Introduzione ai flussi di lavoro di Azure Databricks
I flussi di lavoro di Azure Databricks orchestrano l'elaborazione dei dati, l'apprendimento automatico e le pipeline di analisi nella piattaforma data intelligence di Databricks. I flussi di lavoro hanno servizi di orchestrazione completamente gestiti integrati con la piattaforma Databricks, inclusi i processi di Azure Databricks per eseguire codice non interattivo nell'area di lavoro di Azure Databricks e nelle tabelle Live Delta per creare pipeline ETL affidabili e gestibili.
Per altre informazioni sui vantaggi dell'orchestrazione dei flussi di lavoro con la piattaforma Databricks, vedere Flussi di lavoro di Databricks.
Esempio di flusso di lavoro di Azure Databricks
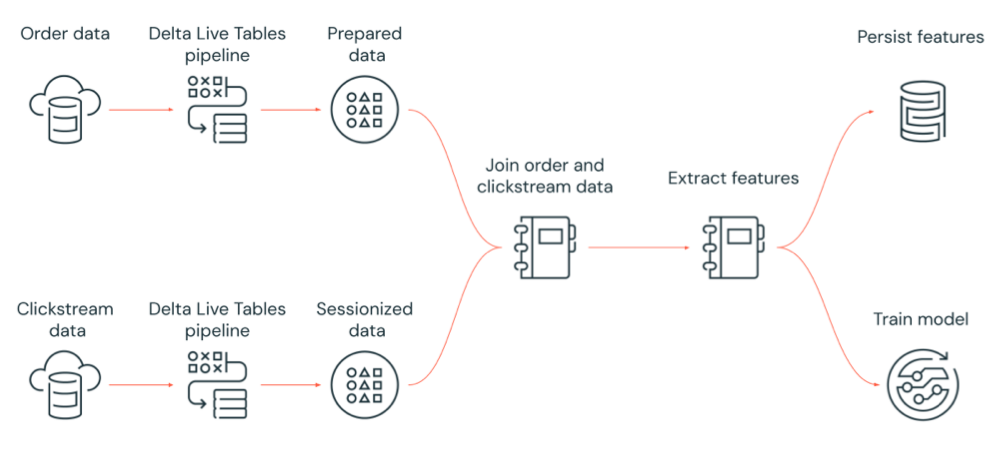
Il diagramma seguente illustra un flusso di lavoro orchestrato da un processo di Azure Databricks per:
- Eseguire una pipeline delta live tables che inserisce dati clickstream non elaborati dall'archiviazione cloud, pulisce e prepara i dati, esegue la sessione dei dati e salva in modo permanente il set di dati con sessione finale su Delta Lake.
- Eseguire una pipeline delta live tables che inserisce i dati in ordine dall'archiviazione cloud, pulisce e trasforma i dati per l'elaborazione e rende persistenti il set di dati finale su Delta Lake.
- Unire l'ordine e i dati clickstream con sessione per creare un nuovo set di dati per l'analisi.
- Estrarre le funzionalità dai dati preparati.
- Eseguire attività in parallelo per rendere persistenti le funzionalità ed eseguire il training di un modello di Machine Learning.
Che cos'è Processi di Azure Databricks?
Un processo di Azure Databricks è un modo per eseguire le applicazioni di elaborazione e analisi dei dati in un'area di lavoro di Azure Databricks. Il processo può essere costituito da una singola attività oppure può essere un flusso di lavoro multi-attività di grandi dimensioni con dipendenze complesse. Azure Databricks gestisce l'orchestrazione delle attività, la gestione del cluster, il monitoraggio e la segnalazione degli errori per tutti i processi. È possibile eseguire immediatamente i processi, periodicamente tramite un sistema di pianificazione facile da usare, ogni volta che arrivano nuovi file in una posizione esterna o continuamente per garantire che un'istanza del processo sia sempre in esecuzione. È anche possibile eseguire processi in modo interattivo nell'interfaccia utente del notebook.
È possibile creare ed eseguire un processo usando l'interfaccia utente processi, l'interfaccia della riga di comando di Databricks o richiamando l'API Processi. È possibile riparare ed eseguire di nuovo un processo non riuscito o annullato usando l'interfaccia utente o l'API. È possibile monitorare i risultati dell'esecuzione dei processi usando l'interfaccia utente, l'interfaccia della riga di comando, l'API e le notifiche (ad esempio, posta elettronica, destinazione webhook o notifiche slack).
Per informazioni sull'uso dell'interfaccia della riga di comando di Databricks, vedere Informazioni sull'interfaccia della riga di comando di Databricks. Per informazioni sull'uso dell'API Processi, vedere l'API Processi.
Le sezioni seguenti illustrano le funzionalità importanti dei processi di Azure Databricks.
Importante
- Un'area di lavoro è limitata a 1000 esecuzioni simultanee. Una risposta
429 Too Many Requestsviene restituita quando si richiede un'esecuzione che non può iniziare immediatamente. - Il numero di processi che un'area di lavoro può creare in un'ora è limitato a 10000 (include "esecuzioni di invio"). Questo limite influisce anche sui processi creati dall'API REST e dai flussi di lavoro del notebook.
Implementare l'elaborazione e l'analisi dei dati con attività di processo
È possibile implementare il flusso di lavoro di elaborazione e analisi dei dati usando le attività. Un processo è costituito da una o più attività. È possibile creare attività di processo che eseguono notebook, JARS, pipeline delta live tables o Python, Scala, Spark submit e Java applications. Le attività del processo possono anche orchestrare query, avvisi e dashboard di Databricks SQL per creare analisi e visualizzazioni oppure è possibile usare l'attività dbt per eseguire trasformazioni dbt nel flusso di lavoro. Sono supportate anche le applicazioni Spark Submit legacy.
È anche possibile aggiungere un'attività a un processo che esegue un processo diverso. Questa funzionalità consente di suddividere un processo di grandi dimensioni in più processi più piccoli o di creare moduli generalizzati che possono essere riutilizzati da più processi.
È possibile controllare l'ordine di esecuzione delle attività specificando le dipendenze tra le attività. È possibile configurare le attività da eseguire in sequenza o in parallelo.
Eseguire processi in modo interattivo, continuo o usando trigger di processo
È possibile eseguire i processi in modo interattivo dall'interfaccia utente dei processi, dall'API o dall'interfaccia della riga di comando oppure è possibile eseguire un processo continuo. È possibile creare una pianificazione per eseguire periodicamente il processo o eseguire il processo quando arrivano nuovi file in un percorso esterno, ad esempio Amazon S3, Archiviazione di Azure o Archiviazione Google Cloud.
Monitorare lo stato del processo con le notifiche
È possibile ricevere notifiche all'avvio, al completamento o all'esito negativo di un processo o di un'attività. È possibile inviare notifiche a uno o più indirizzi di posta elettronica o destinazioni di sistema (ad esempio, destinazioni webhook o Slack). Vedere Aggiungere notifiche di posta elettronica e di sistema per gli eventi del processo.
Eseguire i processi con le risorse di calcolo di Azure Databricks
I cluster Databricks e SQL Warehouse forniscono le risorse di calcolo per i processi. È possibile eseguire i processi con un cluster di processi, un cluster all-purpose o un'istanza di SQL Warehouse:
- Un cluster di processi è un cluster dedicato per il processo o le singole attività di processo. Il processo può usare un cluster di processi condiviso da tutte le attività oppure è possibile configurare un cluster per le singole attività quando si crea o si modifica un'attività. Un cluster di processi viene creato quando il processo o l'attività viene avviata e terminata al termine del processo o dell'attività.
- Un cluster all-purpose è un cluster condiviso avviato e terminato manualmente e può essere condiviso da più utenti e processi.
Per ottimizzare l'utilizzo delle risorse, Databricks consiglia di usare un cluster di processi per i processi. Per ridurre il tempo impiegato per l'avvio del cluster, prendere in considerazione l'uso di un cluster all-purpose. Vedere Usare il calcolo di Azure Databricks con i processi.
Si usa un'istanza di SQL Warehouse per eseguire attività SQL di Databricks, ad esempio query, dashboard o avvisi. È anche possibile usare un'istanza di SQL Warehouse per eseguire trasformazioni dbt con l'attività dbt.
Passaggi successivi
Per iniziare a usare i processi di Azure Databricks:
Creare il primo processo di Azure Databricks con l'avvio rapido.
Informazioni su come creare ed eseguire flussi di lavoro con l'interfaccia utente processi di Azure Databricks.
Informazioni su come eseguire un processo senza dover configurare le risorse di calcolo di Azure Databricks con flussi di lavoro serverless.
Informazioni sul monitoraggio delle esecuzioni dei processi nell'interfaccia utente di Processi di Azure Databricks.
Informazioni sulle opzioni di configurazione per i processi.
Altre informazioni sulla creazione, la gestione e la risoluzione dei problemi dei flussi di lavoro con i processi di Azure Databricks:
- Informazioni su come comunicare informazioni tra le attività in un processo di Azure Databricks con i valori delle attività.
- Informazioni su come passare il contesto relativo all'esecuzione del processo in attività con variabili di parametro dell'attività.
- Informazioni su come configurare le attività del processo per l'esecuzione in modo condizionale in base allo stato delle dipendenze dell'attività.
- Informazioni su come risolvere i problemi e correggere i processi non riusciti .
- Ricevere una notifica all'avvio, al completamento o all'esito negativo dell'esecuzione del processo con le notifiche di esecuzione del processo.
- Attivare i processi in base a una pianificazione personalizzata o eseguire un processo continuo.
- Informazioni su come eseguire il processo di Azure Databricks quando arrivano nuovi dati con trigger di arrivo dei file.
- Informazioni su come usare le risorse di calcolo di Databricks per eseguire i processi.
- Informazioni sugli aggiornamenti all'API Processi per supportare la creazione e la gestione dei flussi di lavoro con i processi di Azure Databricks.
- Usare le guide pratiche e le esercitazioni per altre informazioni sull'implementazione dei flussi di lavoro di dati con Processi di Azure Databricks.
Che cos'è Delta Live Tables?
Nota
Le tabelle live delta richiedono il piano Premium. Per altre informazioni, contattare il team dell'account Databricks.
Delta Live Tables è un framework che semplifica l'elaborazione dei dati ETL e di streaming. Le tabelle live delta offrono un inserimento efficiente dei dati con supporto predefinito per l'utilità di caricamento automatico, le interfacce SQL e Python che supportano l'implementazione dichiarativa delle trasformazioni dei dati e il supporto per la scrittura di dati trasformati in Delta Lake. È possibile definire le trasformazioni da eseguire sui dati e Le tabelle live Delta gestiscono l'orchestrazione delle attività, la gestione del cluster, il monitoraggio, la qualità dei dati e la gestione degli errori.
Per iniziare, vedere Che cos'è Delta Live Tables?.
Processi e tabelle live delta di Azure Databricks
I processi di Azure Databricks e le tabelle live Delta offrono un framework completo per la creazione e la distribuzione di flussi di lavoro di analisi e elaborazione dei dati end-to-end.
Usare tabelle live Delta per tutti gli inserimenti e la trasformazione dei dati. Usare i processi di Azure Databricks per orchestrare i carichi di lavoro composti da una singola attività o da più attività di elaborazione e analisi dei dati nella piattaforma Databricks, tra cui l'inserimento e la trasformazione di tabelle live Delta.
Come sistema di orchestrazione del flusso di lavoro, i processi di Azure Databricks supportano anche:
- L'esecuzione di processi su base attivata, ad esempio l'esecuzione di un flusso di lavoro in base a una pianificazione.
- Analisi dei dati tramite query SQL, Machine Learning e analisi dei dati con notebook, script o librerie esterne e così via.
- Esecuzione di un processo composto da una singola attività, ad esempio l'esecuzione di un processo Apache Spark incluso in un file JAR.
Orchestrazione del flusso di lavoro con Apache AirFlow
Anche se Databricks consiglia di usare Processi di Azure Databricks per orchestrare i flussi di lavoro dei dati, è anche possibile usare Apache Airflow per gestire e pianificare i flussi di lavoro dei dati. Con Airflow si definisce il flusso di lavoro in un file Python e Airflow gestisce la pianificazione e l'esecuzione del flusso di lavoro. Vedere Orchestrare i processi di Azure Databricks con Apache Airflow.
Orchestrazione del flusso di lavoro con Azure Data Factory
Azure Data Factory (ADF) è un servizio di integrazione dei dati cloud che consente di comporre servizi di archiviazione, spostamento ed elaborazione dei dati in pipeline di dati automatizzate. È possibile usare Azure Data Factory per orchestrare un processo di Azure Databricks come parte di una pipeline di Azure Data Factory.
Per informazioni su come eseguire un processo usando l'attività Web di Azure Data Factory, tra cui come eseguire l'autenticazione ad Azure Databricks da Azure Databricks da Azure Databricks, vedere Sfruttare l'orchestrazione dei processi di Azure Databricks da Azure Data Factory.
Azure Data Factory offre anche il supporto predefinito per eseguire notebook di Databricks, script Python o codice in pacchetto in jaR in una pipeline di Azure Data Factory.
Per informazioni su come eseguire un notebook di Databricks in una pipeline di Azure Data Factory, vedere Eseguire un notebook di Databricks con l'attività notebook di Databricks in Azure Data Factory, seguita da Trasformare i dati eseguendo un notebook di Databricks.
Per informazioni su come eseguire uno script Python in una pipeline di Azure Data Factory, vedere Trasformare i dati eseguendo un'attività Python in Azure Databricks.
Per informazioni su come eseguire il codice incluso in un file JAR in una pipeline di Azure Data Factory, vedere Trasformare i dati eseguendo un'attività JAR in Azure Databricks.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per