Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questo articolo illustra Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive.
Databricks Connect è una libreria client per il Runtime Databricks che consente di connettersi al calcolo di Azure Databricks da IDE, ad esempio Visual Studio Code, PyCharm e IntelliJ IDEA, notebook e qualsiasi applicazione personalizzata, per abilitare nuove esperienze utente interattive basate sul Lakehouse di Azure Databricks.
Databricks Connect è disponibile per le lingue seguenti:
Cosa è possibile fare con Databricks Connect?
Usando Databricks Connect, è possibile scrivere codice usando le API Spark ed eseguirle in remoto in Azure Databricks calcolo anziché nella sessione Spark locale.
Sviluppare ed eseguire il debug in modo interattivo da qualsiasi IDE. Databricks Connect consente agli sviluppatori di sviluppare ed eseguire il debug del codice nel calcolo di Databricks usando qualsiasi funzionalità nativa di esecuzione e debug dell'IDE. L'estensione Visual Studio CodeDatabricks usa Databricks Connect per fornire il debug predefinito del codice utente in Databricks.
Creare app interattive per i dati. Proprio come un driver JDBC, la libreria Databricks Connect può essere incorporata in qualsiasi applicazione per interagire con Databricks. Databricks Connect offre la piena espressività di Python tramite PySpark, eliminando l'incompatibilità del linguaggio di programmazione SQL e consentendo di eseguire tutte le trasformazioni dei dati con Spark sul calcolo scalabile serverless di Databricks.
Come funziona?
Databricks Connect è basato su Spark Connect open source, che ha un'architettura client-server disaccoppiata per Apache Spark che consente la connettività remota ai cluster Spark usando l'API DataFrame. Il protocollo sottostante usa piani logici non risolti spark e Apache Arrow sopra gRPC. L'API client è progettata per essere sottile, in modo che possa essere incorporata ovunque: in server applicazioni, IDE, notebook e linguaggi di programmazione.
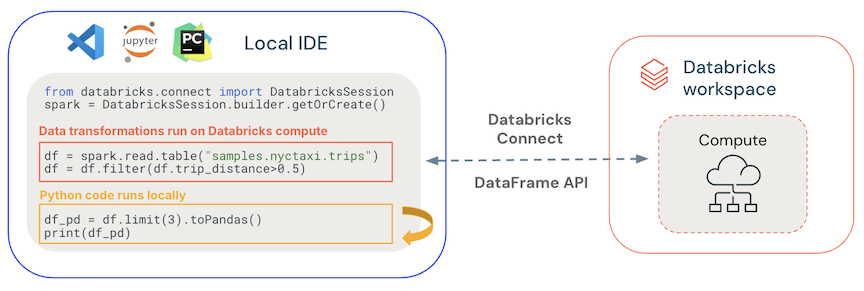
- Codice generale viene eseguito localmente: Python e il codice Scala viene eseguito sul lato client, abilitando il debug interattivo. Tutto il codice viene eseguito in locale, mentre tutto il codice Spark continua a essere eseguito nel cluster remoto.
-
Le API del dataframe vengono eseguite nel calcolo di Databricks. Tutte le trasformazioni dei dati vengono convertite in piani Spark ed eseguite nel calcolo di Databricks tramite la sessione Spark remota. Vengono materializzati nel client locale quando si usano comandi come
collect(),show(),toPandas(). -
Codice UDF eseguito nel calcolo di Databricks: le funzioni definite dall'utente in locale vengono serializzate e inviate al cluster in cui vengono eseguite. Le API che eseguono il codice utente in Databricks includono: funzioni definite dall'utente,
foreach,foreachBatch, etransformWithState. - Per la gestione delle dipendenze:
- Installare le dipendenze dell'applicazione nel computer locale. Queste vengono eseguite in locale e devono essere installate come parte del progetto, ad esempio parte dell'ambiente virtuale Python.
- Installare le dipendenze UDF su Databricks. Vedere Gestire le dipendenze di funzioni definite dall'utente.
Come sono correlati Databricks Connect e Spark Connect?
Spark Connect è un protocollo basato su gRPC open source all'interno di Apache Spark che consente l'esecuzione remota dei carichi di lavoro Spark usando l'API DataFrame.
Per Databricks Runtime 13.3 LTS e versioni successive, Databricks Connect è un'estensione di Spark Connect con aggiunte e modifiche per supportare l'uso delle modalità di calcolo di Databricks e del catalogo Unity.
Risorse aggiuntive
Per iniziare rapidamente a sviluppare soluzioni Databricks Connect, vedere le esercitazioni seguenti:
- Databricks Connect per Python esercitazione di calcolo classico
- Tutorial sul calcolo serverless di Databricks Connect per Python
- Esercitazione sulla computazione classica con Databricks Connect per Scala
- Esercitazione su Databricks Connect per il calcolo serverless in Scala
- Esercitazione su Databricks Connect for R
Per visualizzare applicazioni di esempio che usano Databricks Connect, vedere il repository degli esempi di GitHub, che include gli esempi seguenti: