Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questa documentazione contiene informazioni su Workspace Model Registry. Azure Databricks consiglia di usare i Modelli in Unity Catalog. I modelli in Unity Catalog offrono governance centralizzata dei modelli, accesso trasversale tra le aree di lavoro, tracciabilità e distribuzione. Il Workspace Model Registry sarà ritirato in futuro.
Questo esempio illustra come usare Workspace Model Registry per creare un'applicazione di apprendimento automatico che prevede l'output di potenza giornaliera di un parco eolico. L'esempio illustra come:
- Monitorare e registrare i modelli con MLflow
- Registrare i modelli nel registro dei modelli
- Descrivere i modelli e creare transizioni di fase della versione del modello
- Integrare i modelli registrati con applicazioni di produzione
- Cercare e individuare i modelli nel Registro modelli
- Archiviare ed eliminare i modelli
L'articolo descrive come eseguire questi passaggi usando l'interfaccia utente e le API di MLflow Tracking e MLflow Model Registry.
Per un notebook che esegue tutti questi passaggi usando le API di MLflow Tracking e Registry, consulta il notebook di esempio del modello di registro.
Caricare set di dati, eseguire il training del modello e tenere traccia con MLflow Tracking
Prima di poter registrare un modello nel registro modelli, è necessario eseguire il training e registrare il modello durante un'esecuzione di un esperimento. Questa sezione illustra come caricare il set di dati del parco eolico, eseguire il training di un modello e registrare l'esecuzione del training in MLflow.
Caricare i set di dati
Il codice seguente carica un set di dati contenente dati meteo e informazioni sull'output di potenza per un parco eolico nel Stati Uniti. Il set di dati contiene le caratteristiche wind direction, wind speed e air temperature campionate ogni sei ore (una volta alle 00:00, una volta alle 08:00 e una volta alle 16:00), nonché l'output di potenza aggregato giornalmente (power), nel corso di diversi anni.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Eseguire il training del modello
Il codice seguente esegue il training di una rete neurale usando TensorFlow Keras per stimare l'output di potenza in base alle funzionalità meteo nel set di dati. MLflow viene usato per tenere traccia degli iperparametri del modello, delle metriche delle prestazioni, del codice sorgente e degli artefatti.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registrare e gestire il modello usando l'interfaccia utente di MLflow
Contenuto della sezione:
- Creare un nuovo modello registrato
- Esplorare l'interfaccia del registro modelli
- Aggiungere descrizioni dei modelli
- Effettuare la transizione di una versione di modello
Creare un nuovo modello registrato
Cliccando sull'icona Esperimento
 nel pannello laterale destro del notebook di Azure Databricks, è possibile accedere al pannello laterale Esecuzioni dell'esperimento di MLflow.
nel pannello laterale destro del notebook di Azure Databricks, è possibile accedere al pannello laterale Esecuzioni dell'esperimento di MLflow.
Individuare l'esecuzione MLflow corrispondente alla sessione di training del modello TensorFlow Keras e aprirla nell'interfaccia utente di esecuzione di MLflow facendo clic sull'icona Visualizza dettagli esecuzione.
Nell'interfaccia utente di MLflow scorrere verso il basso fino alla sezione Artifacts e fare clic sulla directory denominata model. Fare clic sul pulsante Registra modello visualizzato.

