Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come creare endpoint e indici di ricerca vettoriali usando Mosaic AI Vector Search.
È possibile creare e gestire componenti di ricerca vettoriale, ad esempio un endpoint di ricerca vettoriale e indici di ricerca vettoriale, usando l'interfaccia utente, l'SDK Python o l'API REST.
Ad esempio, per i notebook che illustrano come creare ed eseguire query sugli endpoint di ricerca vettoriale, consultare Notebook di esempio di ricerca vettoriale. Per informazioni di riferimento, vedere le informazioni di riferimento Python SDK.
Requisiti
- Area di lavoro con Unity Catalog abilitato.
- Calcolo serverless attivato. Per le istruzioni, consulta Connetti al calcolo senza server.
- Per gli endpoint standard, la tabella di origine deve avere il feed di dati delle modifiche abilitato. Consulta Usare il feed di dati di modifica di Delta Lake in Azure Databricks.
- Per creare un indice di ricerca vettoriale, è necessario disporre di CREATE TABLE privilegi sullo schema del catalogo in cui verrà creato l'indice.
- Per eseguire una query su un indice di proprietà di un altro utente, è necessario disporre di privilegi aggiuntivi. Vedere Come eseguire query su un indice di ricerca vettoriale.
L'autorizzazione per creare e gestire gli endpoint di ricerca vettoriali viene configurata usando gli elenchi di controllo di accesso. Vedere ACL dell'endpoint di ricerca vettoriale.
Installazione
Per usare l'SDK di ricerca vettoriale, è necessario installarlo nel notebook. Usare il codice seguente per installare il pacchetto:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Usare quindi il comando seguente per importare VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Per informazioni sull'autenticazione, vedere Protezione dei dati e autenticazione.
Creare un endpoint di ricerca vettoriale
È possibile creare un endpoint di ricerca vettoriale usando l'interfaccia utente di Databricks, Python SDK o l'API.
Creare un endpoint di ricerca vettoriale usando l'interfaccia utente
Seguire questa procedura per creare un endpoint di ricerca vettoriale usando l'interfaccia utente.
Nella barra laterale sinistra fare clic su Calcolo.
Fare clic sulla scheda Ricerca vettoriale e fare clic su Crea endpoint.
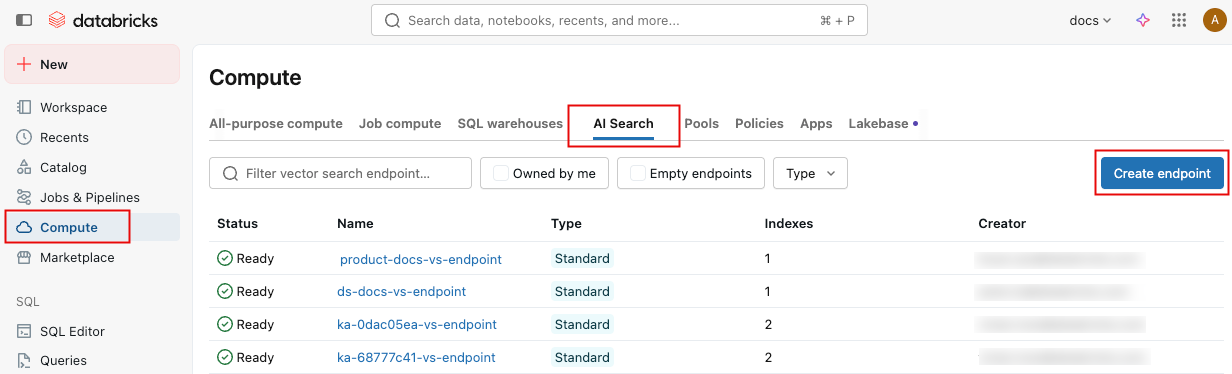
Si apre il modulo Crea un endpoint. Immettere un nome per questo endpoint.
