Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questo articolo illustra Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive.
Databricks Connect consente di connettere IDE comuni, ad esempio PyCharm, server notebook e altre applicazioni personalizzate al calcolo di Azure Databricks. Consultare Cos’è Databricks Connect?.
Questo articolo illustra come iniziare rapidamente a usare Databricks Connect per Python usando PyCharm.
- Per la versione R di questo articolo, vedere Databricks Connect for R.
- Per la versione Scala di questo articolo, consultare Databricks Connect per Scala.
Esercitazione
Nell'esercitazione seguente viene creato un progetto in PyCharm, viene installato Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive, e viene eseguito codice semplice nel sistema di calcolo nell'area di lavoro di Databricks da PyCharm. Per altre informazioni ed esempi, vedere Passaggi successivi.
Requisiti
Per completare questa esercitazione, è necessario soddisfare i requisiti seguenti:
- L'area di lavoro di Azure Databricks di destinazione deve avere Unity Catalog abilitato.
- È installato PyCharm. Questa esercitazione è stata testata con PyCharm Community Edition 2023.3.5. Se si usa una versione o un'edizione diversa di PyCharm, le istruzioni seguenti possono variare.
- L'ambiente locale e il calcolo soddisfano i requisiti di versione di installazione di Databricks Connect per Python .
- Se si usa il calcolo classico, sarà necessario l'ID del cluster. Per ottenere l'ID cluster, nell'area di lavoro fare clic su Calcolo sulla barra laterale e quindi sul nome del cluster. Nella barra degli indirizzi del Web browser copiare la stringa di caratteri tra
clusterseconfigurationnell'URL.
Passaggio 1: Configurare l'autenticazione di Azure Databricks
Questa esercitazione utilizza l'autenticazione OAuth da utente a macchina (U2M) di Azure Databricks e un profilo di configurazione Azure Databricks per l'autenticazione nel tuo workspace di Azure Databricks. Per usare un tipo di autenticazione diverso, vedere Configurare le proprietà di connessione.
La configurazione dell'autenticazione U2M OAuth richiede l'interfaccia della riga di comando di Databricks. Per informazioni sull'installazione dell'interfaccia della riga di comando di Databricks, vedere Installare o aggiornare l'interfaccia della riga di comando di Databricks.
Avviare l'autenticazione U2M OAuth, come indicato di seguito:
Usare il Databricks CLI per avviare la gestione dei token OAuth in locale eseguendo il seguente comando per ogni area di lavoro di destinazione.
Nel seguente comando, sostituire
<workspace-url>con l’URL per l'area di lavoro di Azure Databricks, per esempiohttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Suggerimento
Per usare il calcolo serverless con Databricks Connect, consulta Configurare una connessione al calcolo serverless.
Il Databricks CLI richiede di salvare le informazioni immesse come profilo di configurazione di Azure Databricks. Premere
Enterper accettare il nome del profilo suggerito oppure immettere il nome di un profilo nuovo o esistente. Qualsiasi profilo esistente con lo stesso nome viene sovrascritto con le informazioni immesse. È possibile usare i profili per cambiare rapidamente il contesto di autenticazione tra più aree di lavoro.Per ottenere un elenco di profili esistenti, in un terminale o un prompt dei comandi separato, usare la CLI di Databricks per eseguire il comando
databricks auth profiles. Per visualizzare le impostazioni esistenti di un profilo specifico, eseguire il comandodatabricks auth env --profile <profile-name>.Nel Web browser completare le istruzioni visualizzate per accedere all'area di lavoro di Azure Databricks.
Nell'elenco dei cluster disponibili visualizzati nel terminale o nel prompt dei comandi usare i tasti freccia su e freccia giù per selezionare il cluster Azure Databricks di destinazione nell'area di lavoro e quindi premere
Enter. È anche possibile digitare qualsiasi parte del nome visualizzato del cluster per filtrare l'elenco dei cluster disponibili.Per visualizzare il valore corrente del token OAuth di un profilo e il timestamp di scadenza imminente del token, eseguire uno dei comandi seguenti:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se si dispone di più profili con lo stesso valore
--host, potrebbe essere necessario specificare insieme le opzioni--hoste-pper consentire al Databricks CLI di trovare le informazioni corrette corrispondenti sul token OAuth.
