Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Annotazioni
La funzionalità Feed di dati delle modifiche di Lakebase è disponibile in anteprima pubblica.
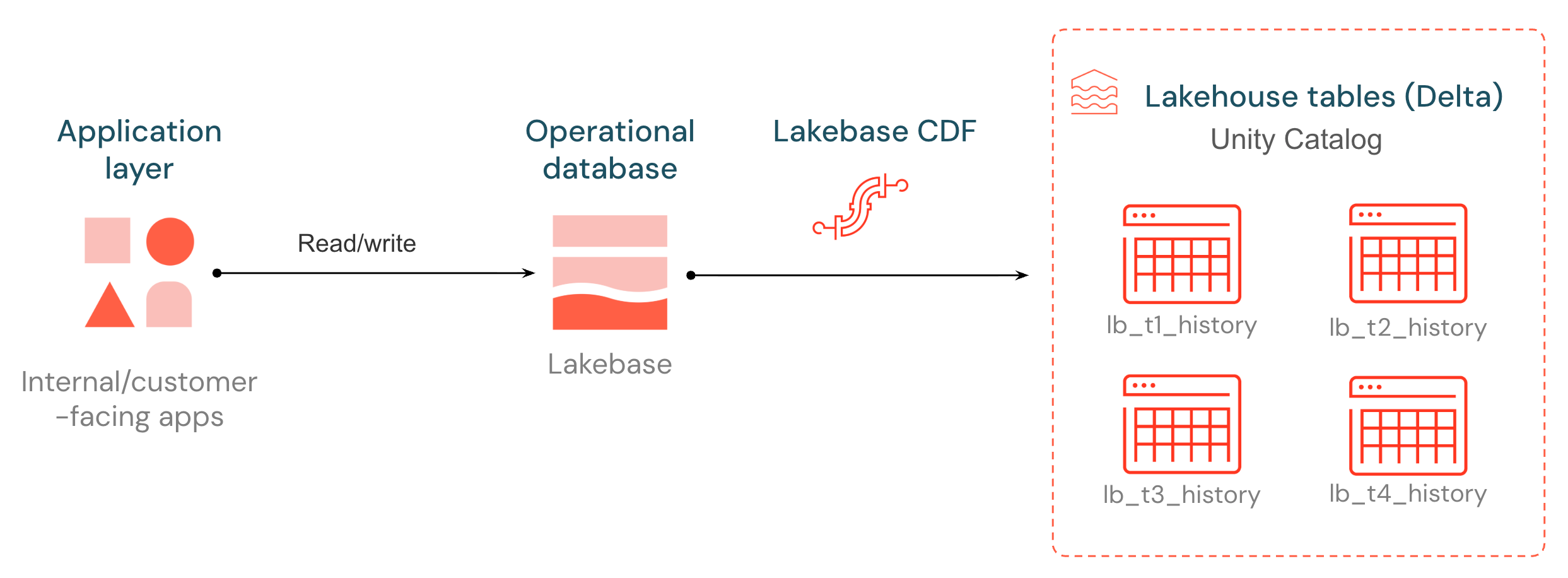
Che cos'è Lakebase Change Data Feed?
Lakebase introduce un feed nativo dei dati sulle modifiche (CDF), rendendo i tuoi dati operativi accessibili a pipeline a valle, modelli e applicazioni. Ogni inserimento, aggiornamento ed eliminazione su una tabella Postgres di Lakebase viene catturato dal log write-ahead e archiviato come nuova riga in una tabella Delta gestita da Unity Catalog, raggruppato in batch e scritto ogni ~15 secondi. La cronologia delle modifiche viene archiviata in un formato aperto che qualsiasi motore di calcolo può leggere.
Le tabelle di destinazione hanno la stessa struttura di Delta Change Data Feed: ogni riga contiene un _pg_change_type, un LSN, un ID della transazione e un timestamp. Le modifiche operative diventano una fonte primaria per ETL, audit e consumer downstream, senza dover predisporre uno stack CDC esterno.
Casi d'uso
Lakebase CDF porta i dati operativi nella lakehouse in modo che le pipeline e le applicazioni downstream possano reagire alle modifiche man mano che si verificano.
| Caso di utilizzo | Description |
|---|---|
| Pipeline ETL | Usare Lakebase come origine bronzea per le pipeline medallion. Creare processi incrementali di SDP o Spark Structured Streaming rispetto al feed di modifiche e aggiornare tabelle silver e gold downstream. |
| Log di controllo | Mantenere una cronologia completa e queryabile di ogni inserimento, aggiornamento ed eliminazione in una tabella Lakebase per la conformità e l'analisi forense. La cronologia è immutabile in Delta. |
| Sistemi esterni | Archiviare i dati delle modifiche di Lakebase in un formato aperto che qualsiasi motore può utilizzare. Poiché la destinazione è una tabella Delta in Unity Catalog, i sistemi esterni e i lettori non Databricks possono accedere direttamente al feed. |
Abilitare questa anteprima
Un amministratore dell'area di lavoro deve abilitare l'anteprima del feed di dati delle modifiche di Lakebase dalla pagina Anteprime dell'area di lavoro.
Requirements
- Scalabilità automatica di Lakebase: Un progetto di scalabilità automatica di Lakebase che esegue Postgres 17.
-
Database di origine: Le tabelle devono risiedere nel
databricks_postgresdatabase in Lakebase. Ogni progetto viene creato con questo database predefinito. Si tratta di una limitazione nota. - Unity Catalog: L'identità che configura CDF richiede USE CATALOG, USE SCHEMA e CREATE TABLE sul catalogo e sullo schema di destinazione. Vedere Concedere autorizzazioni per un oggetto.
- Archiviazione predefinita: I cataloghi di destinazione configurati con l'archiviazione predefinita non sono supportati.
- Progetto Lakebase: Il ruolo Postgres richiede autorizzazioni CAN MANAGE per il progetto Lakebase. I proprietari del progetto dispongono di CAN MANAGE per impostazione predefinita. Vedere Gestire le autorizzazioni del progetto.
- Tipi di dati: Vedere Mapping dei tipi di dati. I tipi senza un equivalente Delta diretto vengono archiviati come STRING.
Configurare Lakebase CDF
Per iniziare, imposta replica identity full sulle tabelle che vuoi includere nel feed (passaggio 1), quindi avvia CDF nell'app Lakebase (passaggio 2). I dati vengono visualizzati come lb_<table_name>_history tabelle Delta nel catalogo di Unity e nello schema scelti.
Passaggio 1: Impostare l'identità di replica completa
Affinché una tabella Lakebase partecipi a CDF, è necessario che REPLICA IDENTITY FULL sia impostata. Per impostazione predefinita, Postgres registra solo la chiave primaria quando una riga viene aggiornata o eliminata. Impostare l'identità completa fa sì che Postgres registri sia lo stato della riga prima della modifica sia quello successivo nel write-ahead log, di cui CDF ha bisogno per costruire una cronologia completa delle modifiche.
È possibile eseguire questi comandi nell'editor SQL di Lakebase o in qualsiasi client Postgres.
Tabella singola
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Tutte le tabelle esistenti in uno schema
Per impostare l'identità della replica in ogni tabella esistente in uno schema (public in questo esempio), eseguire:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Applicazione automatica alle tabelle future
Per fare in modo che ogni tabella appena creata riceva REPLICA IDENTITY FULLautomaticamente , installare un trigger di evento Postgres. Viene eseguito dopo ogni CREATE TABLE e imposta l'identità sulla nuova tabella:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Combina il trigger di evento con il ciclo nella scheda precedente per includere sia le tabelle esistenti sia quelle future in un'unica configurazione.
Controllare quali tabelle hanno un set di identità di replica
Per visualizzare le tabelle in uno schema in cui è configurata l'identità di replica, eseguire:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Solo le righe con replica_identity = 'full' sono pronte per CDF.
