Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come distribuire un'applicazione Red Hat JBoss Enterprise Application Platform (EAP) in un cluster Azure Red Hat OpenShift. L'esempio è un'applicazione Java supportata da un database SQL. L'app viene distribuita usando grafici Helm JBoss EAP.
In questa guida si apprenderà come:
- Preparare un'applicazione JBoss EAP per OpenShift.
- Creare una singola istanza del database SQL di Azure.
- Poiché l'identità del carico di lavoro di Azure non è ancora supportata da Azure OpenShift, questo articolo usa ancora nome utente e password per l'autenticazione del database anziché usare connessioni di database senza password.
- Distribuire l'applicazione in un cluster Azure Red Hat OpenShift usando grafici Helm JBoss e OpenShift Web Console
L'applicazione di esempio è un'applicazione con stato che archivia le informazioni in una sessione HTTP. Usa le funzionalità di clustering JBoss EAP e usa le tecnologie Jakarta EE e MicroProfile seguenti:
- Jakarta Server Faces - una tecnologia per lo sviluppo di interfacce web.
- Jakarta Enterprise Beans
- Persistenza di Jakarta
- Integrità microProfile
Questo articolo è una guida dettagliata per l'esecuzione di app JBoss EAP in un cluster Azure Red Hat OpenShift. Per una soluzione più automatizzata che accelera il percorso verso il cluster Azure Red Hat OpenShift, vedere Avvio rapido: Distribuire JBoss EAP in Azure Red Hat OpenShift usando il portale di Azure.
Se si è interessati a fornire commenti e suggerimenti o lavorare a stretto contatto con il team di progettazione che sviluppa JBoss EAP nelle soluzioni di Azure, compilare questo breve sondaggio sulla migrazione di JBoss EAP e includere le informazioni di contatto. Il team di responsabili del programma, architetti e ingegneri si metterà immediatamente in contatto con l'utente per avviare una stretta collaborazione.
Importante
Questo articolo distribuisce un'applicazione usando grafici Helm JBoss EAP. Al momento della stesura di questo articolo, questa funzionalità è ancora disponibile come Technology Preview. Prima di scegliere di distribuire applicazioni con grafici Helm JBoss EAP in ambienti di produzione, assicurarsi che questa funzionalità sia una funzionalità supportata per la versione del prodotto JBoss EAP/XP.
Importante
Anche se Red Hat e Microsoft Azure operano congiuntamente e supportano Azure Red Hat OpenShift per offrire un'esperienza di supporto integrata, il software eseguito su Azure Red Hat OpenShift, incluso quello descritto in questo articolo, è soggetto alle proprie condizioni di supporto e licenza. Per informazioni dettagliate sul supporto di Azure Red Hat OpenShift, vedere Ciclo di vita del supporto per Azure Red Hat OpenShift 4. Per informazioni dettagliate sul supporto del software descritto in questo articolo, vedere le pagine principali per tale software, come indicato nell'articolo.
Prerequisiti
Nota
Azure Red Hat OpenShift richiede almeno 40 core per creare ed eseguire un cluster OpenShift. La quota di risorse di Azure predefinita per una nuova sottoscrizione di Azure non soddisfa questo requisito. Per richiedere un aumento del limite di risorse, vedere Quota standard: aumentare i limiti per serie di macchine virtuali. La sottoscrizione di valutazione gratuita non è idonea per un aumento della quota, eseguire l'aggiornamento a una sottoscrizione con pagamento in base al consumoYou-Go prima di richiedere un aumento della quota.
Preparare un computer locale con un sistema operativo simile a Unix supportato dai vari prodotti installati, ad esempio Ubuntu, macOS o sottosistema Windows per Linux.
Installare un'implementazione di Java edizione Standard (SE). I passaggi di sviluppo locali in questo articolo sono stati testati con Java Development Kit (JDK) 17 dalla build Microsoft di OpenJDK.
Installare Maven 3.8.6 o versione successiva.
Installare l'interfaccia della riga di comando di Azure 2.40 o versione successiva.
Clonare il codice per questa applicazione demo (todo-list) nel sistema locale. L'applicazione demo è disponibile in GitHub.
Seguire le istruzioni in Creare un cluster Azure Red Hat OpenShift 4.
Anche se il passaggio "Ottenere un segreto pull di Red Hat" è etichettato come facoltativo, è necessario per questo articolo. Il segreto pull consente al cluster Azure Red Hat OpenShift di trovare le immagini dell'applicazione JBoss EAP.
Se si prevede di eseguire applicazioni a elevato utilizzo di memoria nel cluster, specificare le dimensioni della macchina virtuale appropriate per i nodi di lavoro usando il
--worker-vm-sizeparametro . Per altre informazioni, vedi:Connettersi al cluster seguendo la procedura descritta in Connettersi a un cluster Azure Red Hat OpenShift 4.
- Seguire la procedura descritta in "Installare l'interfaccia della riga di comando di OpenShift"
- Connettersi a un cluster Azure Red Hat OpenShift usando l'interfaccia della riga di comando di OpenShift con l'utente
kubeadmin
Eseguire il comando seguente per creare il progetto OpenShift per questa applicazione demo:
oc new-project eap-demoEseguire il comando seguente per aggiungere il ruolo di visualizzazione all'account del servizio predefinito. Questo ruolo è necessario in modo che l'applicazione possa individuare altri pod e configurare un cluster con essi:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Preparare l'applicazione
Clonare l'applicazione di esempio usando il comando seguente:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Hai clonato l'applicazione demo Todo-list e la tua repository locale è sul ramo principale. L'applicazione demo è una semplice app Java che crea, legge, aggiorna ed elimina i record in Azure SQL. È possibile distribuire questa applicazione così come si trova in un server JBoss EAP installato nel computer locale. È sufficiente configurare il server con il driver di database e l'origine dati necessari. È anche necessario un server di database accessibile dall'ambiente locale.
Tuttavia, quando si usa OpenShift come destinazione, è possibile ridurre le funzionalità del server JBoss EAP. Ad esempio, è possibile ridurre l'esposizione alla sicurezza del server di cui è stato effettuato il provisioning e ridurre il footprint complessivo. È anche possibile includere alcune specifiche di MicroProfile per rendere l'applicazione più adatta per l'esecuzione in un ambiente OpenShift. Quando si usa JBoss EAP, un modo per eseguire questa attività consiste nel creare pacchetti dell'applicazione e del server in una singola unità di distribuzione nota come JAR di avvio. A questo scopo, aggiungere le modifiche necessarie all'applicazione demo.
Accedi al repository locale della tua applicazione demo e cambia il branch in bootable-jar:
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Verrà ora esaminata rapidamente le modifiche apportate in questo ramo:
- È stato aggiunto il plug-in per effettuare il
wildfly-jar-mavenprovisioning del server e dell'applicazione in un singolo file JAR eseguibile. L'unità di distribuzione OpenShift è il server con l'applicazione. - Nel plug-in Maven è stato specificato un set di livelli galleon. Questa configurazione consente di ridurre le funzionalità del server solo a ciò di cui abbiamo bisogno. Per la documentazione completa su Galleon, vedere la documentazione di WildFly.
- L'applicazione usa Jakarta Faces con richieste Ajax, il che significa che sono presenti informazioni archiviate nella sessione HTTP. Se un pod viene rimosso, non si vogliono perdere tali informazioni. È possibile salvare queste informazioni sul client e inviarle nuovamente a ogni richiesta. Tuttavia, esistono casi in cui si potrebbe decidere di non distribuire determinate informazioni ai client. Per questa demo si è scelto di replicare la sessione in tutte le repliche pod. A tale scopo, è stato aggiunto
<distributable />al web.xml. Ciò, insieme alle funzionalità di clustering del server, rende la sessione HTTP distribuibile in tutti i pod. - Sono stati aggiunti due controlli di integrità microProfile che consentono di identificare quando l'applicazione è attiva e pronta per ricevere le richieste.
Eseguire l'applicazione in locale
Prima di distribuire l'applicazione in OpenShift, verrà eseguita in locale per verificare il funzionamento. I passaggi seguenti presuppongono che Azure SQL sia in esecuzione e disponibile nell'ambiente locale.
Per creare il database, seguire la procedura descritta in Avvio rapido: Creare un database SQL di Azure database singolo, ma usare le sostituzioni seguenti.
- Per Gruppo di risorse usare il gruppo di risorse creato in precedenza.
- Per Nome database usare
todos_db. - Per l'account di accesso amministratore del server usare
azureuser. - Per Password usare
Passw0rd!. - Nella sezione Regole del firewall attivare o disattivare Consenti alle risorse e ai servizi di Azure di accedere a questo server su Sì.
Tutte le altre impostazioni possono essere usate in modo sicuro dall'articolo collegato.
Nella pagina Impostazioni aggiuntive non è necessario scegliere l'opzione per prepopopolare il database con dati di esempio, ma non c'è alcun danno in questo caso.
Dopo aver creato il database, ottenere il valore per il nome del server dalla pagina di panoramica. Passare il puntatore del mouse sul valore del campo Nome server e selezionare l'icona di copia visualizzata accanto al valore. Salvare questo valore per usarlo in un secondo momento (si imposta una variabile denominata MSSQLSERVER_HOST su questo valore).
Nota
Per ridurre i costi monetari, la guida introduttiva indirizza il lettore a selezionare il livello di calcolo serverless. Questo livello viene ridimensionato a zero quando non è presente alcuna attività. In questo caso, il database non risponde immediatamente. Se in qualsiasi momento durante l'esecuzione dei passaggi descritti in questo articolo vengono rilevati problemi relativi al database, è consigliabile disabilitare la sospensione automatica. Per informazioni su come, cercare Sospensione automatica in database SQL di Azure serverless. Al momento in cui scriviamo, il seguente comando Azure CLI disattiva la funzione di sospensione automatica per il database configurato in questo articolo: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Seguire i passaggi successivi per compilare ed eseguire l'applicazione in locale.
Compilare il file JAR di avvio. Poiché si usa con il
eap-datasources-galleon-packdatabase MS SQL Server, è necessario specificare la versione del driver di database che si vuole usare con questa variabile di ambiente specifica. Per altre informazioni sueap-datasources-galleon-packe MS SQL Server, vedere la documentazione di Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageAvviare il file JAR di avvio usando i comandi seguenti.
È necessario assicurarsi che il database SQL di Azure consenta il traffico di rete dall'host in cui è in esecuzione il server. Poiché è stato selezionato Aggiungi indirizzo IP client corrente durante l'esecuzione della procedura descritta in Avvio rapido: Creare un database singolo database SQL di Azure, se l'host in cui è in esecuzione il server è lo stesso host da cui il browser si connette al portale di Azure, il traffico di rete deve essere consentito. Se l'host in cui è in esecuzione il server è un altro host, è necessario fare riferimento a Usare il portale di Azure per gestire le regole del firewall IP a livello di server.
Quando si avvia l'applicazione, è necessario passare le variabili di ambiente necessarie per configurare l'origine dati:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runNota
Microsoft consiglia di usare il flusso di autenticazione più sicuro disponibile. Il flusso di autenticazione descritto in questa procedura, ad esempio per database, cache, messaggistica o servizi di intelligenza artificiale, richiede un livello di attendibilità molto elevato nell'applicazione e comporta rischi non presenti in altri flussi. Usare questo flusso solo quando le opzioni più sicure, ad esempio le identità gestite per le connessioni senza password o senza chiave, non sono valide. Per le operazioni del computer locale, preferire le identità utente per le connessioni senza password o senza chiave.
Per altre informazioni sul runtime sottostante usato da questa demo, la documentazione relativa all'integrazione delle origini dati include un elenco completo delle variabili di ambiente disponibili. Per informazioni dettagliate sul concetto di Feature Pack, vedere la documentazione di WildFly.
Se viene visualizzato un errore con testo simile all'esempio seguente:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Questo messaggio indica che i passaggi per assicurarsi che il traffico di rete non sia consentito. Verificare che l'indirizzo IP del messaggio di errore sia incluso nelle regole del firewall.
Se si riceve un messaggio con testo simile all'esempio seguente:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Questo messaggio indica che i dati di esempio sono già presenti nel database. È possibile ignorare questo messaggio.
(Facoltativo) Per verificare le funzionalità di clustering, è anche possibile avviare più istanze della stessa applicazione passando all'argomento Bootable JAR
jboss.node.namee, per evitare conflitti con i numeri di porta, spostare i numeri di porta usandojboss.socket.binding.port-offset. Ad esempio, per avviare una seconda istanza che rappresenta un nuovo pod in OpenShift, è possibile eseguire il comando seguente in una nuova finestra del terminale:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Nota
Microsoft consiglia di usare il flusso di autenticazione più sicuro disponibile. Il flusso di autenticazione descritto in questa procedura, ad esempio per database, cache, messaggistica o servizi di intelligenza artificiale, richiede un livello di attendibilità molto elevato nell'applicazione e comporta rischi non presenti in altri flussi. Usare questo flusso solo quando le opzioni più sicure, ad esempio le identità gestite per le connessioni senza password o senza chiave, non sono valide. Per le operazioni del computer locale, preferire le identità utente per le connessioni senza password o senza chiave.
Se il cluster funziona, è possibile visualizzare nel log della console del server una traccia simile alla seguente:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbNota
Per impostazione predefinita, il file JAR di avvio configura il sottosistema JGroups per l'uso del protocollo UDP e invia messaggi per individuare altri membri del cluster all'indirizzo multicast 230.0.0.4. Per verificare correttamente le funzionalità di clustering nel computer locale, il sistema operativo deve essere in grado di inviare e ricevere datagrammi multicast e di instradarli all'indirizzo IP 230.0.0.4 tramite l'interfaccia Ethernet. Se vengono visualizzati avvisi relativi al cluster nei log del server, controllare la configurazione di rete e verificare che supporti il multicast in tale indirizzo.
Aprire http://localhost:8080/ nel browser per visitare la home page dell'applicazione. Se sono state create più istanze, è possibile accedervi spostando il numero di porta, ad esempio http://localhost:9080/. L'applicazione dovrebbe essere simile all'immagine seguente:
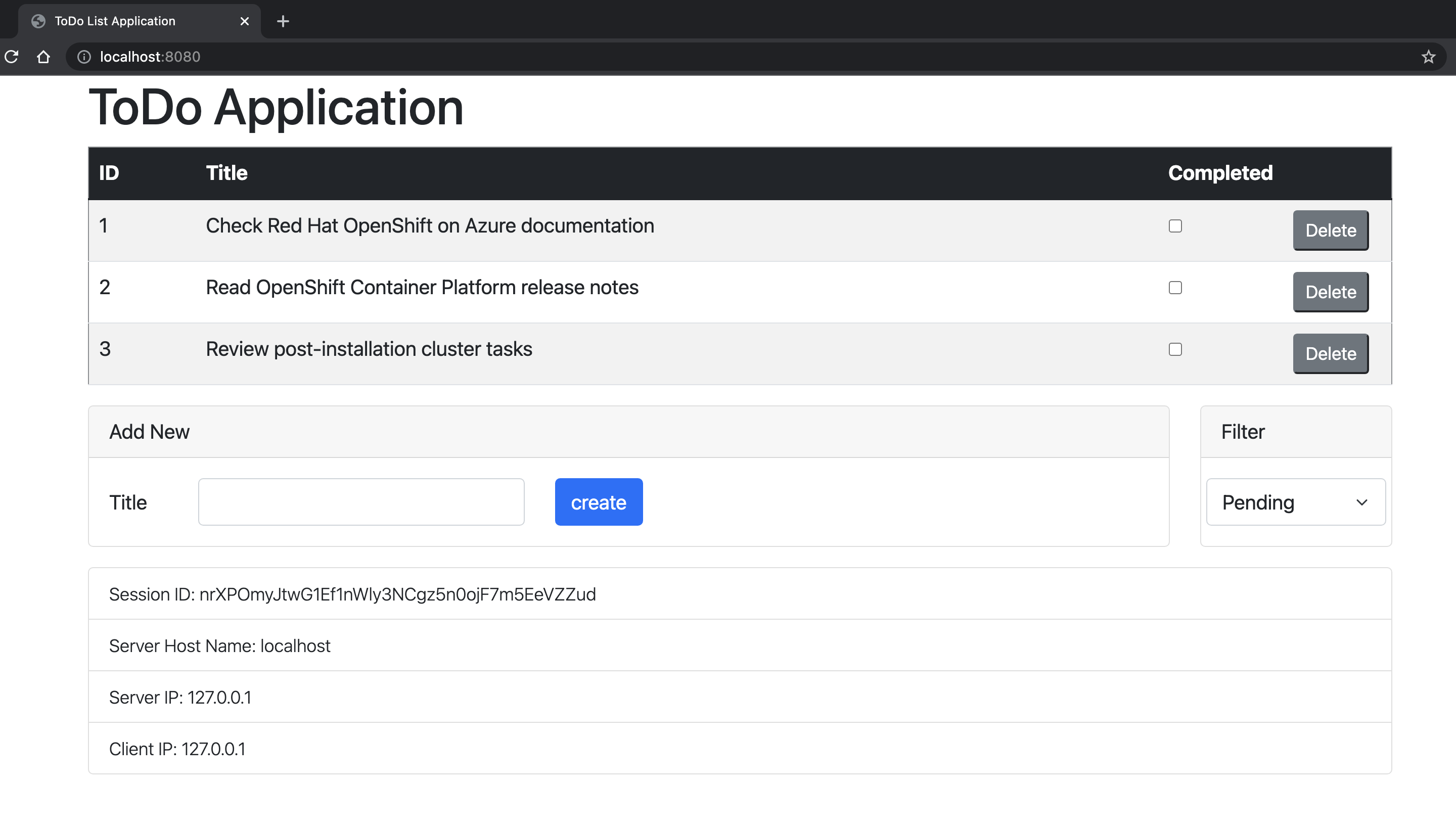
Controllare la disponibilità e i probe di idoneità per l'applicazione. OpenShift usa questi endpoint per verificare quando il pod è attivo e pronto per ricevere le richieste utente.
