Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità è disponibile in anteprima pubblica. Per informazioni sull'idoneità e l'abilitazione, vedere Abilitare il calcolo serverless.
Questo articolo illustra come usare il calcolo serverless per i notebook. Per informazioni sull'uso del calcolo serverless per i flussi di lavoro, vedere Eseguire il processo di Azure Databricks con calcolo serverless per i flussi di lavoro.
Per informazioni sui prezzi, vedere Prezzi di Databricks.
Requisiti
L'area di lavoro deve essere abilitata per Il catalogo unity.
L'area di lavoro deve trovarsi in un'area supportata. Vedere Aree di Azure Databricks.
L'account deve essere abilitato per il calcolo serverless. Vedere Abilitare l'ambiente di calcolo serverless.
Collegare un notebook a un ambiente di calcolo serverless
Se l'area di lavoro è abilitata per il calcolo interattivo serverless, tutti gli utenti dell'area di lavoro hanno accesso all'ambiente di calcolo serverless per i notebook. Non sono necessarie autorizzazioni aggiuntive.
Per connettersi al calcolo serverless, fare clic sul menu a discesa Connetti nel notebook e selezionare Serverless. Per i nuovi notebook, per impostazione predefinita il calcolo collegato viene impostato automaticamente su serverless durante l'esecuzione del codice se non è stata selezionata alcuna altra risorsa.
Installare le dipendenze del notebook
È possibile installare le dipendenze python per i notebook serverless usando il pannello laterale Ambiente , che offre un'unica posizione in cui modificare, visualizzare ed esportare i requisiti della libreria per un notebook. Queste dipendenze possono essere aggiunte usando un ambiente di base o singolarmente.
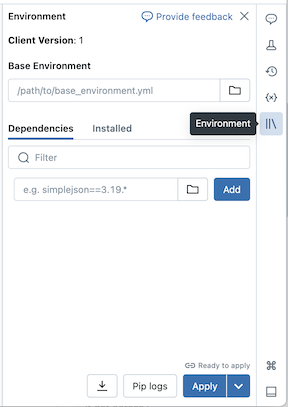
Configurare un ambiente di base
Un ambiente di base è un file YAML archiviato come file dell'area di lavoro o in un volume di Catalogo Unity che specifica dipendenze di ambiente aggiuntive. Gli ambienti di base possono essere condivisi tra notebook. Per configurare un ambiente di base:
Creare un file YAML che definisce le impostazioni per un ambiente virtuale Python. L'esempio YAML seguente, basato sulla specifica dell'ambiente dei progetti MLflow, definisce un ambiente di base con alcune dipendenze della libreria:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Caricare il file YAML come file dell'area di lavoro o in un volume del catalogo Unity. Vedere Importare un file o Caricare file in un volume del catalogo Unity.
A destra del notebook fare clic sul
 pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.
pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.Nel campo Ambiente di base immettere il percorso del file YAML caricato o selezionarlo e selezionarlo.
Fare clic su Applica. In questo modo vengono installate le dipendenze nell'ambiente virtuale del notebook e viene riavviato il processo Python.
Gli utenti possono eseguire l'override delle dipendenze specificate nell'ambiente di base installando singolarmente le dipendenze.
Aggiungere le dipendenze singolarmente
È anche possibile installare le dipendenze in un notebook connesso al calcolo serverless usando la scheda Dipendenze del pannello Ambiente :
- A destra del notebook fare clic sul pulsante per espandere il pannello Ambiente . Questo pulsante viene visualizzato solo quando un notebook è connesso al calcolo serverless.
- Nella sezione Dipendenze fare clic su Aggiungi dipendenza e immettere il percorso della dipendenza della libreria nel campo . È possibile specificare una dipendenza in qualsiasi formato valido in un file di requirements.txt .
- Fare clic su Applica. In questo modo vengono installate le dipendenze nell'ambiente virtuale del notebook e viene riavviato il processo Python.
Nota
Un processo che usa il calcolo serverless installerà la specifica dell'ambiente del notebook prima di eseguire il codice del notebook. Ciò significa che non è necessario aggiungere dipendenze durante la pianificazione dei notebook come processi. Vedere Configurare ambienti e dipendenze dei notebook.
Visualizzare le dipendenze installate e i log pip
Per visualizzare le dipendenze installate, fare clic su Installato nel pannello laterale Ambienti per un notebook. I log di installazione pip per l'ambiente notebook sono disponibili anche facendo clic su Pip logs (Log pip) nella parte inferiore del pannello.
