Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Compilare e distribuire il primo agente di intelligenza artificiale usando i modelli di App di Databricks. In questa esercitazione:
- Compilare e distribuire l'agente dall'interfaccia utente di Databricks Apps.
- Chat con l'agente usando un'interfaccia di chat predefinita.
Prerequisiti
Abilitare Le app di Databricks nell'area di lavoro. Vedere Configurare l'area di lavoro e l'ambiente di sviluppo di Databricks Apps.
Distribuire il modello di agente
Introduzione all'uso di un modello di agente predefinito dal repository dei modelli di app Databricks.
Questa esercitazione usa il modello agent-openai-agents-sdk, che include:
- Un agente creato con OpenAI Agent SDK
- Codice di avvio per un'applicazione agente con un'API REST di conversazione e un'interfaccia utente di chat interattiva
- Codice per valutare l'agente usando MLflow
Installare il modello di app usando l'interfaccia utente dell'area di lavoro. In questo modo l'app viene installata e distribuita in una risorsa di calcolo nell'area di lavoro.
Nell'area di lavoro di Databricks fare clic su + Nuova>app.
Fare clic su Agenti>Agenti - SDK di OpenAI Agents.
Creare un nuovo esperimento MLflow con il nome
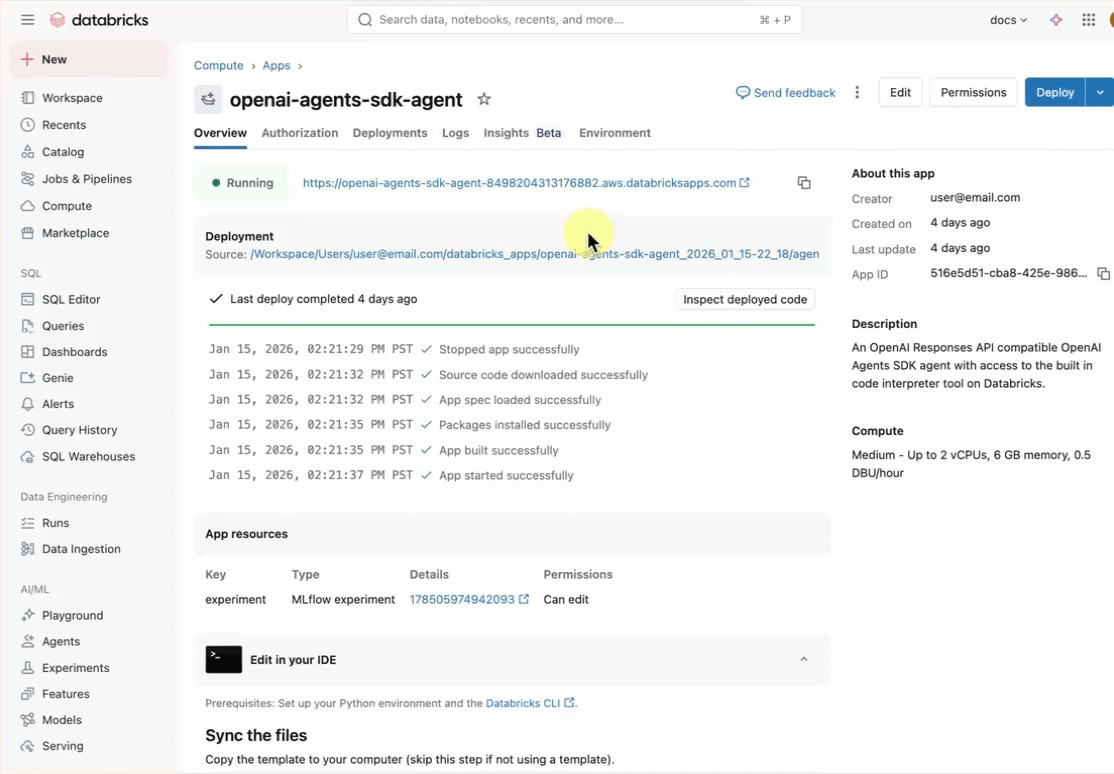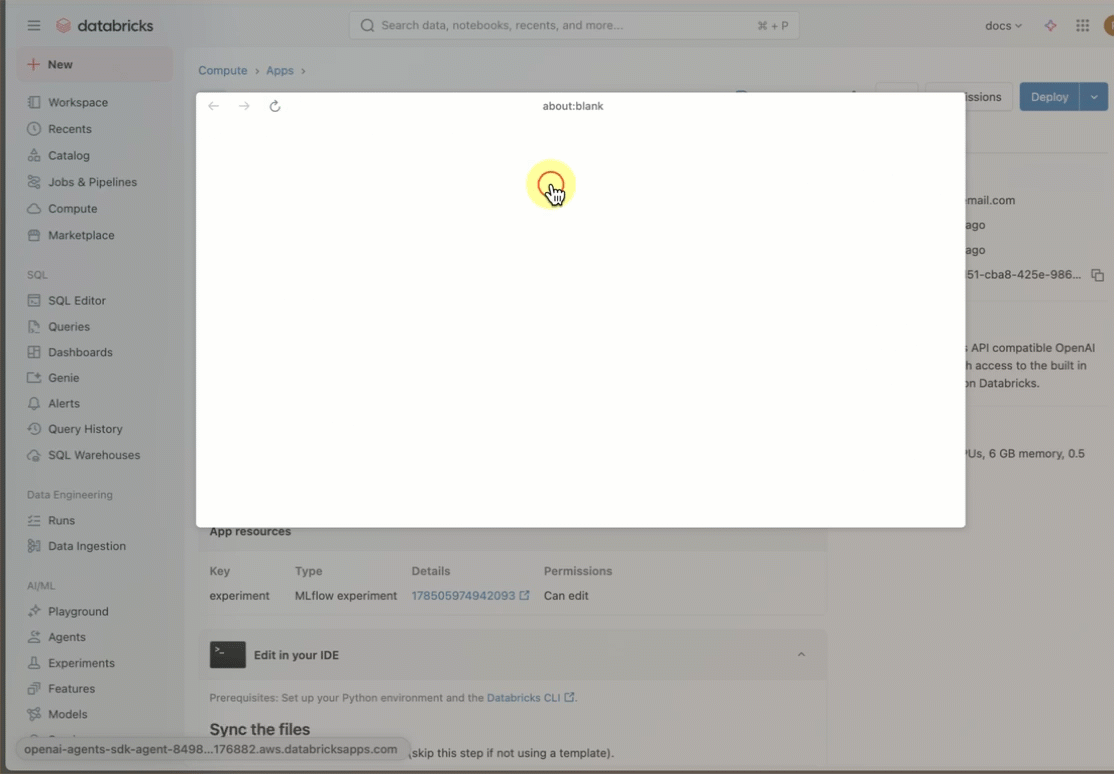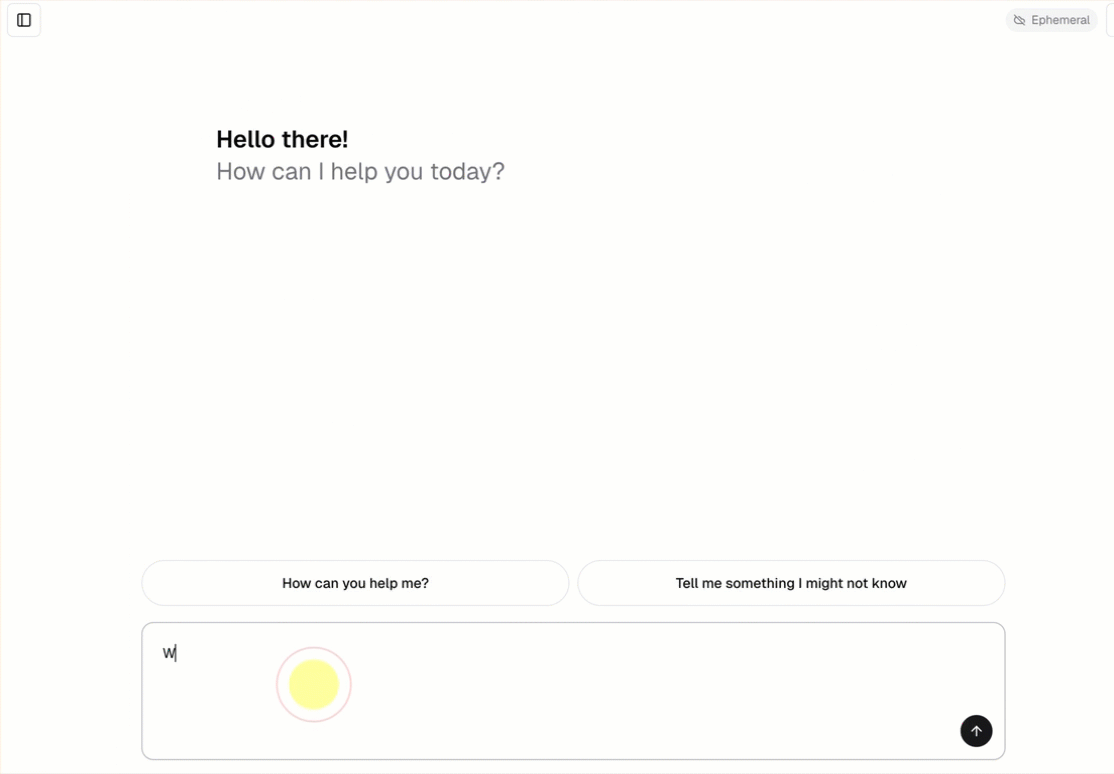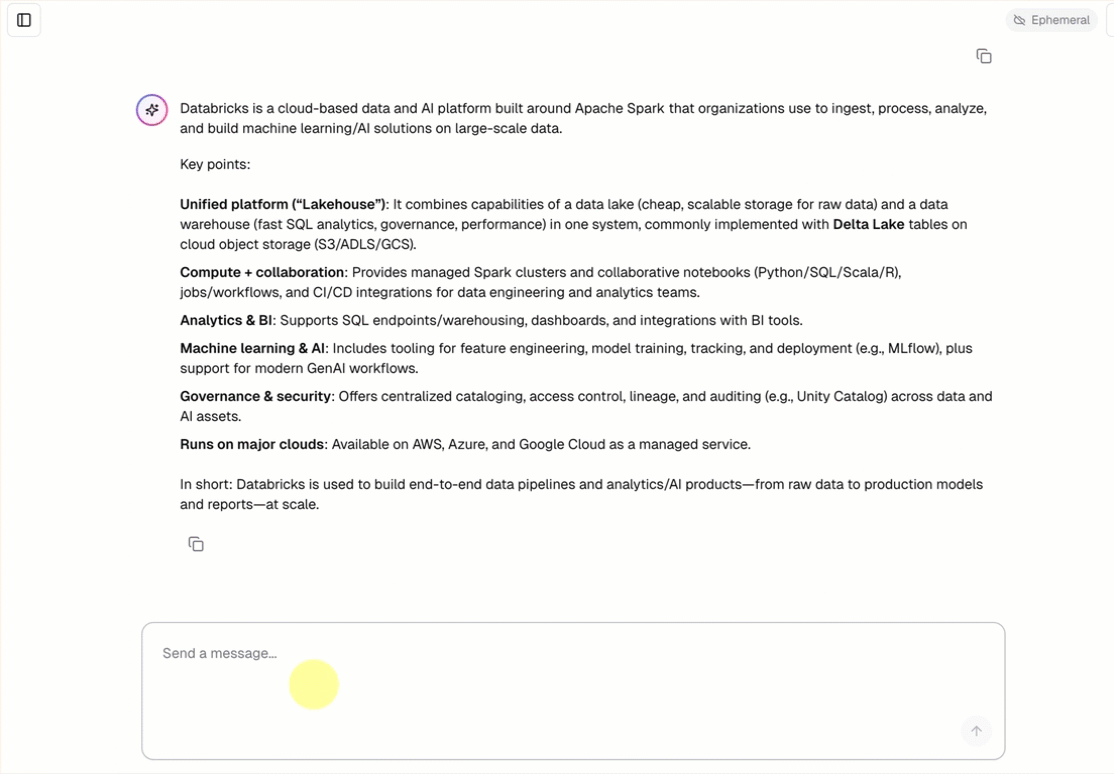
openai-agents-templatee completare il resto della configurazione per installare il modello.Dopo aver creato l'app, fare clic sull'URL dell'app per aprire l'interfaccia utente della chat.
Informazioni sull'applicazione agente
Il modello di agente illustra un'architettura pronta per la produzione con questi componenti chiave:
MLflow AgentServer: server FastAPI asincrono che gestisce le richieste degli agenti con traccia e osservabilità predefinite. AgentServer fornisce l'endpoint per l'esecuzione di query sull'agente /invocations e gestisce automaticamente il routing delle richieste, la registrazione e la gestione degli errori.
OpenAI Agents SDK: il modello usa OpenAI Agents SDK come framework agente per la gestione delle conversazioni e l'orchestrazione degli strumenti. È possibile creare agenti usando qualsiasi framework. La chiave è eseguire il wrapping del proprio agente con l'interfaccia MLflow ResponsesAgent.
ResponsesAgent interfaccia: questa interfaccia garantisce che l'agente funzioni in framework diversi e si integra con gli strumenti di Databricks. Compila il tuo agente usando l’SDK di OpenAI, LangGraph, LangChain o Python puro, quindi incapsularlo con ResponsesAgent per ottenere la compatibilità automatica con AI Playground, valutazione dell’agente e distribuzione delle app Databricks.
Server MCP (Model Context Protocol): il modello si connette ai server MCP di Databricks per accedere agli agenti a strumenti e origini dati. Vedere Model Context Protocol (MCP) in Databricks.

Passaggi successivi
Informazioni su come creare un agente personalizzato: creare un agente di intelligenza artificiale e distribuirlo in Databricks Apps