Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Databricks Connect per Databricks Runtime 12.2 LTS e versioni precedenti è deprecato. Databricks Runtime 12.2 LTS e tutte le versioni LTS precedenti hanno raggiunto la fine del supporto. Usare Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive. Per informazioni sulla migrazione da Databricks Connect per Databricks Runtime 12.2 LTS e versioni successive a Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive, vedere Eseguire la migrazione a Databricks Connect per Python o eseguire la migrazione a Databricks Connect per Scala.
Databricks Connect consente di connettere gli IDE più diffusi, ad esempio Visual Studio Code e PyCharm, i server notebook e altre applicazioni personalizzate ai cluster Azure Databricks.
Questo articolo illustra il funzionamento di Databricks Connect, illustra la procedura per iniziare a usare Databricks Connect, illustra come risolvere i problemi che possono verificarsi quando si usa Databricks Connect e le differenze tra l'esecuzione con Databricks Connect e l'esecuzione in un notebook di Azure Databricks.
Panoramica
Databricks Connect è una libreria client per Databricks Runtime. Consente di scrivere processi usando le API Spark ed eseguirli in remoto in un cluster Azure Databricks anziché nella sessione Spark locale.
Ad esempio, quando si esegue il comando spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame usando Databricks Connect, la rappresentazione logica del comando viene inviata al server Spark in esecuzione in Azure Databricks per l'esecuzione nel cluster remoto.
Con Databricks Connect è possibile:
- Eseguire processi Spark su larga scala da qualsiasi applicazione Python, R, Scala o Java. Ovunque sia possibile
import pyspark,require(SparkR)oimport org.apache.spark, è ora possibile eseguire processi Spark direttamente dall'applicazione, senza dover installare plug-in IDE o usare script di invio spark. - Esegui il debug e analizza il codice nel tuo IDE anche quando lavori con un cluster remoto.
- Iterare rapidamente nello sviluppo di librerie. Non è necessario riavviare il cluster dopo aver modificato le dipendenze della libreria Python o Java in Databricks Connect, perché ogni sessione client è isolata l'una dall'altra nel cluster.
- Spegnere i cluster inattivi senza interrompere l'attività. Poiché l'applicazione client è disaccoppiata dal cluster, non è interessata dai riavvii o dagli aggiornamenti del cluster, che normalmente causa la perdita di tutte le variabili, rdd e gli oggetti DataFrame definiti in un notebook.
Nota
Per lo sviluppo python con query SQL, Databricks consiglia di usare il connettore SQL di Databricks per Python invece di Databricks Connect. Il connettore SQL di Databricks per Python è più semplice da configurare rispetto a Databricks Connect. Inoltre, Databricks Connect analizza e pianifica le attività che vengono eseguite sul computer locale, mentre le attività vengono eseguite su risorse di calcolo remote. Ciò può rendere particolarmente difficile eseguire il debug degli errori di runtime. Il connettore SQL di Databricks per Python invia query SQL direttamente alle risorse di calcolo remote e recupera i risultati.
Requisiti
Questa sezione elenca i requisiti per Databricks Connect.
Sono supportate solo le versioni di Databricks Runtime seguenti:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
È necessario installare Python 3 nel computer di sviluppo e la versione secondaria dell'installazione di Python client deve corrispondere alla versione secondaria di Python del cluster Azure Databricks. La tabella seguente illustra la versione di Python installata con ogni runtime di Databricks.
Versione Databricks Runtime Versione di Python 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3.7 Databricks consiglia vivamente di avere un ambiente virtuale Python attivato per ogni versione di Python usata con Databricks Connect. Gli ambienti virtuali Python consentono di assicurarsi di usare le versioni corrette di Python e Databricks Connetti insieme. Ciò consente di ridurre il tempo impiegato per la risoluzione dei problemi tecnici correlati.
Ad esempio, se si usa venv nel computer di sviluppo e il cluster esegue Python 3.9, è necessario creare un
venvambiente con tale versione. Il comando di esempio seguente genera gli script per attivare unvenvambiente con Python 3.9 e questo comando inserisce tali script all'interno di una cartella nascosta denominata.venvall'interno della directory di lavoro corrente:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvPer usare questi script per attivare questo
venvambiente, vedere Funzionamento di venvs.Come altro esempio, se si usa Conda nel computer di sviluppo e il cluster esegue Python 3.9, è necessario creare un ambiente Conda con tale versione, ad esempio:
conda create --name dbconnect python=3.9Per attivare l'ambiente Conda con questo nome di ambiente, eseguire
conda activate dbconnect.La versione principale e secondaria del pacchetto Databricks Connect deve sempre corrispondere alla versione di Databricks Runtime. Databricks consiglia di usare sempre il pacchetto più recente di Databricks Connect corrispondente alla versione di Databricks Runtime. Ad esempio, quando si usa un cluster Databricks Runtime 12.2 LTS, è necessario usare anche il
databricks-connect==12.2.*pacchetto.Nota
Vedere le note sulla versione di Databricks Connect per un elenco delle versioni di Databricks Connect disponibili e degli aggiornamenti di manutenzione.
Java Runtime Environment (JRE) 8. Il client è stato testato con OpenJDK 8 JRE. Il client non supporta Java 11.
Nota
In Windows, se viene visualizzato un errore che indica che Databricks Connect non riesce a trovare winutils.exe, vedere Impossibile trovare winutils.exe in Windows.
Configurare il client
Completare i passaggi seguenti per configurare il client locale per Databricks Connect.
Nota
Prima di iniziare a configurare il client Databricks Connect locale, è necessario soddisfare i requisiti per Databricks Connect.
Passaggio 1: Installare il client Databricks Connect
Dopo aver attivato l'ambiente virtuale, disinstallare PySpark, se è già installato, eseguendo il
uninstallcomando . Questa operazione è necessaria perché ildatabricks-connectpacchetto è in conflitto con PySpark. Per informazioni dettagliate, vedere Installazioni di PySpark in conflitto. Per verificare se PySpark è già installato, eseguire ilshowcomando .# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkCon l'ambiente virtuale ancora attivato, installare il client Databricks Connect eseguendo il
installcomando . Usare l'opzione--upgradeper aggiornare qualsiasi installazione client esistente alla versione specificata.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Nota
Databricks consiglia di aggiungere la notazione "dot-asterisk" per specificare
databricks-connect==X.Y.*invece didatabricks-connect=X.Y, per assicurarsi che il pacchetto più recente sia installato.
Passaggio 2: Configurare le proprietà di connessione
Raccogliere le proprietà di configurazione seguenti.
