Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Gli esperimenti sono unità organizzative per le esecuzioni di MLflow, incluse le tracce degli agenti, le valutazioni delle applicazioni LLM e le esecuzioni di addestramento del modello. Esistono due tipi di esperimenti: area di lavoro e notebook.
- È possibile creare un esperimento dell'area di lavoro dall'interfaccia utente di Databricks Mosaic AI o dall'API MLflow. Gli esperimenti dell'area di lavoro non sono associati ad alcun notebook e qualsiasi notebook può registrare un'esecuzione a questi esperimenti usando l'ID esperimento o il nome dell'esperimento.
- Un esperimento di notebook è associato a un notebook specifico. Azure Databricks crea automaticamente un esperimento di notebook se non è presente alcun esperimento attivo quando si avvia un'esecuzione usando mlflow.start_run().
Per visualizzare tutti gli esperimenti in un'area di lavoro a cui si ha accesso, selezionare Esperimenti di Machine Learning > nella barra laterale.
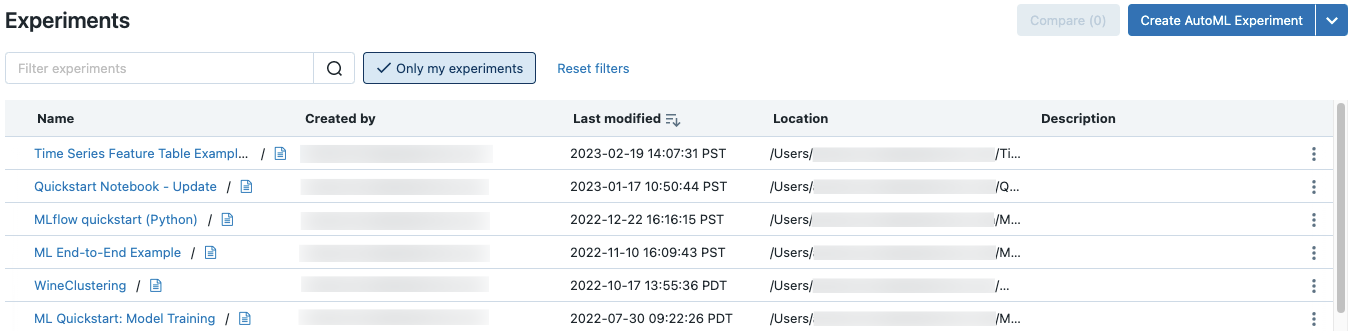
Creare esperimento area di lavoro
Questa sezione descrive come creare un esperimento dell'area di lavoro usando l'interfaccia utente di Azure Databricks. È possibile creare un esperimento dell'area di lavoro direttamente dall'area di lavoro o dalla pagina Esperimenti.
È anche possibile usare l'API MLflow o il provider Databricks Terraform con databricks_mlflow_experiment.
Per istruzioni sulla registrazione delle esecuzioni in esperimenti dell'area di lavoro, vedere Registrare esecuzioni e modelli in un esperimento.
Creare un esperimento dall'area di lavoro
Cliccare
 Area di lavoro nella barra laterale.
Area di lavoro nella barra laterale.Passare alla cartella in cui si vuole creare l'esperimento.
Fare clic con il pulsante destro del mouse sulla cartella e selezionare Crea > esperimento MLflow.
Nella finestra di dialogo "Crea esperimento MLflow," inserisci un nome per l'esperimento e un percorso facoltativo per l'artefatto. Se non si specifica una posizione dell'artefatto, gli artefatti vengono archiviati nell'archiviazione degli artefatti gestiti da MLflow:
dbfs:/databricks/mlflow-tracking/<experiment-id>.Per le aree di lavoro abilitate per Unity Catalog, è anche possibile archiviare gli artefatti in un volume del catalogo Unity. Per archiviare gli artefatti nella propria risorsa di archiviazione cloud, creare un volume esterno del catalogo Unity.
Per archiviare gli artefatti in un volume di Catalogo Unity, specificare un percorso del volume del modulo
dbfs:/Volumes/catalog_name/schema_name/volume_name/user/specified/pathcome percorso dell'artefatto dell'esperimento MLflow, nell'interfaccia utente o come illustrato nel codice seguente:import mlflow # Storing artifacts in a volume requires MLflow 2.15.0 or above EXP_NAME = "/Users/first.last@databricks.com/my_experiment_name" CATALOG = "my_catalog" SCHEMA = "my_schema" VOLUME = "my_volume" ARTIFACT_PATH = f"dbfs:/Volumes/{CATALOG}/{SCHEMA}/{VOLUME}" # can be a managed or external volume mlflow.set_tracking_uri("databricks") mlflow.set_registry_uri("databricks-uc") if mlflow.get_experiment_by_name(EXP_NAME) is None: mlflow.create_experiment(name=EXP_NAME, artifact_location=ARTIFACT_PATH) mlflow.set_experiment(EXP_NAME)Se l'area di lavoro non è abilitata per Unity Catalog o non si ha accesso a MLflow 2.15.0 o versione successiva, specificare un percorso in questo formato:
dbfs:/path/to/artifacts.Databricks consiglia di usare un volume di Unity Catalog per l'archiviazione degli artefatti. Se né un'unità di archiviazione del catalogo Unity né DBFS sono opzioni appropriate, è anche possibile archiviare gli artefatti direttamente nell'archiviazione blob di Azure (non raccomandato). Per archiviare gli artefatti nell'archiviazione BLOB di Azure, specificare un URI che abbia il formato
wasbs://<container>@<storage-account>.blob.core.windows.net/<path>. Gli artefatti archiviati nell'archiviazione BLOB di Azure non vengono visualizzati nell'interfaccia utente di MLflow; è necessario scaricarli usando un client di archiviazione BLOB.Nota
Quando si archivia un artefatto in una posizione diversa dai volumi DBFS gestiti da MLflow (impostazione predefinita) o Unity Catalog, l'artefatto non viene visualizzato nell'interfaccia utente MLflow. I modelli archiviati in posizioni diverse da questi non possono essere registrati nel Registro modelli.
Cliccare Crea. Viene visualizzata la pagina dei dettagli dell'esperimento per il nuovo esperimento.
Per registrare le esecuzioni a questo esperimento, richiamare
mlflow.set_experiment()con il percorso dell'esperimento. Per visualizzare il percorso dell'esperimento, fai clic sull'icona delle informazioni a destra del nome dell'esperimento. Per informazioni dettagliate e un notebook di esempio, vedere Log runs and models to an experiment.
a destra del nome dell'esperimento. Per informazioni dettagliate e un notebook di esempio, vedere Log runs and models to an experiment.
Creare un esperimento dalla pagina Esperimenti
Per creare un modello di base per l'ottimizzazione, l'ottimizzazione automatica o l'esperimento personalizzato, fare clic su Esperimenti o selezionare Nuovo > esperimento nella barra laterale sinistra.
Nella parte superiore della pagina selezionare una delle opzioni seguenti per configurare un esperimento:
- Messa a punto fine del modello fondamentale. Viene visualizzata la finestra di dialogo di ottimizzazione fine del modello di base . Per informazioni dettagliate, vedere Eseguire un ciclo di addestramento usando l'interfaccia utente di affinamento del modello di base.
- La previsione. Viene visualizzata la finestra di dialogo Configura previsione dell'esperimento . Per informazioni dettagliate, vedere Configurare l'esperimento AutoML.
- classificazione. Apparirà la finestra di dialogo Configura l'esperimento di classificazione . Per informazioni dettagliate, vedere Configurare l'esperimento di classificazione con l'interfaccia utente.
- regressione. Apparirà la finestra di dialogo Configura l'esperimento di classificazione . Per informazioni dettagliate, vedere Configurare l'esperimento di regressione con l'interfaccia utente.
- personalizzato. Viene visualizzata la finestra di dialogo Crea esperimento MLflow. Per informazioni dettagliate, consultare il Passaggio 4 in Creare un esperimento dall'area di lavoro.
Creare un esperimento per notebook
Quando si usa il comando mlflow.start_run() in un notebook, l'esecuzione registra metriche e parametri per l'esperimento attivo. Se non è attivo alcun esperimento, Azure Databricks crea un esperimento di notebook. Un esperimento di notebook condivide lo stesso nome e identificativo del notebook corrispondente. L'ID del notebook è l'identificatore numerico alla fine di un URL e un ID del notebook.
Nota
Gli utenti che eseguono MLflow nel calcolo con accesso al gruppo dedicato devono verificare che il gruppo abbia l'autorizzazione per scrivere nella directory in cui risiede il notebook oppure usare mlflow.set_tracking_uri("<path>") per specificare una cartella in cui MLflow deve scrivere.
In alternativa, è possibile passare un percorso dell'area di lavoro di Azure Databricks a un notebook esistente in mlflow.set_experiment() per creare un esperimento di notebook.
Per istruzioni sulla registrazione delle esecuzioni nei notebook, vedere Registrare esecuzioni e modelli in un esperimento.
Nota
Se si elimina un esperimento di notebook usando l'API (ad esempio, MlflowClient.tracking.delete_experiment() in Python), il notebook stesso viene spostato nella cartella Cestino.
Visualizzare gli esperimenti
Ogni esperimento a cui si ha accesso viene visualizzato nella pagina degli esperimenti. Da questa pagina è possibile visualizzare qualsiasi esperimento. Fare clic sul nome di un esperimento per visualizzare la pagina dei dettagli dell'esperimento.
Altri modi per accedere alla pagina dei dettagli dell'esperimento:
- È possibile accedere alla pagina dei dettagli dell'esperimento per un esperimento dell'area di lavoro dal menu dell'area di lavoro.
- È possibile accedere alla pagina dei dettagli dell'esperimento relativo a un esperimento sul notebook dal notebook.
Per cercare esperimenti, digitare il testo nel campo Filtra esperimenti e premere Invio o cliccare l'icona della lente di ingrandimento. L'elenco di esperimenti cambia per visualizzare solo gli esperimenti che contengono il testo di ricerca nelle colonne Nome o Posizione .
Per un uso avanzato, è possibile immettere una query di ricerca per tags.`mlflow.note.content` e cercare nella colonna Descrizione. Per altri dettagli sulla sintassi, vedere Esperimenti di ricerca. Si noti che, a differenza della ricerca di Nome o Posizione, la ricerca tra tag richiede di costruire manualmente la query di ricerca con un identificatore e un comparatore. Non restituirà direttamente tutti i risultati che contengono il testo di ricerca.
Fare clic sul nome di qualsiasi esperimento nella tabella per visualizzare la relativa pagina dei dettagli dell'esperimento:
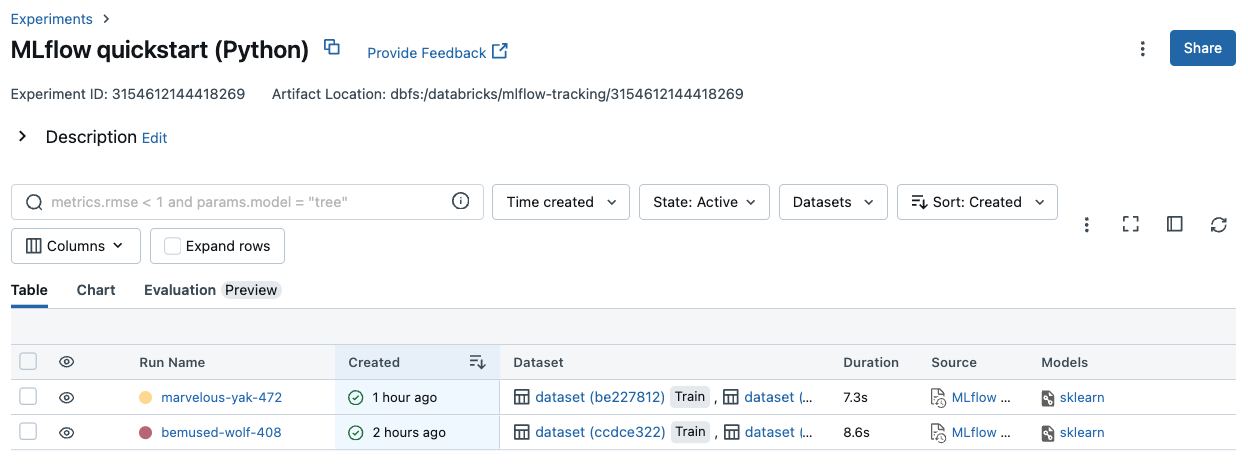
La pagina dei dettagli dell'esperimento elenca tutte le esecuzioni associate all'esperimento. Dalla tabella è possibile aprire la pagina di esecuzione per qualsiasi esecuzione associata all'esperimento facendo clic sul relativo nome di esecuzione. La colonna Origine consente di accedere alla versione del notebook che ha creato l'esecuzione. È anche possibile cercare e filtrare le esecuzioni in base alle metriche o alle impostazioni dei parametri.