Selezionare Crea nuovo modello dal menu a discesa e immettere il nome del modello seguente:
power-forecasting-model.Fare clic su Registra. In questo modo viene registrato un nuovo modello denominato
power-forecasting-modele viene creata una nuova versione del modello:Version 1.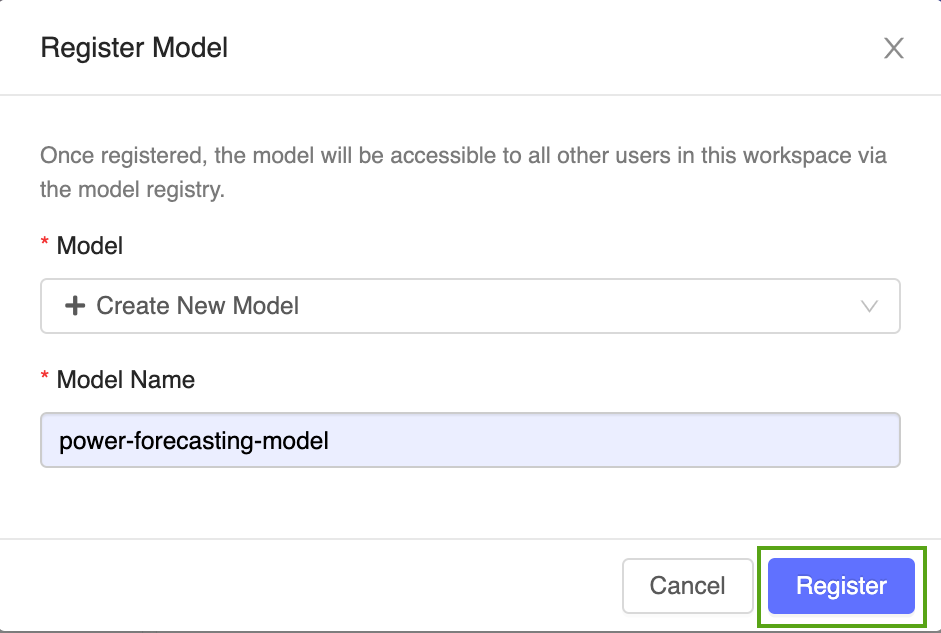
Dopo alcuni istanti, l'interfaccia utente di MLflow visualizza un collegamento al nuovo modello registrato. Fare clic sul collegamento per aprire la nuova versione del modello nell'interfaccia utente di MLflow Model Registry.
Esplorare l'interfaccia utente del registro Modelli
La pagina della versione del modello nell'interfaccia utente di MLflow Model Registry fornisce informazioni sul Version 1 modello di previsione registrato, tra cui l'autore, l'ora di creazione e la fase corrente.
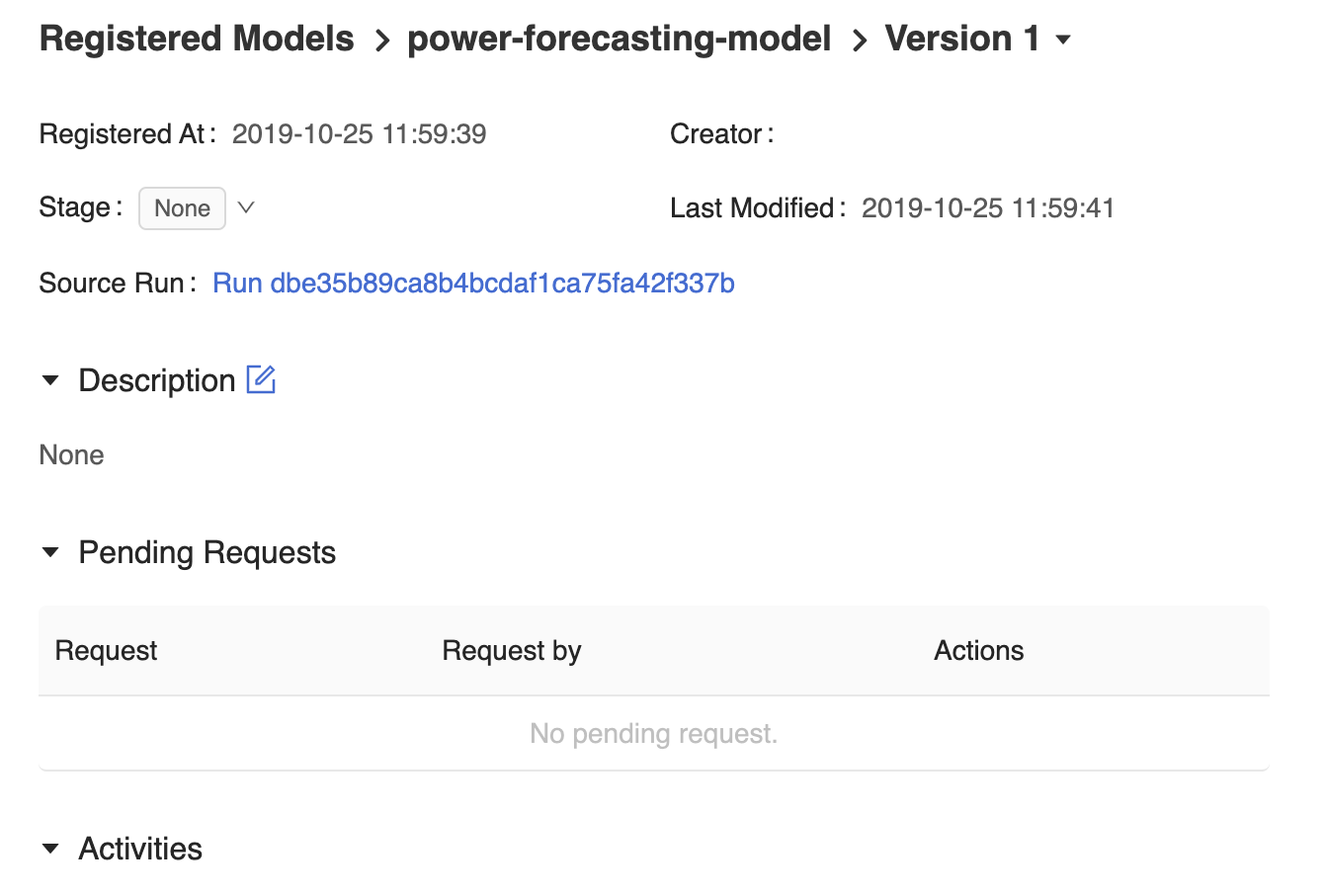
La pagina della versione del modello fornisce anche un collegamento Esecuzione origine, che apre l'esecuzione MLflow usata per creare il modello nell'interfaccia utente di esecuzione di MLflow. Dall'interfaccia utente di esecuzione di MLflow è possibile accedere al collegamento di origine per visualizzare uno snapshot del notebook di Azure Databricks usato per eseguire il training del modello.