L'URL per area di lavoro di Azure Databricks. Questo è lo stesso di
https://seguito dal Server Hostname per il cluster; consulta Ottenere i dettagli di connessione per una risorsa di calcolo Azure Databricks.Il token di accesso personale di Azure Databricks o il token Microsoft Entra ID (in precedenza Azure Active Directory).
- Per il passaggio delle credenziali di Azure Data Lake Storage (ADLS), è necessario utilizzare un token ID di Microsoft Entra. Il pass-through delle credenziali di Microsoft Entra ID è supportato solo nei cluster Standard che eseguono Databricks Runtime 7.3 LTS e versioni successive, e non è compatibile con l'autenticazione tramite service principal.
- Per altre informazioni sull'autenticazione con i token ID di Microsoft Entra, vedere Autenticazione con token ID Microsoft Entra.
ID del sistema di calcolo classico. È possibile ottenere l'ID di calcolo classico dall'URL. Qui l'ID è
1108-201635-xxxxxxxx. Vedere anche URL e ID della risorsa di calcolo.
L'ID organizzazione univoco per la tua area di lavoro. Vedere Ottenere gli identificatori per gli oggetti dell'area di lavoro.
Porta a cui Databricks Connect si connette nel cluster. La porta predefinita è
15001. Se il cluster è configurato per l'uso di una porta diversa, ad esempio8787fornita nelle istruzioni precedenti per Azure Databricks, usare il numero di porta configurato.
Configurare la connessione come indicato di seguito.
È possibile usare l'interfaccia della riga di comando, le configurazioni SQL o le variabili di ambiente. La precedenza dei metodi di configurazione dal più alto al più basso è: chiavi di configurazione SQL, interfaccia della riga di comando e variabili di ambiente.
Interfaccia a riga di comando (CLI)
Eseguire
databricks-connect.databricks-connect configureLa licenza visualizza:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Accettare la licenza e specificare i valori di configurazione. Per Databricks Host e Databricks Token immettere l'URL dell'area di lavoro e il token di accesso personale annotato nel passaggio 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Se viene visualizzato un messaggio che indica che il token ID di Microsoft Entra è troppo lungo, è possibile lasciare vuoto il campo Token di Databricks e immettere manualmente il token in
~/.databricks-connect.
Configurazioni SQL o variabili di ambiente. La tabella seguente illustra le chiavi di configurazione SQL e le variabili di ambiente che corrispondono alle proprietà di configurazione annotate nel passaggio 1. Per impostare una chiave di configurazione SQL, usare
sql("set config=value"). Ad esempio:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parametro Chiave di configurazione SQL Nome variabile di ambiente Host di Databricks spark.databricks.service.address INDIRIZZO DI DATABRICKS Databricks Token spark.databricks.service.token DATABRICKS_API_TOKEN ID cluster spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID ID organizzazione spark.databricks.service.orgId DATABRICKS_ORG_ID Porta spark.databricks.service.port DATABRICKS_PORT
Con l'ambiente virtuale ancora attivato, testare la connettività ad Azure Databricks come indicato di seguito.
databricks-connect testSe il cluster configurato non è in esecuzione, il test avvia il cluster che rimarrà in esecuzione fino al tempo di autoterminazione configurato. L'output dovrebbe essere simile al seguente:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiSe non vengono visualizzati errori correlati alla connessione (
WARNi messaggi sono ok), la connessione è stata completata.
Usare Databricks Connect
La sezione descrive come configurare l'IDE o il server notebook preferito per l'uso del client per Databricks Connect.
Contenuto della sezione:
- JupyterLab
- Jupyter Notebook classico
- PyCharm
- SparkR e RStudio Desktop
- sparklyr e RStudio Desktop
- IntelliJ (Scala o Java)
- PyDev con Eclipse
- Eclissi
- SBT
- Spark Shell
JupyterLab
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect with JupyterLab and Python (Connettersi a JupyterLab e Python), seguire queste istruzioni.
Per installare JupyterLab, con l'ambiente virtuale Python attivato, eseguire il comando seguente dal terminale o dal prompt dei comandi:
pip3 install jupyterlabPer avviare JupyterLab nel Web browser, eseguire il comando seguente dall'ambiente virtuale Python attivato:
jupyter labSe JupyterLab non viene visualizzato nel Web browser, copiare l'URL che inizia con
localhosto127.0.0.1dall'ambiente virtuale e immetterlo nella barra degli indirizzi del Web browser.Creare un nuovo notebook: in JupyterLab fare clic su File > Nuovo > Notebook nel menu principale, selezionare Python 3 (ipykernel) e fare clic su Select.
Nella prima cella del notebook immettere il codice di esempio o il proprio codice. Se si usa il proprio codice, è necessario creare almeno un'istanza di
SparkSession.builder.getOrCreate(), come illustrato nel codice di esempio.Per eseguire il notebook, fare clic su Esegui > Esegui tutte le celle.
Per eseguire il debug del notebook, fare clic sull'icona del bug (Abilita debugger) accanto a Python 3 (ipykernel) sulla barra degli strumenti del notebook. Impostare uno o più punti di interruzione e quindi fare clic su Esegui > Esegui tutte le celle.
Per arrestare JupyterLab, fare clic su File > Arresta. Se il processo JupyterLab è ancora in esecuzione nel terminale o nel prompt dei comandi, arrestare questo processo premendo
Ctrl + ce immettendoyper confermare.
Per istruzioni di debug più specifiche, vedere Debugger.
Jupyter Notebook classico
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Lo script di configurazione per Databricks Connect aggiunge automaticamente il pacchetto alla configurazione del progetto. Per iniziare a usare un kernel Python, eseguire:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Per abilitare la sintassi abbreviata per l'esecuzione %sql e la visualizzazione di query SQL, usare il frammento di codice seguente:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect with Visual Studio Code, seguire questa procedura:
Aprire il riquadro comandi (Comando+MAIUSC+P in macOS e CTRL+MAIUSC+P in Windows/Linux).
Selezionare un interprete Python. Passare a Codice> Preferenze> Impostazioni e scegliere impostazioni Python.