Per controllare lo stato di attività, eseguire:
curl http://localhost:9990/health/liveDovrebbe essere visualizzato questo output:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Per controllare lo stato di idoneità, eseguire:
curl http://localhost:9990/health/readyDovrebbe essere visualizzato questo output:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Premere CTRL+C per arrestare l'applicazione.
Eseguire la distribuzione in OpenShift
Per distribuire l'applicazione, si useranno i grafici Helm JBoss EAP già disponibili in Azure Red Hat OpenShift. È anche necessario specificare la configurazione desiderata, ad esempio l'utente del database, la password del database, la versione del driver da usare e le informazioni di connessione usate dall'origine dati. I passaggi seguenti presuppongono che Azure SQL sia in esecuzione e accessibile dal cluster OpenShift ed è stato archiviato il nome utente del database, la password, il nome host, la porta e il nome del database in un oggetto OpenShift OpenShift
Vai al repository locale della tua applicazione demo e cambia il ramo corrente in bootable-jar-openshift:
git checkout bootable-jar-openshift
Verrà ora esaminata rapidamente le modifiche apportate in questo ramo:
- È stato aggiunto un nuovo profilo Maven denominato
bootable-jar-openshiftche prepara il file JAR di avvio con una configurazione specifica per l'esecuzione del server nel cloud. Ad esempio, consente al sottosistema JGroups di usare le richieste di rete per individuare altri pod usando il protocollo KUBE_PING. - È stato aggiunto un set di file di configurazione nella directory jboss-on-aro-jakartaee/deployment . In questa directory è possibile trovare i file di configurazione per distribuire l'applicazione.
Distribuire l'applicazione in OpenShift
I passaggi successivi illustrano come distribuire l'applicazione con un grafico Helm usando la console Web OpenShift. Evitare la codifica dei valori sensibili nel grafico Helm usando una funzionalità denominata "segreti". Un segreto è semplicemente una raccolta di coppie nome-valore, in cui i valori vengono specificati in una posizione nota prima che siano necessari. In questo caso, il grafico Helm usa due segreti, con le coppie nome-valore seguenti da ognuna.
mssqlserver-secret-
db-hostindica il valore diMSSQLSERVER_HOST. -
db-nametrasmette il valore diMSSQLSERVER_DATABASE -
db-passwordtrasmette il valore diMSSQLSERVER_PASSWORD -
db-portindica il valore diMSSQLSERVER_PORT. -
db-userindica il valore diMSSQLSERVER_USER.
-
todo-list-secret-
app-cluster-passwordtrasmette una password arbitraria e specificata dall'utente in modo che i nodi del cluster possano formare in modo più sicuro. -
app-driver-versionindica il valore diMSSQLSERVER_DRIVER_VERSION. -
app-ds-jndiindica il valore diMSSQLSERVER_JNDI.
-
Creare
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Creare
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Nota
Microsoft consiglia di usare il flusso di autenticazione più sicuro disponibile. Il flusso di autenticazione descritto in questa procedura, ad esempio per database, cache, messaggistica o servizi di intelligenza artificiale, richiede un livello di attendibilità molto elevato nell'applicazione e comporta rischi non presenti in altri flussi. Usare questo flusso solo quando le opzioni più sicure, ad esempio le identità gestite per le connessioni senza password o senza chiave, non sono valide. Per le operazioni del computer locale, preferire le identità utente per le connessioni senza password o senza chiave.
