Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Il data wrangling in data factory consente di creare mash-up interattivi Power Query in modo nativo in Azure Data Factory e quindi di eseguirli su larga scala all'interno di una pipeline di Azure Data Factory.
Creare un'attività di Power Query
Esistono due modi per creare un Power Query in Azure Data Factory. Un modo consiste nel fare clic sull'icona con il segno più e selezionare Power Query nel riquadro delle risorse factory.
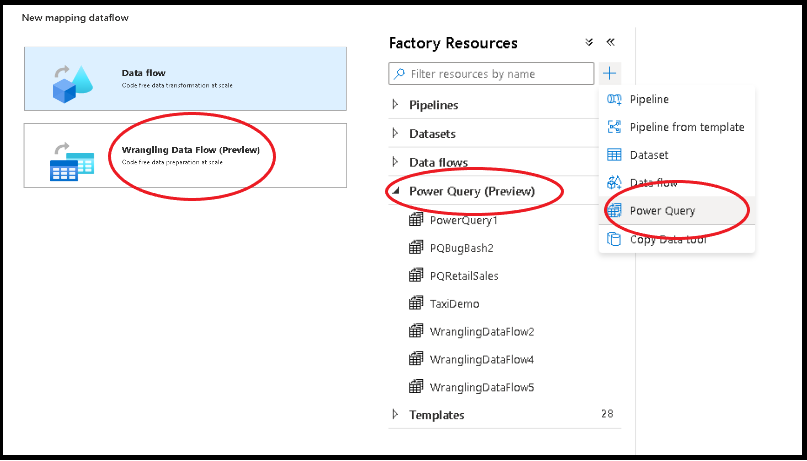
L'altro metodo è disponibile nel riquadro delle attività dell'area di disegno della pipeline. Aprire l'accordion Power Query e trascinare l'attività di Power Query nel canvas.
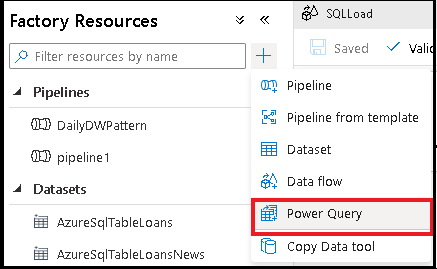
Creare un'attività di manipolazione dati con Power Query
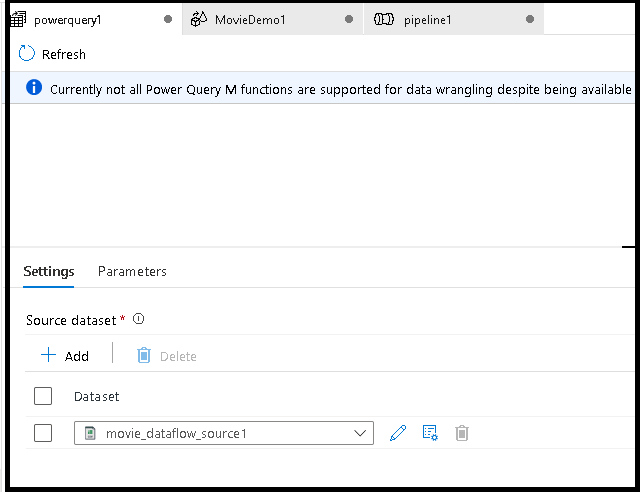
Aggiungere un set di dati Source per il mash-up Power Query. È possibile scegliere un set di dati esistente o crearne uno nuovo. Dopo aver salvato il mash-up, è possibile creare una pipeline, aggiungere l'attività di wrangling dei dati Power Query alla pipeline e selezionare un set di dati sink per indicare a ADF dove inserire i dati. Anche se è possibile scegliere uno o più set di dati di origine, al momento è consentito un solo sink. La scelta di un set di dati sink è facoltativa, ma è necessario almeno un set di dati di origine.
Fare clic su Crea per aprire l'editor mashup Power Query Online.
In primo luogo, si sceglierà un'origine del set di dati per l'editor mashup.
Dopo aver completato la compilazione del Power Query, è possibile salvarlo e quindi creare una pipeline. È necessario aggiungere il mashup come attività alla pipeline. Ovvero quando si creerà o si selezionerà il set di dati del sink per trasferire i dati. È anche possibile impostare le proprietà del set di dati del sink facendo clic sul secondo pulsante a destra del set di dati del sink. Ricordarsi di modificare l'opzione "partition option" in "Optimize" in "Single partition" (Partizione singola) se si vuole ottenere solo un singolo file di output.