Visualizzare l'esperimento dell'area di lavoro
- Cliccare Area di lavoro nella barra laterale.
- Passare alla cartella che contiene l'esperimento.
- Cliccare il nome dell'esperimento.
Visualizza l'esperimento del notebook
Nella barra laterale destra del notebook, fare clic sull'icona Esperimento![]() .
.
Viene visualizzata la barra laterale Experiment Runs (Esecuzioni di esperimenti) e viene visualizzato un riepilogo di ogni esecuzione associata all'esperimento del notebook, inclusi i parametri di esecuzione e le metriche. Nella parte superiore della barra laterale è riportato il nome dell'esperimento in cui il notebook ha eseguito l'ultima registrazione (un esperimento del notebook o un esperimento dell'area di lavoro).
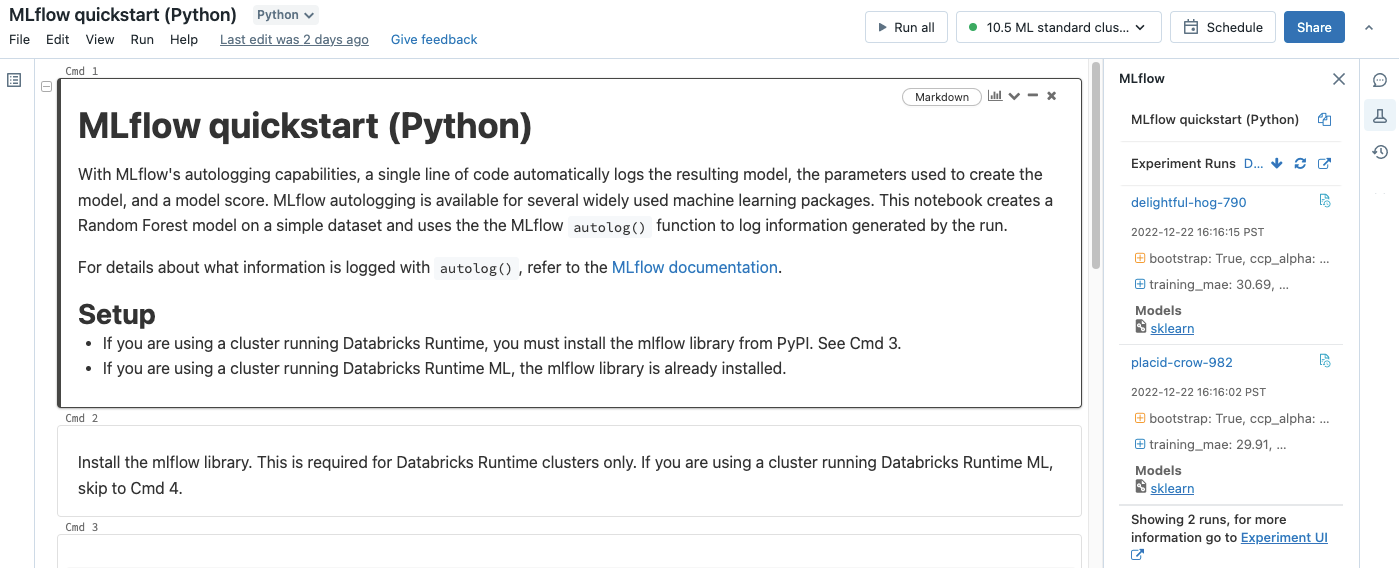
Dalla barra laterale è possibile passare alla pagina dei dettagli dell'esperimento o direttamente a un'esecuzione dell'esperimento.