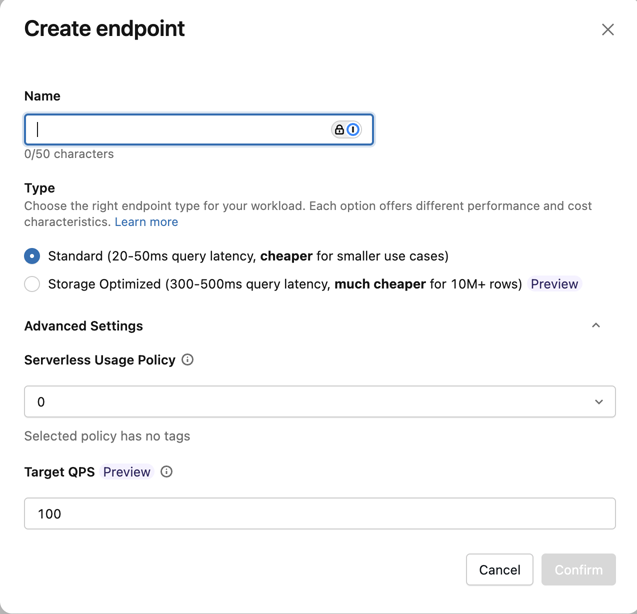
Nel campo Tipo selezionare Standard o Ottimizzato per l'archiviazione. Vedere Opzioni endpoint.
(Facoltativo) In Impostazioni avanzate, selezionare un criterio di budget. Vedere Criteri di budget per la ricerca vettoriale.
Cliccare Conferma.
Creare un endpoint di ricerca vettoriale usando Python SDK
Nell'esempio seguente viene usata la funzione create_endpoint() SDK per creare un endpoint di ricerca vettoriale.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Creare un endpoint di ricerca vettoriale usando l'API REST
Consultare la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/endpoints.
** Creare un endpoint con un obiettivo QPS minimo per carichi di lavoro ad elevata velocità effettiva
Importante
Questa funzionalità è in versione beta. Gli amministratori dell'area di lavoro possono controllare l'accesso a questa funzionalità dalla pagina Anteprime . Consulta Gestisci anteprime Azure Databricks.
Per i carichi di lavoro con throughput elevato, è possibile creare un endpoint con un obiettivo QPS minimo. Questa funzionalità è disponibile solo per gli endpoint standard.
Per impostare una destinazione QPS minima, usare il min_qps parametro . Consulta Aumentare la capacità di trasmissione degli endpoint con un alto QPS (Beta).
Importante
L'impostazione min_qps fornisce capacità aggiuntiva, aumentando il costo dell'endpoint. Questa capacità aggiuntiva viene addebitata indipendentemente dal traffico effettivo delle query. Per interrompere l'addebito di questi addebiti, reimpostare l'endpoint usando min_qps=-1. Il ridimensionamento della velocità effettiva è il massimo sforzo e non è garantito durante la versione Beta.
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
min_qps=500, # Beta: minimum QPS target for high-throughput workloads
)
Per modificare il valore QPS minimo in un endpoint esistente, usare update_endpoint().
from databricks.vector_search.client import VectorSearchClient, MIN_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update minimum QPS
response = client.update_endpoint(name="vector_search_endpoint_name", min_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", min_qps=MIN_QPS_RESET_TO_DEFAULT)
Dopo l'aggiornamento del QPS minimo, sincronizzare gli indici per applicare la nuova configurazione.
(Facoltativo) Creare e configurare un endpoint per gestire il modello di incorporamento
Se si sceglie di usare databricks per calcolare gli incorporamenti, è possibile usare un endpoint delle API del modello di base preconfigurato o creare un endpoint di gestione di un modello per gestire il modello di incorporamento preferito. Per istruzioni, vedere API modello di base con pagamento in base al token o Creare un modello di base che gestisce gli endpoint. Per notebook di esempio, vedere Notebook di esempio di ricerca vettoriale.
Quando configuri un endpoint di embedding, Databricks consiglia di rimuovere la selezione predefinita di Riduci a zero. Gli endpoint di servizio possono richiedere un paio di minuti per scaldarsi, e la query iniziale su un indice con un endpoint ridimensionato può andare in timeout.
Annotazioni
L'inizializzazione dell'indice di ricerca vettoriale potrebbe scadere se l'endpoint di incorporamento non è configurato in modo appropriato per il set di dati. È consigliabile usare solo endpoint CPU per set di dati e test di piccole dimensioni. Per set di dati di dimensioni maggiori, usare un endpoint GPU per ottenere prestazioni ottimali.
Creare un indice di ricerca vettoriale
È possibile creare un indice di ricerca vettoriale usando l'interfaccia utente, l'SDK di Python o l'API REST. L'interfaccia utente è l'approccio più semplice.
Esistono due tipi di indici:
- indice di sincronizzazione delta sincronizza automaticamente con una tabella delta di origine, aggiornando automaticamente e in modo incrementale l'indice man mano che cambiano i dati sottostanti nella tabella Delta.
