Informazioni di riferimento sulla configurazione di calcolo
Questo articolo illustra tutte le impostazioni di configurazione disponibili nell'interfaccia utente di creazione calcolo. La maggior parte degli utenti crea calcolo usando i criteri assegnati, che limita le impostazioni configurabili. Se non viene visualizzata una particolare impostazione nell'interfaccia utente, il criterio selezionato non consente di configurare tale impostazione.
Le configurazioni e gli strumenti di gestione descritti in questo articolo si applicano sia al calcolo di tutti gli scopi che ai processi. Per altre considerazioni sulla configurazione del calcolo dei processi, vedere Usare l'ambiente di calcolo di Azure Databricks con i processi.
Politiche
I criteri sono un set di regole usate per limitare le opzioni di configurazione disponibili agli utenti quando creano il calcolo. Se un utente non ha il diritto di creazione di un cluster senza restrizioni, può creare il calcolo solo usando i criteri concessi.
Per creare il calcolo in base a un criterio, selezionare un criterio dal menu a discesa Criteri .
Per impostazione predefinita, tutti gli utenti hanno accesso ai criteri di calcolo personale, consentendo loro di creare risorse di calcolo a computer singolo. Se è necessario accedere a Personal Compute o a eventuali criteri aggiuntivi, contattare l'amministratore dell'area di lavoro.
Calcolo a nodo singolo o a più nodi
A seconda dei criteri, è possibile scegliere tra la creazione di un calcolo a nodo singolo o di un calcolo multinodo .
Il calcolo a nodo singolo è destinato ai processi che usano piccole quantità di dati o carichi di lavoro non distribuiti, ad esempio librerie di Machine Learning a nodo singolo. Il calcolo a più nodi deve essere usato per processi di grandi dimensioni con carichi di lavoro distribuiti.
Proprietà a nodo singolo
Un calcolo a nodo singolo ha le proprietà seguenti:
- Esegue Spark in locale.
- Il driver funge sia da master che da ruolo di lavoro, senza nodi di lavoro.
- Genera un thread executor per ogni core logico nel calcolo, meno 1 core per il driver.
- Salva tutti gli
stderroutput di log ,stdoutelog4jnel log del driver. - Non è possibile convertire in un ambiente di calcolo multinodo.
Selezione di un nodo singolo o multinodo
Si consideri il caso d'uso quando si decide tra un calcolo a nodo singolo o multinodo:
L'elaborazione dei dati su larga scala esaurisce le risorse in un singolo nodo di calcolo. Per questi carichi di lavoro, Databricks consiglia di usare un calcolo multinodo.
Il calcolo a nodo singolo non è progettato per essere condiviso. Per evitare conflitti di risorse, Databricks consiglia di usare un calcolo multinodo quando è necessario condividere l'ambiente di calcolo.
Un calcolo multinodo non può essere ridimensionato a 0 ruoli di lavoro. Usare invece un singolo nodo di calcolo.
Il calcolo a nodo singolo non è compatibile con l'isolamento del processo.
La pianificazione GPU non è abilitata nel calcolo a nodo singolo.
Nel calcolo a nodo singolo Spark non è in grado di leggere i file Parquet con una colonna con tipo definito dall'utente. Risultati del messaggio di errore seguenti:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Per risolvere questo problema, disabilitare il lettore Parquet nativo:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Modalità di accesso
La modalità di accesso è una funzionalità di sicurezza che determina chi può usare il calcolo e quali dati possono accedere tramite il calcolo. Ogni calcolo in Azure Databricks ha una modalità di accesso.
Databricks consiglia di usare la modalità di accesso condiviso per tutti i carichi di lavoro. Usare la modalità di accesso utente singolo solo se la funzionalità richiesta non è supportata dalla modalità di accesso condiviso.
| Modalità di accesso | Visibile all'utente | Supporto uc | Lingue supportate | Note |
|---|---|---|---|---|
| Un solo utente | Sempre | Sì | Python, SQL, Scala, R | Può essere assegnato a e usato da un singolo utente. Definito modalità di accesso assegnato in alcune aree di lavoro. |
| Condiviso | Sempre (piano Premium obbligatorio) | Sì | Python (in Databricks Runtime 11.3 LTS e versioni successive), SQL, Scala (nelle risorse di calcolo abilitate per Il catalogo unity con Databricks Runtime 13.3 LTS e versioni successive) | Può essere usato da più utenti con isolamento dei dati tra gli utenti. |
| Nessun isolamento condiviso | Gli amministratori possono nascondere questa modalità di accesso applicando l'isolamento utente nella pagina delle impostazioni di amministrazione. | No | Python, SQL, Scala, R | È disponibile un'impostazione a livello di account correlata per Nessun calcolo condiviso isolamento. |
| Personalizzazione | Nascosto (per tutte le nuove risorse di calcolo) | No | Python, SQL, Scala, R | Questa opzione viene visualizzata solo se si dispone di risorse di calcolo esistenti senza una modalità di accesso specificata. |
È possibile aggiornare un ambiente di calcolo esistente per soddisfare i requisiti del catalogo Unity impostandone la modalità di accesso su Utente singolo o Condiviso.
Nota
In Databricks Runtime 13.3 LTS e versioni successive sono supportati script e librerie init in tutte le modalità di accesso. I requisiti e il supporto variano. Vedere Dove è possibile installare gli script init ele librerie con ambito cluster.
Versioni di Databricks Runtime
Databricks Runtime è il set di componenti di base eseguiti nel calcolo. Selezionare il runtime usando il menu a discesa Versione di Databricks Runtime. Per informazioni dettagliate sulle versioni specifiche di Databricks Runtime, vedere Versioni e compatibilità delle note sulla versione di Databricks Runtime. Tutte le versioni includono Apache Spark. Databricks consiglia quanto segue:
- Per il calcolo all-purpose, usare la versione più recente per assicurarsi di avere le ottimizzazioni più recenti e la compatibilità più aggiornata tra il codice e i pacchetti precaricati.
- Per il calcolo dei processi che eseguono carichi di lavoro operativi, è consigliabile usare la versione di Databricks Runtime LTS (Long Term Support). L'uso della versione LTS garantisce che non si verifichino problemi di compatibilità e possa testare accuratamente il carico di lavoro prima dell'aggiornamento.
- Per i casi d'uso di Data Science e Machine Learning, prendere in considerazione la versione di Databricks Runtime ML.
Usare l'accelerazione Photon
Photon è abilitato per impostazione predefinita nel calcolo che esegue Databricks Runtime 9.1 LTS e versioni successive.
Per abilitare o disabilitare l'accelerazione Photon, selezionare la casella di controllo Usa accelerazione foton. Per altre informazioni su Photon, vedi Che cos'è Photon?.
Tipi di nodo del ruolo di lavoro e driver
Il calcolo è costituito da un nodo driver e da zero o più nodi di lavoro. È possibile selezionare tipi di istanza del provider di servizi cloud separati per i nodi driver e di lavoro, anche se per impostazione predefinita il nodo driver usa lo stesso tipo di istanza del nodo di lavoro. Diverse famiglie di tipi di istanza si adattano a casi d'uso diversi, ad esempio carichi di lavoro a elevato utilizzo di memoria o a elevato utilizzo di calcolo.
È anche possibile selezionare un pool da usare come nodo di lavoro o driver. Usare solo un pool con istanze spot come tipo di lavoro. Selezionare un tipo di driver su richiesta separato per impedire che il driver venga recuperato. Vedere Che cosa sono i pool di Azure Databricks?.
Tipo di lavoratore
Nel calcolo a più nodi, i nodi di lavoro eseguono gli executor Spark e altri servizi necessari per il corretto funzionamento del calcolo. Quando si distribuisce il carico di lavoro con Spark, tutte le elaborazioni distribuite vengono eseguite nei nodi di lavoro. Azure Databricks esegue un executor per ogni nodo di lavoro. Di conseguenza, i termini executor e worker vengono usati in modo intercambiabile nel contesto dell'architettura di Databricks.
Suggerimento
Per eseguire un processo Spark, è necessario almeno un nodo di lavoro. Se il calcolo ha zero ruoli di lavoro, è possibile eseguire comandi non Spark nel nodo del driver, ma i comandi Spark avranno esito negativo.
