Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Important
La scalabilità automatica di Lakebase è la versione più recente di Lakebase, con calcolo autoscalabile, scalabilità fino a zero, ramificazione e ripristino immediato. Per le aree supportate, vedere Disponibilità dell'area. Se sei un utente provisioning di Lakebase, vedere Lakebase provisioning.
Questa guida illustra come connettere applicazioni esterne alla scalabilità automatica di Lakebase usando driver Postgres standard (psycopg, pgx, JDBC) con rotazione dei token OAuth. Si usa Azure Databricks SDK con un'entità servizio e un pool di connessioni che chiama generate_database_credential() quando si apre ogni nuova connessione, in modo da ottenere un nuovo token (durata di 60 minuti) ogni volta che ci si connette. Sono disponibili esempi per Python, Java e Go. Per semplificare la configurazione con la gestione automatica delle credenziali, considera invece Azure Databricks Apps.
Elementi che verranno compilati: Modello di connessione che usa la rotazione dei token OAuth per connettersi alla scalabilità automatica di Lakebase da un'applicazione esterna, quindi verificare il funzionamento della connessione.
È necessario Databricks SDK (Python v0.89.0+, Java v0.73.0+o Go v0.109.0+). Completare i passaggi seguenti nell'ordine indicato:
:::tip Altri linguaggi Per le lingue senza supporto di Databricks SDK (Node.js, Ruby, PHP, Elixir, Rust e così via), vedere Connettere un'app esterna a Lakebase usando l'API. :::
Come funziona
Databricks SDK semplifica l'autenticazione OAuth gestendo automaticamente la gestione dei token dell'area di lavoro:
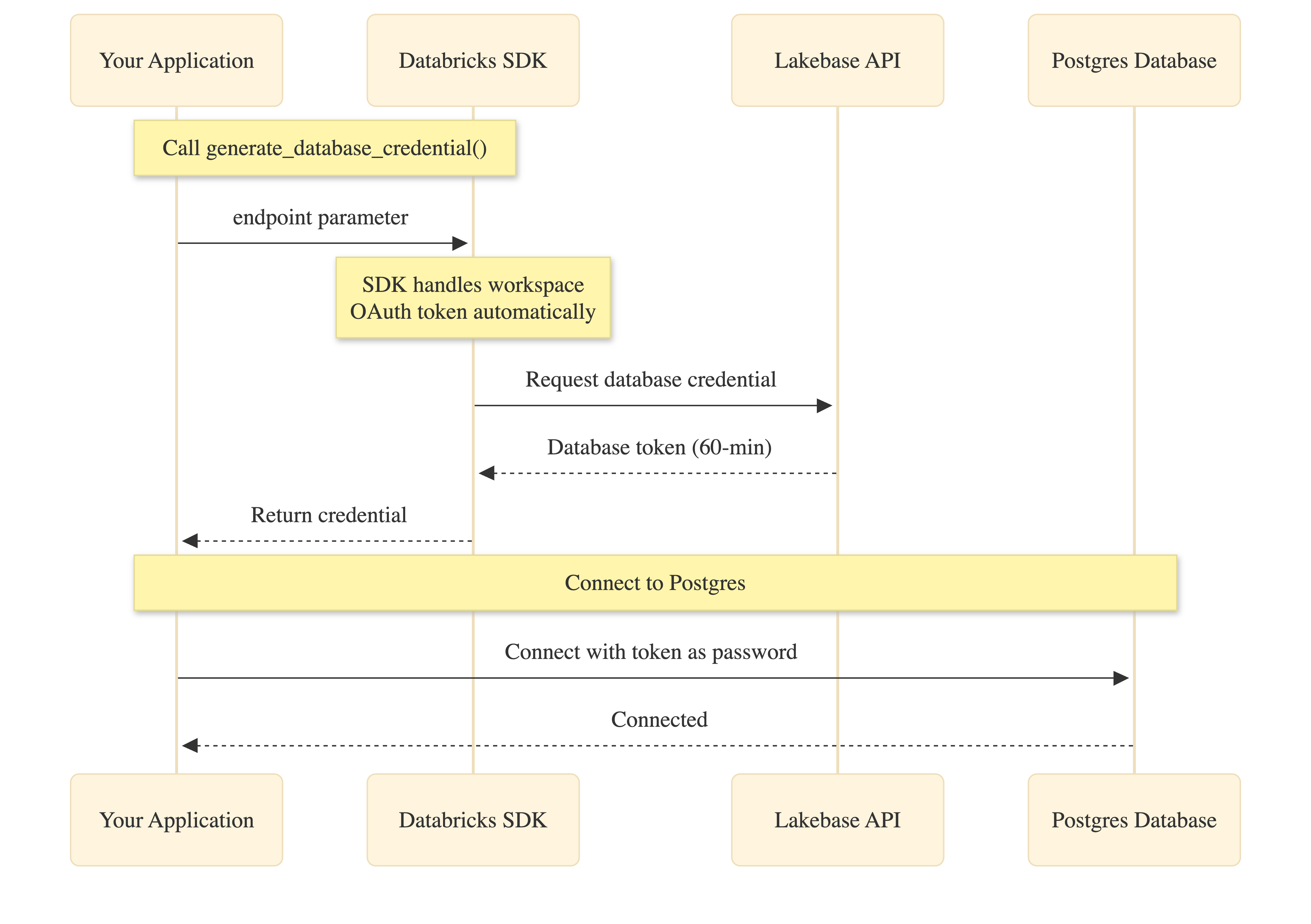
L'applicazione chiama generate_database_credential() con il parametro endpoint. L'SDK ottiene internamente il token OAuth dell'area di lavoro (senza codice necessario), richiede le credenziali del database dall'API Lakebase e lo restituisce all'applicazione. Questa credenziale viene quindi usata come password per la connessione a Postgres.