Eseguire
databricks-connect get-jar-dir.Aggiungere la directory restituita dal comando alle Impostazioni Utente nel codice JSON in
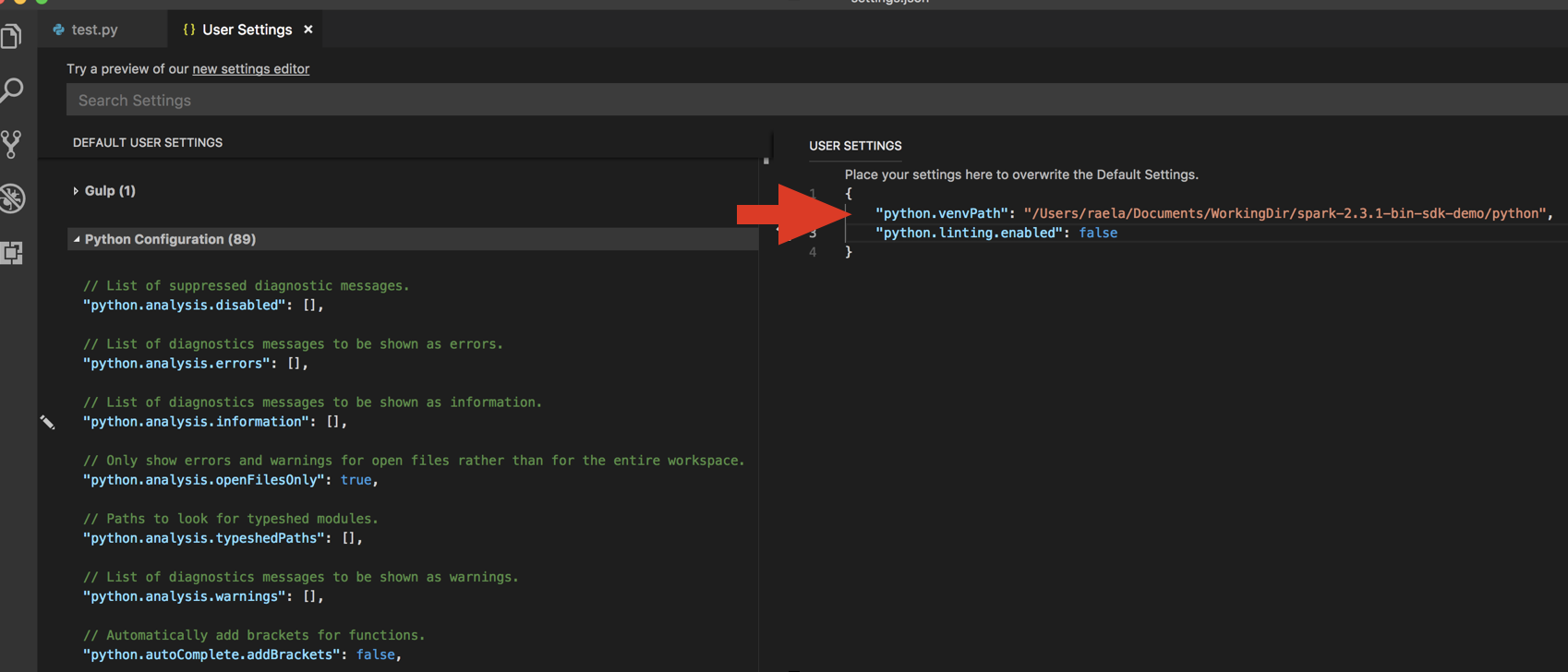
python.venvPath. Questa operazione deve essere aggiunta alla configurazione di Python.Disabilitare il linter. Fare clic su ... sul lato destro e modificare le impostazioni JSON. Le impostazioni modificate sono le seguenti:
Se stai eseguendo con un ambiente virtuale, che è il modo consigliato per sviluppare in Python in VS Code, nella barra dei comandi digita
select python interpretere punta al tuo ambiente che corrisponde alla versione di Python del cluster.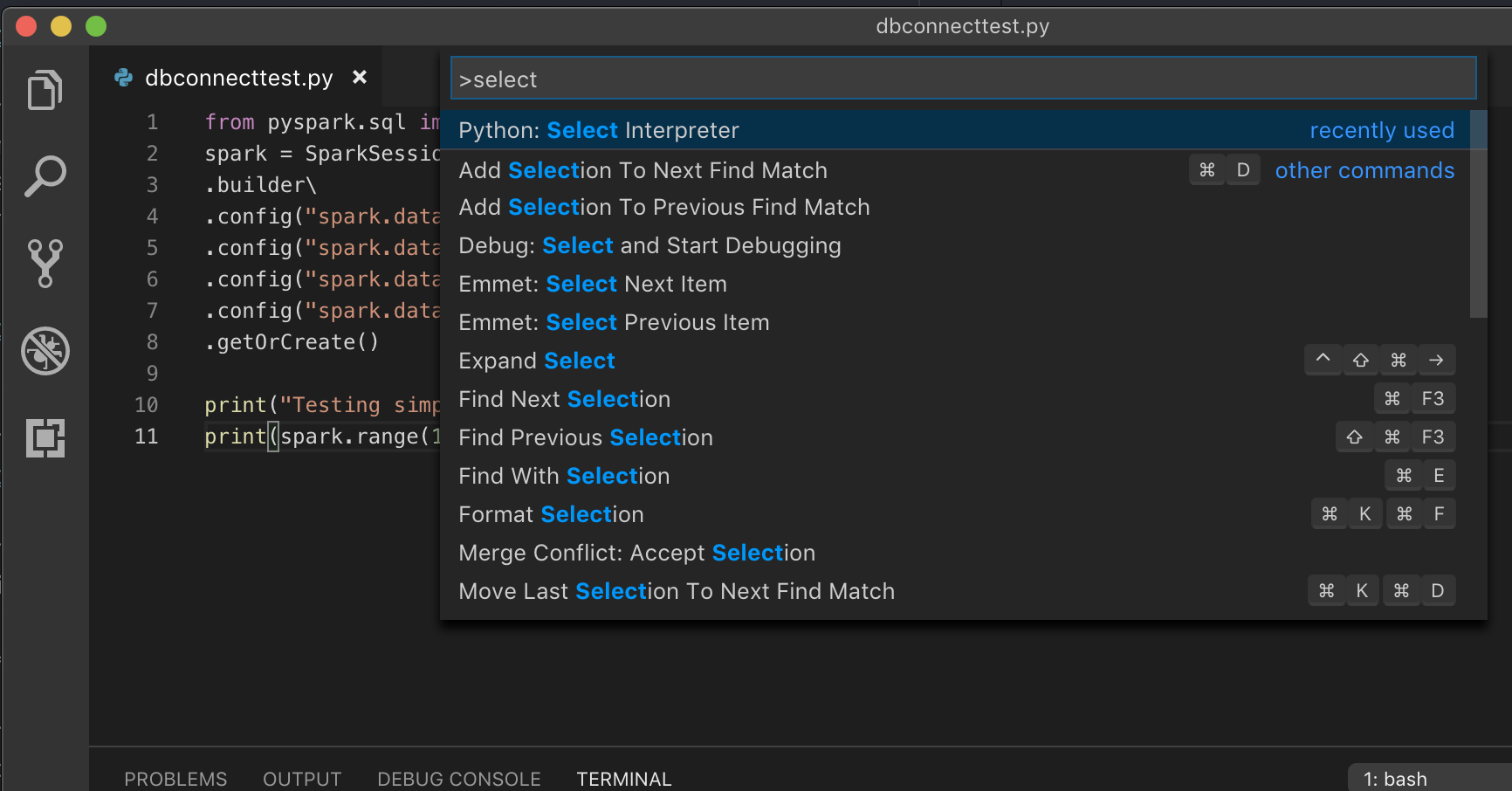
Ad esempio, se il cluster è Python 3.9, l'ambiente di sviluppo deve essere Python 3.9.