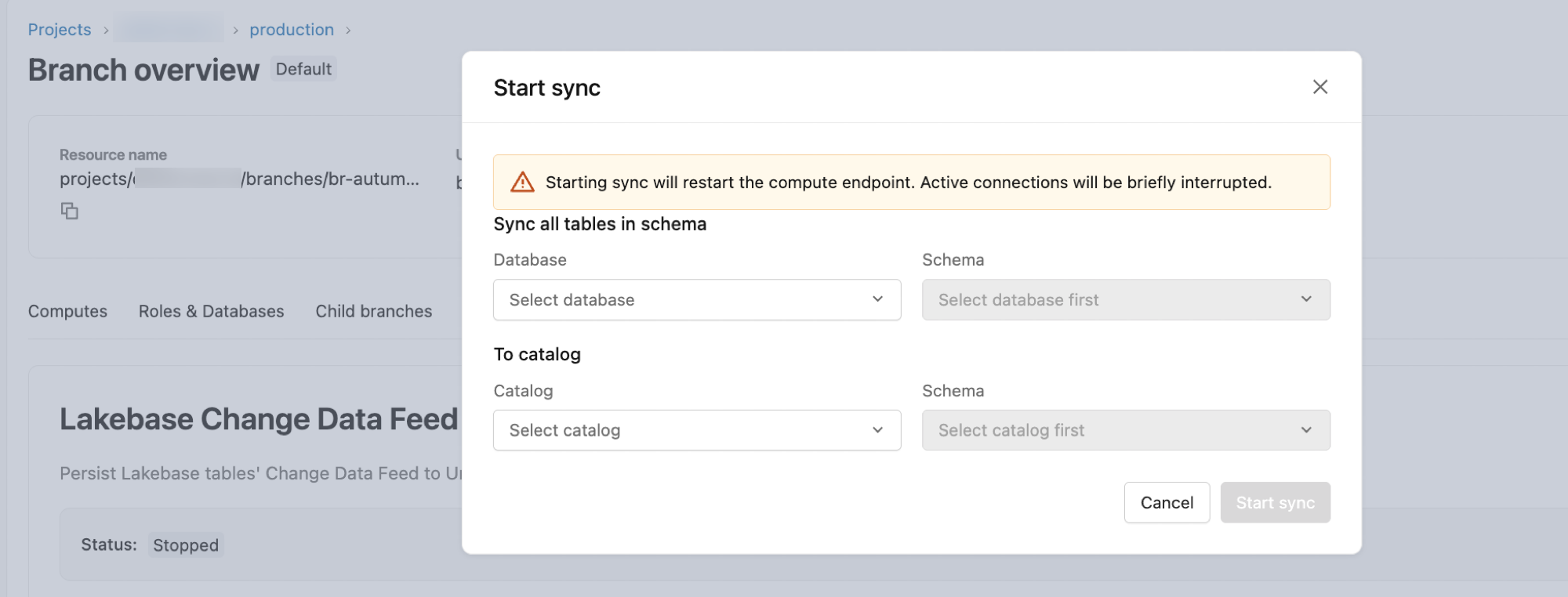
Passaggio 2: Avviare il feed di dati delle modifiche
Lakebase CDF è configurato a livello di schema. Una volta avviato, ogni tabella corrente e futura nello schema di origine viene inclusa nel feed.
- Nell'area di lavoro Azure Databricks aprire Lakebase Postgres dall'interruttore dell'app (in alto a destra).
- Selezionare il progetto Lakebase e il ramo da usare, ad esempio produzione o main.
- Aprire Panoramica di Branch e fare clic sulla scheda Feed di dati delle modifiche .
- Fare clic su Inizia.
- Nella finestra di dialogo di configurazione:
-
Database: Il valore predefinito è
databricks_postgres. - Schema: Selezionare lo schema Postgres di origine.
- Nel catalogo: Selezionare il catalogo di destinazione in Unity Catalog.
- Schema: Selezionare lo schema del catalogo Unity di destinazione.
-
Database: Il valore predefinito è
- Fare clic su Start per avviare il feed.
Le tabelle vengono visualizzate nella destinazione come lb_<table_name>_history. Per trovarli, aprire Catalogo nella barra laterale, passare al catalogo di destinazione e allo schema e aprire la scheda Tabelle .