- Direct Vector Access Index supporta la lettura diretta e scrittura di vettori e metadati. L'utente è responsabile dell'aggiornamento di questa tabella usando l'API REST o l'SDK di Python. Questo tipo di indice non può essere creato usando l'interfaccia utente. È necessario usare l'API REST o l'SDK.
Gli indici di sincronizzazione delta supportano le modalità di ricerca seguenti:
-
Ricerca vettoriale (ANN o ibrida): richiede l'incorporamento di colonne. Supporta endpoint sia standard che ottimizzati per l'archiviazione. È anche possibile usare
query_type="FULL_TEXT"per la ricerca di parole chiave in questi indici. - Indice di ricerca full-text dedicato (Beta): Indice di Sincronizzazione Delta creato senza colonne di embedding, per la ricerca esclusivamente di parole chiave. Disponibile solo sugli endpoint ottimizzati per l'archiviazione usando la modalità di sincronizzazione attivata. Vedere Creare un indice di ricerca full-text.
Annotazioni
Il nome _id della colonna è riservato. Se la tabella di origine contiene una colonna denominata _id, rinominarla prima di creare un indice di ricerca vettoriale.
Creare un indice usando l'interfaccia utente
Nella barra laterale sinistra fare clic su Catalogo per aprire l'interfaccia utente di Esplora cataloghi.
Passare alla tabella Delta da usare.
Fare clic sul pulsante crea in alto a destra e selezionare Indice di Ricerca Vettoriale dal menu a discesa.
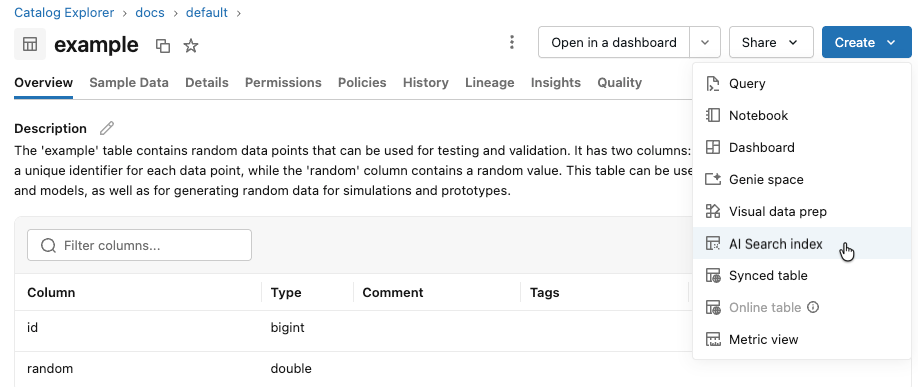
Usare i selettori nella finestra di dialogo per configurare l'indice.
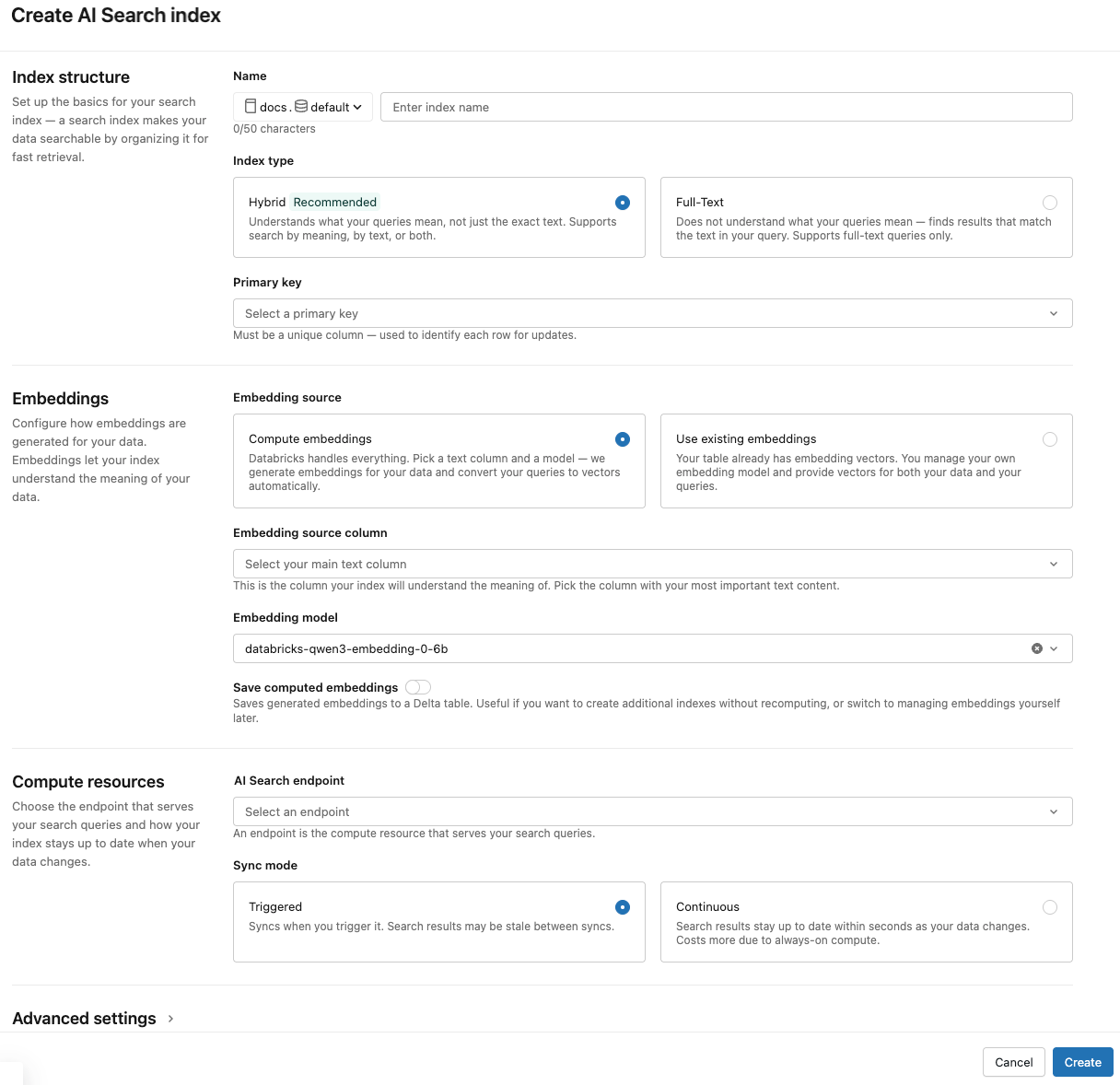
Nome: Nome da usare per la tabella online nel Catalogo Unity. Il nome richiede un namespace a tre livelli,
<catalog>.<schema>.<name>. Sono consentiti solo caratteri alfanumerici e caratteri di sottolineatura.chiave primaria: colonna da usare come chiave primaria.
Colonne da sincronizzare: selezionare le colonne da sincronizzare con l'indice vettoriale. Se si lascia vuoto questo campo, tutte le colonne della tabella di origine vengono sincronizzate con l'indice. La colonna chiave primaria e la colonna di origine di incorporamento o la colonna vettoriale di incorporamento vengono sempre sincronizzate.