PyCharm
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Lo script di configurazione per Databricks Connect aggiunge automaticamente il pacchetto alla configurazione del progetto.
I cluster di Python 3
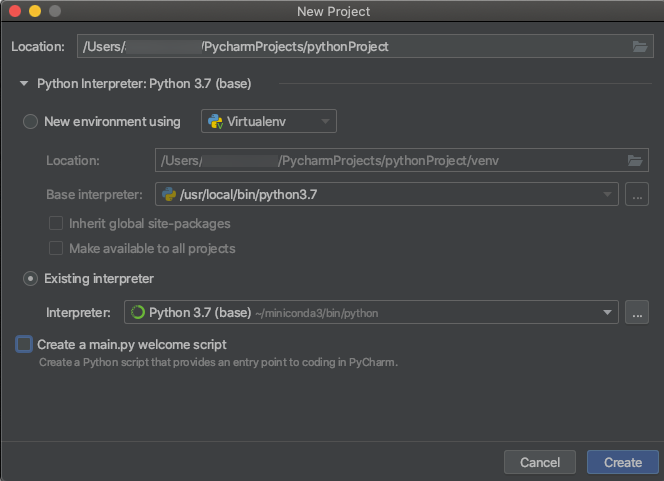
Quando si crea un progetto PyCharm, selezionare Interprete esistente. Dal menu a discesa selezionare l'ambiente Conda creato (vedere Requisiti).
Passare a Esegui > modifica configurazioni.
Aggiungere
PYSPARK_PYTHON=python3come variabile di ambiente.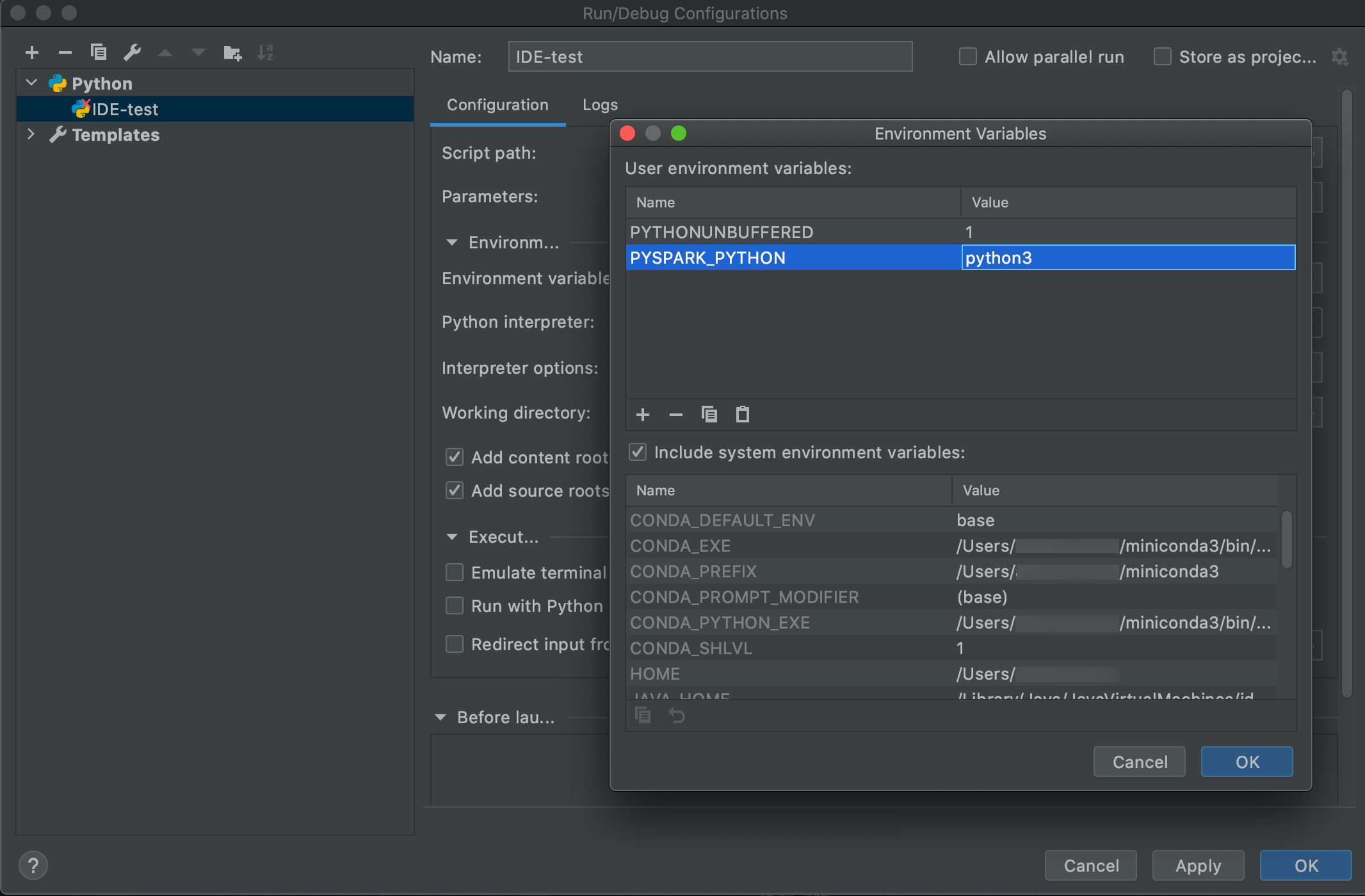
SparkR e RStudio Desktop
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect con SparkR e RStudio Desktop, eseguire le operazioni seguenti:
Scaricare e decomprimere la distribuzione Spark open source nel computer di sviluppo. Scegliere la stessa versione del cluster Azure Databricks (Hadoop 2.7).
