Shiny in Azure Databricks
Shiny è un pacchetto R, disponibile in CRAN, usato per creare dashboard e applicazioni R interattive. È possibile usare Shiny all'interno di RStudio Server ospitato in cluster di Azure Databricks. È anche possibile sviluppare, ospitare e condividere applicazioni Shiny direttamente da un notebook di Azure Databricks.
Per iniziare a usare Shiny, vedere le esercitazioni shiny. È possibile eseguire queste esercitazioni nei notebook di Azure Databricks.
Questo articolo descrive come eseguire applicazioni Shiny in Azure Databricks e usare Apache Spark all'interno di applicazioni Shiny.
Notebook R lucidi all'interno di R
Introduzione a Shiny all'interno di notebook R
Il pacchetto Shiny è incluso in Databricks Runtime. È possibile sviluppare e testare in modo interattivo applicazioni Shiny all'interno di notebook R di Azure Databricks in modo analogo a RStudio ospitato.
Per iniziare, segui questa procedura:
Creare un notebook R.
Importare il pacchetto Shiny ed eseguire l'app
01_hellodi esempio come segue:library(shiny) runExample("01_hello")Quando l'app è pronta, l'output include l'URL dell'app Shiny come collegamento selezionabile che apre una nuova scheda. Per condividere questa app con altri utenti, vedere Condividere l'URL dell'app Shiny.

Nota
- I messaggi di log vengono visualizzati nel risultato del comando, in modo analogo al messaggio di log predefinito (
Listening on http://0.0.0.0:5150) illustrato nell'esempio. - Per arrestare l'applicazione Shiny, fare clic su Annulla.
- L'applicazione Shiny usa il processo R del notebook. Se si scollega il notebook dal cluster o si annulla la cella che esegue l'applicazione, l'applicazione Shiny termina. Non è possibile eseguire altre celle mentre l'applicazione Shiny è in esecuzione.
Eseguire app Shiny dalle cartelle Git di Databricks
È possibile eseguire app Shiny archiviate nelle cartelle Git di Databricks.
Clonare un repository Git remoto.
Eseguire l'applicazione.
library(shiny) runApp("006-tabsets")
Eseguire app Shiny da file
Se il codice dell'applicazione Shiny fa parte di un progetto gestito dal controllo della versione, è possibile eseguirlo all'interno del notebook.
Nota
È necessario usare il percorso assoluto o impostare la directory di lavoro con setwd().
Controllare il codice da un repository usando codice simile al seguente:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Per eseguire l'applicazione, immettere codice simile al seguente in un'altra cella:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Condividere l'URL dell'app Shiny
L'URL dell'app Shiny generato all'avvio di un'app è condivisibile con altri utenti. Qualsiasi utente di Azure Databricks con l'autorizzazione CAN ATTACH TO nel cluster può visualizzare e interagire con l'app purché sia l'app che il cluster siano in esecuzione.
Se il cluster in cui è in esecuzione l'app viene interrotta, l'app non è più accessibile. È possibile disabilitare la terminazione automatica nelle impostazioni del cluster.
Se si collega ed esegue il notebook che ospita l'app Shiny in un cluster diverso, l'URL lucido cambia. Inoltre, se si riavvia l'app nello stesso cluster, Shiny potrebbe scegliere una porta casuale diversa. Per garantire un URL stabile, è possibile impostare l'opzione shiny.port oppure, quando si riavvia l'app nello stesso cluster, è possibile specificare l'argomento port .
Lucidi in RStudio Server ospitato
Requisiti
Importante
Con RStudio Server Pro, è necessario disabilitare l'autenticazione proxy.
Assicurarsi che auth-proxy=1 non sia presente all'interno /etc/rstudio/rserver.confdi .
Introduzione a Shiny in RStudio Server ospitato
Aprire RStudio in Azure Databricks.
In RStudio importare il pacchetto Shiny ed eseguire l'app
01_hellodi esempio come segue:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Viene visualizzata una nuova finestra che visualizza l'applicazione Shiny.
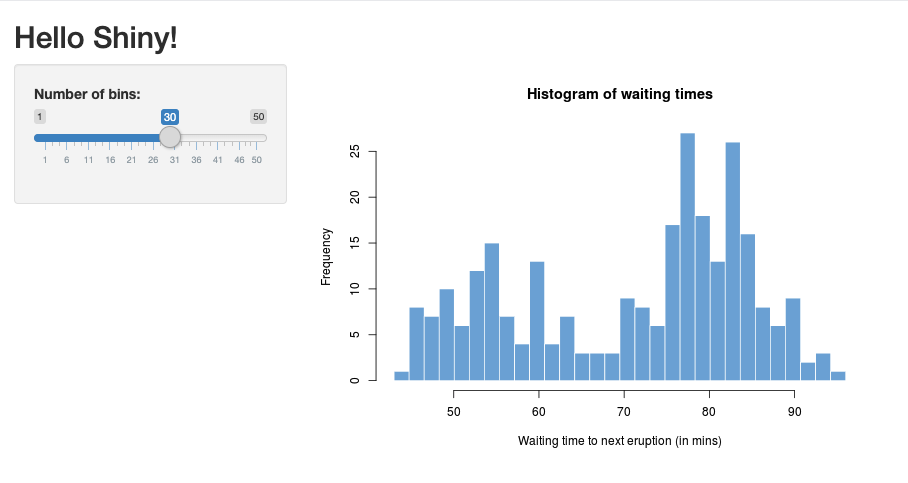
Eseguire un'app Shiny da uno script R
Per eseguire un'app Shiny da uno script R, aprire lo script R nell'editor di RStudio e fare clic sul pulsante Esegui app in alto a destra.
Usare Apache Spark all'interno di app Shiny
È possibile usare Apache Spark all'interno di applicazioni Shiny con SparkR o sparklyr.
Usare SparkR con Shiny in un notebook
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Usare sparklyr con Shiny in un notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
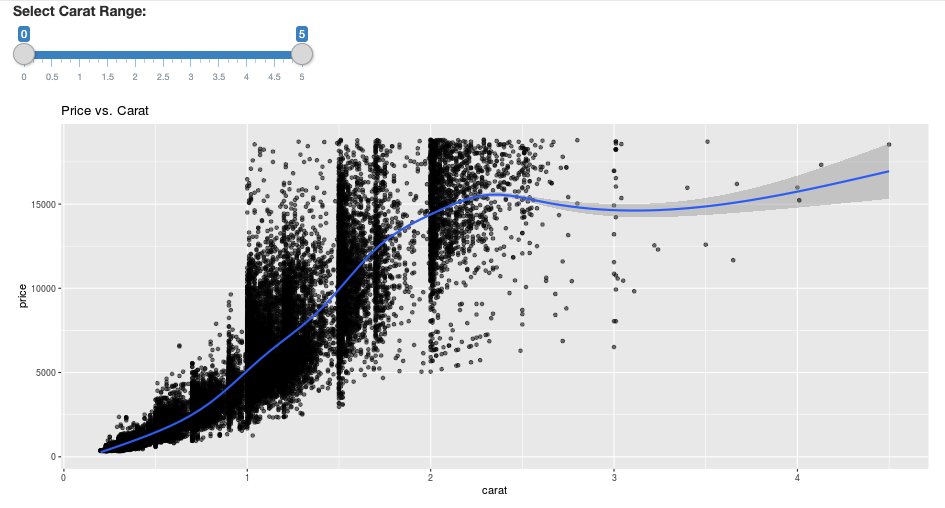
Domande frequenti
- Perché l'app Shiny è disattivata dopo qualche tempo?
- Perché la finestra del visualizzatore Shiny scompare dopo un po'?
- Perché i processi Spark lunghi non restituiscono mai?
- Come è possibile evitare il timeout?
- L'app si arresta in modo anomalo immediatamente dopo l'avvio, ma il codice sembra essere corretto. Che cosa succede?
- Quante connessioni possono essere accettate per un collegamento a un'app Shiny durante lo sviluppo?
- È possibile usare una versione diversa del pacchetto Shiny rispetto a quella installata in Databricks Runtime?
- Come è possibile sviluppare un'applicazione Shiny che può essere pubblicata in un server Shiny e accedere ai dati in Azure Databricks?
- È possibile sviluppare un'applicazione Shiny all'interno di un notebook di Azure Databricks?
- Come è possibile salvare le applicazioni Shiny sviluppate in RStudio Server ospitato?
Perché l'app Shiny è disattivata dopo qualche tempo?
Se non è presente alcuna interazione con l'app Shiny, la connessione all'app si chiude dopo circa 4 minuti.
Per riconnettersi, aggiornare la pagina dell'app Shiny. Lo stato del dashboard viene reimpostato.
Perché la finestra del visualizzatore Shiny scompare dopo un po'?
Se la finestra del visualizzatore Shiny scompare dopo alcuni minuti di inattività, è dovuto allo stesso timeout dello scenario di "grigio".
Perché i processi Spark lunghi non restituiscono mai?
Ciò è dovuto anche al timeout di inattività. Qualsiasi processo Spark in esecuzione per più tempo rispetto ai timeout indicati in precedenza non è in grado di eseguire il rendering del risultato perché la connessione viene chiusa prima che il processo venga restituito.
Come è possibile evitare il timeout?
Esiste una soluzione alternativa suggerita nella richiesta di funzionalità: chiedere al client di inviare un messaggio keep-alive per evitare il timeout TCP in alcuni servizi di bilanciamento del carico in GitHub. La soluzione alternativa invia heartbeat per mantenere attiva la connessione WebSocket quando l'app è inattiva. Tuttavia, se l'app è bloccata da un calcolo a esecuzione prolungata, questa soluzione alternativa non funziona.
Shiny non supporta attività a esecuzione prolungata. Un post di blog Shiny consiglia di usare promesse e future per eseguire attività lunghe in modo asincrono e mantenere l'app sbloccata. Di seguito è riportato un esempio che usa heartbeat per mantenere attiva l'app Shiny ed esegue un processo Spark a esecuzione prolungata in un
futurecostrutto.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)È previsto un limite rigido di 12 ore dal caricamento iniziale della pagina dopo il quale qualsiasi connessione, anche se attiva, verrà terminata. È necessario aggiornare l'app Shiny per riconnettersi in questi casi. Tuttavia, la connessione WebSocket sottostante può essere chiusa in qualsiasi momento da diversi fattori, tra cui l'instabilità della rete o la modalità sospensione del computer. Databricks consiglia di riscrivere le app Shiny in modo che non richiedano una connessione di lunga durata e non si basano sullo stato della sessione.
L'app si arresta in modo anomalo immediatamente dopo l'avvio, ma il codice sembra essere corretto. Che cosa succede?
Esiste un limite di 50 MB per la quantità totale di dati che è possibile visualizzare in un'app Shiny in Azure Databricks. Se le dimensioni totali dei dati dell'applicazione superano questo limite, si arresterà immediatamente dopo l'avvio. Per evitare questo problema, Databricks consiglia di ridurre le dimensioni dei dati, ad esempio eseguendo il downcampioning dei dati visualizzati o riducendo la risoluzione delle immagini.
Quante connessioni possono essere accettate per un collegamento a un'app Shiny durante lo sviluppo?
Databricks consiglia fino a 20.
È possibile usare una versione diversa del pacchetto Shiny rispetto a quella installata in Databricks Runtime?
Sì. Vedere Correggere la versione dei pacchetti R.
Come è possibile sviluppare un'applicazione Shiny che può essere pubblicata in un server Shiny e accedere ai dati in Azure Databricks?
Sebbene sia possibile accedere ai dati in modo naturale usando SparkR o sparklyr durante lo sviluppo e il test in Azure Databricks, dopo che un'applicazione Shiny viene pubblicata in un servizio di hosting autonomo, non può accedere direttamente ai dati e alle tabelle in Azure Databricks.
Per consentire all'applicazione di funzionare all'esterno di Azure Databricks, è necessario riscrivere il modo in cui si accede ai dati. Sono disponibili alcune opzioni:
- Usare JDBC/ODBC per inviare query a un cluster Azure Databricks.
- Usare databricks Connessione.
- Accedere direttamente ai dati nell'archivio oggetti.
Databricks consiglia di collaborare con il team di soluzioni Di Azure Databricks per trovare l'approccio migliore per l'architettura di analisi e dati esistente.
È possibile sviluppare un'applicazione Shiny all'interno di un notebook di Azure Databricks?
Sì, è possibile sviluppare un'applicazione Shiny all'interno di un notebook di Azure Databricks.
Come è possibile salvare le applicazioni Shiny sviluppate in RStudio Server ospitato?
È possibile salvare il codice dell'applicazione in DBFS o controllare il codice nel controllo della versione.