Sia il token OAuth dell'area di lavoro che le credenziali del database scadono dopo 60 minuti. I pool di connessioni gestiscono l'aggiornamento automatico chiamando generate_database_credential() durante la creazione di nuove connessioni.
1. Creare un'entità servizio con il segreto OAuth
Creare un'entità servizio di Azure Databricks con un segreto OAuth. I dettagli completi sono disponibili in Autorizzare l'accesso all'entità servizio. Per la creazione di un'app esterna, tenere presente quanto segue:
- Imposta la scadenza del tuo segreto alla durata preferita, fino a 730 giorni. In questo modo viene definita la frequenza con cui è necessario aggiornare il segreto, che viene usato per generare le credenziali del database tramite rotazione.
-
Abilitare "Accesso all'area di lavoro" per l'entità servizio (impostazioni → identità e accesso → entità servizio →
{name}scheda Configurazioni →). È necessario per generare nuove credenziali del database. -
Prendere nota dell'ID client (UUID). Lo si usa quando si crea il ruolo Postgres corrispondente nella configurazione dell'app e per
PGUSER.
2. Creare un ruolo Postgres per l'entità servizio
Creare un ruolo OAuth per il principale del servizio. È possibile eseguire questa operazione nell'interfaccia utente di Lakebase (usando la scheda OAuth della finestra di dialogo Aggiungi ruolo) o nell'editor SQL di Lakebase usando l'ID client del passaggio 1 (non il nome visualizzato; il nome del ruolo fa distinzione tra maiuscole e minuscole):
-- Enable the auth extension (if not already enabled)
CREATE EXTENSION IF NOT EXISTS databricks_auth;
-- Create OAuth role using the service principal client ID
SELECT databricks_create_role('{client-id}', 'SERVICE_PRINCIPAL');
-- Grant database permissions
GRANT CONNECT ON DATABASE databricks_postgres TO "{client-id}";
GRANT USAGE ON SCHEMA public TO "{client-id}";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "{client-id}";
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "{client-id}";
Sostituire {client-id} con l'ID client dell'entità servizio. Consultare Creare ruoli OAuth.
3. Ottenere i dettagli della connessione
Dal tuo progetto nella Lakebase Console, fai clic su Connetti, seleziona il ramo e l'endpoint e prendi nota di host, database (di solito databricks_postgres), e nome dell'endpoint (formato: projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>).
In alternativa, usare l'interfaccia della riga di comando:
databricks postgres list-endpoints projects/<project-id>/branches/<branch-id>
Per informazioni dettagliate, vedere Stringhe di connessione .
4. Impostare le variabili di ambiente
Impostare queste variabili di ambiente prima di eseguire l'applicazione:
# Databricks workspace authentication
export DATABRICKS_HOST="https://your-workspace.databricks.com"
export DATABRICKS_CLIENT_ID="<service-principal-client-id>"
export DATABRICKS_CLIENT_SECRET="<your-oauth-secret>"
# Lakebase connection details (from step 3)
export ENDPOINT_NAME="projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>"
export PGHOST="<endpoint-id>.database.<region>.cloud.databricks.com"
export PGDATABASE="databricks_postgres"
export PGUSER="<service-principal-client-id>" # Same UUID as step 1
export PGPORT="5432"
export PGSSLMODE="require" # Python only
5. Aggiungere il codice di connessione
Pitone
Questo esempio usa psycopg3 con una classe di connessione personalizzata che genera un nuovo token quando il pool crea ogni nuova connessione.
