Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si crea e si distribuisce una pipeline ETL (estrazione, trasformazione e caricamento) con Change Data Capture (CDC) usando le pipeline Lakeflow per l'orchestrazione dei dati e il caricatore automatico. Una pipeline ETL implementa i passaggi per leggere i dati dai sistemi di origine, trasformare tali dati in base ai requisiti, ad esempio i controlli della qualità dei dati e registrare la deduplicazione dei dati e scrivere i dati in un sistema di destinazione, ad esempio un data warehouse o un data lake.
In questa esercitazione si useranno i dati di una customers tabella in un database MySQL per:
- Estrarre le modifiche da un database transazionale usando Debezium o un altro strumento e salvarle nell'archiviazione di oggetti cloud (S3, ADLS o GCS). In questa esercitazione si ignora la configurazione di un sistema CDC esterno e si generano invece dati falsi per semplificare l'esercitazione.
- Usare il caricatore automatico per caricare in modo incrementale i messaggi dall'archiviazione di oggetti cloud e archiviare i messaggi non elaborati nella
customers_cdctabella. Auto Loader deduce lo schema e gestisce l'evoluzione dello schema. - Creare la tabella per controllare la
customers_cdc_cleanqualità dei dati usando le aspettative. Ad esempio,idnon dovrebbe mai esserenullperché viene utilizzato per eseguire operazioni upsert. - Eseguire
AUTO CDC ... INTOsui dati CDC puliti per effettuare l'upsert delle modifiche nella tabella finalecustomers. - Mostrare come una pipeline può creare una tabella di dimensione a modifica lenta (SCD2) di tipo 2 per tenere traccia di tutte le modifiche.
L'obiettivo è inserire i dati non elaborati quasi in tempo reale e creare una tabella per il team analista garantendo al tempo stesso la qualità dei dati.
L'esercitazione utilizza l'architettura medallion Lakehouse, in cui ingestisce i dati grezzi tramite il livello bronzo, pulisce e convalida i dati con il livello argento e applica la modellazione e l'aggregazione dimensionali mediante il livello oro. Per ulteriori informazioni, vedere Che cos'è l'architettura del lakehouse medallion?
Il flusso implementato è simile al seguente:
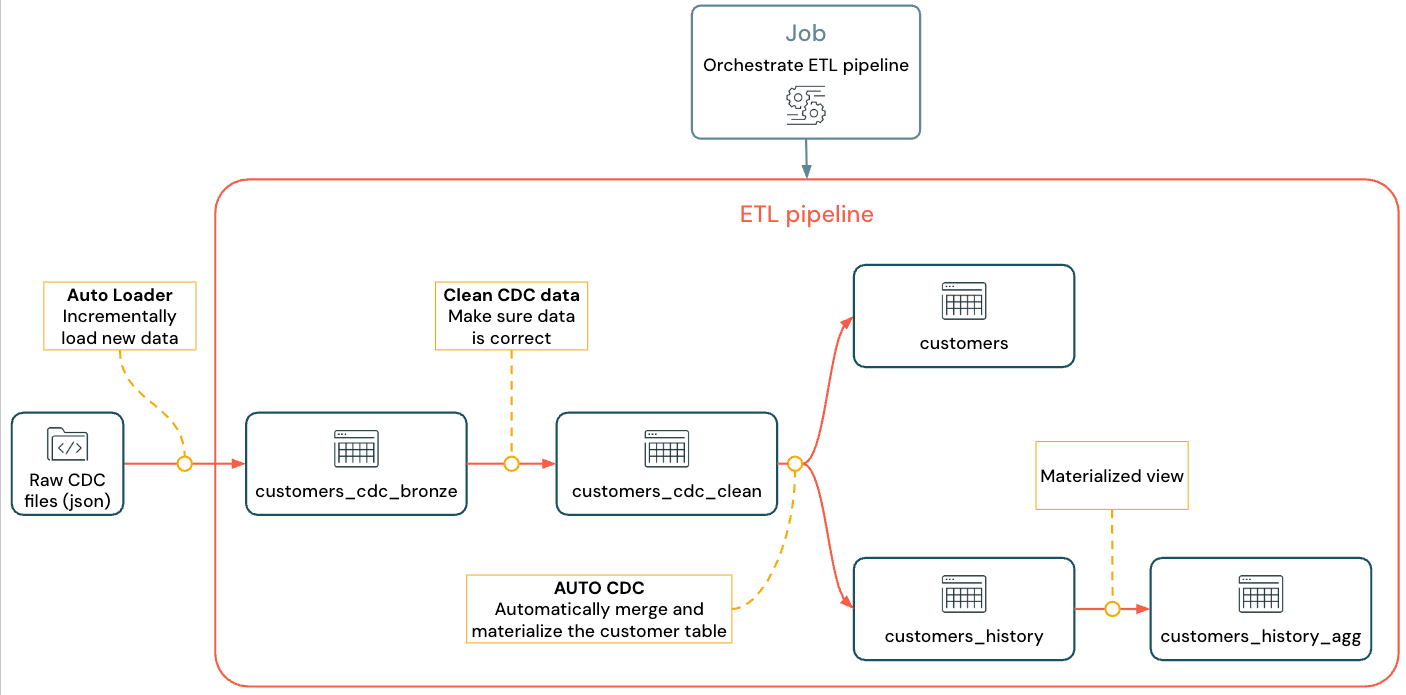
Per ulteriori informazioni su pipeline, Auto Loader e CDC, consulta Pipeline dichiarative di Spark, Che cos'è Auto Loader? e Acquisizione dei dati modificati e snapshot
Requisiti
Per completare questa esercitazione, è necessario soddisfare i requisiti seguenti:
- Unity Catalog è abilitato per l'area di lavoro.
- L'ambiente di calcolo serverless è disponibile nell'area di lavoro (abilitato per impostazione predefinita nelle aree di lavoro con Il catalogo unity). Le pipeline Serverless Lakeflow non sono disponibili in tutte le aree dell'area di lavoro. Vedere Funzionalità con disponibilità a livello di area limitata per le aree disponibili. Se l'ambiente di calcolo serverless non è disponibile, i passaggi devono essere usati con il calcolo predefinito per l'area di lavoro.
- Autorizzazione per creare una risorsa di calcolo o accedere a una risorsa di calcolo.
- Autorizzazioni per creare un nuovo schema in un catalogo. Le autorizzazioni necessarie sono
USE CATALOGeCREATE SCHEMA. - Autorizzazioni per creare un nuovo volume in uno schema esistente. Le autorizzazioni necessarie sono
USE SCHEMAeCREATE VOLUME. - Per il set completo di privilegi necessari per creare, eseguire, aggiornare e visualizzare le pipeline e il relativo output, vedere Gestire identità, autorizzazioni e privilegi per le pipeline.
Acquisizione delle Modifiche dei Dati in una pipeline ETL
Change Data Capture (CDC) è il processo che acquisisce le modifiche apportate ai record apportati a un database transazionale (ad esempio, MySQL o PostgreSQL) o a un data warehouse. CDC acquisisce operazioni come eliminazioni, accodamenti e aggiornamenti dei dati, in genere come flusso per ri materializzare le tabelle in sistemi esterni. CDC abilita il caricamento incrementale eliminando la necessità di aggiornamenti di caricamento in blocco.
Annotazioni
Per semplificare questa esercitazione, ignorare la configurazione di un sistema CDC esterno. Si supponga di eseguire e salvare i dati CDC come file JSON nell'archiviazione di oggetti cloud (S3, ADLS o GCS). Questa esercitazione usa la Faker libreria per generare i dati usati nell'esercitazione.
Acquisizione di CDC
Sono disponibili diversi strumenti CDC. Una delle principali soluzioni open source è Debezium, ma altre implementazioni che semplificano le origini dati esistono, ad esempio Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate e AWS DMS.
In questa esercitazione si usano dati CDC da un sistema esterno, ad esempio Debezium o DMS. Debezium acquisisce ogni riga modificata. In genere invia la cronologia delle modifiche dei dati agli argomenti Kafka o li salva come file.
È necessario inserire le informazioni CDC dalla customers tabella (formato JSON), verificare che siano corrette e quindi materializzare la tabella dei clienti nel Lakehouse.
Input CDC da Debezium
Per ogni modifica, viene visualizzato un messaggio JSON contenente tutti i campi della riga da aggiornare (id, firstname, lastnameemail, , address). Il messaggio include anche metadati aggiuntivi:
-
operation: codice dell'operazione, in genere (DELETE,APPEND,UPDATE). -
operation_date: La data e il timestamp per il record di ogni azione operativa.
Gli strumenti come Debezium possono produrre output più avanzati, ad esempio il valore di riga prima della modifica, ma questa esercitazione li omette per semplicità.
Passaggio 1: creare una pipeline
Creare una nuova pipeline ETL per creare query sull'origine dati CDC e generare tabelle nell'area di lavoro.
Nell'area di lavoro fare clic
 Novità nella barra laterale, quindi selezionare Pipeline ETL. Verrà aperto l'editor della pipeline con un nome di pipeline predefinito, ad esempio
Novità nella barra laterale, quindi selezionare Pipeline ETL. Verrà aperto l'editor della pipeline con un nome di pipeline predefinito, ad esempio New Pipeline <date> <time>.Selezionare il nome e immettere un nome descrittivo, ad esempio
Pipelines with CDC tutorial.A destra del nome, fare clic sul catalogo e sullo schema per scegliere le impostazioni predefinite per le quali si dispone delle autorizzazioni di scrittura.
Questo catalogo e schema vengono usati per impostazione predefinita, se non si specifica un catalogo o uno schema nel codice. Il codice può scrivere in qualsiasi catalogo o schema specificando il percorso completo. Questa esercitazione usa le impostazioni predefinite specificate qui.
(Facoltativo) Nel file di origine
my_transformationcreato, selezionare Python o SQL dall'elenco a discesa della lingua per impostare la lingua per il file.Fare clic
 Usare il codice di esempio.
Usare il codice di esempio.
L'editor Lakeflow Pipelines si apre con i file di esempio nella pipeline. I file di trasformazione verranno aggiunti nei passaggi successivi. Configurare quindi i dati di esempio da importare nell'esercitazione.
Passaggio 2: Creare i dati di esempio da importare in questa esercitazione
Questo passaggio non è necessario se si importano dati personalizzati da un'origine esistente. Per questa esercitazione, generare dati falsi come esempio per l'esercitazione. Creare un notebook per eseguire lo script di generazione di dati Python. Questo codice deve essere eseguito una sola volta per generare i dati di esempio, quindi crearlo all'interno della cartella della explorations pipeline, che non viene eseguito come parte di un aggiornamento della pipeline.
Annotazioni
Questo codice usa Faker per generare i dati CDC di esempio. Faker è disponibile per l'installazione automatica, quindi il tutorial utilizza %pip install faker. È anche possibile impostare una dipendenza da faker per il notebook. Vedere Aggiungere dipendenze al notebook.
Dall'interno dell'editor di Lakeflow Pipelines, nella barra laterale nel browser asset a sinistra dell'editor, fai clic
Aggiungi e scegli Esplorazione.Assegnargli un Name, ad esempio
Setup data, selezionare Python. È possibile lasciare la cartella di destinazione predefinita, ovvero una nuovaexplorationscartella.Clicca su Crea. Verrà creato un notebook nella nuova cartella.
Immettere il codice seguente nella prima cella. È necessario modificare la definizione di
<my_catalog>e<my_schema>in modo che corrisponda al catalogo e allo schema predefiniti selezionati nella procedura precedente:%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Per generare il set di dati usato nell'esercitazione, digitare MAIUSC + INVIO per eseguire il codice:
Optional. Per visualizzare in anteprima i dati usati in questa esercitazione, immettere il codice seguente nella cella successiva ed eseguire il codice. Aggiornare il catalogo e lo schema in modo che corrispondano al percorso del codice precedente.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Questo genera un set di dati di grandi dimensioni (con dati CDC falsi) che è possibile usare nel resto dell'esercitazione. Nel passaggio successivo inserire i dati usando il caricatore automatico.
Passaggio 3: Inserire dati in modo incrementale con il caricatore automatico
Il passaggio successivo consiste nell'inserire i dati non elaborati dall'archiviazione cloud (falsificata) in un livello bronze.
Questo può essere difficile per diversi motivi, perché è necessario:
- Operare su larga scala, potenzialmente inglobando milioni di piccoli file.
- Dedurre lo schema e il tipo JSON.
- Gestire record non validi con uno schema JSON non corretto.
- Prestare attenzione all'evoluzione dello schema, ad esempio una nuova colonna nella tabella cliente.
Auto Loader semplifica questo processo di inserimento, comprese l'inferenza dello schema e l'evoluzione dello schema, scalando fino a milioni di file in arrivo. Il caricatore automatico è disponibile in Python usando cloudFiles e in SQL usando il SELECT * FROM STREAM read_files(...) e può essere usato con un'ampia gamma di formati (JSON, CSV, Apache Avro e così via):
Definire la tabella come tabella di streaming garantisce che si consumino solo i nuovi dati in arrivo. Se non lo si definisce come tabella di streaming, analizza e inserisce tutti i dati disponibili. Per altre informazioni, vedere Tabelle di streaming .
Per inserire i dati CDC in ingresso usando il caricatore automatico, copiare e incollare il codice seguente nel file di codice creato con la pipeline (denominata
my_transformation.pyomy_transformation.sql). È possibile usare Python o SQL in base al linguaggio scelto durante la creazione della pipeline. Assicurati di sostituire<catalog>e<schema>con quelli che hai configurato come predefiniti per la pipeline.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )Fare clic
 Eseguire il file o Eseguire la pipeline per avviare l'aggiornamento della pipeline connessa. Con un solo file di origine nella pipeline, questi sono equivalenti a livello funzionale.
Eseguire il file o Eseguire la pipeline per avviare l'aggiornamento della pipeline connessa. Con un solo file di origine nella pipeline, questi sono equivalenti a livello funzionale.
Al termine dell'aggiornamento, l'editor viene aggiornato con informazioni sulla pipeline.
- Il grafico della pipeline, detto anche grafo aciclico diretto (DAG), nella barra laterale a destra del codice mostra una singola tabella,
customers_cdc_bronze. - Nella parte superiore del browser delle risorse della pipeline viene visualizzato un riepilogo dell'aggiornamento.
- I dettagli della tabella generata vengono visualizzati nel riquadro inferiore ed è possibile esplorare i dati dalla tabella selezionandolo.
Si tratta dei dati del livello bronzo non elaborati importati dall'archiviazione cloud. Nel passaggio successivo pulire i dati per creare una tabella livello silver.
Passaggio 4: Pulizia e aspettative per tenere traccia della qualità dei dati
Dopo aver definito il livello bronzo, creare il livello argento aggiungendo aspettative per controllare la qualità dei dati. Controllare le condizioni seguenti:
- L'ID non deve mai essere
null. - Il tipo di operazione CDC deve essere valido.
- JSON deve essere letto correttamente dal caricatore automatico.
Le righe che non soddisfano queste condizioni vengono eliminate.
Per altre informazioni, vedere Gestire la qualità dei dati con le aspettative della pipeline .
Nella barra laterale del browser delle risorse della pipeline, fare clic
su Aggiungi, quindi su Trasformazione.Immettere un Name (ad esempio,
customers_silver) e scegliere una lingua (Python o SQL) per il file di codice sorgente. L'estensione.pyo.sqlviene aggiunta in base alla lingua scelta. È possibile mescolare e abbinare le lingue all'interno di una pipeline, quindi puoi sceglierne una per questo passaggio.Per creare un livello silver con una tabella pulita e imporre vincoli, copiare e incollare il codice seguente nel nuovo file (scegliere Python o SQL in base al linguaggio del file).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Fare clic
Eseguire il file o Eseguire la pipeline per avviare l'aggiornamento della pipeline connessa.Poiché ora sono presenti due file di origine, questi non fanno la stessa cosa, ma in questo caso l'output è lo stesso.
- Esegui la pipeline esegue tutta la pipeline, incluso il codice nel passaggio 3. Se i dati di input venissero aggiornati, ciò eseguirebbe l'acquisizione di eventuali modifiche da quella fonte al livello bronze. Questo non esegue il codice dal passaggio di configurazione dei dati, perché si trova nella cartella delle esplorazioni e non fa parte della sorgente della tua pipeline.
- Il file di esecuzione esegue solo il file di origine corrente. In questo caso, senza aggiornare i dati di input, vengono generati i dati silver dalla tabella bronze memorizzata nella cache. Sarebbe utile eseguire solo questo file per un'iterazione più veloce durante la creazione o la modifica del codice della pipeline.
Al termine dell'aggiornamento, è possibile notare che il grafico della pipeline mostra ora due tabelle (con il livello argento a seconda del livello bronzo) e il pannello inferiore mostra i dettagli per entrambe le tabelle. La parte superiore del browser delle risorse della pipeline ora mostra gli orari di più esecuzioni, ma solo i dettagli dell’esecuzione più recente.
Quindi, crea la versione finale del livello oro della tabella customers.
Passaggio 5: Materializza la tabella clienti con un flusso CDC automatico
Fino a questo punto, le tabelle hanno semplicemente passato i dati CDC ad ogni passaggio. Creare ora la customers tabella in modo che contenga la visualizzazione più aggiornata e che sia una replica della tabella originale, non l'elenco di operazioni CDC che le hanno creato.
Implementare manualmente non è un compito banale. È necessario considerare elementi come la deduplicazione dei dati per mantenere la riga più recente.
Tuttavia, le pipeline risolvono queste sfide con l'operazione AUTO CDC .
Nella barra laterale del browser delle risorse della pipeline fare clic su
Aggiungi e Trasformazione.Immettere un Name e scegliere una lingua (Python o SQL) per il nuovo file di codice sorgente. È possibile scegliere di nuovo una delle due lingue per questo passaggio, ma usare il codice corretto, riportato di seguito.
Per elaborare i dati CDC usando
AUTO CDC, copiare e incollare il codice seguente nel nuovo file.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Fare clic
Eseguire il file \"Run\" per avviare l'aggiornamento della pipeline connessa.
Al termine dell'aggiornamento, è possibile osservare che il grafico della pipeline mostra 3 tabelle, passando dal bronzo, all'argento, fino all'oro.
Passaggio 6: Tenere traccia della cronologia degli aggiornamenti con il tipo di dimensione a modifica lenta 2 (SCD2)
Spesso è necessario creare una tabella che monitora tutte le modifiche risultanti da APPEND, UPDATEe DELETE:
- Cronologia: si vuole mantenere una cronologia di tutte le modifiche apportate alla tabella.
- Tracciabilità: si vuole vedere quale operazione si è verificata.
SCD2 con le pipeline Lakeflow
Delta supporta il flusso di dati delle modifiche (CDF) e table_change può eseguire query sulle modifiche alla tabella in SQL e Python. Tuttavia, il caso d'uso principale di CDF consiste nell'acquisire le modifiche all'interno di una pipeline, non per creare una visualizzazione completa delle modifiche della tabella dall'inizio.
Le cose sono particolarmente complesse da implementare se si dispone di eventi non ordinati. Se è necessario sequenziare le modifiche in base a un timestamp e ricevere una modifica apportata in passato, è necessario aggiungere una nuova voce nella tabella a modifica lenta e aggiornare le voci precedenti.
Le pipeline di Lakeflow rimuovono questa complessità. È possibile creare una tabella separata contenente tutte le modifiche fin dall'inizio, mantenuta automaticamente dalla pipeline. Questa tabella supporta le ottimizzazioni del layout dei dati, ad esempio il clustering liquido e gestisce automaticamente i record non ordinati in base a _sequence_by. Vedere Usare clustering liquido per le tabelle.
Per creare una tabella SCD2, usare l'opzione STORED AS SCD TYPE 2 in SQL o stored_as_scd_type="2" in Python.
Annotazioni
È anche possibile limitare quali colonne la funzionalità traccia tramite l'opzione: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Nella barra laterale del browser delle risorse della pipeline fare clic su
Aggiungi e Trasformazione.Immettere un Name e scegliere una lingua (Python o SQL) per il nuovo file di codice sorgente.
Copiare e incollare il codice seguente nel nuovo file.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Fare clic
Eseguire il file \"Run\" per avviare l'aggiornamento della pipeline connessa.
Al termine dell'aggiornamento, il grafico della pipeline include la nuova tabella customers_history, dipendente anche dalla tabella del livello argento, mentre il pannello inferiore mostra i dettagli per tutte le quattro tabelle.
Passaggio 7: Creare una vista materializzata che tiene traccia di chi ha modificato maggiormente le proprie informazioni.
La tabella customers_history contiene tutte le modifiche cronologiche apportate da un utente alle relative informazioni. Creare una visualizzazione materializzata semplice nel livello oro che tiene traccia di chi ha modificato le informazioni di più. Questo può essere usato per l'analisi del rilevamento delle frodi o le raccomandazioni degli utenti in uno scenario reale. Inoltre, l'applicazione delle modifiche con SCD2 ha già rimosso duplicati, in modo da poter contare direttamente le righe per ID utente.
Nella barra laterale del browser delle risorse della pipeline fare clic su
Aggiungi e Trasformazione.Immettere un Name e scegliere una lingua (Python o SQL) per il nuovo file di codice sorgente.
Copiare e incollare il codice seguente nel nuovo file di origine.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count_distinct("address").alias("address_count"), count_distinct("email").alias("email_count"), count_distinct("firstname").alias("firstname_count"), count_distinct("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count(distinct address) as address_count, count(distinct email) AS email_count, count(distinct firstname) AS firstname_count, count(distinct lastname) AS lastname_count FROM customers_history GROUP BY idFare clic
Eseguire il file \"Run\" per avviare l'aggiornamento della pipeline connessa.
Al termine dell'aggiornamento, nel grafico della pipeline è presente una nuova tabella che dipende dalla tabella customers_history ed è possibile visualizzarla nel pannello inferiore. La tua pipeline è ora completa. È possibile testarlo eseguendo una pipeline di esecuzione completa. Gli unici passaggi lasciati sono pianificare regolarmente l'aggiornamento della pipeline.
Passaggio 8: Creare un processo per eseguire la pipeline ETL
Creare quindi un flusso di lavoro per automatizzare i passaggi di inserimento, elaborazione e analisi dei dati nella pipeline usando un processo di Databricks.
- Nella parte superiore dell'editor scegliere il pulsante Pianifica .
- Se viene visualizzata la finestra di dialogo Pianificazioni , scegliere Aggiungi pianificazione.
- Verrà visualizzata la finestra di dialogo Nuova pianificazione , in cui è possibile creare un processo per eseguire la pipeline in base a una pianificazione.
- Facoltativamente, dare un nome al job.
- Per impostazione predefinita, la pianificazione è impostata per l'esecuzione una volta al giorno. È possibile accettare questo valore predefinito o impostare una pianificazione personalizzata. Scegliendo Avanzate è possibile impostare un orario specifico in cui verrà eseguito il processo. Se si seleziona Altre opzioni , è possibile creare notifiche durante l'esecuzione del processo.
- Seleziona Crea per applicare le modifiche e creare l'attività.
Ora l'attività verrà eseguita ogni giorno per mantenere aggiornata la pipeline. È possibile scegliere di nuovo Pianifica per visualizzare l'elenco delle pianificazioni. È possibile gestire le pianificazioni per la pipeline da tale finestra di dialogo, inclusa l'aggiunta, la modifica o la rimozione di pianificazioni.
Facendo clic sul nome del programma (o del processo), si accede alla pagina del processo nell'elenco Processi e pipeline. Da qui è possibile visualizzare i dettagli sulle esecuzioni dei processi, inclusa la cronologia delle esecuzioni o eseguire immediatamente il processo con il pulsante Esegui adesso .
Per altre informazioni sulle esecuzioni dei processi, vedere Monitorare i processi Lakeflow .
Risorse aggiuntive
- Pipeline dichiarative di Spark
- Tutorial: Creazione di una pipeline ETL con le pipeline Lakeflow
- Acquisizione delle modifiche e istantanee
- Le API AUTO CDC: semplificare la cattura dei dati di modifica con le pipeline
- Convertire una pipeline in un progetto di bundle
- Che cos'è il caricatore automatico?