- Per visualizzare l'esperimento, cliccare
 all'estrema destra accanto a Esecuzioni di esperimenti.
all'estrema destra accanto a Esecuzioni di esperimenti. - Per visualizzare un'esecuzione, fare clic sul nome dell'esecuzione.
Gestire esperimenti
È possibile rinominare, eliminare o gestire le autorizzazioni per un esperimento di cui si è proprietari dalla pagina degli esperimenti, la pagina dei dettagli dell'esperimento o il menu dell'area di lavoro.
Nota
Non è possibile rinominare, eliminare o gestire direttamente le autorizzazioni per un esperimento MLflow creato da un notebook in una cartella Git di Databricks. È necessario eseguire queste azioni a livello di cartella Git.
Rinominare l'esperimento
È possibile rinominare un esperimento che possiedi dalla pagina esperimenti o dalla pagina dei dettagli dell'esperimento per quell'esperimento.
- Nella pagina Esperimenti fare clic sul menu Kebab
 colonna più a destra e quindi fare clic su Rinomina.
colonna più a destra e quindi fare clic su Rinomina.
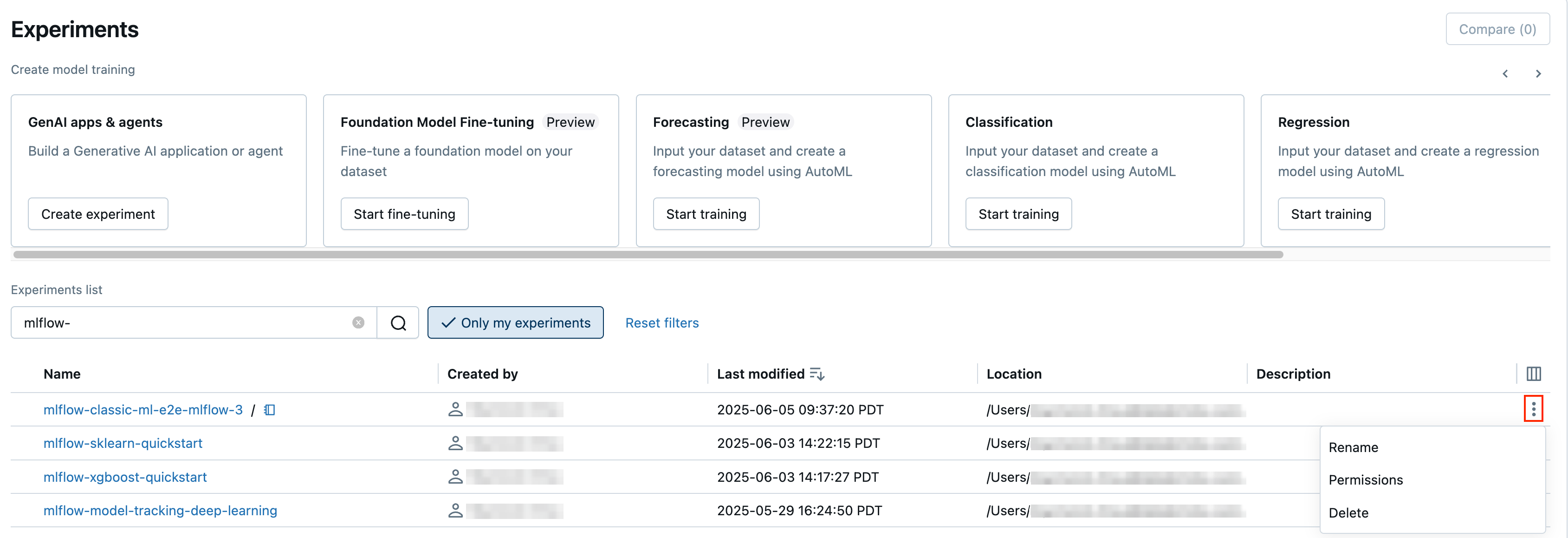
- Nella pagina dei dettagli dell'esperimento, fare clic sull'icona del menu Kebab accanto a Autorizzazioni e quindi fare clic su Rinomina.