import os
from databricks.sdk import WorkspaceClient
import psycopg
from psycopg_pool import ConnectionPool
# Initialize Databricks SDK
workspace_client = None
def _get_workspace_client():
"""Get or create the workspace client for OAuth."""
global workspace_client
if workspace_client is None:
workspace_client = WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
client_id=os.environ["DATABRICKS_CLIENT_ID"],
client_secret=os.environ["DATABRICKS_CLIENT_SECRET"],
)
return workspace_client
def _get_endpoint_name():
"""Get endpoint name from environment."""
name = os.environ.get("ENDPOINT_NAME")
if not name:
raise ValueError(
"ENDPOINT_NAME must be set (format: projects/<id>/branches/<id>/endpoints/<id>)"
)
return name
class OAuthConnection(psycopg.Connection):
"""Custom connection class that generates a fresh OAuth token per connection."""
@classmethod
def connect(cls, conninfo="", **kwargs):
endpoint_name = _get_endpoint_name()
client = _get_workspace_client()
# Generate database credential (tokens are workspace-scoped)
credential = client.postgres.generate_database_credential(
endpoint=endpoint_name
)
kwargs["password"] = credential.token
return super().connect(conninfo, **kwargs)
# Create connection pool with OAuth token rotation
def get_connection_pool():
"""Get or create the connection pool."""
database = os.environ["PGDATABASE"]
user = os.environ["PGUSER"]
host = os.environ["PGHOST"]
port = os.environ.get("PGPORT", "5432")
sslmode = os.environ.get("PGSSLMODE", "require")
conninfo = f"dbname={database} user={user} host={host} port={port} sslmode={sslmode}"
return ConnectionPool(
conninfo=conninfo,
connection_class=OAuthConnection,
min_size=1,
max_size=10,
open=True,
)
# Use the pool in your application
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Dipendenze:databricks-sdk>=0.89.0, psycopg[binary,pool]>=3.1.0
Go
Questo esempio usa pgxpool con un callback BeforeConnect che genera un nuovo token per ogni nuova connessione.
package main
import (
"context"
"fmt"
"log"
"os"
"time"
"github.com/databricks/databricks-sdk-go"
"github.com/databricks/databricks-sdk-go/service/postgres"
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgxpool"
)
func createConnectionPool(ctx context.Context) (*pgxpool.Pool, error) {
// Initialize Databricks workspace client
w, err := databricks.NewWorkspaceClient(&databricks.Config{
Host: os.Getenv("DATABRICKS_HOST"),
ClientID: os.Getenv("DATABRICKS_CLIENT_ID"),
ClientSecret: os.Getenv("DATABRICKS_CLIENT_SECRET"),
})
if err != nil {
return nil, err
}
// Build connection string
connStr := fmt.Sprintf("host=%s port=%s dbname=%s user=%s sslmode=require",
os.Getenv("PGHOST"),
os.Getenv("PGPORT"),
os.Getenv("PGDATABASE"),
os.Getenv("PGUSER"))
config, err := pgxpool.ParseConfig(connStr)
if err != nil {
return nil, err
}
// Configure pool
config.MaxConns = 10
config.MinConns = 1
config.MaxConnLifetime = 45 * time.Minute
config.MaxConnIdleTime = 15 * time.Minute
// Generate fresh token for each new connection
config.BeforeConnect = func(ctx context.Context, connConfig *pgx.ConnConfig) error {
credential, err := w.Postgres.GenerateDatabaseCredential(ctx,
postgres.GenerateDatabaseCredentialRequest{
Endpoint: os.Getenv("ENDPOINT_NAME"),
})
if err != nil {
return err
}
connConfig.Password = credential.Token
return nil
}
return pgxpool.NewWithConfig(ctx, config)
}
func main() {
ctx := context.Background()
pool, err := createConnectionPool(ctx)
if err != nil {
log.Fatal(err)
}
defer pool.Close()
var user, database string
err = pool.QueryRow(ctx, "SELECT current_user, current_database()").Scan(&user, &database)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Connected as: %s to database: %s\n", user, database)
}
Dipendenze: Databricks SDK per Go v0.109.0+ (github.com/databricks/databricks-sdk-go), pgx driver (github.com/jackc/pgx/v5)
Nota: Il BeforeConnect callback garantisce token OAuth aggiornati per ogni nuova connessione, gestendo la rotazione automatica dei token per le applicazioni a esecuzione prolungata.
