Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'ottimizzazione predittiva esegue automaticamente OPTIMIZE, VACUUM e ANALYZE sulle tabelle gestite da Unity Catalog (Delta Lake e Iceberg) in Azure Databricks, eliminando la necessità di manutenzione manuale e il tempo dedicato al monitoraggio dei problemi di prestazioni.
Nota
L'ottimizzazione predittiva è abilitata per impostazione predefinita per gli account creati il 11 novembre 2024. Databricks abilita gli account esistenti con un'implementazione graduale. Questa implementazione dovrebbe essere completata entro agosto 2026. Per verificare se l'account è già abilitato, vedere Verificare se l'ottimizzazione predittiva è abilitata.
Con l'ottimizzazione predittiva abilitata, Databricks esegue automaticamente le operazioni seguenti:
- Identifica le tabelle che trarrebbero vantaggio dalle operazioni di manutenzione e accoda tali operazioni da eseguire.
- Raccoglie le statistiche quando i dati vengono scritti in una tabella gestita.
In questo modo si eliminano le esecuzioni di manutenzione non necessarie e il carico di controllo e risoluzione dei problemi delle prestazioni manualmente.
Databricks consiglia l'ottimizzazione predittiva per tutte le tabelle gestite di Unity Catalog. Ad esempio, il clustering liquido automatico usa l'ottimizzazione intelligente del layout dei dati in base ai modelli di utilizzo dei dati. Vedere Usare clustering liquido per le tabelle.
Quali operazioni vengono eseguite dall'ottimizzazione predittiva?
L'ottimizzazione predittiva esegue le operazioni seguenti nelle tabelle gestite di Unity Catalog:
| Operazione | Descrizione |
|---|---|
OPTIMIZE |
Attiva il clustering incrementale per le tabelle abilitate. Vedere Usare clustering liquido per le tabelle. Migliora le prestazioni delle query ottimizzando le dimensioni dei file. Vedere Ottimizzare il layout dei file di dati. |
VACUUM |
Riduce i costi di archiviazione eliminando i file di dati non più a cui fa riferimento la tabella. Vedi Eliminazione dei file di dati inutilizzati con vacuum. |
ANALYZE |
Analizza la tabella e raccoglie le statistiche per migliorare le prestazioni delle query. Vedere ANALYZE TABLE ... STATISTICHE DI CALCOLO. Per rimuovere le statistiche raccolte dall'ottimizzazione predittiva, vedere ANALYZE TABLE ... ELIMINARE LE STATISTICHE. |
Nota
OPTIMIZE non viene eseguito ZORDER quando viene eseguito dall'ottimizzazione predittiva. Nelle tabelle che usano l'ordine Z, l'ottimizzazione predittiva ignora i file ordinati Z.
Se il clustering liquido automatico è abilitato, l'ottimizzazione predittiva potrebbe selezionare nuove chiavi di clustering prima del clustering dei dati. Per ulteriori informazioni, vedere Clustering liquido automatico.
Avviso
La finestra di conservazione per VACUUM è determinata dalla delta.deletedFileRetentionDuration proprietà della tabella, che per impostazione predefinita è 7 giorni.
VACUUM rimuove i file di dati a cui non fa più riferimento una versione della tabella Delta all'interno di tale finestra. Per conservare i dati per durate più lunghe, ad esempio per supportare il viaggio di tempo prolungato, impostare questa proprietà prima di abilitare l'ottimizzazione predittiva:
ALTER TABLE table_name SET TBLPROPERTIES ('delta.deletedFileRetentionDuration' = '30 days');
Calcolo e fatturazione
L'ottimizzazione predittiva avvia ANALYZE, OPTIMIZE e VACUUM usando il calcolo serverless per i processi. L'account viene fatturato per questo calcolo usando uno SKU di processi serverless.
Vedere i prezzi per i servizi gestiti di Databricks. Vedere Tenere traccia dell'ottimizzazione predittiva con le tabelle di sistema.
Prerequisiti
Per usare l'ottimizzazione predittiva, è necessario soddisfare i requisiti seguenti:
- L'area di lavoro di Azure Databricks deve trovarsi nel piano Premium in un'area supportata.
- È necessario usare SQL Warehouse o Databricks Runtime 12.2 LTS o versione successiva.
- Sono supportate solo le tabelle gestite di Unity Catalog.
- Se hai bisogno di connettività privata per gli account di archiviazione, configura una connessione privata di tipo serverless. Vedere Configurare la connettività privata alle risorse di Azure.