La scheda Change Data Feed in Lakebase ha due sotto-schede:
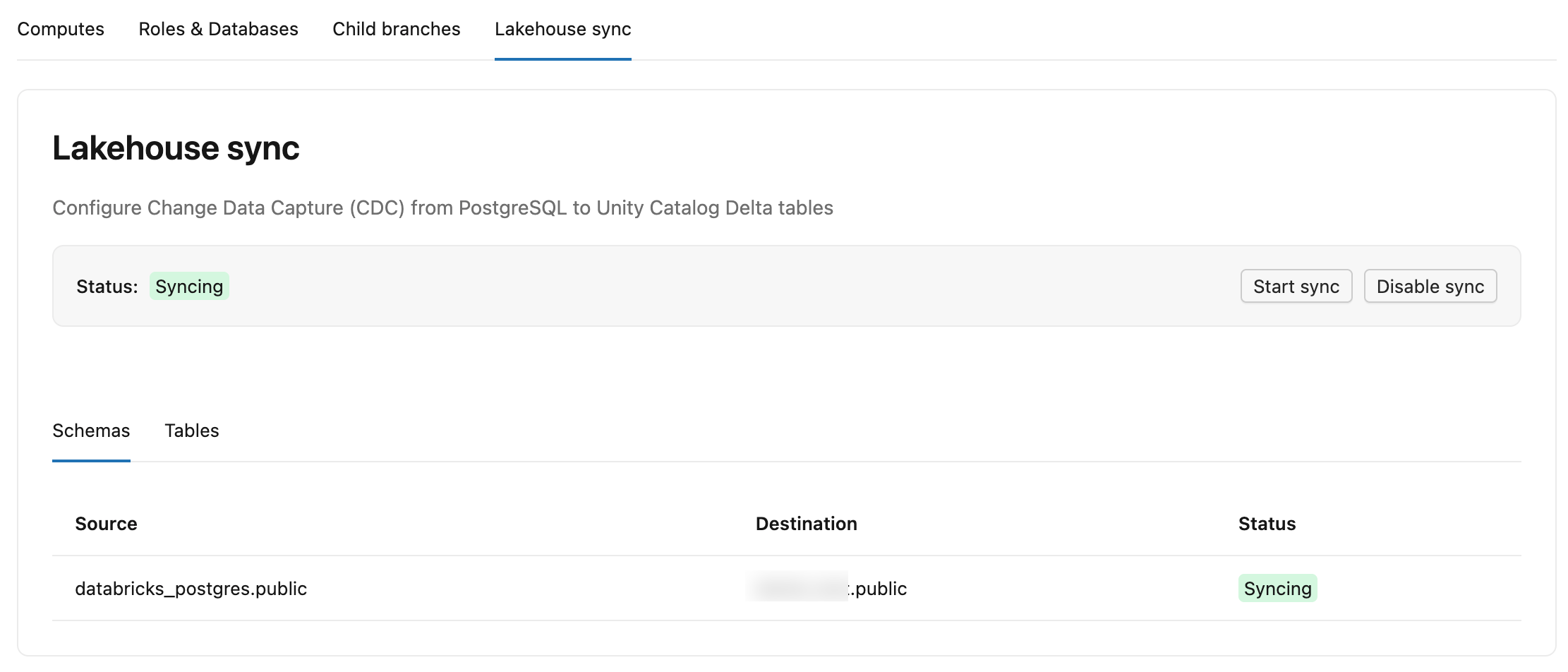
- Schemi: Elenca ogni schema di origine, il catalogo di destinazione e lo schema in Unity Catalog e uno stato.
-
Tabelle: Elenca ciascuna tabella di origine, la relativa tabella di destinazione
lb_<table_name>_history, lo stato (StreamingoSnapshotting), LSN confermato (fino a che punto il feed è stato scritto in Delta, mostrato come-finché è ancora nello snapshot iniziale) e Ultimo aggiornamento (l'ultima volta in cui la tabella ha ricevuto modifiche).
È anche possibile esaminare lo stato del feed da Postgres eseguendo questa operazione nell'editor SQL di Lakebase:
SELECT * FROM wal2delta.tables;
Il risultato include table_oid, status (STREAMING o SNAPSHOTTING), committed_lsne last_write_time per tabella.
Importante
Che cos'è wal2delta? Lakebase CDF è basato sull'estensione wal2delta Postgres, che viene eseguita all'interno dell'ambiente di calcolo Lakebase. Usa la decodifica logica per acquisire le modifiche del write-ahead log (WAL) e scriverle nelle tabelle Delta in Unity Catalog.
Schema della tabella di destinazione
CDF scrive una tabella Delta per ogni tabella di origine, denominata lb_<table_name>_history nel catalogo di destinazione e nello schema. Oltre alle colonne di origine, ogni riga contiene queste colonne di sistema:
| Column | Tipo | Description |
|---|---|---|
_pg_change_type |
TESTO | Tipo di operazione: insert, delete, update_preimageo update_postimage. |
_pg_lsn |
BIGINT | Numero di sequenza del log di Postgres. |
_pg_xid |
INTEGER | ID transazione Postgres. |
_timestamp |
TIMESTAMP | Timestamp durante l'elaborazione della modifica (senza fuso orario). |
_sort_by |
BIGINT | Tasto di ordinamento monotonico usato per ordinare tutte le modifiche. |
Modelli di modifica comuni
-
Snapshot iniziale: La prima volta che CDF viene eseguito in una tabella Lakebase esistente, ogni riga esistente viene scritta con
_pg_change_type = 'insert'. -
Aggiornamenti: Un aggiornamento produce due righe: una con
_pg_change_type = 'update_preimage'(riga precedente) e una con_pg_change_type = 'update_postimage'(nuova riga). -
Elimina: Un'eliminazione produce una riga con
_pg_change_type = 'delete'.