Fonte di embedding: Indicare se si vuole che Databricks calcoli gli embedding per una colonna di testo nella tabella Delta (Calcolare embedding) o se la tabella Delta contiene embedding precompilati (Utilizzare la colonna di embedding esistente).
Se sono stati selezionati incorporamenti di calcolo, selezionare la colonna per cui si vogliono incorporare gli incorporamenti e il modello di incorporamento da usare per il calcolo. Sono supportate solo le colonne di testo.
Per le applicazioni di produzione che usano endpoint standard, Databricks consiglia di usare il modello foundation
databricks-gte-large-encon un endpoint di servizio con capacità throughput provisionata.Per le applicazioni di produzione che usano endpoint ottimizzati per l'archiviazione con modelli ospitati in Databricks, usare direttamente il nome del modello (ad esempio,
databricks-gte-large-en) come endpoint del modello di incorporamento. Gli endpoint ottimizzati per l'archiviazione usanoai_querycon inferenza batch in fase di inserimento, offrendo una velocità effettiva elevata per il processo di incorporamento. Se si preferisce usare un endpoint di throughput con provisioning per l'esecuzione di query, specificarlo nel campomodel_endpoint_name_for_queryquando si crea l'indice.
Se è stata selezionata Usa colonna di embedding esistente, selezionare la colonna contenente gli embedding precomputati e la dimensione di embedding. Il formato della colonna di incorporamento pre-calcolata deve essere
array[float]. Per gli endpoint ottimizzati per l'archiviazione, la dimensione di incorporamento deve essere divisibile in modo uniforme per 16.
Sincronizza gli embeddings calcolati: Attiva o disattiva questa impostazione per salvare gli embeddings generati in una tabella del catalogo Unity. Per ulteriori informazioni, vedere Tabella di embedding generata.