Per tornare al MLflow Model Registry, fare clic su ![]() Modelli nella barra laterale.
Modelli nella barra laterale.
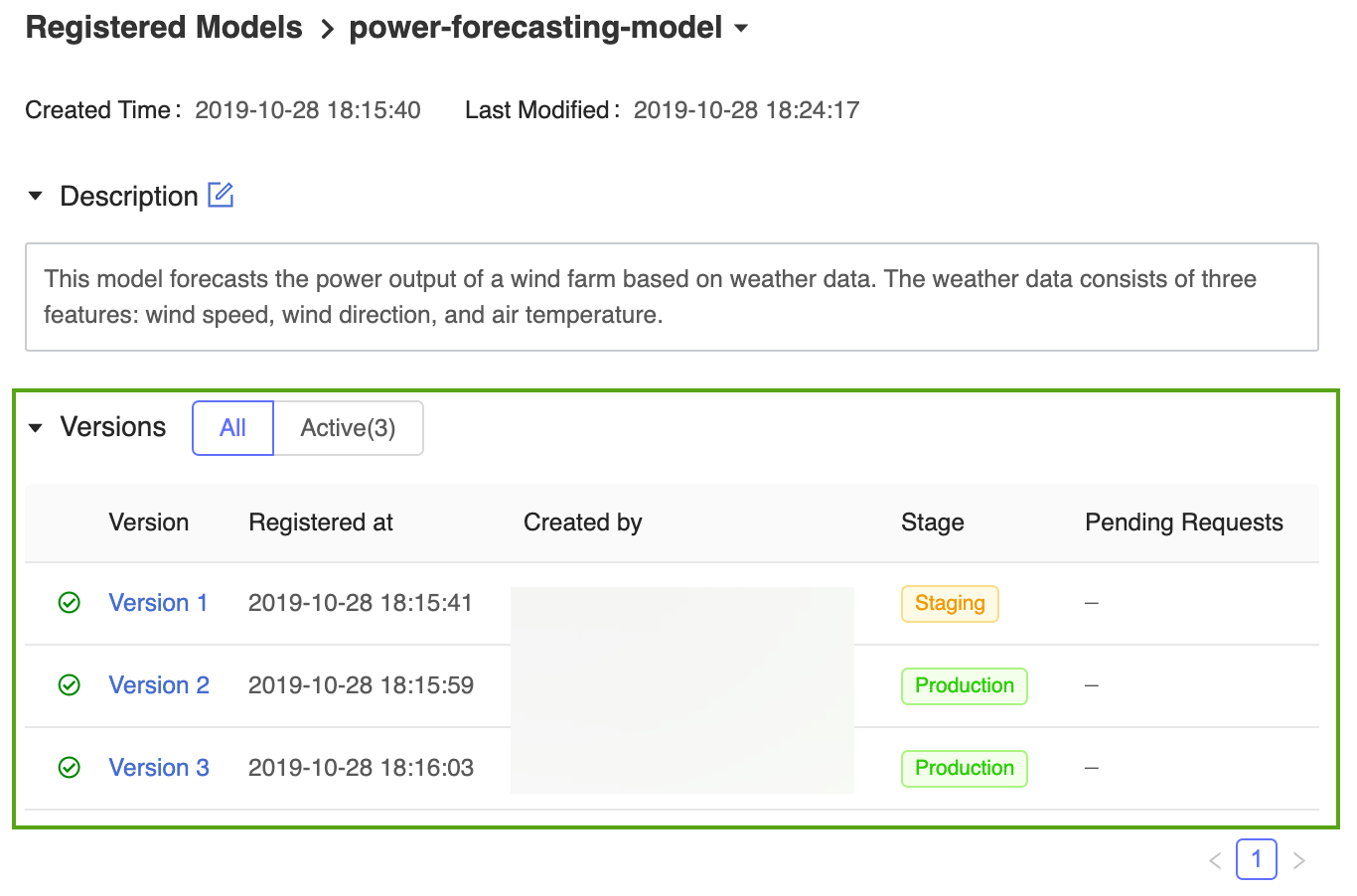
La home page di MLflow Model Registry risultante visualizza un elenco di tutti i modelli registrati nell'area di lavoro di Azure Databricks, incluse le versioni e le fasi.