Indirizzi IP del nodo di lavoro
Azure Databricks avvia nodi di lavoro con due indirizzi IP privati ciascuno. L'indirizzo IP privato primario del nodo ospita il traffico interno di Azure Databricks. L'indirizzo IP privato secondario viene usato dal contenitore Spark per la comunicazione all'interno del cluster. Questo modello consente ad Azure Databricks di fornire l'isolamento tra più risorse di calcolo nella stessa area di lavoro.
Tipo di driver
Il nodo driver gestisce le informazioni sullo stato di tutti i notebook collegati al calcolo. Il nodo driver gestisce anche SparkContext, interpreta tutti i comandi eseguiti da un notebook o da una libreria nel calcolo ed esegue il master Apache Spark che si coordina con gli executor spark.
Il valore predefinito del tipo di nodo driver corrisponde a quello del tipo di nodo di lavoro. È possibile scegliere un tipo di nodo driver di dimensioni maggiori con maggiore memoria se si prevede di ottenere collect() molti dati dai ruoli di lavoro Spark e analizzarli nel notebook.
Suggerimento
Poiché il nodo driver mantiene tutte le informazioni sullo stato dei notebook collegati, assicurarsi di scollegare i notebook inutilizzati dal nodo driver.
Tipi di istanza GPU
Per le attività complesse a livello di calcolo che richiedono prestazioni elevate, ad esempio quelle associate all'apprendimento avanzato, Azure Databricks supporta l'accelerazione del calcolo con unità di elaborazione grafica (GPU). Per altre informazioni, vedere Calcolo abilitato per GPU.
Macchine virtuali di confidential computing di Azure
I tipi di macchina virtuale confidential computing di Azure impediscono l'accesso non autorizzato ai dati mentre sono in uso, incluso l'operatore cloud. Questo tipo di macchina virtuale è vantaggioso per settori e aree altamente regolamentati, nonché per le aziende con dati sensibili nel cloud. Per altre informazioni sul confidential computing di Azure, vedere Confidential computing di Azure.
Per eseguire i carichi di lavoro usando le macchine virtuali di confidential computing di Azure, selezionare tra i tipi di VM della serie DC o EC negli elenchi a discesa ruolo di lavoro e nodo driver. Vedere Opzioni della macchina virtuale riservata di Azure.
Istanze spot
Per risparmiare sui costi, è possibile scegliere di usare istanze spot, note anche come macchine virtuali spot di Azure selezionando la casella di controllo Istanze spot.

La prima istanza sarà sempre su richiesta (il nodo driver è sempre su richiesta) e le istanze successive saranno istanze spot.
Se le istanze vengono rimosse a causa di un'indisponibilità, Azure Databricks tenterà di acquisire nuove istanze spot per sostituire le istanze rimosse. Se non è possibile acquisire istanze spot, le istanze su richiesta vengono distribuite per sostituire le istanze rimosse. Inoltre, quando vengono aggiunti nuovi nodi al calcolo esistente, Azure Databricks tenterà di acquisire istanze spot per tali nodi.
Abilitare la scalabilità automatica
Quando si seleziona Abilita scalabilità automatica, è possibile specificare un numero minimo e massimo di ruoli di lavoro per il calcolo. Databricks sceglie quindi il numero appropriato di ruoli di lavoro necessari per eseguire il processo.
Per impostare il numero minimo e il numero massimo di ruoli di lavoro tra cui il calcolo verrà ridimensionato automaticamente, usare i campi Min worker e Max worker accanto all'elenco a discesa Tipo di lavoro.
Se non si abilita la scalabilità automatica, immettere un numero fisso di ruoli di lavoro nel campo Ruoli di lavoro accanto all'elenco a discesa Tipo di lavoro.
Nota
Quando il calcolo è in esecuzione, nella pagina dei dettagli di calcolo viene visualizzato il numero di ruoli di lavoro allocati. È possibile confrontare il numero di ruoli di lavoro allocati con la configurazione del ruolo di lavoro e apportare modifiche in base alle esigenze.
Vantaggi della scalabilità automatica
Con la scalabilità automatica, Azure Databricks rialloca dinamicamente i ruoli di lavoro per tenere conto delle caratteristiche del processo. Alcune parti della pipeline possono essere più impegnative dal punto di vista del calcolo rispetto ad altre e Databricks aggiunge automaticamente altri ruoli di lavoro durante queste fasi del processo e li rimuove quando non sono più necessari.
La scalabilità automatica semplifica l'utilizzo elevato perché non è necessario effettuare il provisioning del calcolo in modo che corrisponda a un carico di lavoro. Questo vale soprattutto per i carichi di lavoro i cui requisiti cambiano nel tempo ,ad esempio l'esplorazione di un set di dati durante il corso di un giorno, ma possono essere applicati anche a un carico di lavoro monouso più breve i cui requisiti di provisioning sono sconosciuti. La scalabilità automatica offre quindi due vantaggi:
- I carichi di lavoro possono essere eseguiti più velocemente rispetto a un calcolo con provisioning inferiore alle dimensioni costanti.
- La scalabilità automatica può ridurre i costi complessivi rispetto a un calcolo con dimensioni statiche.
A seconda delle dimensioni costanti del calcolo e del carico di lavoro, la scalabilità automatica offre uno o entrambi questi vantaggi contemporaneamente. Le dimensioni di calcolo possono superare il numero minimo di ruoli di lavoro selezionati quando il provider di servizi cloud termina le istanze. In questo caso, Azure Databricks ritenta continuamente il provisioning delle istanze per mantenere il numero minimo di ruoli di lavoro.
Nota
La scalabilità automatica non è disponibile per i processi spark-submit.
Nota
Il ridimensionamento automatico delle risorse di calcolo presenta limitazioni per ridurre le dimensioni del cluster per i carichi di lavoro Structured Streaming. Databricks consiglia di usare tabelle live Delta con scalabilità automatica avanzata per i carichi di lavoro di streaming. Vedere Ottimizzare l'utilizzo del cluster delle pipeline di tabelle live Delta con scalabilità automatica avanzata.
Comportamento del ridimensionamento automatico
L'area di lavoro nel piano Premium usa la scalabilità automatica ottimizzata. Le aree di lavoro nel piano tariffario standard usano la scalabilità automatica standard.
La scalabilità automatica ottimizzata presenta le caratteristiche seguenti:
- Aumenta da min a max in 2 passaggi.
- Può ridurre le prestazioni, anche se il calcolo non è inattivo, esaminando lo stato del file casuale.
- Riduce le prestazioni in base a una percentuale di nodi correnti.
- Nel calcolo del processo, riduce le prestazioni se il calcolo è sottoutilizzato negli ultimi 40 secondi.
- Nel calcolo all-purpose, riduce le prestazioni se il calcolo è sottoutilizzato negli ultimi 150 secondi.
- La
spark.databricks.aggressiveWindowDownSproprietà di configurazione di Spark specifica in secondi la frequenza con cui il calcolo prende decisioni di ridimensionamento. Aumentando il valore, il calcolo viene ridotto più lentamente. Il valore massimo è 600.
La scalabilità automatica standard viene usata nelle aree di lavoro del piano standard. La scalabilità automatica standard presenta le caratteristiche seguenti:
- Inizia aggiungendo 8 nodi. Quindi aumenta in modo esponenziale, eseguendo tutti i passaggi necessari per raggiungere il numero massimo.
- Riduce le prestazioni quando il 90% dei nodi non è occupato per 10 minuti e il calcolo è inattivo per almeno 30 secondi.
- Riduce in modo esponenziale, a partire da 1 nodo.
Scalabilità automatica con pool
Se si collega il calcolo a un pool, tenere presente quanto segue:
- Assicurarsi che le dimensioni di calcolo richieste siano minori o uguali al numero minimo di istanze inattive nel pool. Se è maggiore, il tempo di avvio del calcolo sarà equivalente al calcolo che non usa un pool.
- Assicurarsi che le dimensioni massime di calcolo siano minori o uguali alla capacità massima del pool. Se è più grande, la creazione del calcolo avrà esito negativo.
