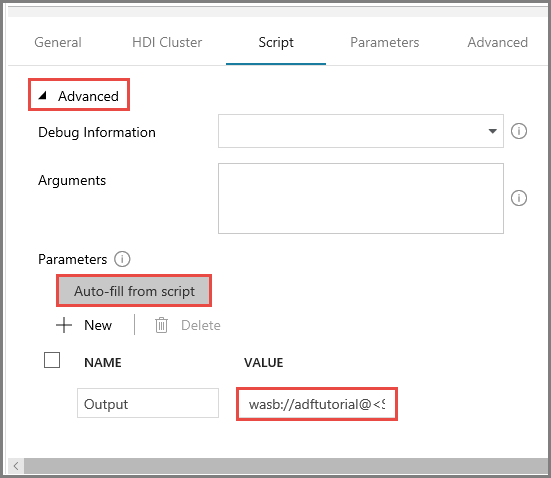
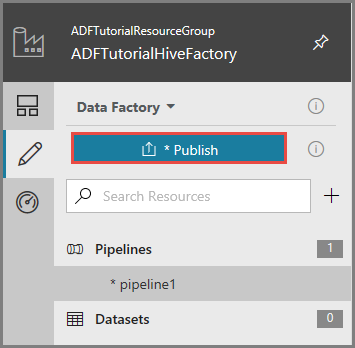
Per pubblicare gli elementi in Data Factory, fare clic su Pubblica.
Attivare un'esecuzione della pipeline
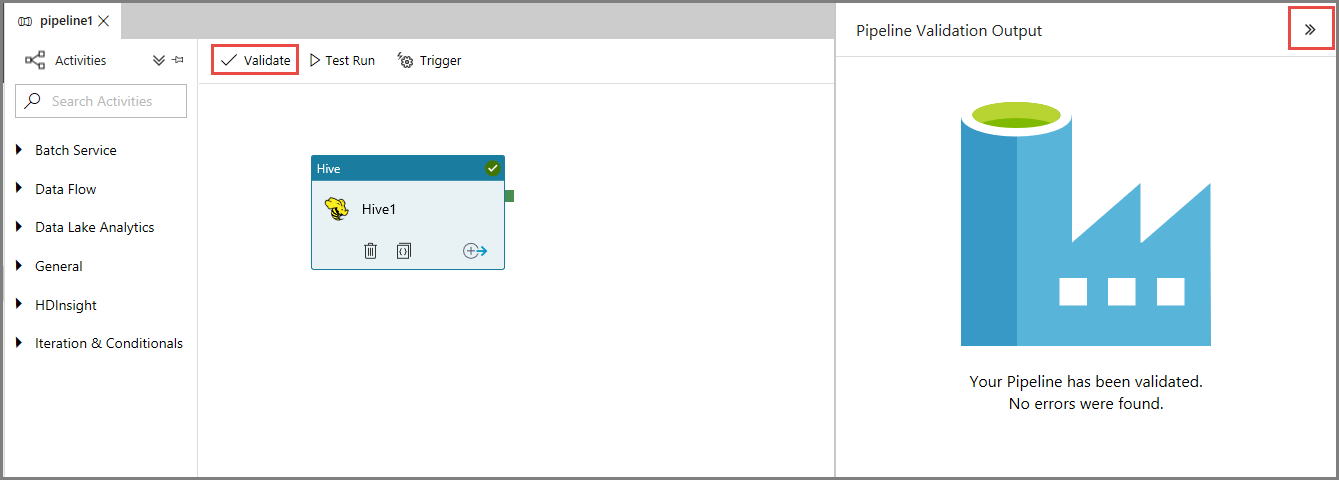
Per prima cosa, convalidare la pipeline facendo clic sul pulsante Convalida sulla barra degli strumenti. Chiudere la finestra Output convalida pipeline facendo clic sulla freccia destra (>>).
Per attivare un'esecuzione della pipeline, fare clic su Trigger sulla barra degli strumenti e quindi su Trigger Now (Attiva adesso).
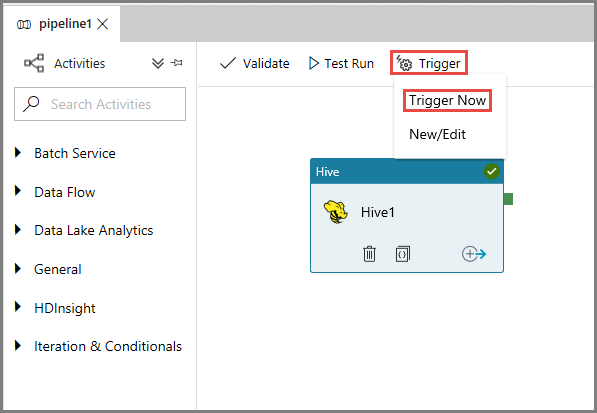
Monitorare l'esecuzione della pipeline
Passare alla scheda Monitoraggio a sinistra. Nell'elenco Pipeline Runs (Esecuzioni di pipeline) verrà visualizzata un'esecuzione della pipeline.