Fare clic sul collegamento power-forecasting-model per aprire la pagina del modello registrato, che visualizza tutte le versioni del modello di previsione.
Aggiungere descrizioni dei modelli
È possibile aggiungere descrizioni ai modelli registrati e alle versioni del modello. Le descrizioni dei modelli registrati sono utili per registrare informazioni applicabili a più versioni del modello (ad esempio una panoramica generale del problema di modellazione e del set di dati). Le descrizioni delle versioni del modello sono utili per illustrare in dettaglio gli attributi univoci di una determinata versione del modello (ad esempio la metodologia e l'algoritmo usati per sviluppare il modello).
Aggiungere una descrizione di alto livello al modello di previsione della potenza registrata. Fare clic sull'icona
 e inserire la seguente descrizione:
e inserire la seguente descrizione:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.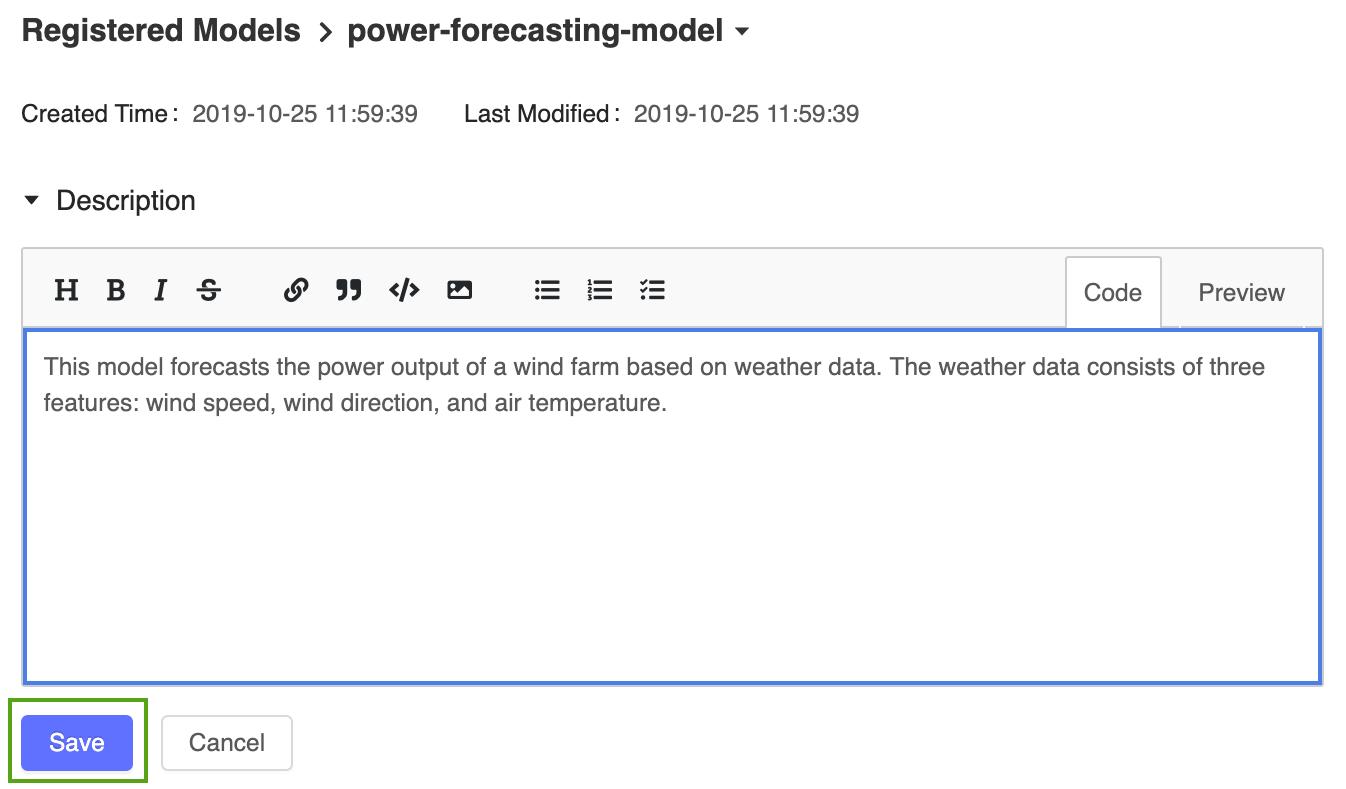
Fare clic su Salva.