Eseguire
databricks-connect get-jar-dir. Questo comando restituisce un percorso come/usr/local/lib/python3.5/dist-packages/pyspark/jars. Copia il percorso del file di una directory sopra il percorso della directory JAR, ad esempio , che rappresenta la directory/usr/local/lib/python3.5/dist-packages/pyspark.Configurare il percorso della libreria Spark e spark home aggiungendoli all'inizio dello script R. Impostare
<spark-lib-path>sulla directory in cui è stato decompresso il pacchetto Spark open source nel passaggio 1. Impostare<spark-home-path>sulla directory Databricks Connect del passaggio 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Avviare una sessione Spark e avviare l'esecuzione di comandi SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr e RStudio Desktop
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Importante
Questa funzionalità è disponibile in anteprima pubblica.
È possibile copiare codice dipendente da sparklyr sviluppato in locale usando Databricks Connect ed eseguirlo in un notebook di Azure Databricks o in RStudio Server ospitato nell'area di lavoro di Azure Databricks con modifiche minime o senza modifiche al codice.
Contenuto della sezione:
- Requisiti
- Installare, configurare e usare sparklyr
- Risorse
- Limitazioni di sparklyr e RStudio Desktop
Requisiti
- sparklyr 1.2 o versione successiva.
- Databricks Runtime 7.3 LTS o versione successiva con la versione corrispondente di Databricks Connect.
Installare, configurare e usare sparklyr
In RStudio Desktop installare sparklyr 1.2 o versione successiva da CRAN o installare la versione master più recente da GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Attivare l'ambiente Python con la versione corretta di Databricks Connect installata ed eseguire il comando seguente nel terminale per ottenere
<spark-home-path>:databricks-connect get-spark-homeAvviare una sessione Spark e avviare l'esecuzione di comandi sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countChiudere la connessione.
spark_disconnect(sc)
Risorse
Per ulteriori informazioni, consultare il README di GitHub sparklyr.
Per esempi di codice, vedere sparklyr.
Limitazioni di sparklyr e RStudio Desktop
Le funzionalità seguenti non sono supportate:
- API di streaming sparklyr
- API ML di sparklyr
- API di scopa
- csv_file modalità di serializzazione
- spark submit
IntelliJ (Scala o Java)
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect with IntelliJ (Scala o Java), eseguire le operazioni seguenti:
Eseguire
databricks-connect get-jar-dir.Punta le dipendenze verso la directory restituita dal comando. Passare a File > Struttura del Progetto > Moduli > Dipendenze > segno '+' > JAR o Directory.
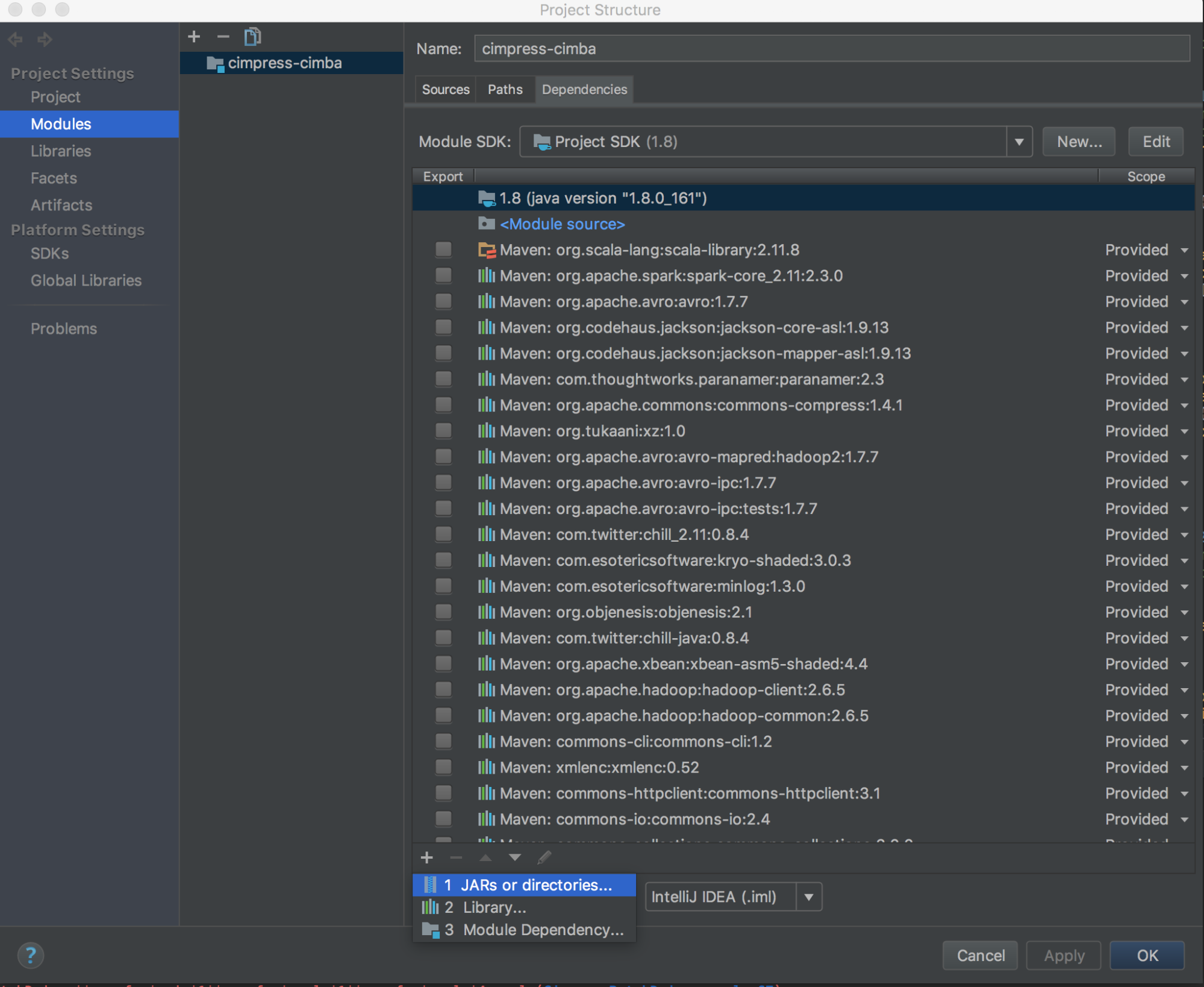
Per evitare conflitti, è consigliabile rimuovere eventuali altre installazioni spark dal classpath. Se ciò non è possibile, assicurarsi che i file JAR aggiunti si trovino davanti al classpath. In particolare, devono precedere qualsiasi altra versione installata di Spark (in caso contrario, verrà utilizzata una di queste altre versioni di Spark, eseguendola localmente o generando un errore
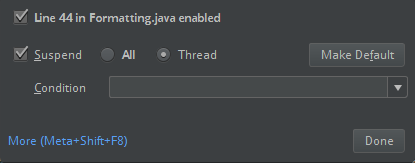
ClassDefNotFoundError).Controllare l'impostazione dell'opzione di interruzione in IntelliJ. Il valore predefinito è All e causerà timeout di rete se si impostano punti di interruzione per il debug. Impostarlo su Thread per evitare di arrestare i thread di rete in background.