Abilitare l'ottimizzazione predittiva
È possibile abilitare l'ottimizzazione predittiva per un account, un catalogo, uno schema o una tabella. Tutte le tabelle gestite di Unity Catalog ereditano il valore dell'account per impostazione predefinita. È possibile eseguire l'override del valore predefinito dell'account a livello di catalogo, schema o tabella.
Per abilitare o disabilitare l'ottimizzazione predittiva, è necessario disporre dei privilegi seguenti:
| Oggetto del Catalogo di Unity | Privilegio |
|---|---|
| Conto | Amministratore dell'account |
| Catalogo | Proprietario del catalogo o utente con MANAGE privilegi nel catalogo |
| Diagramma | Proprietario dello schema o utente con MANAGE privilegi per lo schema |
| Tabella | Proprietario della tabella o utente con MANAGE privilegi sulla tabella |
Abilitare o disabilitare l'ottimizzazione predittiva per l'account
Un amministratore dell'account può abilitare l'ottimizzazione predittiva per tutti i metastore in un account. I cataloghi e gli schemi ereditano questa impostazione per impostazione predefinita, ma è possibile eseguirne l'override a entrambi i livelli.
- Vai alla console degli account.
- Passare a Impostazioni, quindi Abilitare la funzionalità.
- Seleziona l'opzione desiderata (ad esempio Abilitato) accanto a Ottimizzazione predittiva.
Nota
- I metastore nelle aree che non supportano l'ottimizzazione predittiva non sono abilitati.
- La disabilitazione dell'ottimizzazione predittiva a livello di account non la disabilita per cataloghi o schemi che l'hanno abilitata in modo specifico.
Abilitare o disabilitare l'ottimizzazione predittiva per un catalogo, uno schema o una tabella
L'ottimizzazione predittiva usa un modello di ereditarietà. Se abilitato per un catalogo, gli schemi in tale catalogo ereditano l'impostazione e anche le tabelle all'interno di uno schema abilitato lo ereditano. È possibile abilitare o disabilitare in modo esplicito l'ottimizzazione predittiva per un catalogo, uno schema o una tabella per eseguire l'override di questo comportamento.
Nota
È possibile disabilitare l'ottimizzazione predittiva a livello di catalogo, schema o tabella prima di abilitarla a livello di account. Se l'ottimizzazione predittiva viene abilitata in un secondo momento a livello di account, rimane bloccata per gli oggetti che lo hanno disabilitato in modo specifico.
Usare la sintassi seguente per abilitare, disabilitare o reimpostare l'ottimizzazione predittiva per ereditare dall'oggetto padre:
ALTER CATALOG [catalog_name] { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER { SCHEMA | DATABASE } schema_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
ALTER TABLE table_name { ENABLE | DISABLE | INHERIT } PREDICTIVE OPTIMIZATION;
Vedete ALTER TABLE.
Verificare se l'ottimizzazione predittiva è abilitata
Il Predictive Optimization campo è una proprietà del catalogo Unity che indica se l'ottimizzazione predittiva è abilitata. Se l'impostazione viene ereditata da un oggetto padre, il valore del campo indica questo valore.
Usare la sintassi seguente per controllare lo stato:
DESCRIBE (CATALOG | SCHEMA | TABLE) EXTENDED name
Controllare perché l'ottimizzazione predittiva ha ignorato una tabella
In Databricks Runtime 18 e versioni successive, dopo che l'ottimizzazione predittiva valuta una tabella gestita, usare la scheda Cronologia in Esplora cataloghi per vedere perché un'operazione è stata ignorata. La visualizzazione dei risultati potrebbe richiedere fino a 24 ore.
Usare la scheda cronologia in Esplora cataloghi
È possibile visualizzare i motivi di esclusione nella scheda Cronologia di una tabella in Catalog Explorer. Nella colonna Operazione l'etichetta Auto indica l'operazione eseguita e l'etichetta Non applicata indica che l'operazione è stata ignorata. L'etichetta Auto include l'ottimizzazione predittiva e altre operazioni automatiche, ad esempio la compattazione automatica di streaming.
Per visualizzare il motivo del salto, fare clic su una riga con l'etichetta Non applicata nella colonna Operazione.