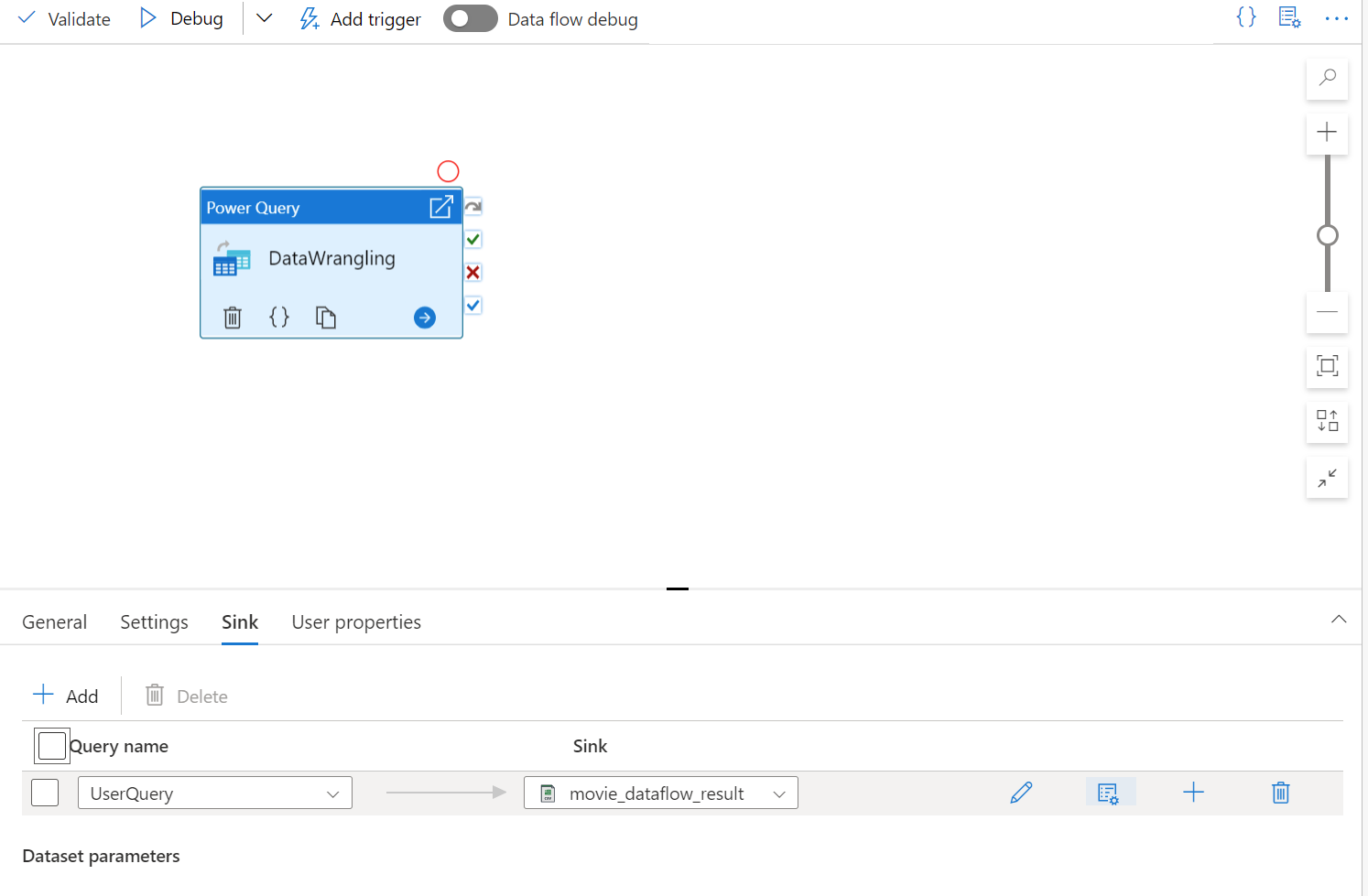
Crea il tuo Power Query per wrangling usando la preparazione dei dati senza effettuare alcuna codifica. Per l'elenco delle funzioni disponibili, vedere Funzioni di trasformazione. ADF converte lo script M in uno script del flusso di dati in modo da poter eseguire il Power Query su larga scala usando l'ambiente Spark del flusso di dati Azure Data Factory.
