Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Le raccomandazioni per l'ottimizzazione manuale in questo articolo non si applicano alle tabelle gestite di Unity Catalog, che usano l'ottimizzazione automatica delle dimensioni dei file. Per le nuove tabelle, usare le tabelle gestite di Unity Catalog con le impostazioni predefinite.
In Databricks Runtime 13.3 e versioni successive Databricks consiglia di usare il clustering per il layout di tabella. Vedere Usare clustering liquido per le tabelle.
Databricks consiglia di usare l'ottimizzazione predittiva per l'esecuzione automatica di OPTIMIZE e VACUUM per le tabelle. Vedere Ottimizzazione predittiva per le tabelle gestite di Unity Catalog.
In Databricks Runtime 10.4 LTS e versioni successive, la compattazione automatica e le scritture ottimizzate sono sempre abilitate per le operazioni MERGE, UPDATE e DELETE. Non è possibile disabilitare questa funzionalità.
Sono disponibili opzioni per configurare manualmente o automaticamente le dimensioni del file di destinazione per le operazioni di scrittura e OPTIMIZE per altre operazioni. Azure Databricks ottimizza automaticamente molte di queste impostazioni e abilita funzionalità che migliorano automaticamente le prestazioni delle tabelle cercando di ottenere file di dimensioni appropriate.
Per le tabelle gestite di Unity Catalog, Databricks ottimizza automaticamente la maggior parte di queste configurazioni se si usa un'istanza di SQL Warehouse o Databricks Runtime 11.3 LTS o versione successiva.
Se stai aggiornando un carico di lavoro da Databricks Runtime 10.4 LTS o versioni precedenti, vedi Eseguire l'aggiornamento alla compattazione automatica in background.
Quando eseguire OPTIMIZE
La compattazione automatica e le scritture ottimizzate riducono ogni piccolo problema di file, ma non sono una sostituzione completa per OPTIMIZE. In particolare per le tabelle di dimensioni superiori a 1 TB, Databricks consiglia di eseguire OPTIMIZE in base a una pianificazione per consolidare ulteriormente i file. Databricks consiglia il clustering liquido per migliorare la capacità di ignorare dati irrilevanti. Quando il clustering liquido è abilitato, OPTIMIZE riorganizza automaticamente i dati in base alle chiavi di clustering. Vedere Usare clustering liquido per le tabelle.
Per le tabelle gestite di Unity Catalog, l'ottimizzazione predittiva viene eseguita OPTIMIZE automaticamente nelle tabelle con ottimizzazione predittiva abilitata.
Che cos'è l'ottimizzazione automatica in Azure Databricks?
Il termine ottimizzazione automatica viene talvolta usato per descrivere le funzionalità controllate dalle impostazioni autoOptimize.autoCompact e autoOptimize.optimizeWrite. Questo termine è stato ritirato a favore della descrizione di ogni impostazione singolarmente. Vedere Compattazione automatica e Scritture ottimizzate.
Compattazione automatica
La compattazione automatica combina file di piccole dimensioni all'interno delle partizioni di tabella per ridurre i piccoli problemi di file. Viene eseguito in modo sincrono nel cluster che esegue la scrittura, dopo l'esito positivo della scrittura e compatta solo i file che non sono stati compattati in precedenza.
La compattazione automatica e l'ottimizzazione predittiva sono funzionalità indipendenti che possono essere usate separatamente o insieme. La compattazione automatica viene eseguita nel cluster che esegue la scrittura, mentre l'ottimizzazione predittiva esegue operazioni di manutenzione in modo asincrono usando il calcolo serverless.
Usare le impostazioni seguenti per configurare la compattazione automatica:
| Impostazione | Delta | Iceberg | Description |
|---|---|---|---|
| Abilitare la compattazione automatica (proprietà della tabella) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Abilita la compattazione automatica a livello di tabella. |
| Abilitare la compattazione automatica (sessione Spark) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Abilita la compattazione automatica a livello di sessione. |
| Dimensioni massime del file di output | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Controlla le dimensioni del file di output di destinazione. |
| File minimi per attivare la compattazione | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Imposta il numero minimo di file di piccole dimensioni necessari in una partizione o in una tabella per attivare la compattazione automatica. |
Queste impostazioni accettano le opzioni seguenti:
| Opzioni | Comportamento |
|---|---|
auto (scelta consigliata) |
Regola le dimensioni del file di destinazione mentre rispetta altre funzionalità di ottimizzazione automatica. Richiede Databricks Runtime 10.4 LTS o versione successiva. |
legacy |
Alias per true. Richiede Databricks Runtime 10.4 LTS o versione successiva. |
true |
Usare 128 MB come dimensione del file di destinazione. Nessun ridimensionamento dinamico. |
false |
Disattiva la compattazione automatica. Può essere impostato a livello di sessione per eseguire l'override della compattazione automatica per tutte le tabelle modificate nel carico di lavoro. |
Nota
Azure Databricks consiglia di usare l'ottimizzazione automatica per controllare le dimensioni dei file di output in base alle dimensioni della tabella. Vedere Ridimensionamento automatico dei file in base alle dimensioni della tabella.