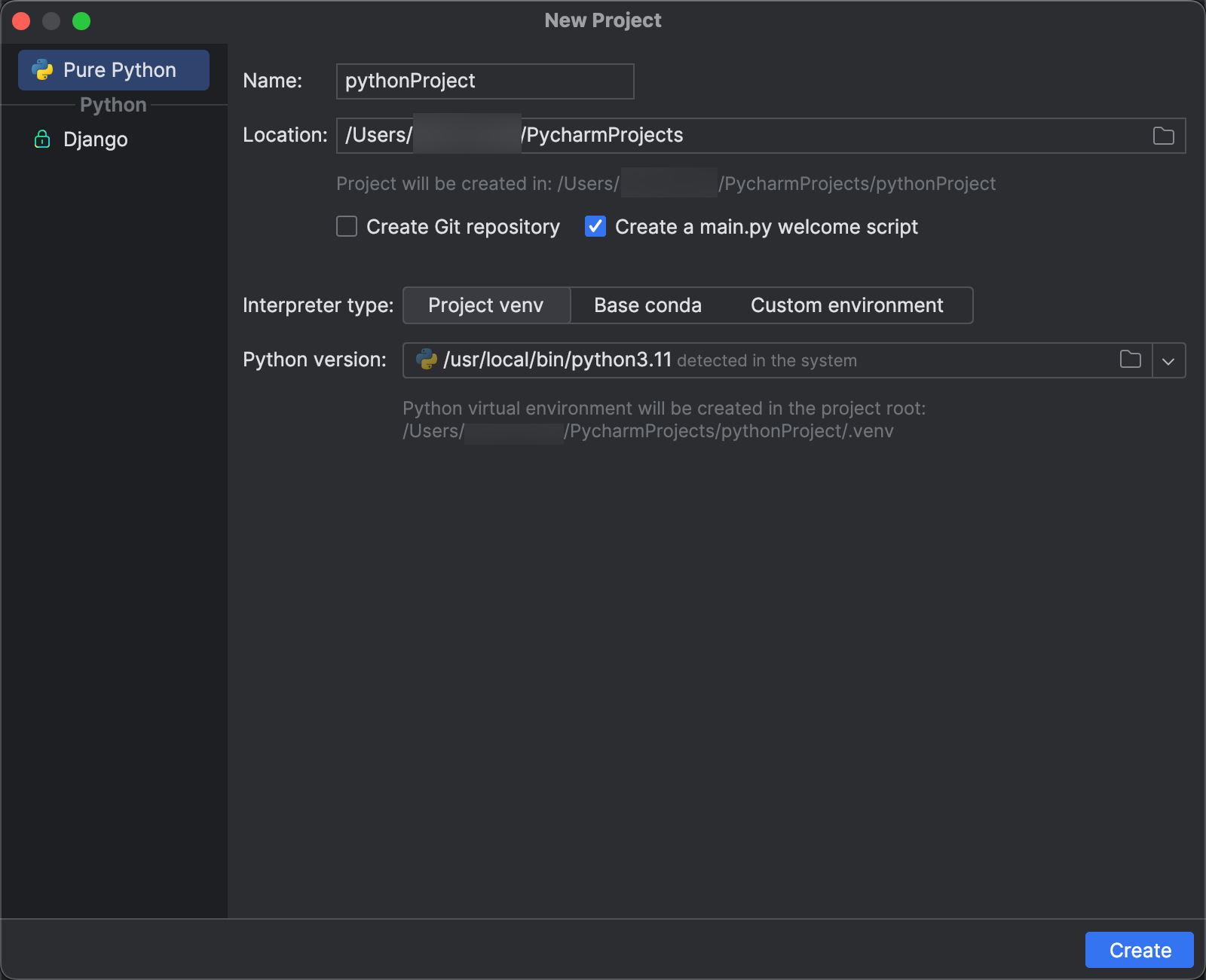
Step 2: Creare il progetto
- Avviare PyCharm.
- Dal menu principale, fare click su File > Nuovo progetto.
- Nella finestra di dialogo Nuovo progetto fare clic su Pure Python.
- Per Percorso fare clic sull'icona della cartella e completare le istruzioni visualizzate per specificare il percorso del nuovo progetto Python.
- Lasciare selezionata l'opzione Crea un main.py script di benvenuto.
- Per Tipo di interprete, fare clic su Progetto venv.
- Espandere Versione di Python e usare l'icona della cartella o l'elenco a discesa per specificare il percorso dell'interprete Python dai requisiti precedenti.
- Cliccare su Crea.
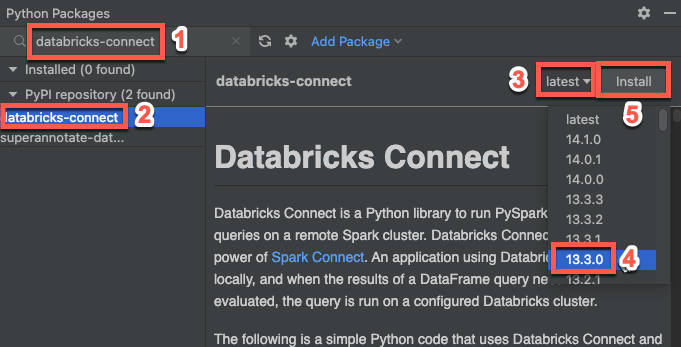
Passaggio 3: Aggiungere il pacchetto Databricks Connect
- Nel menu principale di PyCharm, fai clic su Visualizza > Finestra degli strumenti > Pacchetti Python.