Fare clic sul collegamento Versione 1 dalla pagina del modello registrato per tornare alla pagina della versione del modello.
Fare clic sull'icona
e inserire la seguente descrizione:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.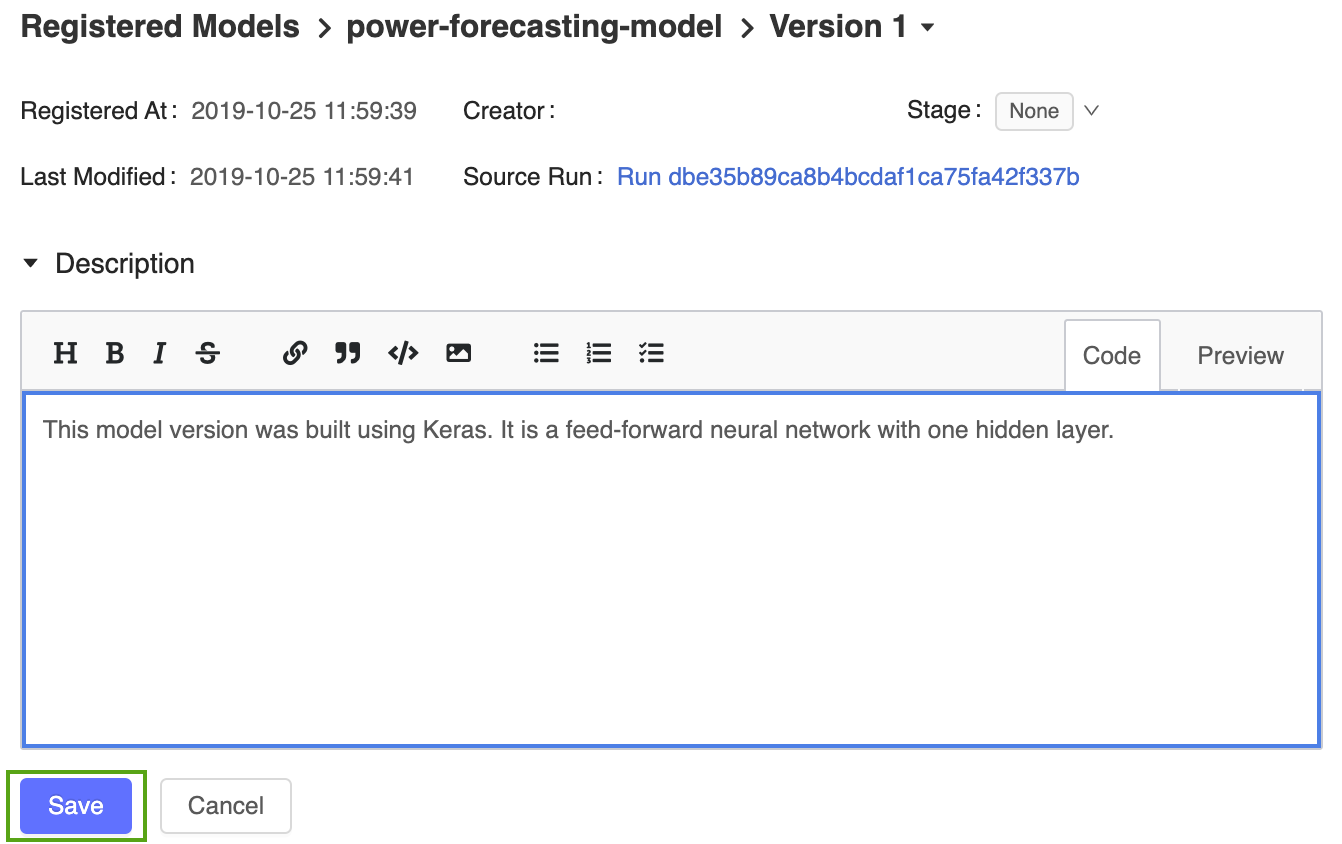
Fare clic su Salva.