Esempio di scalabilità automatica
Se si riconfigura un calcolo statico per la scalabilità automatica, Azure Databricks ridimensiona immediatamente il calcolo entro i limiti minimo e massimo e quindi avvia la scalabilità automatica. Ad esempio, la tabella seguente illustra cosa accade al calcolo con una determinata dimensione iniziale se si riconfigura il calcolo per la scalabilità automatica tra 5 e 10 nodi.
| Dimensioni iniziali | Dimensioni dopo la riconfigurazione |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Abilitare la scalabilità automatica dell'archiviazione locale
Spesso può essere difficile stimare la quantità di spazio su disco che un determinato processo richiederà. Per evitare di dover stimare il numero di gigabyte di disco gestito da collegare al calcolo in fase di creazione, Azure Databricks abilita automaticamente la scalabilità automatica dell'archiviazione locale in tutte le risorse di calcolo di Azure Databricks.
Con la scalabilità automatica dell'archiviazione locale, Azure Databricks monitora la quantità di spazio disponibile su disco nei ruoli di lavoro Spark dell'ambiente di calcolo. Se un ruolo di lavoro inizia a essere troppo basso su disco, Databricks collega automaticamente un nuovo disco gestito al ruolo di lavoro prima che esaurisca lo spazio su disco. I dischi vengono collegati fino a un limite di 5 TB di spazio totale su disco per macchina virtuale (inclusa l'archiviazione locale iniziale della macchina virtuale).
I dischi gestiti collegati a una macchina virtuale vengono scollegati solo quando la macchina virtuale viene restituita ad Azure. Ovvero, i dischi gestiti non vengono mai scollegati da una macchina virtuale, purché facciano parte di un ambiente di calcolo in esecuzione. Per ridurre l'utilizzo del disco gestito, Azure Databricks consiglia di usare questa funzionalità nel calcolo configurato con il calcolo con scalabilità automatica o terminazione automatica.
Crittografia dischi locali
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Alcuni tipi di istanza usati per eseguire il calcolo possono avere dischi collegati in locale. Azure Databricks può archiviare dati casuali o dati temporanei in questi dischi collegati localmente. Per assicurarsi che tutti i dati inattivi siano crittografati per tutti i tipi di archiviazione, inclusi i dati casuali archiviati temporaneamente nei dischi locali dell'ambiente di calcolo, è possibile abilitare la crittografia del disco locale.
Importante
I carichi di lavoro possono essere eseguiti più lentamente a causa dell'impatto sulle prestazioni della lettura e della scrittura di dati crittografati da e verso volumi locali.
Quando la crittografia del disco locale è abilitata, Azure Databricks genera una chiave di crittografia in locale univoca per ogni nodo di calcolo e viene usata per crittografare tutti i dati archiviati nei dischi locali. L'ambito della chiave è locale per ogni nodo di calcolo e viene eliminato definitivamente insieme al nodo di calcolo stesso. Durante la sua durata, la chiave risiede nella memoria per la crittografia e la decrittografia e viene archiviata crittografata sul disco.
Per abilitare la crittografia del disco locale, è necessario usare l'API Clusters. Durante la creazione o la modifica del calcolo, impostare su enable_local_disk_encryptiontrue.
Terminazione automatica
È possibile impostare la terminazione automatica per il calcolo. Durante la creazione del calcolo, specificare un periodo di inattività in minuti dopo il quale si vuole che il calcolo termini.
Se la differenza tra l'ora corrente e l'ultima esecuzione del comando nel calcolo è maggiore del periodo di inattività specificato, Azure Databricks termina automaticamente tale calcolo. Per altre informazioni sulla terminazione di calcolo, vedere Terminare un calcolo.
Tag
I tag consentono di monitorare facilmente il costo delle risorse cloud usate da vari gruppi nell'organizzazione. Specificare i tag come coppie chiave-valore quando si crea il calcolo e Azure Databricks applica questi tag alle risorse cloud, ad esempio macchine virtuali e volumi di dischi, nonché report di utilizzo DBU.
Per le risorse di calcolo avviate dai pool, i tag personalizzati vengono applicati solo ai report di utilizzo DBU e non vengono propagati alle risorse cloud.
Per informazioni dettagliate sul funzionamento dei tipi di tag di calcolo e pool, vedere Monitorare l'uso dei tag
Per aggiungere tag al calcolo:
- Nella sezione Tag aggiungere una coppia chiave-valore per ogni tag personalizzato.