Scritture ottimizzate
Le scritture ottimizzate migliorano le dimensioni dei file durante la scrittura dei dati e favoriscono le successive letture nella tabella.
Le scritture ottimizzate sono più efficaci per le tabelle partizionate, in quanto riducono il numero di file di piccole dimensioni scritti in ogni partizione. La scrittura di meno file di grandi dimensioni è più efficiente rispetto alla scrittura di molti file di piccole dimensioni, ma potrebbe comunque verificarsi un aumento della latenza di scrittura perché i dati vengono riorganizzati prima della scrittura.
L'immagine seguente illustra il funzionamento delle scritture ottimizzate:
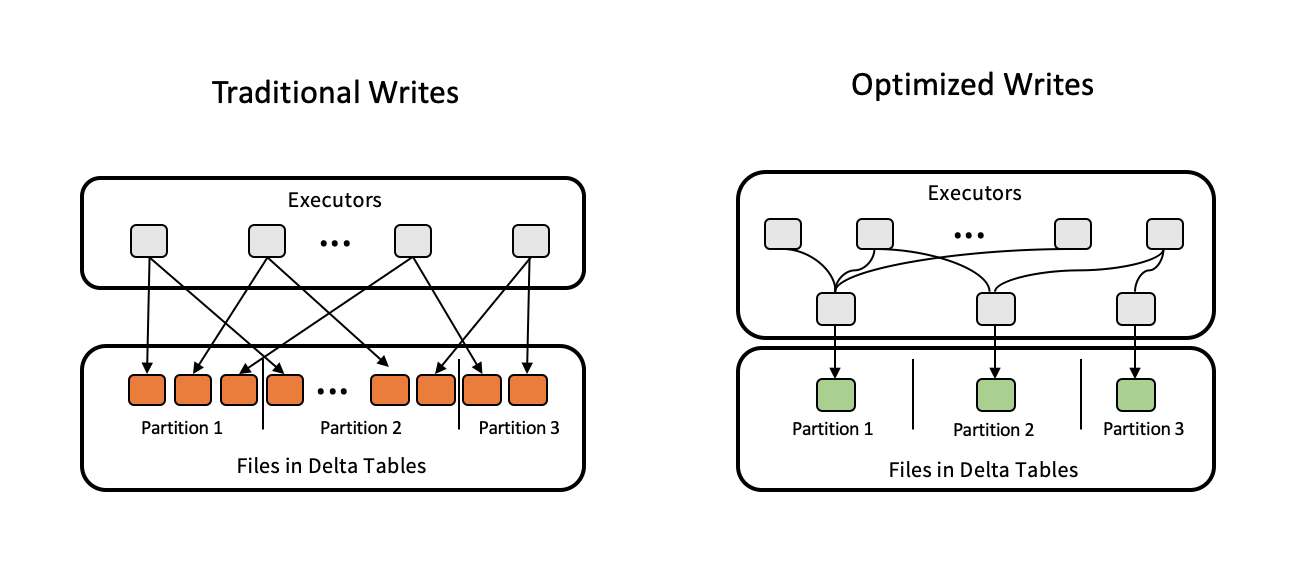
Nota
Potrebbe essere presente codice in esecuzione coalesce(n) o repartition(n) subito prima di scrivere i dati per controllare il numero di file scritti. Le scritture ottimizzate eliminano la necessità di usare questo modello.
Le scritture ottimizzate sono abilitate per impostazione predefinita per le operazioni seguenti in Databricks Runtime 9.1 LTS e versioni successive:
MERGE-
UPDATEcon sottoquery -
DELETEcon sottoquery
Le scritture ottimizzate sono anche abilitate per le istruzioni CTAS e le operazioni INSERT quando si utilizzano i SQL warehouse. In Databricks Runtime 13.3 LTS e versioni successive, tutte le tabelle registrate in Unity Catalog hanno le scritture ottimizzate abilitate per le istruzioni CTAS e le operazioni INSERT relative alle tabelle partizionate.
Le scritture ottimizzate possono essere abilitate a livello di tabella o sessione usando le impostazioni seguenti:
- Proprietà tabella:
autoOptimize.optimizeWrite - Impostazione sparkSession:
spark.databricks.delta.optimizeWrite.enabled(Delta) ospark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Queste impostazioni accettano le opzioni seguenti:
| Opzioni | Comportamento |
|---|---|
true |
Usare 128 MB come dimensione del file di destinazione. |
false |
Disattiva le scritture ottimizzate. Può essere impostato a livello di sessione per eseguire l'override della compattazione automatica per tutte le tabelle modificate nel carico di lavoro. |
Impostare le dimensioni di un file di destinazione
Se si desidera ottimizzare le dimensioni dei file nella tabella, impostare la proprietà della tabellatargetFileSize sulle dimensioni desiderate. Quando impostate, tutte le operazioni di ottimizzazione del layout dei dati fanno un tentativo, nel miglior modo possibile, di generare file delle dimensioni specificate, tra cui ottimizzazione, clustering liquido, compattazione automatica e scritture ottimizzate.
