Aumento di un modello linguistico di grandi dimensioni con generazione aumentata e ottimizzazione del recupero
Gli articoli di questa serie illustrano i modelli di recupero delle conoscenze usati dai moduli APM per generare le risposte. Per impostazione predefinita, un modello LLM (Large Language Model) ha accesso solo ai dati di training. Tuttavia, è possibile aumentare il modello per includere dati in tempo reale o dati privati. Questo articolo illustra uno dei due meccanismi per l'aumento di un modello.
Il primo meccanismo è Retrieval-Augmented Generation (RAG), una forma di pre-elaborazione che combina la ricerca semantica con il priming contestuale (descritto in un altro articolo).
Il secondo meccanismo è l'ottimizzazione, che fa riferimento al processo di ulteriore training del modello su un set di dati specifico dopo il training iniziale, ampio, con l'obiettivo di adattarlo per migliorare le attività o comprendere i concetti correlati a tale set di dati. Questo processo consente al modello di specializzare o migliorare la precisione e l'efficienza nella gestione di determinati tipi di input o domini.
Le sezioni seguenti descrivono questi due meccanismi in modo più dettagliato.
Informazioni su RAG
Rag viene spesso usato per abilitare lo scenario "chat over my data", in cui le aziende che dispongono di un ampio insieme di contenuti testuali (documenti interni, documentazione e così via) e vogliono usare questo corpus come base per le risposte alle richieste degli utenti.
A livello generale, si crea una voce di database per ogni documento (o parte di un documento denominato "blocco"). Il blocco viene indicizzato sull'incorporamento, un vettore (matrice) di numeri che rappresentano facet del documento. Quando un utente invia una query, si esegue una ricerca nel database per documenti simili, quindi inviare la query e i documenti all'LLM per comporre una risposta.
Nota
Il termine Retrieval-Augmented Generation (RAG) accomodantemente. Il processo di implementazione di un sistema di chat basato su RAG descritto in questo articolo può essere applicato indipendentemente dal desiderio di usare dati esterni da usare in una capacità di supporto (RAG) o da usare come centro della risposta (RCG). Questa distinzione sfumata non viene affrontata nella maggior parte delle letture relative alla rag.
Creazione di un indice di documenti vettorializzati
Il primo passaggio per creare un sistema di chat basato su RAG consiste nel creare un archivio dati vettoriale contenente l'incorporamento vettoriale del documento (o una parte del documento). Si consideri il diagramma seguente che descrive i passaggi di base per la creazione di un indice vettorializzato di documenti.

Questo diagramma rappresenta una pipeline di dati, responsabile dell'inserimento, dell'elaborazione e della gestione dei dati usati dal sistema. Ciò include la pre-elaborazione dei dati da archiviare nel database vettoriale e garantire che i dati inseriti nel file LLM siano nel formato corretto.
L'intero processo è basato sulla nozione di incorporamento, ovvero una rappresentazione numerica dei dati (in genere parole, frasi, frasi o anche interi documenti) che acquisisce le proprietà semantiche dell'input in modo che possa essere elaborato dai modelli di Machine Learning.
Per creare un incorporamento, inviare il blocco di contenuto (frasi, paragrafi o interi documenti) all'API di incorporamento Di Azure OpenAI. Ciò che viene restituito dall'API di incorporamento è un vettore. Ogni valore nel vettore rappresenta alcune caratteristiche (dimensione) del contenuto. Le dimensioni possono includere argomenti, significato semantico, sintassi e grammatica, utilizzo di parole e frasi, relazioni contestuali, stile e tono e così via. Insieme, tutti i valori del vettore rappresentano lo spazio dimensionale del contenuto. In altre parole, se si può pensare a una rappresentazione 3D di un vettore con tre valori, un determinato vettore vive in una determinata area del piano x, y, z. Cosa accade se si 1000 (o più) valori? Anche se non è possibile che gli esseri umani disegnare un grafico a 1000 dimensioni su un foglio di carta per renderlo più comprensibile, i computer non hanno problemi a capire quel grado di spazio dimensionale.
Il passaggio successivo del diagramma illustra l'archiviazione del vettore insieme al contenuto stesso (o un puntatore alla posizione del contenuto) e altri metadati in un database vettoriale. Un database vettoriale è simile a qualsiasi tipo di database, con due differenze:
- I database vettoriali usano un vettore come indice per cercare i dati.
- I database vettoriali implementano un algoritmo denominato ricerca simile al coseno, noto anche come vicino più vicino, che usa vettori che corrispondono più strettamente ai criteri di ricerca.
Con il corpus di documenti archiviati in un database vettoriale, gli sviluppatori possono compilare un componente retriever che recupera i documenti che corrispondono alla query dell'utente dal database per fornire all'LLM le informazioni necessarie per rispondere alla query dell'utente.
Risposta alle query con i documenti
Un sistema RAG usa prima la ricerca semantica per trovare articoli che potrebbero essere utili per l'LLM durante la composizione di una risposta. Il passaggio successivo consiste nell'inviare gli articoli corrispondenti insieme al prompt originale dell'utente all'LLM per comporre una risposta.
Si consideri il diagramma seguente come una semplice implementazione RAG (talvolta definita "RAG ingenua").
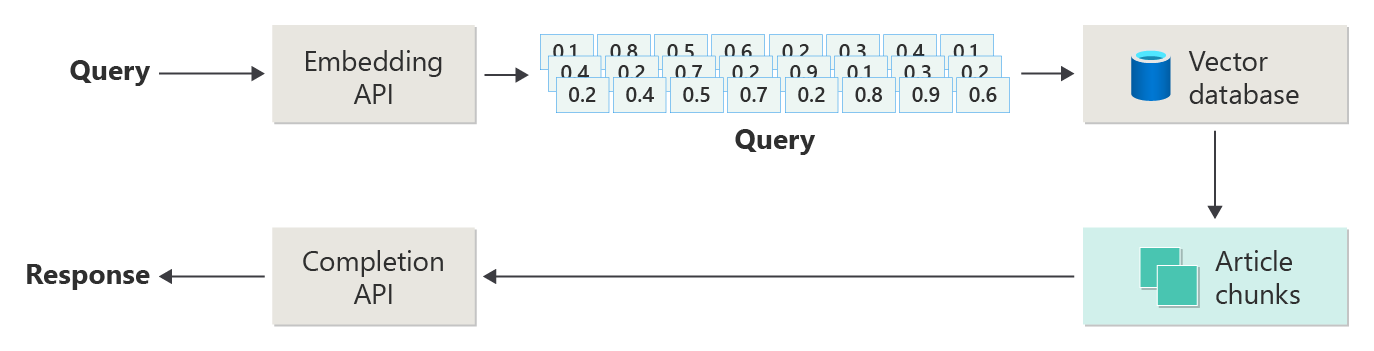
Nel diagramma un utente invia una query. Il primo passaggio consiste nel creare un'incorporamento per la richiesta dell'utente di recuperare un vettore. Il passaggio successivo consiste nel cercare nel database vettoriale i documenti (o parti di documenti) corrispondenti a una corrispondenza "vicina più vicina".
La somiglianza del coseno è una misura usata per determinare il modo in cui due vettori sono simili, essenzialmente valutando il coseno dell'angolo tra di essi. Una somiglianza coseno vicina a 1 indica un alto grado di somiglianza (angolo piccolo), mentre una somiglianza vicina a -1 indica la differenza (angolo che si avvicina a 180 gradi). Questa metrica è fondamentale per attività come la somiglianza dei documenti, in cui l'obiettivo è trovare documenti con contenuto o significato simili.
Gli algoritmi "Vicino più vicino" funzionano trovando i vettori più vicini (vicini) a un determinato punto nello spazio vettoriale. Nell'algoritmo k-nearest neighbors (KNN) 'k' fa riferimento al numero di vicini più vicini da considerare. Questo approccio viene ampiamente usato nella classificazione e nella regressione, in cui l'algoritmo stima l'etichetta di un nuovo punto dati in base all'etichetta di maggioranza dei vicini più vicini "k" nel set di training. La somiglianza knn e coseno vengono spesso usate insieme in sistemi come motori di raccomandazione, dove l'obiettivo è trovare elementi più simili alle preferenze di un utente, rappresentati come vettori nello spazio di incorporamento.
Si ottengono i risultati migliori da tale ricerca e si inviano i contenuti corrispondenti insieme alla richiesta dell'utente di generare una risposta che (speriamo) sia informata dal contenuto corrispondente.
Sfide e considerazioni
L'implementazione di un sistema RAG presenta una serie di sfide. La privacy dei dati è fondamentale, in quanto il sistema deve gestire i dati degli utenti in modo responsabile, soprattutto quando si recuperano ed elaborano informazioni da origini esterne. I requisiti di calcolo possono anche essere significativi, poiché sia i processi di recupero che i processi generativi sono a elevato utilizzo di risorse. Garantire l'accuratezza e la pertinenza delle risposte durante la gestione delle distorsioni presenti nei dati o nel modello è un'altra considerazione critica. Gli sviluppatori devono affrontare queste sfide con attenzione per creare sistemi RAG efficienti, etici e preziosi.
L'articolo successivo di questa serie, Building advanced Retrieval-Augmented Generation systems (Compilazione di sistemi avanzati di generazione aumentata) fornisce maggiori dettagli sulla creazione di pipeline di dati e inferenza per abilitare un sistema RAG pronto per la produzione.
Se si vuole iniziare subito a sperimentare la creazione di una soluzione di intelligenza artificiale generativa, è consigliabile esaminare Introduzione alla chat usando un esempio di dati personalizzato per Python. Sono disponibili versioni dell'esercitazione anche in .NET, Java e JavaScript.
Ottimizzazione di un modello
L'ottimizzazione, nel contesto di un LLM, si riferisce al processo di regolazione dei parametri del modello in un set di dati specifico del dominio dopo il training iniziale su un set di dati di grandi dimensioni e diversificato.
I moduli LLM vengono sottoposti a training (con training preliminare) su un set di dati ampio, afferrando la struttura del linguaggio, il contesto e un'ampia gamma di conoscenze. Questa fase prevede l'apprendimento di modelli linguistici generali. L'ottimizzazione consente di aggiungere altri training al modello con training preliminare in base a un set di dati più piccolo e specifico. Questa fase di training secondaria mira ad adattare il modello per ottenere prestazioni migliori in determinate attività o comprendere domini specifici, migliorandone l'accuratezza e la pertinenza per tali applicazioni specializzate. Durante l'ottimizzazione, i pesi del modello vengono modificati per prevedere meglio o comprendere le sfumature di questo set di dati più piccolo.
Alcune considerazioni:
- Specializzazione: l'ottimizzazione adatta il modello a attività specifiche, ad esempio l'analisi dei documenti legali, l'interpretazione del testo medico o le interazioni con il servizio clienti. In questo modo il modello risulta più efficace in tali aree.
- Efficienza: è più efficiente ottimizzare un modello con training preliminare per un'attività specifica piuttosto che eseguire il training di un modello da zero, perché l'ottimizzazione richiede meno dati e risorse di calcolo.
- Adattabilità: l'ottimizzazione consente l'adattamento a nuove attività o domini che non fanno parte dei dati di training originali, rendendo gli strumenti versatili per le macchine virtuali per varie applicazioni.
- Prestazioni migliorate: per le attività notevolmente diverse dai dati su cui è stato originariamente eseguito il training, l'ottimizzazione può portare a prestazioni migliori, in quanto regola il modello per comprendere il linguaggio, lo stile o la terminologia specifici usati nel nuovo dominio.
- Personalizzazione: in alcune applicazioni l'ottimizzazione consente di personalizzare le risposte o le stime del modello in base alle esigenze o alle preferenze specifiche di un utente o di un'organizzazione. Tuttavia, l'ottimizzazione presenta anche alcuni svantaggi e limitazioni. Comprendere questi elementi può aiutare a decidere quando scegliere l'ottimizzazione e le alternative, ad esempio la generazione aumentata di recupero( RAG).
- Requisito dei dati: l'ottimizzazione richiede un set di dati sufficientemente grande e di alta qualità specifico per l'attività o il dominio di destinazione. La raccolta e la cura di questo set di dati possono essere complesse e a elevato utilizzo di risorse.
- Rischio di overfitting: esiste un rischio di overfitting, soprattutto con un set di dati di piccole dimensioni. L'overfitting rende il modello ottimale sui dati di training, ma scarsamente sui dati nuovi e non visibili, riducendone la generalizzabilità.
- Costi e risorse: sebbene sia meno intensivo delle risorse rispetto al training da zero, l'ottimizzazione richiede comunque risorse di calcolo, soprattutto per modelli e set di dati di grandi dimensioni, che potrebbero essere proibitivi per alcuni utenti o progetti.
- Manutenzione e aggiornamento: i modelli ottimizzati potrebbero richiedere aggiornamenti regolari per rimanere efficaci man mano che le informazioni specifiche del dominio cambiano nel tempo. Questa manutenzione continua richiede risorse e dati aggiuntivi.
- Deriva del modello: poiché il modello è ottimizzato per attività specifiche, potrebbe perdere parte della comprensione e della versatilità del linguaggio generale, causando un fenomeno noto come deriva del modello.
La personalizzazione di un modello con l'ottimizzazione spiega come ottimizzare un modello. A livello generale, è possibile fornire un set di dati JSON di potenziali domande e risposte preferite. La documentazione suggerisce che esistono miglioramenti evidenti fornendo da 50 a 100 coppie di domande/risposte, ma il numero corretto varia notevolmente nel caso d'uso.
Ottimizzazione e generazione aumentata del recupero
In superficie, potrebbe sembrare che ci sia un po ' di sovrapposizione tra l'ottimizzazione e la generazione aumentata di recupero. La scelta tra l'ottimizzazione e la generazione aumentata del recupero dipende dai requisiti specifici dell'attività, incluse le aspettative sulle prestazioni, la disponibilità delle risorse e la necessità di specificità del dominio rispetto alla generalizzabilità.
Quando preferire l'ottimizzazione oltre alla generazione aumentata di recupero:
- Prestazioni specifiche dell'attività: l'ottimizzazione è preferibile quando le prestazioni elevate in un'attività specifica sono fondamentali e esistono dati sufficienti specifici del dominio per eseguire il training efficace del modello senza rischi significativi di overfitting.
- Controllo sui dati : se si dispone di dati proprietari o altamente specializzati che differiscono significativamente dai dati su cui è stato eseguito il training del modello di base, l'ottimizzazione consente di incorporare questa conoscenza univoca nel modello.
- Necessità limitata di aggiornamenti in tempo reale: se l'attività non richiede che il modello venga costantemente aggiornato con le informazioni più recenti, l'ottimizzazione può essere più efficiente perché i modelli RAG in genere devono accedere a database esterni aggiornati o a Internet per eseguire il pull dei dati recenti.
Quando preferire la generazione aumentata di recupero rispetto all'ottimizzazione:
- Contenuto dinamico o in evoluzione: la funzionalità RAG è più adatta alle attività in cui le informazioni più aggiornate sono fondamentali. Poiché i modelli RAG possono estrarre dati da origini esterne in tempo reale, sono più adatti per applicazioni come la generazione di notizie o la risposta a domande sugli eventi recenti.
- Generalizzazione rispetto alla specializzazione : se l'obiettivo è mantenere prestazioni elevate in un'ampia gamma di argomenti anziché eccellere in un dominio ristretto, rag potrebbe essere preferibile. Usa knowledge base esterne, consentendo di generare risposte in domini diversi senza il rischio di overfitting a un set di dati specifico.
- Vincoli di risorse: per le organizzazioni con risorse limitate per la raccolta dei dati e il training del modello, l'uso di un approccio RAG potrebbe offrire un'alternativa conveniente all'ottimizzazione, soprattutto se il modello di base esegue già abbastanza bene le attività desiderate.
Considerazioni finali che potrebbero influenzare le decisioni di progettazione dell'applicazione
Ecco un breve elenco di aspetti da considerare e altre considerazioni di questo articolo che influiscono sulle decisioni di progettazione delle applicazioni:
- Scegliere tra l'ottimizzazione e la generazione aumentata del recupero in base alle esigenze specifiche dell'applicazione. L'ottimizzazione potrebbe offrire prestazioni migliori per le attività specializzate, mentre RAG potrebbe offrire flessibilità e contenuto aggiornato per le applicazioni dinamiche.