Si tratta degli stessi eventi di modifica del feed dei dati di modifica delta, quindi si applicano gli stessi modelli a valle.
Comportamento operativo
-
Conflitti di denominazione: Se due tabelle di origine corrispondono allo stesso nome di destinazione (ad esempio, se
sales.usersemarketing.userscorrispondono entrambi alb_users_history), CDF scrive la prima inlb_users_historye aggiunge automaticamente un suffisso alla seconda inlb_users_history_1. È possibile rinominare una delle due tabelle di destinazione in Unity Catalog e il feed continua a funzionare. - Ambito a livello di schema: Quando si avvia CDF in uno schema Lakebase, viene inclusa ogni tabella corrente e futura in tale schema. Le tabelle vuote vengono ignorate. Una tabella deve contenere almeno una riga da visualizzare nella destinazione.
- Tabelle di origine eliminate: Se si rilascia una tabella in Lakebase, la tabella Delta di destinazione nel catalogo Unity viene mantenuta.
Creare pipeline a valle
Lakebase CDF è progettato per le pipeline downstream che reagiscono alle modifiche operative. I modelli seguenti mostrano tre modi per utilizzare il feed, ordinati dal più semplice al più flessibile.
Scenario di esempio. Un'app di ecommerce registra gli ordini in una tabella Postgres orders, in cui ogni riga contiene un item_id e quantity. Il team logistico ha bisogno di livelli di inventario in tempo reale. Con CDF, ogni modifica apportata a orders viene memorizzata nella tabella Delta lb_orders_history in Unity Catalog. Le pipeline downstream leggono il feed di modifiche e aggiornano una inventory_levels tabella ogni volta che viene effettuato, modificato o annullato un ordine.
Calcolare l'inventario corrente con una vista materializzata
Il modello più semplice è una vista materializzata SQL sulla tabella di cronologia. La MV si aggiorna in modo incrementale man mano che arrivano nuovi eventi di modifica e i consumer a valle la interrogano come qualsiasi altra tabella.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Le due righe generate per ogni aggiornamento si annullano a vicenda, fatta eccezione per la variazione netta, quindi la somma cumulativa rimane corretta man mano che gli ordini vengono modificati.
Elaborare in streaming le modifiche con pipeline dichiarative di Spark
Per un'architettura medallion strutturata, utilizzare Spark Declarative Pipelines (SDP) per dichiarare le tabelle bronze, silver e gold. SDP li esegue come una pipeline connessa, con checkpoint e gestione delle dipendenze gestiti per te.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments legge lb_orders_history in modo incrementale con readStream e genera un delta per evento.
inventory_levels aggrega per item_id per calcolare le scorte correnti. L'aspettativa riduce le righe che potrebbero spingere le scorte negative, segnalando un bug upstream.
Per una procedura dettagliata completa end-to-end, vedere Esercitazione: Creare una pipeline ETL usando Change Data Capture.
Elaborazione personalizzata con Spark Structured Streaming
Quando hai bisogno del pieno controllo — ad esempio, operazioni di merge personalizzate, effetti collaterali o più sink — leggi direttamente la tabella della cronologia con Spark Structured Streaming e usa foreachBatch per scrivere nella destinazione desiderata.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Ogni microbatch aggrega gli eventi di modifica in item_id e unisce i delta netti in inventory_levels.
Progettato per essere incrementale. Ogni lb_<table_name>_history tabella è una tabella Delta di sola accodamento. Ogni modifica di origine viene registrata come nuova riga con _pg_change_type il contrassegno dell'operazione. Le viste materializzate di Databricks SQL, i flussi dichiarativi di Lakeflow Spark e i processi Spark Structured Streaming elaborano tutte le nuove righe in modo incrementale dal log delle transazioni Delta, quindi le pipeline downstream funzionano solo in modo proporzionale alle modifiche apportate. Non è necessario abilitare il feed di dati delle modifiche delta nella tabella di cronologia perché la semantica delle modifiche è già codificata nei dati di riga.