Trasferire una versione del modello
MLflow Model Registry definisce diverse fasi del modello: Nessuno, Gestione temporanea, Produzione e Archived. Ogni fase ha un significato univoco. Ad esempio, Gestione temporanea è destinata ai test dei modelli, mentre Produzione è destinata ai modelli che hanno completato i processi di test o di revisione e sono stati distribuiti alle applicazioni.
Fare clic sul pulsante Fase per visualizzare l'elenco delle fasi del modello disponibili e le opzioni di transizione della fase disponibili.
Selezionare Transizione a -> Produzione e premere OK nella finestra di conferma della transizione di fase per eseguire la transizione del modello a Produzione.
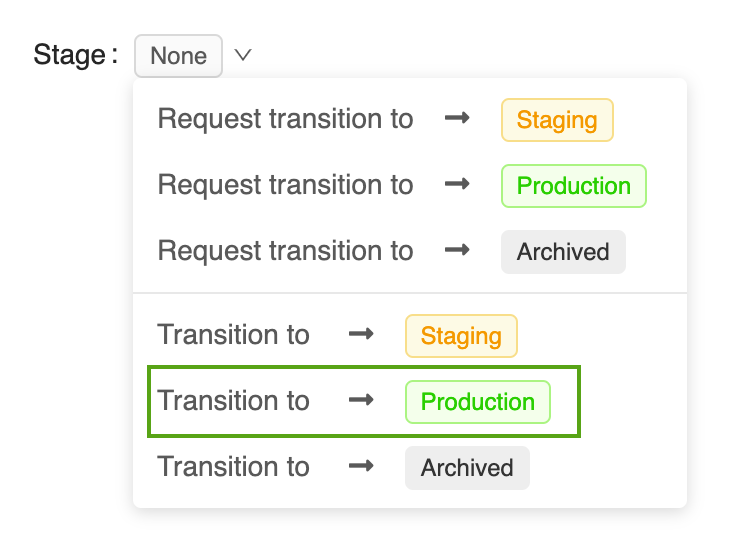
Dopo la transizione della versione del modello a Produzione, la fase corrente viene visualizzata nell'interfaccia utente e viene aggiunta una voce al log attività per riflettere la transizione.


MLflow Model Registry consente a più versioni del modello di condividere la stessa fase. Quando si fa riferimento a un modello per fase, il registro modelli usa la versione più recente del modello (la versione del modello con l'ID versione più grande). Nella pagina del modello registrato vengono visualizzate tutte le versioni di un particolare modello.
Registrare e gestire il modello usando l'API MLflow
Contenuto della sezione:
- Definire il nome del modello a livello di codice
- Registrare il modello
- Aggiungere descrizioni del modello e delle versioni del modello usando l'API
- Eseguire la transizione di una versione del modello e recuperare i dettagli usando l'API
Definire il nome del modello a livello di codice
Ora che il modello è stato registrato e fatto passare a Produzione, è possibile farvi riferimento usando le API programmatiche MLflow. Definire il nome del modello registrato come segue:
model_name = "power-forecasting-model"
Registrare il modello
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Aggiungere descrizioni del modello e delle versioni del modello usando l'API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Eseguire la transizione di una versione del modello e recuperare i dettagli usando l'API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Caricare le versioni del modello registrato usando l'API
Il componente MLflow Models definisce le funzioni per il caricamento di modelli da diversi framework di apprendimento automatico. Ad esempio, mlflow.tensorflow.load_model() viene usato per caricare i modelli TensorFlow salvati in formato MLflow e mlflow.sklearn.load_model() viene usato per caricare i modelli scikit-learn salvati in formato MLflow.