Aprire la console OpenShift e passare alla visualizzazione per sviluppatori. È possibile individuare l'URL della console per il cluster OpenShift eseguendo questo comando. Accedere con l'id utente e la password
kubeadminottenuti da un passaggio precedente.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvSelezionare la <prospettiva /> Developer dal menu a discesa nella parte superiore del riquadro di spostamento.
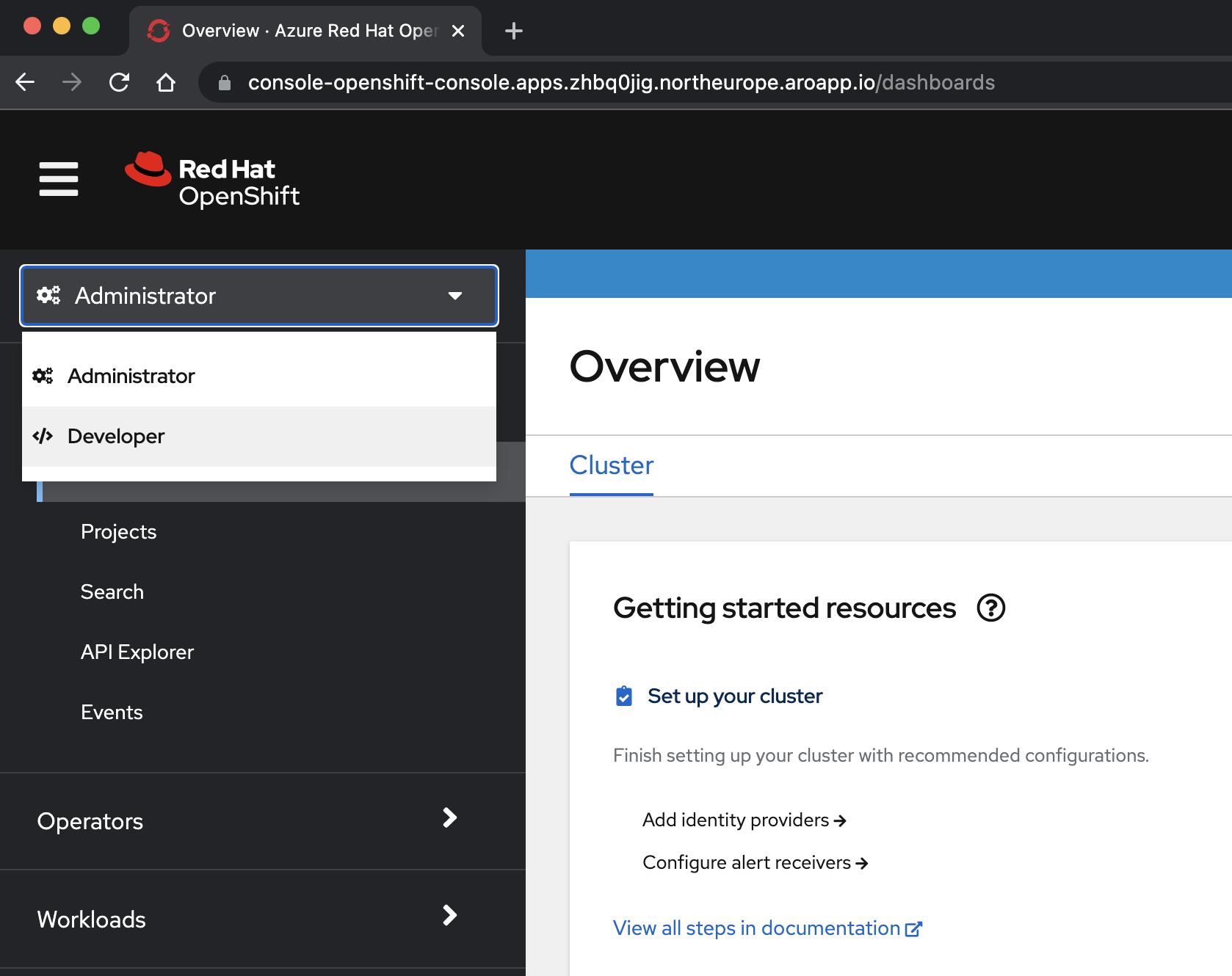
Nel punto <> selezionare il progetto eap-demo dal menu a discesa Progetto.