PyDev con Eclipse
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect e PyDev con Eclipse, seguire queste istruzioni.
- Avviare Eclipse.
- Creare un progetto: fare clic su File > Nuovo > Progetto > PyDev > Progetto PyDev, e poi fare clic su Avanti.
- Specificare un nome di progetto.
- Per i Contenuti del progetto, specifica il percorso del tuo ambiente virtuale Python.
- Fare clic su Configurare un interprete prima di procedere.
- Fare clic su Configurazione manuale.
- Fare clic su Nuovo > cerca python/pypy exe.
- Passare a e selezionare il percorso completo dell'interprete Python a cui si fa riferimento dall'ambiente virtuale e quindi fare clic su Apri.
- Nella finestra di dialogo Seleziona interprete fare clic su OK.
- Nella finestra di dialogo Selezione necessaria fare clic su OK.
- Nella finestra di dialogo Preferenze fare clic su Applica e chiudi.
- Nella finestra di dialogo Progetto PyDev fare clic su Fine.
- Fare clic su Apri prospettiva.
- Aggiungere al progetto un file di codice Python (
.py) che contiene il codice di esempio o il proprio codice. Se si usa il proprio codice, è necessario creare almeno un'istanza diSparkSession.builder.getOrCreate(), come illustrato nel codice di esempio. - Con il file di codice Python aperto, impostare eventuali punti di interruzione in cui si vuole sospendere il codice durante l'esecuzione.
- Fare clic su Esegui > Esegui o Esegui > Debug.
Per istruzioni di esecuzione e debug più specifiche, vedere Esecuzione di un programma.
Eclissi
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect ed Eclipse, eseguire le operazioni seguenti:
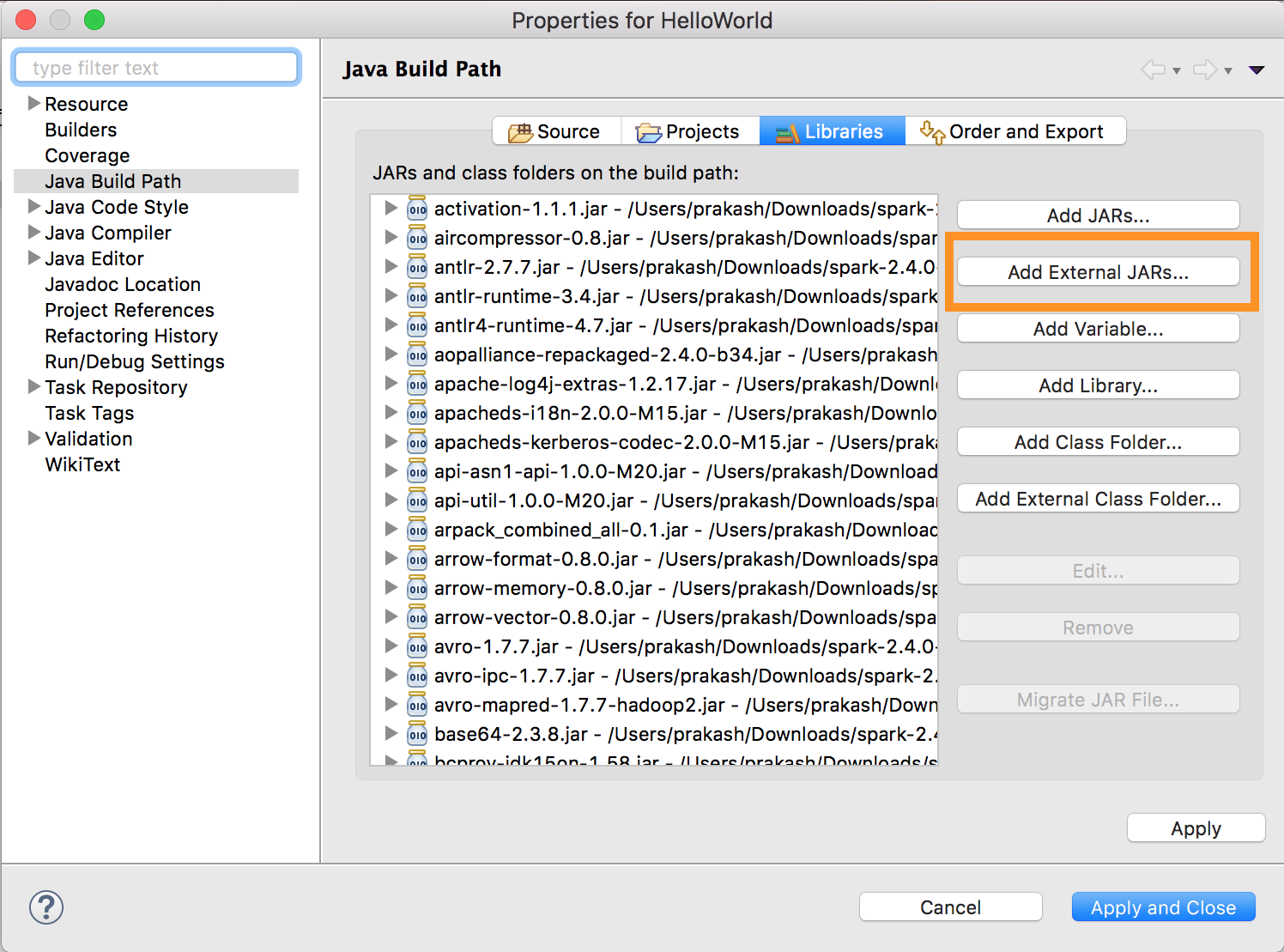
Eseguire
databricks-connect get-jar-dir.Configurare i JAR esterni alla directory restituita dal comando. Passare al > menu Progetto > Proprietà > Java Build Path > Librerie Aggiungi File JAR Esterni>.
Per evitare conflitti, è consigliabile rimuovere eventuali altre installazioni spark dal classpath. Se ciò non è possibile, assicurarsi che i file JAR aggiunti si trovino davanti al classpath. In particolare, devono precedere qualsiasi altra versione installata di Spark (in caso contrario, verrà utilizzata una di queste altre versioni di Spark, eseguendola localmente o generando un errore
ClassDefNotFoundError).