- Nella casella di ricerca immettere
databricks-connect. - Nell'elenco del repository PyPI, fare clic su databricks-connect.
- Nell'elenco a discesa più recente del riquadro dei risultati selezionare la versione corrispondente alla versione di Databricks Runtime del cluster. Ad esempio, se nel cluster è installato Databricks Runtime 14.3, selezionare 14.3.1.
- Fare clic su Installa pacchetto.
- Dopo l'installazione del pacchetto, è possibile chiudere la finestra Pacchetti Python.
Passaggio 4: Aggiungere codice
Nella finestra Strumento progetto fare clic con il pulsante destro del mouse sulla cartella radice del progetto e scegliere Nuovo > file Python.
Immettere
main.pye fare doppio clic su File Python.Immettere il codice seguente nel file e quindi salvare il file, a seconda del nome del profilo di configurazione.
Se il profilo di configurazione del passaggio 1 è denominato
DEFAULT, immettere il codice seguente nel file e quindi salvare il file:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Se il profilo di configurazione del passaggio 1 non è denominato
DEFAULT, immettere il codice seguente nel file. Sostituire il segnaposto<profile-name>con il nome del profilo di configurazione del passaggio 1 e quindi salvare il file:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Passaggio 5: Eseguire il codice
- Avviare il cluster di destinazione nell'area di lavoro remota di Azure Databricks.
- Dopo l'avvio del cluster, nel menu principale fare clic su Esegui > Esegui 'main'.
- Nella finestra strumenti Run (Visualizza > Tool Windows > Run), nel riquadro principale della scheda Run, appaiono le prime 5 righe di
samples.nyctaxi.trips.
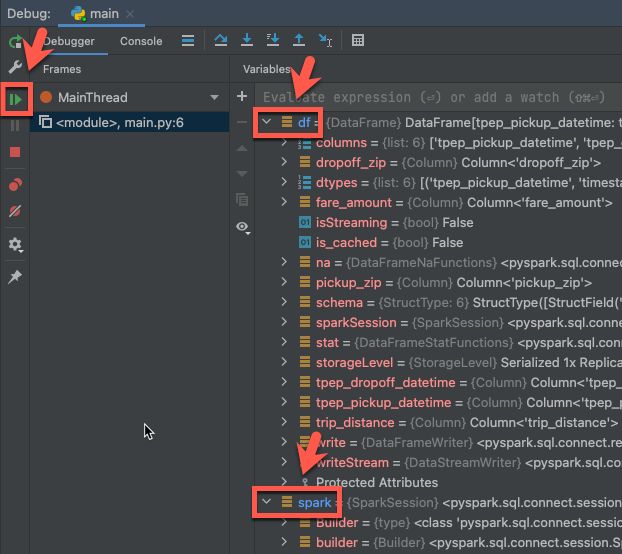
Passaggio 6: Eseguire il debug del codice
- Con il cluster ancora in esecuzione, nel codice precedente fare clic sul margine accanto a
df.show(5)per impostare un punto di interruzione. - Nel menu principale fare clic su Esegui > debug 'main'.
- Nella finestra Debug (Visualizza > Finestre > degli strumenti > Debug), nella scheda Debugger nel riquadro Variabili, espandere i nodi delle variabili df e
dfper esplorare le informazioni sul codice esparke variabili. - Nella barra laterale della finestra dello strumento di debug fare clic sulla freccia verde (Riprendi programma).
- Nel riquadro Console della scheda Debugger vengono visualizzate le prime 5 righe dell'oggetto
samples.nyctaxi.trips.
Passaggi successivi
Per altre informazioni su Databricks Connect, vedere articoli come i seguenti:
- Per usare un tipo di autenticazione diverso, vedere Configurare le proprietà di connessione.
- Utilizzare Databricks Connect insieme ad altri IDE, server notebook e shell Spark.
- Per visualizzare altri esempi di codice semplice, vedere Esempi di codice per Databricks Connect per Python.
- Per visualizzare esempi di codice più complessi, vedere le applicazioni di esempio per il repository Databricks Connect in GitHub, in particolare:
- Per usare le utilità di Databricks con Databricks Connect, vedere Utilità di Databricks con Databricks Connect per Python.
- Per eseguire la migrazione da Databricks Connect per Databricks Runtime 12.2 LTS e versioni successive a Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive, vedere Eseguire la migrazione a Databricks Connect per Python.
- Vedere anche informazioni sulla risoluzione dei problemi e sulle limitazioni.