- Fare clic su Aggiungi.
Configurazione di Spark
Per ottimizzare i processi Spark, è possibile fornire proprietà di configurazione Spark personalizzate.
Nella pagina configurazione calcolo fare clic sull'interruttore Opzioni avanzate.
Fare clic sulla scheda Spark .
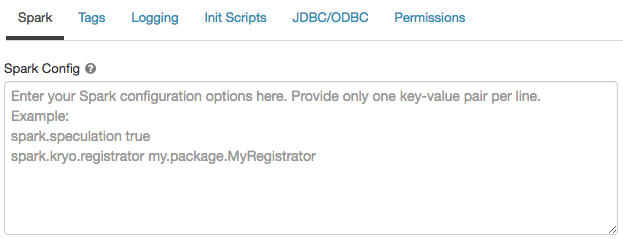
Nella configurazione di Spark immettere le proprietà di configurazione come una coppia chiave-valore per riga.
Quando si configura il calcolo usando l'API Clusters, impostare le proprietà Spark nel spark_conf campo nell'API di creazione del cluster o nell'API del cluster di aggiornamento.
Per applicare le configurazioni Spark nel calcolo, gli amministratori dell'area di lavoro possono usare i criteri di calcolo.
Recuperare una proprietà di configurazione spark da un segreto
Databricks consiglia di archiviare informazioni riservate, ad esempio password, in un segreto anziché in testo non crittografato. Per fare riferimento a un segreto nella configurazione di Spark, usare la sintassi seguente:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Ad esempio, per impostare una proprietà di configurazione Spark denominata password sul valore del segreto archiviato in secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Per altre informazioni, vedere Sintassi per fare riferimento ai segreti in una proprietà di configurazione Spark o in una variabile di ambiente.
Accesso SSH alle risorse di calcolo
Per motivi di sicurezza, in Azure Databricks la porta SSH viene chiusa per impostazione predefinita. Per abilitare l'accesso SSH ai cluster Spark, vedere SSH per il nodo driver.
Nota
È possibile abilitare SSH solo se l'area di lavoro viene distribuita nella propria rete virtuale di Azure.
Variabili di ambiente
Configurare variabili di ambiente personalizzate a cui è possibile accedere dagli script init in esecuzione nel calcolo. Databricks fornisce anche variabili di ambiente predefinite che è possibile usare negli script init. Non è possibile eseguire l'override di queste variabili di ambiente predefinite.
Nella pagina configurazione calcolo fare clic sull'interruttore Opzioni avanzate.
Fare clic sulla scheda Spark .
Impostare le variabili di ambiente nel campo Variabili di ambiente.
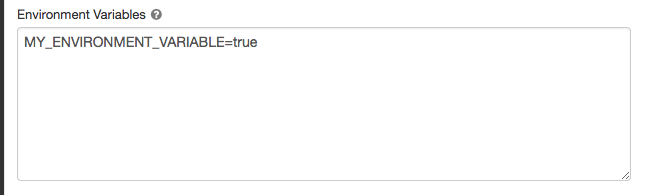
È anche possibile impostare le variabili di ambiente usando il spark_env_vars campo nell'API Di creazione di un cluster o nell'API del cluster di aggiornamento.
Recapito dei log di calcolo
Quando si crea il calcolo, è possibile specificare un percorso per recapitare i log per il nodo del driver Spark, i nodi di lavoro e gli eventi. I log vengono recapitati ogni cinque minuti e archiviati ogni ora nella destinazione scelta. Quando un calcolo viene terminato, Azure Databricks garantisce di recapitare tutti i log generati fino alla chiusura del calcolo.
La destinazione dei log dipende da cluster_id. Se la destinazione specificata è dbfs:/cluster-log-delivery, i log di calcolo per 0630-191345-leap375 vengono recapitati a dbfs:/cluster-log-delivery/0630-191345-leap375.
Per configurare il percorso di recapito dei log:
- Nella pagina calcolo fare clic sull'interruttore Opzioni avanzate.
- Fare clic sulla scheda Registrazione .
- Selezionare un tipo di destinazione.
- Immettere il percorso del log di calcolo.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per