SBT
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect con SBT, è necessario configurare il build.sbt file in modo che venga collegato ai file JAR di Databricks Connect anziché alla normale dipendenza della libreria Spark. A tale scopo, usare la unmanagedBase direttiva nel file di compilazione di esempio seguente, che presuppone un'app Scala con un com.example.Test oggetto principale:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark Shell
Nota
Prima di iniziare a usare Databricks Connect, è necessario soddisfare i requisiti e configurare il client per Databricks Connect.
Per usare Databricks Connect con la shell Spark e Python o Scala, seguire queste istruzioni.
Dopo aver attivato l'ambiente virtuale, assicurarsi che il
databricks-connect testcomando sia stato eseguito correttamente in Configurare il client.Con l'ambiente virtuale attivato, avviare la shell Spark. Per Python, eseguire il
pysparkcomando . Per Scala, eseguire ilspark-shellcomando .# For Python: pyspark# For Scala: spark-shellViene visualizzata la shell Spark, ad esempio per Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Per Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Per informazioni su come usare la shell Spark con Python o Scala per eseguire comandi nel cluster, consultare Analisi interattiva con la shell Spark.
Usa la variabile predefinita
sparkper rappresentare ilSparkSessionnel cluster in esecuzione, ad esempio in Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPer Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPer arrestare la shell spark, premere
Ctrl + doCtrl + zo eseguire il comandoquit()oexit()per Python o:q:quitper Scala.
Esempi di codice
Questo semplice esempio di codice esegue una query sulla tabella specificata e quindi mostra le prime 5 righe della tabella specificata. Per usare una tabella diversa, modificare la chiamata a spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Questo esempio di codice più lungo esegue le operazioni seguenti:
- Crea un dataframe in memoria.
- Crea una tabella con il nome
zzz_demo_temps_tableall'interno dellodefaultschema. Se la tabella con questo nome esiste già, la tabella viene eliminata per prima. Per usare uno schema o una tabella diversa, modificare le chiamate aspark.sql,temps.write.saveAsTableo entrambe. - Salva il contenuto del dataframe nella tabella.
- Esegue una
SELECTquery sul contenuto della tabella. - Mostra il risultato della query.
- Elimina la tabella.
Pitone
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Linguaggio di programmazione Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Giava
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Lavorare con le dipendenze
In genere la classe principale o il file Python avrà altri file e file JAR di dipendenza. È possibile aggiungere i JAR di dipendenza e altri file chiamando sparkContext.addJar("path-to-the-jar") o sparkContext.addPyFile("path-to-the-file"). È anche possibile aggiungere file Egg e file ZIP con l'interfaccia addPyFile() . Ogni volta che si esegue il codice nell'IDE, i file JAR e di dipendenze vengono installati nel cluster.
Pitone
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
UDF Python + Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Linguaggio di programmazione Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Accedere alle utilità di Databricks
Questa sezione descrive come usare Databricks Connect per accedere alle utilità di Databricks.
È possibile utilizzare le utilità dbutils.fs e dbutils.secrets del modulo Databricks Utilities (dbutils) di riferimento.
I comandi supportati sono dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm. dbutils.secrets.getdbutils.secrets.getBytesdbutils.secrets.listdbutils.secrets.listScopes
Vedere Utilità file system (dbutils.fs) o eseguire dbutils.fs.help() l'utilità Secrets ( dbutils.secrets) o eseguire dbutils.secrets.help().
Pitone
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Quando si usa Databricks Runtime 7.3 LTS o versione successiva, per accedere al modulo DBUtils in modo che funzioni sia in locale che in cluster Azure Databricks, usare quanto segue get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
In caso contrario, usare quanto segue get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Linguaggio di programmazione Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Copia di file tra file system locali e remoti
È possibile usare dbutils.fs per copiare file tra il client e i file system remoti. Lo schema file:/ fa riferimento al file system locale nel client.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
La dimensione massima del file che può essere trasferita in questo modo è 250 MB.
Abilitare dbutils.secrets.get
A causa delle restrizioni di sicurezza, la possibilità di chiamare dbutils.secrets.get è disabilitata per impostazione predefinita. Per abilitare questa funzionalità per l'area di lavoro, contattare il supporto di Azure Databricks.
Impostare le configurazioni Hadoop
Nel client è possibile impostare le configurazioni di Hadoop usando l'API spark.conf.set , che si applica alle operazioni SQL e DataFrame. Le configurazioni hadoop impostate in sparkContext devono essere impostate nella configurazione del cluster o usando un notebook. Ciò è dovuto al fatto che le configurazioni impostate in sparkContext non sono associate alle sessioni utente, ma si applicano all'intero cluster.
Risoluzione dei problemi
Eseguire databricks-connect test per verificare la presenza di problemi di connettività. Questa sezione descrive alcuni problemi comuni che possono verificarsi con Databricks Connect e come risolverli.
Contenuto della sezione:
- Versione di Python non corrispondente
- Server non abilitato
- Installazioni di PySpark in conflitto
-
Contraddittorio
SPARK_HOME -
Voce in conflitto o mancante
PATHper i file binari - Impostazioni di serializzazione in conflitto nel cluster
-
Impossibile trovare
winutils.exein Windows - La sintassi del nome file, del nome della directory o dell'etichetta del volume non è corretta in Windows
Versione di Python non corrispondente
Controllare che la versione di Python in uso localmente sia almeno alla stessa versione secondaria di quella sul cluster (ad esempio, 3.9.16 rispetto a 3.9.15 va bene, mentre 3.9 rispetto a 3.8 no).
Se sono installate più versioni di Python in locale, assicurarsi che Databricks Connect usi quello corretto impostando la PYSPARK_PYTHON variabile di ambiente , ad esempio PYSPARK_PYTHON=python3.
Server non abilitato
Verificare che il cluster disponga del server Spark abilitato con spark.databricks.service.server.enabled true. Dovresti vedere le righe seguenti nel log del driver se lo è.
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Installazioni di PySpark in conflitto
Il databricks-connect pacchetto è in conflitto con PySpark. L'installazione di entrambi causerà errori durante l'inizializzazione del contesto Spark in Python. Questo può manifestarsi in diversi modi, tra cui errori di "flusso danneggiato" o "classe non trovata". Se PySpark è installato nell'ambiente Python, assicurarsi che sia disinstallato prima di installare databricks-connect. Dopo aver disinstallato PySpark, assicurarsi di reinstallare completamente il pacchetto Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Contraddittorio SPARK_HOME
Se spark è stato usato in precedenza nel computer, l'IDE può essere configurato per l'uso di una di queste altre versioni di Spark anziché di Databricks Connect Spark. Questo può manifestarsi in diversi modi, tra cui errori di "flusso danneggiato" o "classe non trovata". È possibile visualizzare la versione di Spark usata controllando il valore della SPARK_HOME variabile di ambiente:
Pitone
import os
print(os.environ['SPARK_HOME'])
Linguaggio di programmazione Scala
println(sys.env.get("SPARK_HOME"))
Giava
System.out.println(System.getenv("SPARK_HOME"));
Risoluzione
Se SPARK_HOME è impostato su una versione di Spark diversa da quella nel client, è necessario annullare l'impostazione della SPARK_HOME variabile e riprovare.