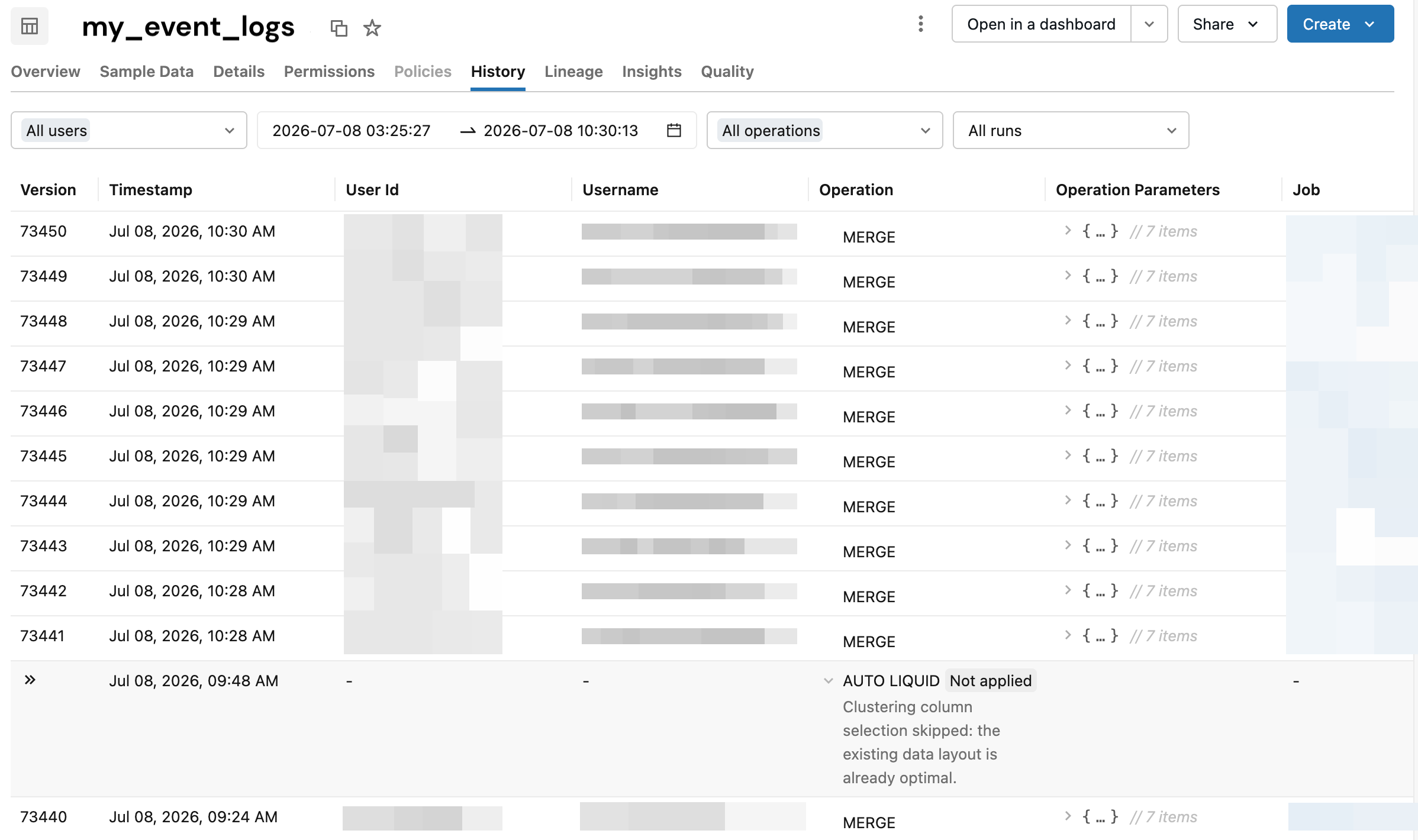
La tabella seguente descrive i tipi di operazione automatica mostrati in Esplora cataloghi:
| Operazione Esplora cataloghi | Descrizione |
|---|---|
OPTIMIZE |
Compattazione dei file per migliorare le prestazioni delle query o il clustering liquido incrementale |
AUTO LIQUID |
Valutazione o evoluzione delle chiavi di clustering liquide |
VACUUM |
Rimozione dei file di dati non più a cui fa riferimento la tabella |
Tenere traccia dell'ottimizzazione predittiva con le tabelle di sistema
Databricks fornisce la tabella system.storage.predictive_optimization_operations_history di sistema per l'osservabilità in operazioni di ottimizzazione predittiva, costi e impatto. Vedere Riferimento alla tabella del sistema di ottimizzazione predittiva.
Messaggio di errore collegamento privato
Se la tabella di sistema contrassegna le operazioni come non riuscite con FAILED: PRIVATE_LINK_SETUP_ERROR, il collegamento privato serverless potrebbe non essere configurato correttamente. Vedere Configurare la connettività privata alle risorse di Azure.
Limiti
L'ottimizzazione predittiva non viene eseguita nei tipi di tabella seguenti:
- Tabelle caricate in un'area di lavoro in qualità di destinatari di OpenSharing
- Tabelle esterne