Reimpostare l'ambiente
Se il notebook è connesso al calcolo serverless, Databricks memorizza automaticamente nella cache il contenuto dell'ambiente virtuale del notebook. Ciò significa che in genere non è necessario reinstallare le dipendenze Python specificate nel pannello Ambiente quando si apre un notebook esistente, anche se è stato disconnesso a causa dell'inattività.
La memorizzazione nella cache dell'ambiente virtuale Python si applica anche ai processi. Ciò significa che le esecuzioni successive dei processi sono più veloci in quanto le dipendenze necessarie sono già disponibili.
Nota
Se si modifica l'implementazione di un pacchetto Python personalizzato usato in un processo serverless, è necessario aggiornare anche il numero di versione per i processi per selezionare l'implementazione più recente.
Per cancellare la cache dell'ambiente ed eseguire una nuova installazione delle dipendenze specificate nel pannello Ambiente di un notebook collegato al calcolo serverless, fare clic sulla freccia accanto a Applica e quindi fare clic su Reimposta ambiente.
Nota
Reimpostare l'ambiente virtuale se si installano pacchetti che interrompono o modificano il notebook principale o l'ambiente Apache Spark. Scollegare il notebook dal calcolo serverless e ricollegarlo non cancella necessariamente l'intera cache dell'ambiente.
Visualizzare informazioni dettagliate sulle query
Il calcolo serverless per notebook e flussi di lavoro usa informazioni dettagliate sulle query per valutare le prestazioni di esecuzione di Spark. Dopo aver eseguito una cella in un notebook, è possibile visualizzare informazioni dettagliate correlate alle query SQL e Python facendo clic sul collegamento Visualizza prestazioni .
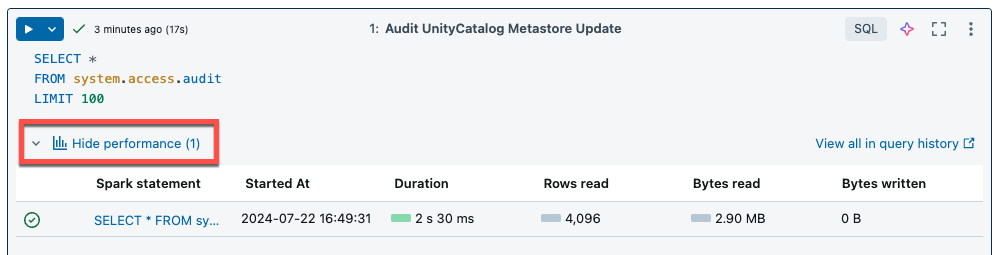
È possibile fare clic su una qualsiasi istruzione Spark per visualizzare le metriche di query. Da qui è possibile fare clic su Visualizza profilo di query per visualizzare una visualizzazione dell'esecuzione della query. Per altre informazioni sui profili di query, vedere Profilo di query.
Nota
Per visualizzare informazioni dettagliate sulle prestazioni per le esecuzioni del processo, vedere Visualizzare informazioni dettagliate sulle query di esecuzione del processo.
Cronologia delle query
Tutte le query eseguite nel calcolo serverless verranno registrate anche nella pagina della cronologia delle query dell'area di lavoro. Per informazioni sulla cronologia delle query, vedere Cronologia query.
Limitazioni delle informazioni dettagliate sulle query
- Il profilo di query è disponibile solo dopo il termine dell'esecuzione della query.
- Le metriche vengono aggiornate in tempo reale anche se il profilo di query non viene visualizzato durante l'esecuzione.
- Vengono trattati solo gli stati di query seguenti: RUNNING, CANCELED, FAILED, FINISHED.
- L'esecuzione di query non può essere annullata dalla pagina della cronologia query. Possono essere annullati nei notebook o nei processi.
- Le metriche verbose non sono disponibili.
- Download del profilo di query non disponibile.
- L'accesso all'interfaccia utente di Spark non è disponibile.
- Il testo dell'istruzione contiene solo l'ultima riga eseguita. Tuttavia, potrebbero essere presenti diverse righe che precedono questa riga che sono state eseguite come parte della stessa istruzione.
Limiti
Per un elenco delle limitazioni, vedere Limitazioni di calcolo serverless.