Queste funzioni possono caricare i modelli da MLflow Model Registry.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Previsionare la produzione di energia con il modello di produzione
In questa sezione viene usato il modello di produzione per valutare i dati delle previsioni meteo per il parco eolico. L'applicazione forecast_power() carica la versione più recente del modello di previsione dalla fase specificata e la usa per prevedere la produzione di energia nei cinque giorni successivi.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Creare una nuova versione del modello
Le tecniche classiche di apprendimento automatico sono efficaci anche per la previsione della potenza. Il codice seguente esegue il training di un modello di foresta casuale usando scikit-learn e lo registra con MLflow Model Registry tramite la funzione mlflow.sklearn.log_model().
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Recuperare il nuovo ID versione del modello usando la ricerca in MLflow Model Registry
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Aggiungere una descrizione alla nuova versione del modello
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Eseguire la transizione della nuova versione del modello a Gestione temporanea e testare il modello
Prima di distribuire un modello in un'applicazione di produzione, è spesso consigliabile testarlo in un ambiente di gestione temporanea. Il codice seguente esegue la transizione della nuova versione del modello a Gestione temporanea e ne valuta le prestazioni.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Distribuire la nuova versione del modello in Produzione
Dopo aver verificato che la nuova versione del modello funziona bene in fase di gestione temporanea, il codice seguente fa passare passa il modello a Produzione e utilizza lo stesso codice applicativo della sezione Previsione dell'output di potenza con il modello di produzione per generare una previsione di potenza.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Nella fase Produzione sono ora disponibili due versioni del modello di previsione: la versione addestrata nel modello Keras e la versione addestrata in scikit-learn.
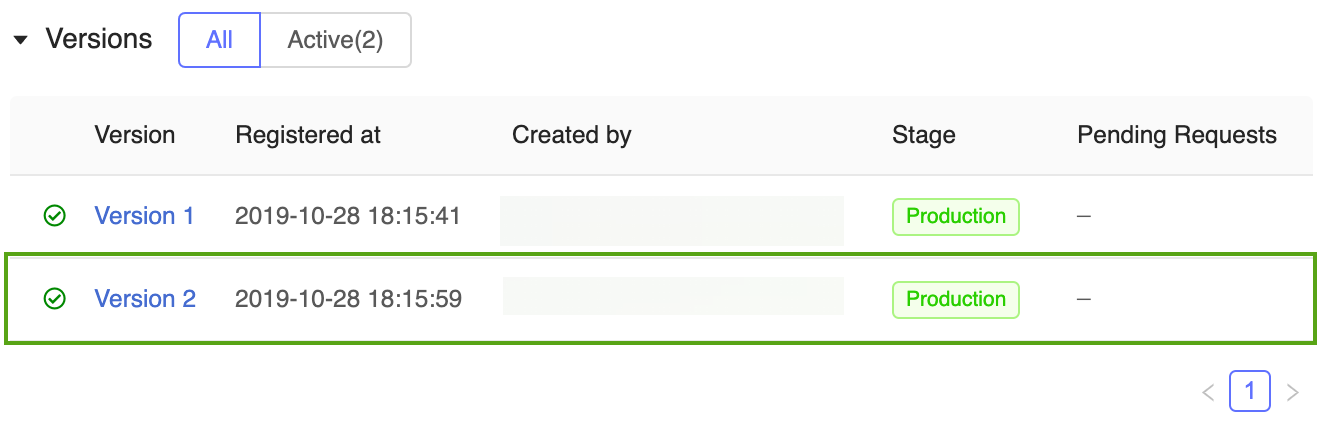
Nota
Quando si fa riferimento a un modello per fase, MLflow Model Registry usa automaticamente la versione di produzione più recente. In questo modo è possibile aggiornare i modelli di produzione senza modificare il codice dell'applicazione.
Archiviare ed eliminare i modelli
Quando non viene più usata una versione del modello, è possibile archiviarla o eliminarla. È anche possibile eliminare un intero modello registrato; in questo modo vengono rimosse tutte le versioni del modello associate.
Archivio Version 1 del modello di previsione della potenza
Archiviazione Version 1 del modello di previsione della potenza perché non si utilizza più. È possibile archiviare i modelli nell'interfaccia utente di MLflow Model Registro o tramite l'API MLflow.