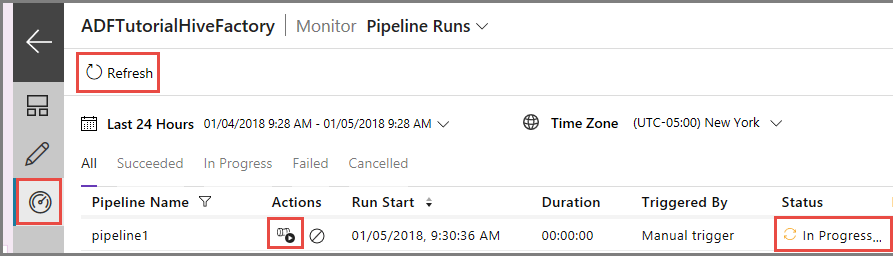
Per aggiornare l'elenco, fare clic su Aggiorna.
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, fare clic su View Activity Runs (Visualizza le esecuzioni di attività) nella colonna Azioni. Gli altri collegamenti ad azioni riguardano l'arresto e la riesecuzione della pipeline.
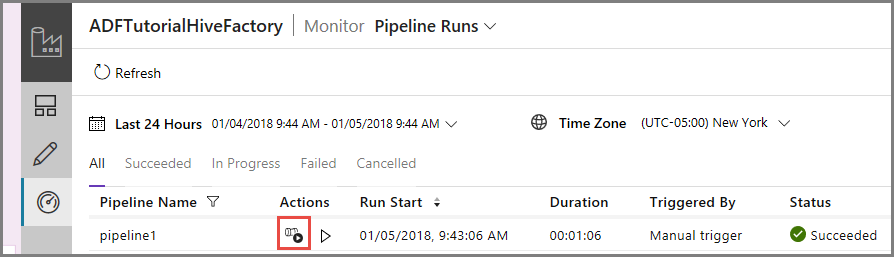
Verrà visualizzata una sola esecuzione di attività perché la pipeline contiene una sola attività, di tipo HDInsightHive. Per tornare alla visualizzazione precedente, fare clic sul collegamento Pipeline in alto.
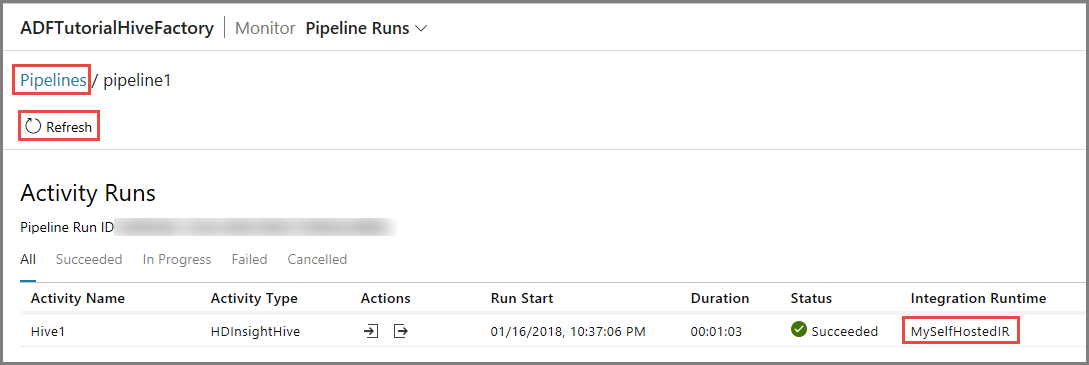
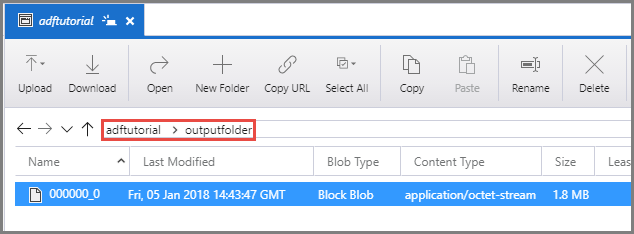
Verificare che venga visualizzato un file di output in outputfolder nel contenitore adftutorial.
Contenuto correlato
In questa esercitazione sono stati eseguiti i passaggi seguenti:
- Creare una data factory.
- Creare un runtime di integrazione self-hosted
- Creare servizi collegati Archiviazione di Azure e Azure HDInsight.
- Creare una pipeline con un'attività Hive.
- Attivare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline
- Verificare l'output
Passare all'esercitazione successiva per informazioni sulla trasformazione dei dati usando un cluster Spark in Azure: