Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come creare una nuova pipeline usando le pipeline dichiarative di Lakeflow Spark (SDP) per l'orchestrazione dei dati e il caricatore automatico. Questa esercitazione estende la pipeline di esempio pulendo i dati e creando una query per trovare i primi 100 utenti.
In questa esercitazione si apprenderà come usare l'editor di Pipelines Lakeflow per:
- Creare una nuova pipeline con la struttura di cartelle predefinita e iniziare con un set di file di esempio.
- Definire vincoli di qualità dei dati usando le aspettative.
- Usare le funzionalità dell'editor per estendere la pipeline con una nuova trasformazione per eseguire analisi sui dati.
Requisiti
Prima di iniziare questa esercitazione, è necessario:
- Accedere a un'area di lavoro Azure Databricks.
- Abilitare Unity Catalog per l'area di lavoro.
- Disporre dell'autorizzazione per creare una risorsa di calcolo o accedere a una risorsa di calcolo.
- Disporre delle autorizzazioni per creare un nuovo schema in un catalogo. Le autorizzazioni necessarie sono
ALL PRIVILEGESoUSE CATALOGeCREATE SCHEMA.
Passaggio 1: creare una pipeline
In questo passaggio si crea una pipeline usando la struttura di cartelle predefinita e gli esempi di codice. Gli esempi di codice fanno riferimento alla tabella users nei dati di esempio wanderbricks.
Nell'area di lavoro Azure Databricks fare clic su
 Nuovo quindi
Nuovo quindi  ETL pipeline. Verrà aperto l'editor della pipeline con un nome di pipeline predefinito, ad esempio
ETL pipeline. Verrà aperto l'editor della pipeline con un nome di pipeline predefinito, ad esempio New Pipeline <date> <time>.(Facoltativo) Selezionare il nome e immettere un nome descrittivo per la pipeline.
(Facoltativo) A destra del nome fare clic sul catalogo e sullo schema per impostare valori predefiniti diversi.
(Facoltativo) Nel file di origine
my_transformationcreato, selezionare Python o SQL dall'elenco a discesa della lingua per impostare la lingua per il file.Fare clic
 Usare il codice di esempio.
Usare il codice di esempio.Il codice di esempio nella lingua selezionata viene visualizzato nel
my_transformationfile di origine nellatransformationscartella . I set di dati di output non sono ancora stati creati e il grafico Pipeline a destra della schermata è vuoto.Per eseguire il codice della pipeline (il codice nella
transformationscartella), fare clic su Esegui pipeline nella parte superiore destra della schermata.Al termine dell’esecuzione, la parte inferiore dell’area di lavoro mostra le due nuove tabelle create,
sample_users_<date_time>esample_aggregation_<date_time>. Il grafico della pipeline sul lato destro dell'area di lavoro mostra ora le due tabelle, incluso il fatto chesample_usersè l'origine disample_aggregation. Prendi nota del nome completo della tabellasample_users_<date_time>: ti servirà nel passaggio successivo.
Passaggio 2: Applicare i controlli di qualità dei dati
In questo passaggio si aggiunge un controllo qualità dei dati alla sample_users tabella. Si usano le condizioni della pipeline per vincolare i dati. In questo caso, si eliminano tutti i record utente che non dispongono di un indirizzo di posta elettronica valido e si restituisce la tabella pulita come users_cleaned.
Nel browser asset della pipeline a sinistra fare clic
e selezionare Trasformazione.Nella finestra di dialogo Crea nuovo file di trasformazione effettuare le selezioni seguenti:
- Scegliere Python o SQL per Language. Non è necessario che corrisponda alla selezione precedente.
- Assegnare un nome al file. In questo caso scegliere
users_cleaned. - Per Percorso di destinazione lasciare il valore predefinito.
- Per Tipo di set di datilasciare selezionato Nessuno oppure scegliere Visualizzazione materializzata. Se si seleziona Visualizzazione materializzata, viene generato automaticamente il codice di esempio.
Fare clic su Crea per creare il file di codice di trasformazione.
Nel nuovo file di codice modificare il codice in modo che corrisponda al seguente (usare SQL o Python, in base alla selezione nella schermata precedente). Sostituire
sample_users_<date_time>con il nome completo dellasample_userstabella della sezione precedente.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Fare clic su Esegui pipeline per aggiornare la pipeline. Ora dovrebbe avere tre tabelle.
Passaggio 3: Analizzare gli utenti principali
Ottenere quindi i primi 100 utenti in base al numero di prenotazioni create. Unire la wanderbricks.bookings tabella alla users_cleaned vista materializzata.
Nel browser delle risorse della pipeline a sinistra, fare clic
e selezionare Trasformazione.Nella finestra di dialogo Crea nuovo file di trasformazione effettuare le selezioni seguenti:
- Scegliere Python o SQL per Language. Non è necessario che corrispondano alle selezioni precedenti.
- Assegnare un nome al file. In questo caso scegliere
users_and_bookings. - Per Percorso di destinazione lasciare il valore predefinito.
- Per Tipo di set di datilasciare selezionato Nessuno.
Fare clic su Crea per creare il file di codice di trasformazione.
Nel nuovo file di codice modificare il codice in modo che corrisponda al seguente (usare SQL o Python, in base alla selezione nella schermata precedente).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Fare clic su Esegui pipeline per aggiornare i set di dati. Al termine dell'esecuzione, è possibile vedere in Pipeline Graph che sono presenti quattro tabelle, inclusa la nuova
users_and_bookingstabella.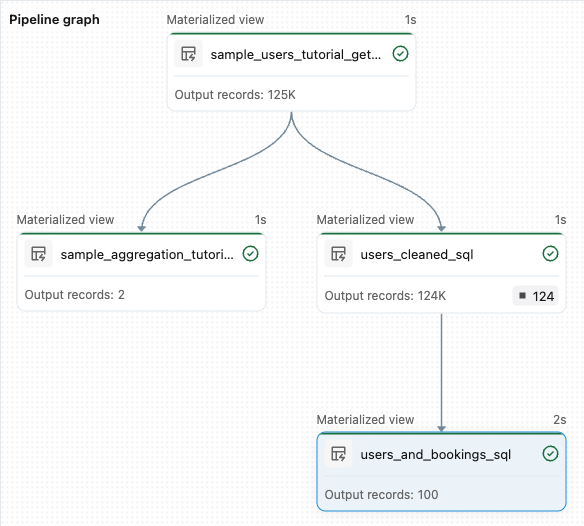
Passaggi successivi
Ora che si è appreso come usare alcune delle funzionalità dell'editor di pipeline Lakeflow e come creare una pipeline, ecco alcune altre funzionalità per altre informazioni:
Strumenti per l'uso e il debug delle trasformazioni durante la creazione di pipeline:
- Esecuzione selettiva
- Anteprime dei dati
- Grafico della pipeline interattiva (grafico dei set di dati nella pipeline)
Integrazione predefinita dei bundle di automazione dichiarativa per una collaborazione efficiente, il controllo delle versioni e l'integrazione CI/CD direttamente dall'editor.