Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa pagina descrive come usare le tabelle Delta come origini e sink per Spark Structured Streaming con readStream e writeStream. Delta Lake risolve i problemi comuni di prestazioni e affidabilità per i sistemi e i file di streaming. I vantaggi includono:
- Unire file di piccole dimensioni prodotti dall'acquisizione a bassa latenza e migliorare le prestazioni.
- Mantenere l'elaborazione "esattamente una volta" con più flussi di dati (o lavori batch simultanei).
- Individuare in modo efficiente nuovi file quando si usano file come origine di flusso.
Per informazioni su come caricare dati usando tabelle di streaming in Databricks SQL, vedere Usare tabelle di streaming autonome.
Per i join statici di flusso con Delta Lake, vedere Join statici di stream.
Per un elenco completo delle opzioni DataStreamReader e DataStreamWriter di Delta Lake, vedere DataStreamReader opzioni Delta Lake e DataStreamWriter opzioni Delta Lake.
Warning
Se si usa una tabella Delta come origine di streaming, la query di streaming deve essere eseguita almeno una volta all'interno della finestra di conservazione della tabella di origine. Le finestre di conservazione predefinite sono 7 giorni per VACUUMi file di dati rimossi e 30 giorni per il log delle transazioni (logRetentionDuration). Se una query si basa su queste finestre, ha esito negativo e DELTA_FILE_NOT_FOUND_DETAILED deve essere reimpostata con un aggiornamento completo.
Non impostare spark.sql.files.ignoreMissingFiles su true come soluzione temporanea, perché questa configurazione produce in modo silenzioso risultati errati. Se la pianificazione di uno stream non riesce a tenere il passo con le finestre di conservazione predefinite, aumenta invece il periodo di conservazione della tabella di origine.
Usare le tabelle Delta come destinazione
È possibile scrivere dati in una tabella Delta usando Structured Streaming. Il log delle transazioni di Delta Lake garantisce l'elaborazione esatta una volta, anche quando ci sono altri flussi o query batch in esecuzione simultaneamente sulla tabella.
Quando si scrive in una tabella Delta usando un sink Structured Streaming, è possibile che vengano visualizzati commit vuoti con epochId = -1. Questi sono previsti e in genere si verificano:
- Nel primo batch di ogni esecuzione della query di streaming (questo avviene ogni batch per
Trigger.AvailableNow). - Quando viene modificato uno schema, ad esempio l'aggiunta di una colonna.
Questi commit vuoti sono intenzionali e non indicano un errore. Non influiscono sulla correttezza o sulle prestazioni della query in alcun modo significativo.
Note
La funzione Delta Lake rimuove tutti i file non gestiti da Delta Lake VACUUM , ma ignora tutte le directory che iniziano con _. È possibile archiviare in modo sicuro i checkpoint insieme ad altri dati e metadati per una tabella Delta usando una struttura di directory, ad esempio <table-name>/_checkpoints.
Monitorare il backlog con le metriche
Usare le metriche seguenti per monitorare il backlog di un processo di query di streaming:
-
numBytesOutstanding: numero di byte ancora da elaborare nel backlog. -
numFilesOutstanding: numero di file ancora da elaborare nel backlog. -
numNewListedFiles: numero di file Delta Lake elencati per calcolare il backlog per questo batch. -
backlogEndOffset: versione della tabella Delta usata per calcolare il backlog.
Nel notebook, visualizza queste metriche nella scheda Dati grezzi nel dashboard dello stato di avanzamento delle query di streaming.
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Modalità accodamento
Per impostazione predefinita, i flussi vengono eseguiti in modalità di accodamento e aggiungono solo nuovi record alla tabella.
Usare il metodo toTable allo streaming nelle tabelle:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Modalità completa
Usare Structured Streaming con modalità completa per sostituire l'intera tabella dopo ogni batch. Ad esempio, è possibile aggiornare continuamente una tabella di riepilogo aggregata degli eventi da parte del cliente:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Per le applicazioni senza requisiti di latenza rigorosi, è possibile risparmiare risorse di calcolo e costi con trigger monouso, AvailableNowad esempio . Ad esempio, usa questo trigger per aggiornare le tabelle di sintesi aggregata in un orario stabilito, elaborando solo i nuovi dati arrivati dopo l'ultimo aggiornamento. Vedere AvailableNow: Elaborazione batch incrementale.
Gestire le modifiche alle tabelle Delta di origine
Structured Streaming legge in modo incrementale le tabelle Delta. Quando una query di streaming legge da una tabella Delta, i nuovi record vengono elaborati in modo idempotente quando le nuove versioni della tabella eseguono il commit nella tabella di origine. Structured Streaming accetta solo input di accodamento e genera un'eccezione se si verificano modifiche nella tabella Delta di origine. Ad esempio, se un'operazione UPDATE, DELETE, MERGE INTOo OVERWRITE modifica una tabella Delta di origine letta da una query di streaming, il flusso ha esito negativo con un errore.
Esistono quattro approcci tipici per la gestione delle modifiche upstream alle tabelle Delta di origine, a seconda del caso d'uso. Di seguito sono riportati una tabella di riferimento e i dettagli su ognuno:
| Avvicinarsi | Pros | Svantaggi |
|---|---|---|
skipChangeCommits |
Semplice, non richiede la scrittura di logica complessa. Utile per l'elaborazione solo in accodamento dove le modifiche upstream vengono gestite separatamente, o per il trattamento temporaneo di un record errato. | Non propaga le modifiche ed elabora solo le aggiunte. |
| Aggiornamento completo | Inoltre, semplice, non richiede la scrittura di logica complessa. Utile per set di dati di piccole dimensioni con rare modifiche upstream. | Costoso per set di dati di grandi dimensioni. Richiede la rielaborazione di tutte le tabelle downstream. |
| Modifica del flusso di dati | Elaborare tutti i tipi di modifica (inserimenti, aggiornamenti ed eliminazioni). Databricks consiglia lo streaming dal feed CDC di una tabella Delta anziché direttamente dalla tabella quando possibile. | Richiede di scrivere logica più complessa per gestire ogni tipo di modifica. |
| Viste materializzate | Alternativa semplice a Structured Streaming con propagazione automatica delle modifiche. | Latenza più elevata. Disponibile solo nelle pipeline dichiarative di Lakeflow Spark e in Databricks SQL. |
Ignorare i commit delle modifiche upstream con skipChangeCommits
Impostare skipChangeCommits per ignorare le transazioni che eliminano o modificano i record esistenti e per elaborare solo le aggiunte. Ciò è utile quando non è necessario propagare le modifiche ai dati esistenti tramite il flusso o quando si preferisce una logica separata per gestire tali modifiche. È possibile attivare e disattivare skipChangeCommits se è necessario ignorare temporaneamente le modifiche una tantum.
Databricks consiglia di usare skipChangeCommits per la maggior parte dei carichi di lavoro che non usano feed di dati di modifica.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Se lo schema di una tabella Delta cambia dopo l'inizio di una lettura in streaming sulla tabella, la query fallisce. Per la maggior parte delle modifiche dello schema, è possibile riavviare il flusso per risolvere la mancata corrispondenza dello schema e continuare l'elaborazione.
In Databricks Runtime 12.2 LTS e versioni successive non è possibile eseguire lo streaming da una tabella Delta con mapping di colonne abilitato che ha subito un'evoluzione dello schema non additivi, ad esempio la ridenominazione o l'eliminazione di colonne. Per informazioni dettagliate, vedere Mapping e streaming delle colonne.
Note
In Databricks Runtime 12.2 LTS e versioni successive, skipChangeCommits sostituisce ignoreChanges. In Databricks Runtime 11.3 LTS e versioni precedenti ignoreChanges è l'unica opzione supportata. Per ulteriori dettagli, vedere Opzione "legacy" ignoreChanges.
Opzione legacy: ignoreDeletes
ignoreDeletes è un'opzione legacy che gestisce solo le transazioni che eliminano i dati ai limiti della partizione, ovvero le eliminazioni di partizione completa. Se è necessario gestire eliminazioni, aggiornamenti o altre modifiche non di partizione, usare skipChangeCommits invece .
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Opzione legacy: ignoreChanges
ignoreChanges è disponibile in Databricks Runtime 11.3 LTS e versioni precedenti. In Databricks Runtime 12.2 LTS e versioni successive viene sostituito da skipChangeCommits.
Con ignoreChanges abilitato, i file di dati riscritti nella tabella di origine vengono re-emessi dopo un'operazione di modifica dei dati, ad esempio UPDATE, MERGE INTO, DELETE (all'interno delle partizioni), o OVERWRITE. Le righe invariate vengono spesso generate insieme a quelle nuove, quindi i consumer downstream devono essere in grado di gestire i duplicati. Le eliminazioni non vengono propagate downstream.
ignoreChanges ha la precedenza rispetto a ignoreDeletes.
Al contrario, skipChangeCommits ignora completamente le operazioni di modifica dei file. I file di dati riscritti nella tabella di origine a causa di operazioni di modifica dei dati come UPDATE, MERGE INTO, DELETEe OVERWRITE vengono ignorati completamente. Per riflettere le modifiche nelle tabelle di origine del flusso, è necessario implementare logica separata per propagare queste modifiche.
Databricks consiglia di usare skipChangeCommits per tutti i nuovi carichi di lavoro. Per eseguire la migrazione di un carico di lavoro da ignoreChanges a skipChangeCommits, effettuare il refactoring della logica di streaming.
Aggiornamento completo delle tabelle downstream
Se le modifiche upstream sono rare e i dati sono sufficientemente piccoli da rielaborare, è possibile eliminare il checkpoint di streaming e la tabella di output, quindi riavviare il flusso dall'inizio. In questo modo, il flusso rielabora tutti i dati della tabella di origine. Tenere presente che questo approccio richiede anche la rielaborazione di tutte le tabelle downstream che dipendono dall'output di questo flusso.
Questo approccio è più adatto per set di dati o carichi di lavoro più piccoli in cui le modifiche upstream sono poco frequenti e il costo di un aggiornamento completo è accettabile.
Usare il feed di dati delle modifiche
Per i carichi di lavoro che elaborano tutti i tipi di modifiche (inserimenti, aggiornamenti ed eliminazioni), usare il feed di dati delle modifiche di Delta Lake. Il feed di dati delle modifiche registra le modifiche a livello di riga in una tabella Delta, consentendo di trasmettere tali modifiche e scrivere la logica per gestire ogni tipo di modifica nelle tabelle downstream. Questo è l'approccio più affidabile perché il codice gestisce in modo esplicito ogni tipo di evento di modifica. Vedere
Se si usano le pipeline dichiarative di Lakeflow Spark, vedere API AUTO CDC: Semplificare la cattura dei dati modificati con le pipeline.
Important
In Databricks Runtime 12.2 LTS e versioni precedenti, non è possibile eseguire lo streaming dal change data feed per una tabella Delta con mapping di colonne abilitato che ha subito un'evoluzione dello schema non additiva, come la ridenominazione o l'eliminazione di colonne. Vedere Mapping e streaming delle colonne.
Utilizzare viste materializzate
Le viste materializzate gestiscono automaticamente le modifiche upstream ricompilando i risultati quando cambiano i dati di origine. Se non è necessaria la latenza più bassa possibile e si vuole evitare di gestire la complessità del flusso, una vista materializzata può semplificare l'architettura. Le viste materializzate sono disponibili nelle pipeline dichiarative di Lakeflow Spark e in Databricks SQL. Vedere Viste materializzate.
Example
Si supponga, ad esempio, di avere una tabella user_events con date, user_emaile action colonne partizionate da date. Estraete dati dalla tabella user_events ed è necessario eliminarli a causa del GDPR.
skipChangeCommits consente di eliminare i dati in più partizioni (in questo esempio, filtrando in base user_emaila ). Usare la sintassi seguente:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Se si aggiorna un user_email con l'istruzione UPDATE, il file contenente il user_email in questione viene riscritto. Usare skipChangeCommits per ignorare i file di dati modificati.
Databricks consiglia di usare skipChangeCommits anziché ignoreDeletes a meno che non si sia certi che le eliminazioni siano sempre eliminazioni complete della partizione.
Usare foreachBatch per le scritture di tabelle idempotenti
Note
Databricks consiglia di configurare una scrittura di streaming separata per ogni sink da aggiornare anziché usare foreachBatch. Le operazioni di scrittura in più sink in foreachBatch riducono la parallelizzazione e aumentano la latenza complessiva perché le scritture in più tabelle vengono serializzate in foreachBatch.
Le tabelle Delta supportano le opzioni di DataFrameWriter seguenti per eseguire operazioni di scrittura in più tabelle all'interno di foreachBatch idempotente:
-
txnAppId: stringa univoca che è possibile passare a ogni scrittura di dataframe. Ad esempio, è possibile usare l'ID StreamingQuery cometxnAppId.txnAppIdpuò essere qualsiasi stringa univoca generata dall'utente e non deve essere correlata all'ID flusso. -
txnVersion: numero che aumenta in modo monotonico che funge da versione della transazione.
Delta Lake usa txnAppId e txnVersion per identificare e ignorare le scritture duplicate. Ad esempio, dopo che un errore interrompe una scrittura batch, è possibile rieseguire il batch con lo stesso txnAppId e txnVersion per identificare e ignorare correttamente i duplicati. Consulta Usare foreachBatch per scrivere su destinazioni dati arbitrarie.
Warning
Se si elimina il checkpoint di streaming e si riavvia la query con un nuovo checkpoint, è necessario specificare un elemento diverso txnAppId. I nuovi checkpoint iniziano con un ID batch di 0. Delta Lake usa l'ID batch e txnAppId come chiave univoca e ignora i batch con valori già visualizzati.
L'esempio di codice seguente illustra questo modello:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert dalle query di streaming con foreachBatch
È possibile usare merge e foreachBatch per scrivere upsert complessi da una query di streaming in una tabella Delta. Consulta Usare foreachBatch per scrivere su destinazioni dati arbitrarie.
Questo approccio ha molte applicazioni:
- Migliorare le prestazioni di scrittura con la modalità di output
update, mentre la modalità di outputcompleterichiede la riscrittura dell'intera tabella dei risultati per ogni microbatch. - Applicare continuamente un flusso di modifiche a una tabella Delta usando una query di merge per scrivere dati delle modifiche in
foreachBatch. Consulta Dati a cambiamento lento (SCD) e change data capture (CDC) con Delta Lake. - Gestire la deduplicazione durante l'elaborazione del flusso. Puoi usare una query di unione di tipo insert-only in
foreachBatchper scrivere continuamente dati in una tabella Delta con deduplicazione automatica. Vedere Deduplicazione dei dati durante la scrittura in tabelle Delta.
Note
Verificare che l'istruzione
mergeall'interno diforeachBatchsia idempotente. In caso contrario, i riavvii della query di streaming possono applicare l'operazione nello stesso batch di dati più volte. Vedere UsareforeachBatchper le scritture di tabelle idempotenti.Quando
mergeviene usato inforeachBatch, la metrica della frequenza dei dati di input potrebbe restituire un multiplo della frequenza effettiva generata dai dati nell'origine.mergelegge i dati di input più volte, moltiplicando le metriche. Per evitare la moltiplicazione delle metriche, memorizzare nella cache il dataframe batch primamergee quindi annullarlo dopomerge.Il tasso di dati in ingresso è disponibile tramite
StreamingQueryProgresse nel grafico del tasso di streaming del notebook. Vedi Monitoraggio delle query di structured streaming su Azure Databricks.
Ad esempio, è possibile usare MERGE istruzioni SQL all'interno foreachBatchdi :
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
È anche possibile usare le API Delta Lake per gli upsert di streaming:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Impostare la versione iniziale della tabella per elaborare le modifiche
Per impostazione predefinita, i flussi iniziano con la versione più recente della tabella Delta disponibile. Questo include un'istantanea completa della tabella in quel momento e tutte le modifiche future. Databricks consiglia di usare la versione della tabella iniziale predefinita per la maggior parte dei carichi di lavoro.
Facoltativamente, è possibile usare le opzioni seguenti per specificare il punto iniziale dell'origine di streaming Delta Lake senza elaborare l'intera tabella.
startingVersion: versione della tabella Delta da cui iniziare la lettura. Tutte le modifiche committate alla tabella a partire dalla versione specificata vengono lette dal flusso. Se la versione specificata non è disponibile, l'avvio del flusso non riesce.Per trovare le versioni di commit disponibili, eseguire
DESCRIBE HISTORYe controllare ilversion. Per restituire solo le modifiche più recenti, specificarelatest. Per informazioni sulle versioni delle tabelle Delta, vedere Usare la cronologia delle tabelle.startingTimestamp: timestamp da cui iniziare la lettura. Tutte le modifiche apportate alla tabella di cui è stato eseguito il commit o dopo il timestamp specificato vengono lette dal flusso. Se il timestamp specificato precede tutti i commit della tabella, la lettura di streaming inizia con il timestamp meno recente disponibile. Impostare una delle opzioni seguenti:- Una stringa di timestamp Ad esempio:
"2019-01-01T00:00:00.000Z". - Stringa di data. Ad esempio:
"2019-01-01".
- Una stringa di timestamp Ad esempio:
Non è possibile impostare sia startingVersion che startingTimestamp contemporaneamente. Queste impostazioni si applicano solo alle nuove query di streaming. Se una query di streaming è stata avviata e lo stato di avanzamento è stato registrato nel relativo checkpoint, queste impostazioni vengono ignorate.
Important
Anche se è possibile avviare l'origine di streaming da una versione o un timestamp specificato, lo schema dell'origine di streaming è sempre lo schema più recente della tabella Delta. È necessario assicurarsi che non vi sia alcuna modifica dello schema incompatibile alla tabella Delta dopo la versione o il timestamp specificati. In caso contrario, l'origine di streaming potrebbe restituire risultati non corretti durante la lettura dei dati con uno schema non corretto.
Example
Si supponga, ad esempio, di avere una tabella user_events. Se si desidera leggere le modifiche dalla versione 5, usare:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Se si desidera leggere le modifiche dal 2018-10-18, usare:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Elaborare uno snapshot iniziale senza eliminare i dati
Questa funzionalità è disponibile in Databricks Runtime 11.3 LTS e versioni successive.
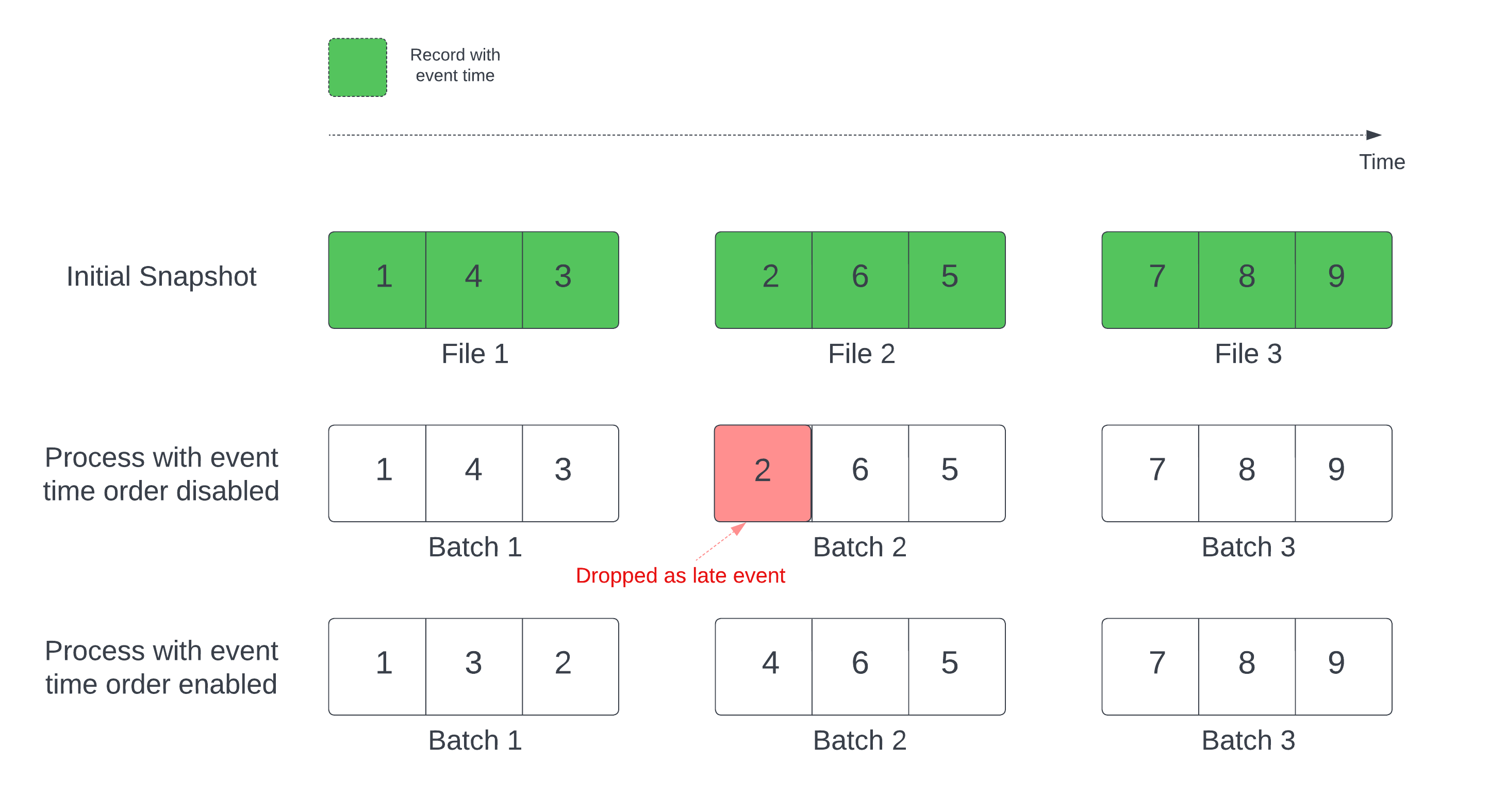
In una query di streaming stateful con un watermark definito, l'elaborazione dei file in base al tempo di modifica può elaborare i record in un ordine scorretto. In questo modo la filigrana contrassegna erroneamente i record come eventi tardivi e li rilascia. Ciò può verificarsi solo quando lo snapshot Delta iniziale viene elaborato nell'ordine predefinito.
Per i flussi con una tabella di origine Delta, la query elabora innanzitutto tutti i dati presenti nella tabella e crea una versione denominata snapshot iniziale. Per impostazione predefinita, i file di dati della tabella Delta vengono elaborati in base all'ultima modifica del file. Tuttavia, l'ora dell'ultima modifica non rappresenta necessariamente l'ordine di ora dell'evento del record.
Per evitare perdite di dati durante l'elaborazione iniziale dello snapshot, abilitare l'opzione withEventTimeOrder .
withEventTimeOrder divide l'intervallo di tempo dell'evento dei dati dello snapshot iniziale in raggruppamenti temporali. Ogni micro batch elabora un bucket filtrando i dati all'interno dell'intervallo di tempo. Le maxFilesPerTrigger opzioni e maxBytesPerTrigger sono ancora applicabili per controllare le dimensioni del micro batch, ma solo approssimativamente a causa dell'approccio di elaborazione.
Il diagramma seguente illustra questo processo:
Vincoli
- Non è possibile modificare
withEventTimeOrderse la query di flusso è stata avviata e lo snapshot iniziale sta elaborando attivamente. Per riavviare conwithEventTimeOrdermodificato, è necessario eliminare il checkpoint. - Se
withEventTimeOrderè abilitato, non è possibile effettuare il downgrade di un flusso a una versione di Databricks Runtime che non supporta questa funzionalità fino al completamento dell'elaborazione iniziale degli snapshot. Per effettuare il downgrade, attendere il completamento dello snapshot iniziale o eliminare il checkpoint e riavviare la query. - Questa funzionalità non è supportata negli scenari seguenti:
- La colonna tempo evento è una colonna generata e sono presenti trasformazioni non proiettive tra l'origine Delta e la marca temporale.
- Nella query di flusso c'è una filigrana che ha più di un'origine Delta.
Prestazioni
Se withEventTimeOrder è abilitato, le prestazioni iniziali di elaborazione degli snapshot potrebbero risultare più lente. Ogni micro batch analizza lo snapshot iniziale per filtrare i dati all'interno dell'intervallo di tempo dell'evento corrispondente. Per migliorare le prestazioni di filtro:
- Usare una colonna di origine Delta come riferimento temporale dell'evento per applicare il salto dei dati. Vedere Salto dati.
- Partizionare la tabella in base alla colonna di ora dell'evento.
Usare l'interfaccia utente di Spark per verificare il numero di file Delta analizzati per un micro batch specifico.
Example
Si supponga di avere una tabella user_events con una colonna event_time. La tua query di streaming è una di aggregazione. Se vuoi assicurarti che non vi siano perdite di dati durante l'elaborazione iniziale dello snapshot, puoi usare:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
È possibile impostare withEventTimeOrder con una configurazione spark nel cluster per applicarla a tutte le query di streaming: spark.databricks.delta.withEventTimeOrder.enabled true.
Limitare la frequenza di input per migliorare le prestazioni di elaborazione
Per impostazione predefinita, Structured Streaming elabora il maggior numero possibile di file in ogni micro batch. Per limitare la quantità di dati elaborati per batch e gestire l'utilizzo della memoria, stabilizzare la latenza o ridurre i costi di archiviazione cloud, usare le opzioni seguenti:
-
maxFilesPerTrigger: numero di nuovi file da considerare in ogni micro batch. Il valore predefinito è 1000. -
maxBytesPerTrigger: quantità di dati elaborati in ogni micro batch. Questa opzione imposta un valore "soft max", ovvero un batch elabora approssimativamente questa quantità di dati e potrebbe elaborare più del limite per far avanzare la query di streaming nei casi in cui l'unità di input più piccola è maggiore di questo limite. Questa impostazione non è impostata per impostazione predefinita.
Se si usano sia maxBytesPerTrigger che maxFilesPerTrigger, il micro-batch elabora i dati fino a quando non viene raggiunto il limite di maxFilesPerTrigger o di maxBytesPerTrigger.
Note
Per impostazione predefinita, se logRetentionDuration pulisce le transazioni nella tabella di origine e la query di streaming tenta di elaborare tali versioni, la query non riesce a evitare la perdita di dati. È possibile impostare l'opzione failOnDataLoss su false per ignorare i dati persi e continuare l'elaborazione. Vedere Configurare la conservazione dei dati per le query di spostamento cronologico.
Controllare i costi di archiviazione cloud
Le query di streaming hanno diverse modalità di trigger disponibili che consentono di bilanciare i costi e la latenza, tra cui processingTime, availableNowe realTime. Vedere Controllare i costi di archiviazione cloud.