Endpoint di ricerca vettoriale: selezionare l'endpoint di ricerca vettoriale per archiviare l'indice.
modalità di sincronizzazione: continua mantiene la sincronizzazione dell'indice con i secondi di latenza. Tuttavia, è associato a costi più elevati poiché viene effettuato il provisioning di un cluster di calcolo per eseguire la pipeline di streaming di sincronizzazione continua.
- Per gli endpoint standard, sia continuous che triggered eseguono aggiornamenti incrementali, quindi vengono elaborati solo i dati modificati dall'ultima sincronizzazione.
- Per gli endpoint ottimizzati per l'archiviazione, ogni sincronizzazione ricompila parzialmente l'indice. Per gli indici gestiti nelle sincronizzazioni successive, gli incorporamenti generati in cui la riga di origine non è stata modificata vengono riutilizzate e non devono essere ricalcolate. Vedere Limitazioni degli endpoint ottimizzati per l'archiviazione.
Con Triggered modalità di sincronizzazione, usare Python SDK o l'API REST per avviare la sincronizzazione. Vedere Aggiornare un indice di sincronizzazione delta.
Per gli endpoint ottimizzati per l'archiviazione, è supportata solo la modalità di sincronizzazione attivata .
Impostazioni avanzate: (facoltativo)
È possibile applicare criteri di budget all'indice. Vedere Criteri di budget per la ricerca vettoriale.
Se hai selezionato Calcolare gli incorporamenti, puoi specificare un modello di incorporamento separato per effettuare query nel tuo indice di ricerca vettoriale. Ciò può essere utile se è necessario un endpoint con velocità effettiva elevata per l'inserimento, ma un endpoint di latenza inferiore per l'esecuzione di query sull'indice. Il modello specificato nel campo Modello di incorporamento viene sempre usato per l'inserimento e viene usato anche per l'esecuzione di query, a meno che non si specifichi un modello diverso. Per specificare un modello diverso, fare clic su Scegliere un modello di incorporamento separato per l'esecuzione di query sull'indice e selezionare un modello dal menu a discesa.

Al termine della configurazione dell'indice, fare clic su Crea.
Creare un indice con Python SDK
Nell'esempio seguente viene creato un indice di sincronizzazione Delta con embedding calcolati da Databricks. Per informazioni dettagliate, vedere le informazioni di riferimento Python SDK.
In questo esempio viene illustrato anche il parametro facoltativo model_endpoint_name_for_query, che specifica un endpoint di modello di embedding separato da usare per interrogare l'indice.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
Nell'esempio seguente viene creato un indice Delta Sync con incorporamenti autogestiti.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Per impostazione predefinita, tutte le colonne della tabella di origine vengono sincronizzate con l'indice. Per selezionare un subset di colonne da sincronizzare, usare columns_to_sync. La chiave primaria e le colonne di incorporazione sono sempre incluse nell'indice.
Per sincronizzare solo la chiave primaria e la colonna di incorporamento, è necessario specificarli in columns_to_sync come illustrato:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Per sincronizzare colonne aggiuntive, specificarle come illustrato. Non è necessario includere la chiave primaria e la colonna embedding, perché vengono sempre sincronizzate.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Creare un indice di ricerca full-text (Beta)
Importante
La creazione dell'indice di ricerca full-text è disponibile solo come funzionalità beta sugli endpoint ottimizzati per l'archiviazione. Per usarla, è necessario abilitare l'anteprima dell'area vs_full_text di lavoro. Contatta il team del tuo account o consulta Gestione delle anteprime di Azure Databricks per attivare le anteprime.
Un indice di ricerca full-text consente la ricerca basata su parole chiave sulle colonne di testo senza richiedere incorporamenti vettoriali. Ciò è utile quando si desidera cercare termini, identificatori o parole chiave esatte anziché somiglianza semantica.
Gli indici di ricerca full-text hanno i requisiti seguenti:
- Deve usare un endpoint ottimizzato per l'archiviazione . Gli endpoint standard non sono supportati.
- Deve usare la modalità di sincronizzazione attivata . La sincronizzazione continua non è supportata.
- I parametri
embedding_source_column,embedding_vector_columneembedding_dimensionnon sono supportati.
L'esempio seguente crea un indice di ricerca full-text usando Python SDK.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
Dopo aver creato l'indice, attivare una sincronizzazione per popolarla:
index.sync()
Per eseguire una query sull'indice full-text, usare query_type="FULL_TEXT". Per informazioni dettagliate, vedere Eseguire query su un indice di ricerca vettoriale .