Java
Questo esempio usa JDBC con HikariCP e un'origine dati personalizzata che genera un nuovo token quando il pool crea ogni nuova connessione.
import java.sql.*;
import javax.sql.DataSource;
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.core.DatabricksConfig;
import com.databricks.sdk.service.postgres.*;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class LakebaseConnection {
private static WorkspaceClient workspaceClient() {
String host = System.getenv("DATABRICKS_HOST");
String clientId = System.getenv("DATABRICKS_CLIENT_ID");
String clientSecret = System.getenv("DATABRICKS_CLIENT_SECRET");
return new WorkspaceClient(new DatabricksConfig()
.setHost(host)
.setClientId(clientId)
.setClientSecret(clientSecret));
}
private static DataSource createDataSource() {
WorkspaceClient w = workspaceClient();
String endpointName = System.getenv("ENDPOINT_NAME");
String host = System.getenv("PGHOST");
String database = System.getenv("PGDATABASE");
String user = System.getenv("PGUSER");
String port = System.getenv().getOrDefault("PGPORT", "5432");
String jdbcUrl = "jdbc:postgresql://" + host + ":" + port +
"/" + database + "?sslmode=require";
// DataSource that returns a new connection with a fresh token (tokens are workspace-scoped)
DataSource tokenDataSource = new DataSource() {
@Override
public Connection getConnection() throws SQLException {
DatabaseCredential cred = w.postgres().generateDatabaseCredential(
new GenerateDatabaseCredentialRequest().setEndpoint(endpointName)
);
return DriverManager.getConnection(jdbcUrl, user, cred.getToken());
}
@Override
public Connection getConnection(String u, String p) {
throw new UnsupportedOperationException();
}
// ... other DataSource methods (getLogWriter, etc.)
};
// Wrap in HikariCP for connection pooling
HikariConfig config = new HikariConfig();
config.setDataSource(tokenDataSource);
config.setMaximumPoolSize(10);
config.setMinimumIdle(1);
// Recycle connections before 60-min token expiry
config.setMaxLifetime(45 * 60 * 1000L);
return new HikariDataSource(config);
}
public static void main(String[] args) throws SQLException {
DataSource pool = createDataSource();
try (Connection conn = pool.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT current_user, current_database()")) {
if (rs.next()) {
System.out.println("User: " + rs.getString(1));
System.out.println("Database: " + rs.getString(2));
}
}
}
}
Dipendenze: Databricks SDK per Java v0.73.0+ (com.databricks:databricks-sdk-java), driver JDBC PostgreSQL (org.postgresql:postgresql), HikariCP (com.zaxxer:HikariCP)
6. Eseguire e verificare la connessione
Pitone
Installare le dipendenze:
pip install databricks-sdk psycopg[binary,pool]
Esegui:
# Save all the code from step 5 (above) as db.py, then run:
from db import get_connection_pool
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Output previsto:
('c00f575e-d706-4f6b-b62c-e7a14850571b', 'databricks_postgres')
Se current_user corrisponde all'ID client del principale del servizio del passaggio 1, la rotazione del token OAuth funziona.
Java
Nota: Si supponga di avere un progetto Maven con le dipendenze dell'esempio Java precedente in pom.xml.
Installare le dipendenze:
mvn install
Esegui:
mvn exec:java -Dexec.mainClass="com.example.LakebaseConnection"
Output previsto:
User: c00f575e-d706-4f6b-b62c-e7a14850571b
Database: databricks_postgres
Se il cliente corrisponde all'ID client principale del servizio dal passaggio 1, la rotazione del token OAuth funziona.
Go
Installare le dipendenze:
go mod init myapp
go get github.com/databricks/databricks-sdk-go
go get github.com/jackc/pgx/v5
Esegui:
go run main.go
Output previsto:
Connected as: c00f575e-d706-4f6b-b62c-e7a14850571b to database: databricks_postgres
Se il cliente corrisponde all'ID client principale del servizio dal passaggio 1, la rotazione del token OAuth funziona.
Nota: La prima connessione dopo l'inattività potrebbe richiedere più tempo perché la scalabilità automatica di Lakebase avvia il calcolo da zero.
Risoluzione dei problemi
| Errore | Correzione |
|---|---|
| "L'API è disabilitata per gli utenti senza diritti di accesso all'area di lavoro" | Abilitare "Accesso all'area di lavoro" per l'entità servizio (passaggio 1). |
| "Il ruolo non esiste" o l'autenticazione ha esito negativo | Creare il ruolo OAuth tramite SQL (passaggio 2), non l'interfaccia utente. |
| "Connessione rifiutata" o "Endpoint non trovato" | Utilizzare il formato ENDPOINT_NAMEprojects/<id>/branches/<id>/endpoints/<id>; l'ID dell'endpoint si trova nell'host. |
| "Utente non valido" o "Utente non trovato" | Impostare PGUSER sull'ID client dell'entità servizio (UUID), non sul nome visualizzato. |