È possibile rinominare un esperimento dall'interno dell'area di lavoro. Fare clic con il pulsante destro del mouse sul nome dell'esperimento e quindi fare clic su Rinomina.
Ottenere l'ID esperimento e il percorso dell'esperimento
Nella pagina dei dettagli dell'esperimento è possibile ottenere il percorso di un esperimento di notebook facendo clic ![]() a destra del nome dell'esperimento. Viene visualizzata una nota popup che mostra il percorso dell'esperimento, l'ID esperimento e la posizione dell'artefatto. È possibile usare l'ID esperimento nel comando
a destra del nome dell'esperimento. Viene visualizzata una nota popup che mostra il percorso dell'esperimento, l'ID esperimento e la posizione dell'artefatto. È possibile usare l'ID esperimento nel comando set_experiment MLflow per impostare l'esperimento MLflow attivo.

Da un notebook è possibile copiare il percorso completo dell'esperimento facendo clic ![]() Nella barra laterale dell'esperimento del notebook.
Nella barra laterale dell'esperimento del notebook.
Eliminare l'esperimento del notebook
Gli esperimenti del notebook fanno parte del notebook e non possono essere eliminati separatamente. Quando si elimina un notebook, l'esperimento notebook associato viene eliminato. Quando si elimina un esperimento notebook tramite l'interfaccia utente, il notebook viene eliminato anch'esso.
Per eliminare gli esperimenti del notebook mediante API, utilizzare API Area di lavoro per assicurarsi che il notebook e l'esperimento vengano eliminati dall'area di lavoro.
Eliminare un'area di lavoro o un esperimento in un notebook
È possibile eliminare un esperimento di cui sei proprietario dalla pagina esperimenti o dalla pagina dei dettagli dell'esperimento.
Importante
Quando si elimina un esperimento notebook, viene eliminato anche il notebook.
- Nella pagina Esperimenti fare clic nella colonna più a destra e quindi fare clic su Elimina.
- Nella pagina dei dettagli dell'esperimento, fai clic sull'icona del menu Kebab accanto a Permessi e quindi su Elimina.
È possibile eliminare un esperimento dell'area di lavoro dall'area di lavoro. Fare clic con il pulsante destro del mouse sul nome dell'esperimento e quindi scegliere Sposta nel Cestino.
Modificare le autorizzazioni per un esperimento
Per modificare le autorizzazioni di un esperimento dalla pagina dei dettagli dell'esperimento , cliccare su Autorizzazioni.

È possibile modificare i permessi per un esperimento di cui si è proprietari dalla pagina esperimenti. Fare clic sull'icona del menu Kebab ![]() nella colonna più a destra e quindi fare clic su Autorizzazioni.
nella colonna più a destra e quindi fare clic su Autorizzazioni.
Per informazioni sui livelli di autorizzazione del modello, vedere ACL dell'esperimento MLflow.
Copiare esperimenti tra aree di lavoro
Per eseguire la migrazione di esperimenti MLflow tra aree di lavoro, è possibile usare il progetto open source basato su community MLflow Export-Import.
Con questi strumenti è possibile:
- Condividere e collaborare con altri data scientist nello stesso server di rilevamento o in un altro server di rilevamento. Ad esempio, nello spazio di lavoro è possibile clonare un esperimento di un altro utente.
- Copiare gli esperimenti MLflow ed eseguirli dal server di rilevamento locale nell'area di lavoro di Databricks.
- Eseguire il backup di esperimenti e modelli cruciali in un'altra area di lavoro di Databricks.