Screenshot che mostra il processo di progettazione della trasformazione dei dati in Power Query.
Esecuzione e monitoraggio di un'attività di data wrangling Power Query
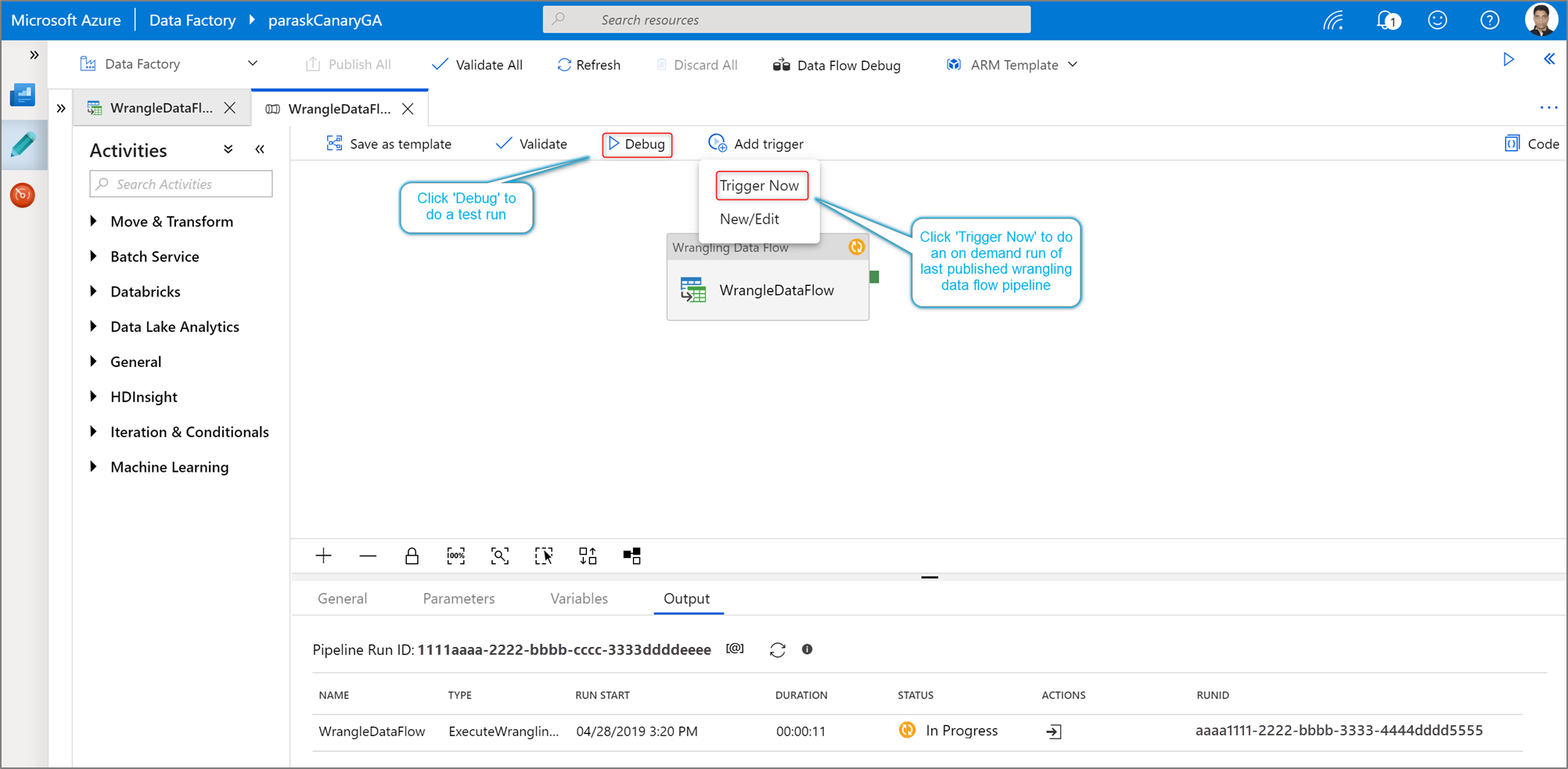
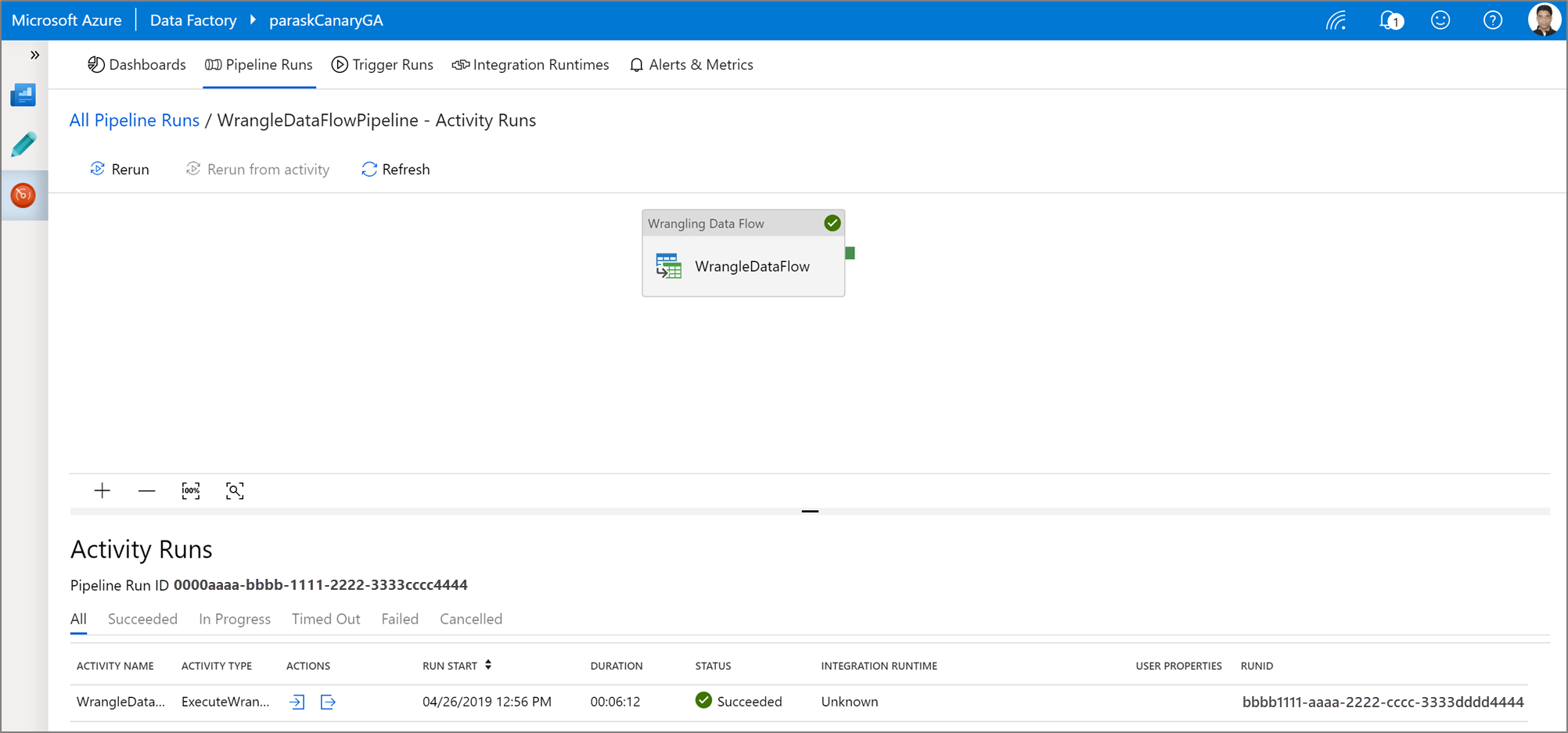
Per eseguire un'esecuzione di debug della pipeline di un'attività di Power Query, fare clic su Debug nell'area di disegno della pipeline. Dopo aver pubblicato la pipeline, Trigger esegue ora un'esecuzione su richiesta dell'ultima pipeline pubblicata. Power Query pipeline possono essere pianificate con tutti i trigger di Azure Data Factory esistenti.
Passare alla scheda Monitor per visualizzare l'output di un'esecuzione di attività Power Query attivata.
Contenuto correlato
Informazioni su come creare un flusso di dati di mapping.