Controlla le impostazioni delle variabili di ambiente dell'IDE, il file .bashrc, .zshrc, .bash_profile e qualsiasi altra posizione in cui possono essere impostate variabili di ambiente. È molto probabile che sia necessario uscire e riavviare l'IDE per eliminare lo stato precedente e potrebbe anche essere necessario creare un nuovo progetto se il problema persiste.
Non è necessario impostare SPARK_HOME su un nuovo valore. L'annullamento dell'impostazione deve essere sufficiente.
Voce in conflitto o mancante PATH per i file binari
È possibile che il tuo PATH sia configurato in modo tale che comandi come spark-shell eseguano altri file binari precedentemente installati anziché quello fornito con Databricks Connect. Ciò può causare il fallimento di databricks-connect test. È necessario assicurarsi che i file binari di Databricks Connect abbia la precedenza o rimuovere quelli installati in precedenza.
Se non è possibile eseguire comandi come spark-shell, è anche possibile che PATH non sia stato configurato automaticamente da pip3 install e sarà necessario aggiungere manualmente il dir di installazione bin al percorso. È possibile usare Databricks Connect con gli IDE anche se non è configurato. Tuttavia, il databricks-connect test comando non funzionerà.
Impostazioni di serializzazione in conflitto nel cluster
Se visualizzi l'errore "flusso danneggiato" durante l'esecuzione di databricks-connect test, ciò potrebbe essere dovuto a configurazioni di serializzazione del cluster incompatibili. Ad esempio, l'impostazione della spark.io.compression.codec configurazione può causare questo problema. Per risolvere questo problema, è consigliabile rimuovere queste configurazioni dalle impostazioni del cluster o impostare la configurazione nel client Databricks Connect.
Impossibile trovare winutils.exe in Windows
Se stai usando Databricks Connect su Windows e vedi:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Seguire le istruzioni per configurare il percorso hadoop in Windows.
La sintassi del nome file, del nome della directory o dell'etichetta del volume non è corretta in Windows
Se si usi Windows e Databricks Connect e visualizzi:
The filename, directory name, or volume label syntax is incorrect.
Java o Databricks Connect sono stati installati in una directory con uno spazio nel percorso. È possibile risolvere questo problema installando in un percorso senza spazi o configurando il percorso usando il formato nome breve.
Autenticazione tramite token ID Microsoft Entra
Nota
Le informazioni seguenti si applicano solo alle versioni da Databricks Connect 7.3.5 a 12.2.x.
Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive attualmente non supporta i token ID di Microsoft Entra.
Quando si usa Databricks Connect versioni da 7.3.5 a 12.2.x, è possibile eseguire l'autenticazione usando un token ID Microsoft Entra invece di un token di accesso personale. I token ID Di Microsoft Entra hanno una durata limitata. Quando scade il token ID di Microsoft Entra, Databricks Connect ha esito negativo e viene visualizzato un Invalid Token errore.
Per Databricks Connect versioni da 7.3.5 a 12.2.x, è possibile fornire il token ID Microsoft Entra nell'applicazione Databricks Connect in esecuzione. L'applicazione deve ottenere il nuovo token di accesso e impostarlo sulla spark.databricks.service.token chiave di configurazione SQL.
Pitone
spark.conf.set("spark.databricks.service.token", new_aad_token)
Linguaggio di programmazione Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Dopo aver aggiornato il token, l'applicazione può continuare a usare lo stesso SparkSession e tutti gli oggetti e lo stato creati nel contesto della sessione. Per evitare errori intermittenti, Databricks consiglia di fornire un nuovo token prima della scadenza del token precedente.
È possibile estendere la durata del token MICROSOFT Entra ID per rendere persistente durante l'esecuzione dell'applicazione. A tale scopo, allegare un TokenLifetimePolicy che abbia una durata adeguatamente lunga all'applicazione di autorizzazione Microsoft Entra ID usata per acquisire il token di accesso.
Nota
Il passthrough Microsoft Entra ID utilizza due token: il token di accesso Microsoft Entra ID descritto in precedenza che configuri nelle versioni di Databricks Connect dalla 7.3.5 alla 12.2.x e il token di passthrough ADLS per la risorsa specifica che Databricks genera mentre elabora la richiesta. Non è possibile estendere la durata dei token pass-through di ADLS usando i criteri di durata del token ID di Microsoft Entra. Se si invia un comando al cluster che richiede più di un'ora, questo fallirà se accede a una risorsa ADLS dopo il limite di un'ora.
Limiti
- Structured Streaming.
- Esecuzione di codice arbitrario che non fa parte di un processo Spark nel cluster remoto.
- Le API Scala, Python e R native per le operazioni di tabella Delta (ad esempio,
DeltaTable.forPath) non sono supportate. Tuttavia, l'API SQL (spark.sql(...)) con operazioni Delta Lake e l'API Spark (ad esempio)spark.read.loadnelle tabelle Delta sono entrambe supportate. - Copia in.
- Uso di funzioni SQL, funzioni definite dall'utente (UDF) in Python o Scala, che fanno parte del catalogo del server. Tuttavia, le funzioni definite dall'utente in locale per Scala e Python funzionano.
- Apache Zeppelin 0.7.x e versioni successive.
- Connessione ai cluster con controllo di accesso alle tabelle.
- Connessione ai cluster con isolamento del processo abilitato (in altre parole, dove
spark.databricks.pyspark.enableProcessIsolationè impostato sutrue). - Comando DELTA
CLONESQL. - Visualizzazioni temporanee globali.
-
Koala e
pyspark.pandas. -
CREATE TABLE table AS SELECT ...I comandi SQL non funzionano sempre. Usare invecespark.sql("SELECT ...").write.saveAsTable("table").
- La trasmissione diretta delle credenziali ID di Microsoft Entra è supportata solo nei cluster standard che eseguono Databricks Runtime 7.3 LTS e versioni successive e non è compatibile con l'autenticazione del principale del servizio.
- La seguente riferimento alle utilità di Databricks (
dbutils):