Nota
Quando si usano tabelle gestite di Unity Catalog e SQL Warehouses o Databricks Runtime 11.3 LTS e versioni successive, solo OPTIMIZE comandi rispettano l'impostazione targetFileSize.
| Proprietà | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Iceberg) |
Tipo: dimensioni in byte o unità superiori. Descrizione: dimensioni del file di destinazione. Ad esempio, 104857600 (byte) o 100mb.Valore predefinito: nessuno |
Per le tabelle esistenti, è possibile impostare e annullare l'impostazione delle proprietà usando il comando SQL ALTER TABLESET TBL PROPERTIES. È anche possibile impostare queste proprietà automaticamente durante la creazione di nuove tabelle usando configurazioni di sessione Spark. Per informazioni dettagliate, vedere Informazioni di riferimento sulle proprietà della tabella .
Ridimensionare automaticamente il file in base alle dimensioni della tabella
Per ridurre al minimo la necessità di ottimizzazione manuale, Azure Databricks ottimizza automaticamente le dimensioni del file delle tabelle in base alle dimensioni della tabella. Azure Databricks usa dimensioni di file più piccole per tabelle più piccole e dimensioni di file maggiori per tabelle più grandi, in modo che il numero di file nella tabella non sia troppo grande. Azure Databricks non esegue l'autotuning delle tabelle che hai ottimizzato con una dimensione obiettivo specifica.
Le dimensioni del file di destinazione si basano sulle dimensioni correnti della tabella. Per le tabelle inferiori a 2,56 TB, le dimensioni del file di destinazione con ottimizzazione automatica sono pari a 256 MB. Per le tabelle con dimensioni comprese tra 2,56 TB e 10 TB, le dimensioni di destinazione aumentano in modo lineare da 256 MB a 1 GB. Per le tabelle superiori a 10 TB, le dimensioni del file di destinazione sono 1 GB.
Nota
Quando le dimensioni del file di destinazione per una tabella aumentano, i file esistenti non vengono ottimizzati nuovamente in file di dimensioni maggiori tramite il OPTIMIZE comando . Una tabella di grandi dimensioni può quindi avere sempre alcuni file inferiori alle dimensioni di destinazione. Se è necessario ottimizzare anche i file più piccoli in file di dimensioni maggiori, è possibile configurare una dimensione fissa del file di destinazione per la tabella usando la targetFileSize proprietà table.
Quando una tabella viene scritta in modo incrementale, le dimensioni e i conteggi dei file di destinazione saranno vicini ai numeri seguenti, in base alle dimensioni della tabella. I conteggi dei file in questa tabella sono solo un esempio. I risultati effettivi saranno diversi a seconda di molti fattori.
| Dimensioni della tabella | Dimensioni del file di destinazione | Numero approssimativo di file nella tabella |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 terabyte (TB) | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Limitare le righe scritte in un file di dati
In alcuni casi, le tabelle con dati ristretti possono incontrare un errore in cui il numero di righe di un file di dati supera i limiti di supporto del formato Parquet. Per evitare questo errore, è possibile usare la configurazione spark.sql.files.maxRecordsPerFile di sessione SQL per specificare il numero massimo di record da scrivere in un singolo file per una tabella. La specifica di un valore pari a zero o un valore negativo non rappresenta alcun limite.
In Databricks Runtime 11.3 LTS e versioni successive è anche possibile usare l'opzione maxRecordsPerFile DataFrameWriter quando si usano le API dataframe per scrivere in una tabella. Quando maxRecordsPerFile viene specificato, il valore della configurazione spark.sql.files.maxRecordsPerFile della sessione SQL viene ignorato.
Nota
Databricks non consiglia l'uso di questa opzione a meno che non sia necessario evitare l'errore menzionato in precedenza. Questa impostazione potrebbe essere comunque necessaria per alcune tabelle gestite di Unity Catalog con dati molto stretti.
Aggiornare alla compattazione automatica in secondo piano
La compattazione automatica in background è disponibile per le tabelle gestite di Unity Catalog in Databricks Runtime 11.3 LTS e versioni successive. La compattazione automatica in background non richiede l'ottimizzazione predittiva. Quando si esegue la migrazione di un carico di lavoro o di una tabella legacy, eseguire le operazioni seguenti:
- Rimuovere la configurazione Spark
spark.databricks.delta.autoCompact.enabled(Delta) ospark.databricks.iceberg.autoCompact.enabled(Iceberg) dalle impostazioni di configurazione del cluster o del notebook. - Per ogni tabella, eseguire
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) oALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) per rimuovere le impostazioni di compattazione automatica legacy.
Dopo aver rimosso queste configurazioni legacy, verrà visualizzata la compattazione automatica in background attivata automaticamente per tutte le tabelle gestite di Unity Catalog.