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
Nell'esempio seguente viene creato un indice di accesso a vettori diretti.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Creare un indice usando l'API REST
Consulta la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes.
Salva tabella di incorporamento generata
Se Databricks genera gli incorporamenti, è possibile salvare gli incorporamenti generati in una tabella in Unity Catalog. Questa tabella viene creata nello stesso schema dell'indice vettoriale ed è collegata dalla pagina dell'indice vettoriale.
Il nome della tabella è il nome dell'indice di ricerca vettoriale, aggiunto da _writeback_table. Il nome non è modificabile.
È possibile accedere ed eseguire query sulla tabella come su qualsiasi altra tabella nel Catalogo Unity. Tuttavia, non è consigliabile eliminare o modificare la tabella, perché non deve essere aggiornata manualmente. La tabella viene eliminata automaticamente se l'indice viene eliminato.
Aggiornare un indice di ricerca vettoriale
Aggiornare un Indice di Sincronizzazione Delta
Gli indici creati con la modalità di sincronizzazione continua si aggiornano automaticamente quando cambia la tabella Delta di origine. Se si usa Triggered modalità di sincronizzazione, è possibile avviare la sincronizzazione usando l'interfaccia utente, Python SDK o l'API REST.
Interfaccia utente di Databricks
In Esplora cataloghi passare all'indice di ricerca vettoriale.
Nella sezione Inserimento dati della scheda Panoramica fare clic su Sincronizza.
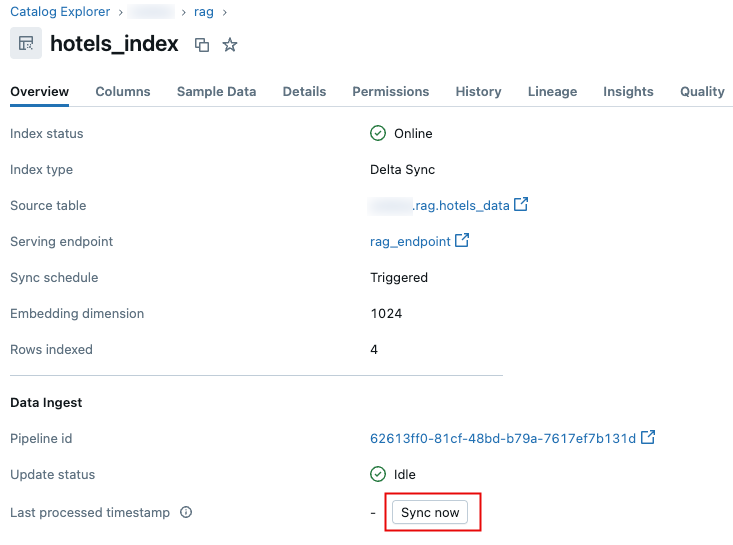
PYTHON SDK
Per informazioni dettagliate, vedere le informazioni di riferimento Python SDK.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
Consultare la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Aggiornare un indice di accesso diretto ai vettori
È possibile usare l'SDK di Python o l'API REST per inserire, aggiornare o eliminare dati da un indice di accesso a vettore diretto.
PYTHON SDK
Per informazioni dettagliate, vedere le informazioni di riferimento Python SDK.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
Consulta la documentazione di riferimento dell'API REST: POST /api/2.0/vector-search/indexes.
Per le applicazioni di produzione, Databricks consiglia di usare principali di servizio anziché token di accesso personali. Le prestazioni possono essere migliorate di fino a 100 millisecondi per ogni query.
Nell'esempio di codice seguente viene illustrato come aggiornare un indice usando un'entità servizio.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Nell'esempio di codice seguente viene illustrato come aggiornare un indice usando un token di accesso personale (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Come apportare modifiche allo schema senza tempi di inattività
Le modifiche dello schema alla tabella di origine non sono supportate a meno che non si ricompila l'indice. Ciò include la modifica delle colonne esistenti e l'aggiunta di nuove colonne. Lo schema dell'indice è fisso in fase di creazione, pertanto tutte le modifiche dello schema richiedono la creazione di un nuovo indice per rendere effettivo.
Seguire questa procedura per ricompilare e distribuire l'indice senza tempi di inattività:
- Eseguire la modifica dello schema nella tabella di origine.
- Creare un nuovo indice usando lo schema aggiornato.
- Dopo aver pronto il nuovo indice, passare il traffico al nuovo indice.
- Eliminare l'indice originale.