Archiviare Version 1 nell'interfaccia utente di MLflow
Per l'archiviazione di Version 1 nel modello di previsione della potenza
Aprire la pagina corrispondente della versione del modello nell'interfaccia utente di MLflow Model Registry:
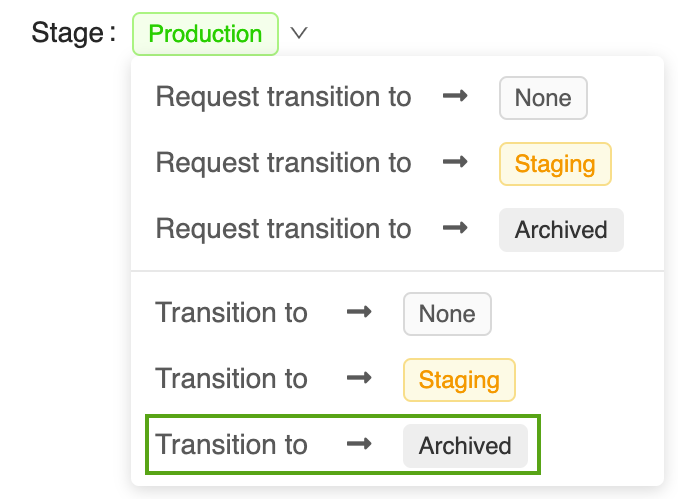
Fare clic sul pulsante Fase, selezionare Transizione a -> Archiviato:
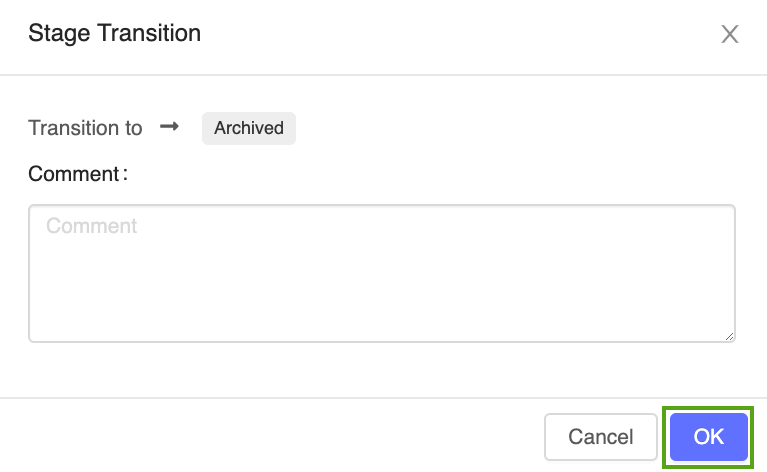
Premere OK nella finestra di conferma della transizione di fase.

Archiviare Version 1 usando l'API MLflow
Il codice seguente usa la funzione MlflowClient.update_model_version() per archiviare Version 1 del modello di previsione della potenza.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Eliminare Version 1 del modello di previsione della potenza
È anche possibile usare l'interfaccia utente MLflow o l'API MLflow per eliminare le versioni del modello.
Avviso
L'eliminazione della versione del modello è permanente e non può essere annullata.
Eliminare Version 1 nell'interfaccia utente di MLflow
Per eliminare Version 1 del modello di previsione della potenza:
Aprire la pagina corrispondente della versione del modello nell'interfaccia utente di MLflow Model Registry.
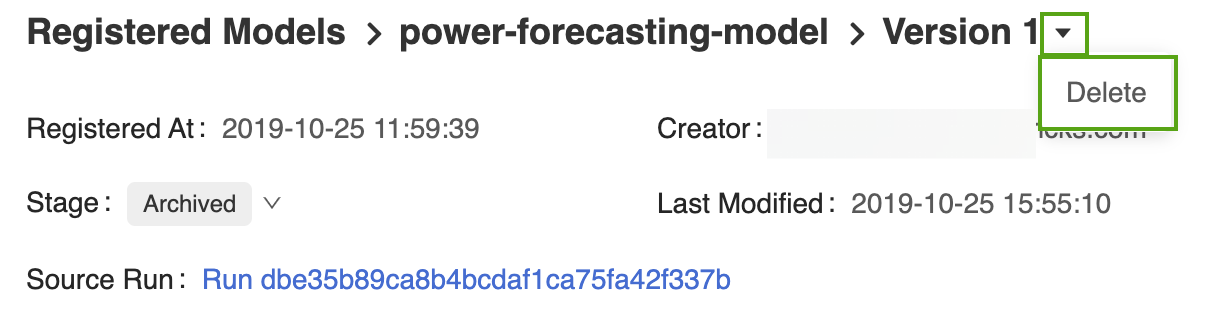
Selezionare la freccia a discesa accanto all'identificatore della versione e fare clic su Elimina.
Eliminare Version 1 usando l'API MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Eliminare il modello usando l'API MLflow
È prima necessario eseguire la transizione di tutte le fasi rimanenti della versione del modello a Nessuno o Archiviato.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)