Mappatura del tipo di dati
CDF supporta la maggior parte dei tipi primitivi PostgreSQL standard. I tipi senza un equivalente Delta diretto vengono archiviati come STRING.
| Tipo PostgreSQL | Azure Databricks di tipo Delta | Note |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| TEXT, VARCHAR, CHAR | filo | |
| JSONB | filo | Archiviato come stringa JSON. |
| ENUM | filo | Archiviato come etichetta di enumerazione. |
| NUMERICO / DECIMALE | DECIMAL o STRING | Usa precisione/scala di origine quando possibile. Esegue il ridimensionamento senza perdita di dati per valori di precisione/scala incompatibili. Ripiega su STRING quando la precisione supera 38 o quando precisione e scala non sono definite (NUMERIC senza limiti). Tutte le colonne NUMERIC/DECIMAL sono nullable perché i valori NaN vengono mappati a NULL. Vedere Tipi numerici PostgreSQL. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
Tipi archiviati come STRING:
-
Geography/Geometry (PostGIS): Tipi dall'estensione PostGIS ( ad esempio ,
geometrygeography). -
Vettore (pgvector): Il tipo
vectordell'estensione pgvector. -
Tipi compositi/struct: Tipi personalizzati definiti con
CREATE TYPE ... AS (field_name type, ...). Si tratta di tipi simili a righe con campi denominati. -
Mappa: Tipi chiave-valore simili a mappe, ad esempio hstore (dell'estensione
hstore). Postgres non ha alcun tipo di mappa predefinito.hstoreè il modo comune per archiviare coppie chiave-valore in una colonna.
Gestione delle modifiche dello schema
-
La ridenominazione di una tabella in Postgres (ad esempio,
ALTER TABLE users RENAME TO customers) consente di continuare il feed. Il nome della tabella Delta di destinazione non cambia, ma rimanelb_users_history. - Le modifiche dello schema (aggiunta di una colonna, eliminazione di una colonna o modifica del tipo di dati di una colonna) attivano uno snapshot di nuovo della tabella interessata. CDF rilegge l'intera tabella da Postgres e la riscrive nella tabella Delta di destinazione.
Disabilitare Lakebase CDF
La disabilitazione di CDF arresta il feed per tutti gli schemi Lakebase nel progetto.
- Nell'area di lavoro Azure Databricks aprire Lakebase Postgres dall'interruttore dell'app (in alto a destra).
- Selezionare il progetto Lakebase e il ramo in cui è stato configurato CDF.
- Aprire Panoramica di Branch e fare clic sulla scheda Feed di dati delle modifiche .
- Fare clic su Disabilita. Nella finestra di dialogo di conferma, verificare l'avviso che le modifiche non verranno più applicate alle tabelle Delta, quindi fare di nuovo clic su Disabilita per confermare.
La disabilitazione di CDF non riavvia il calcolo.
Avvertimento
Se si riattiva CDF più tardi, il sistema non esegue una nuova snapshot completa. Tutte le modifiche apportate durante la disattivazione di CDF risultano mancanti in modo permanente nelle tabelle Delta di destinazione.
Limitazioni e risoluzione dei problemi
Puoi visualizzare lo stato di ogni tabella (snapshot, ignorata o in streaming) nella scheda Feed di dati delle modifiche oppure eseguendo questo comando in Lakebase:
SELECT * FROM wal2delta.tables;
Motivi comuni per cui una tabella non viene visualizzata nel feed:
-
REPLICA IDENTITY FULLnon è impostato: EseguireALTER TABLE <table_name> REPLICA IDENTITY FULL;per la tabella. Vedere Passaggio 1: Impostare l'identità della replica completa. - Tabelle partizionate: Le tabelle partizionate di Lakebase non sono supportate. Uno schema che contiene tabelle partizionate causa l'esito negativo di tali tabelle.
- Tabelle vuote: Una tabella con zero righe viene ignorata fino a quando non esiste almeno una riga.
Passaggi successivi
- Compilazione di ETL incrementali con pipeline dichiarative Spark. Per una procedura dettagliata completa, vedere Esercitazione: Creare una pipeline ETL usando Change Data Capture .
- Eseguire query sul livello bronze con Databricks SQL. Vedere Introduzione al data warehousing con Databricks SQL.
- Cronologia di controllo con query di spostamento temporali nelle tabelle Delta di destinazione.