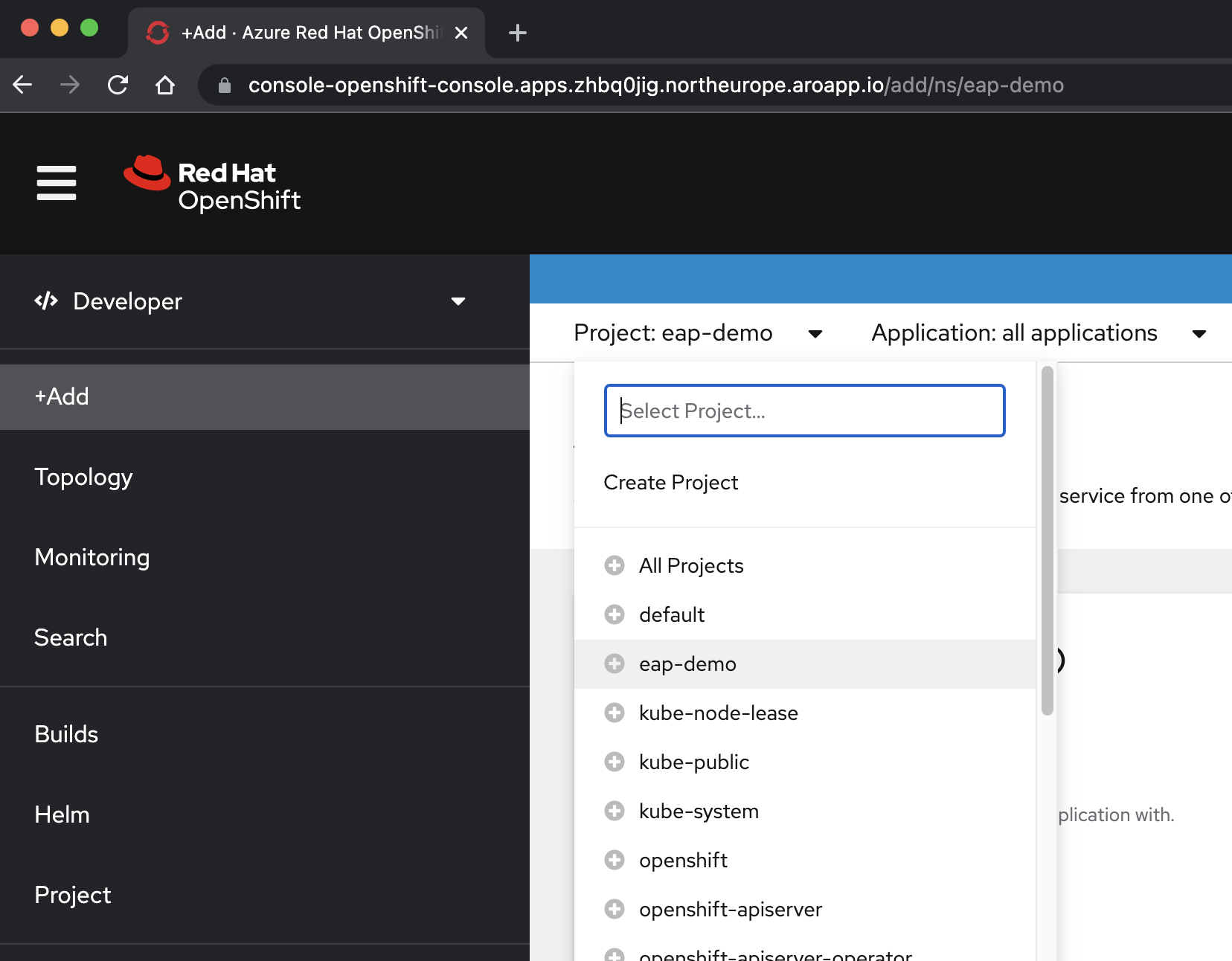
Selezionare +Aggiungi. Nella sezione Catalogo per sviluppatori selezionare Grafico Helm. Si arriva al catalogo Helm Chart disponibile nel cluster Azure Red Hat OpenShift. Nella casella Filtra per parola chiave digitare eap. Verranno visualizzate diverse opzioni, come illustrato di seguito:
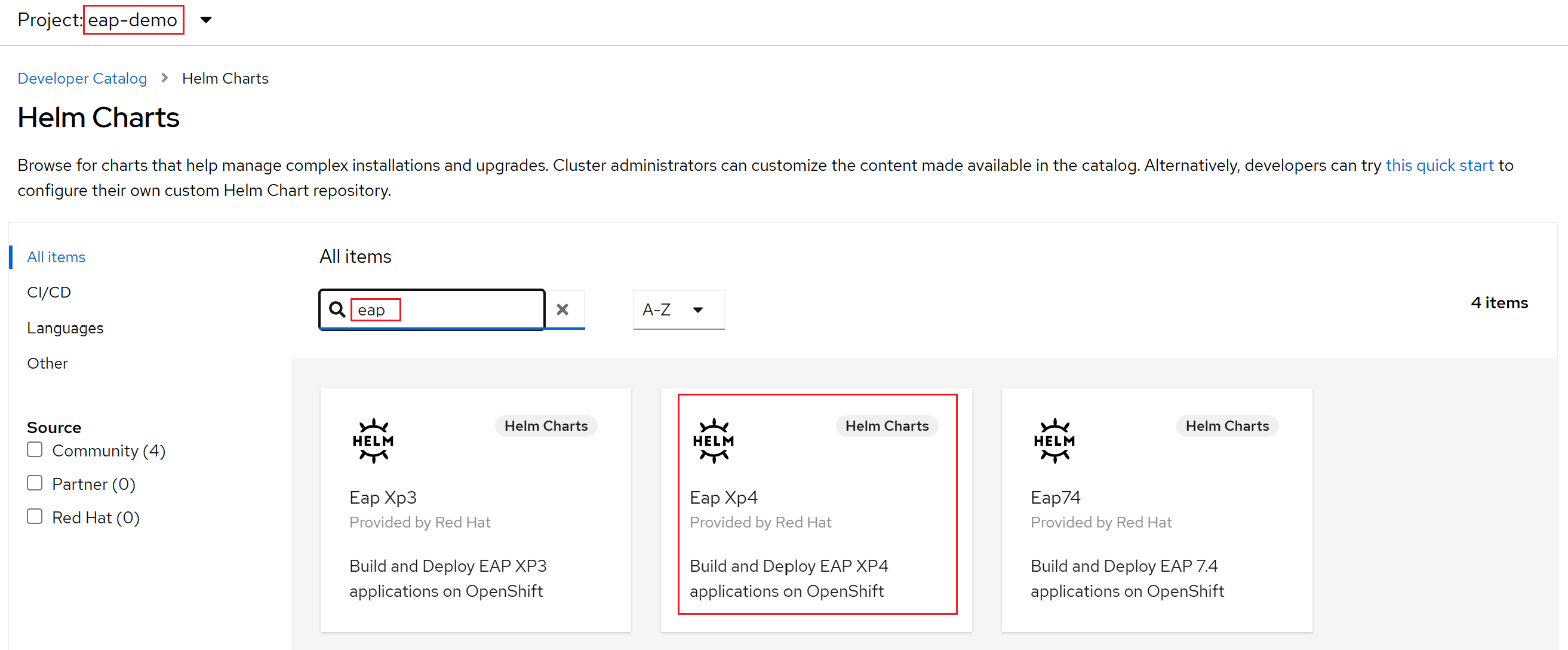
Poiché l'applicazione usa le funzionalità MicroProfile, si seleziona il grafico Helm per EAP Xp. "Xp" è l'acronimo di Expansion Pack. Con il pacchetto di espansione JBoss Enterprise Application Platform, gli sviluppatori possono usare le API (Application Programming Interface) di Eclipse MicroProfile per compilare e distribuire applicazioni basate su microservizi.
Selezionare il grafico Helm di JBoss EAP XP 4 e quindi selezionare Installa grafico Helm.
A questo punto, è necessario configurare il grafico per compilare e distribuire l'applicazione:
Modificare il nome della versione in eap-todo-list-demo.
È possibile configurare il grafico Helm usando una visualizzazione Maschera o una visualizzazione YAML. Nella sezione Configura tramite selezionare Visualizzazione YAML.
Modificare il contenuto YAML per configurare il grafico Helm copiando e incollando il contenuto del file del grafico Helm disponibile in deployment/application/todo-list-helm-chart.yaml invece del contenuto esistente:
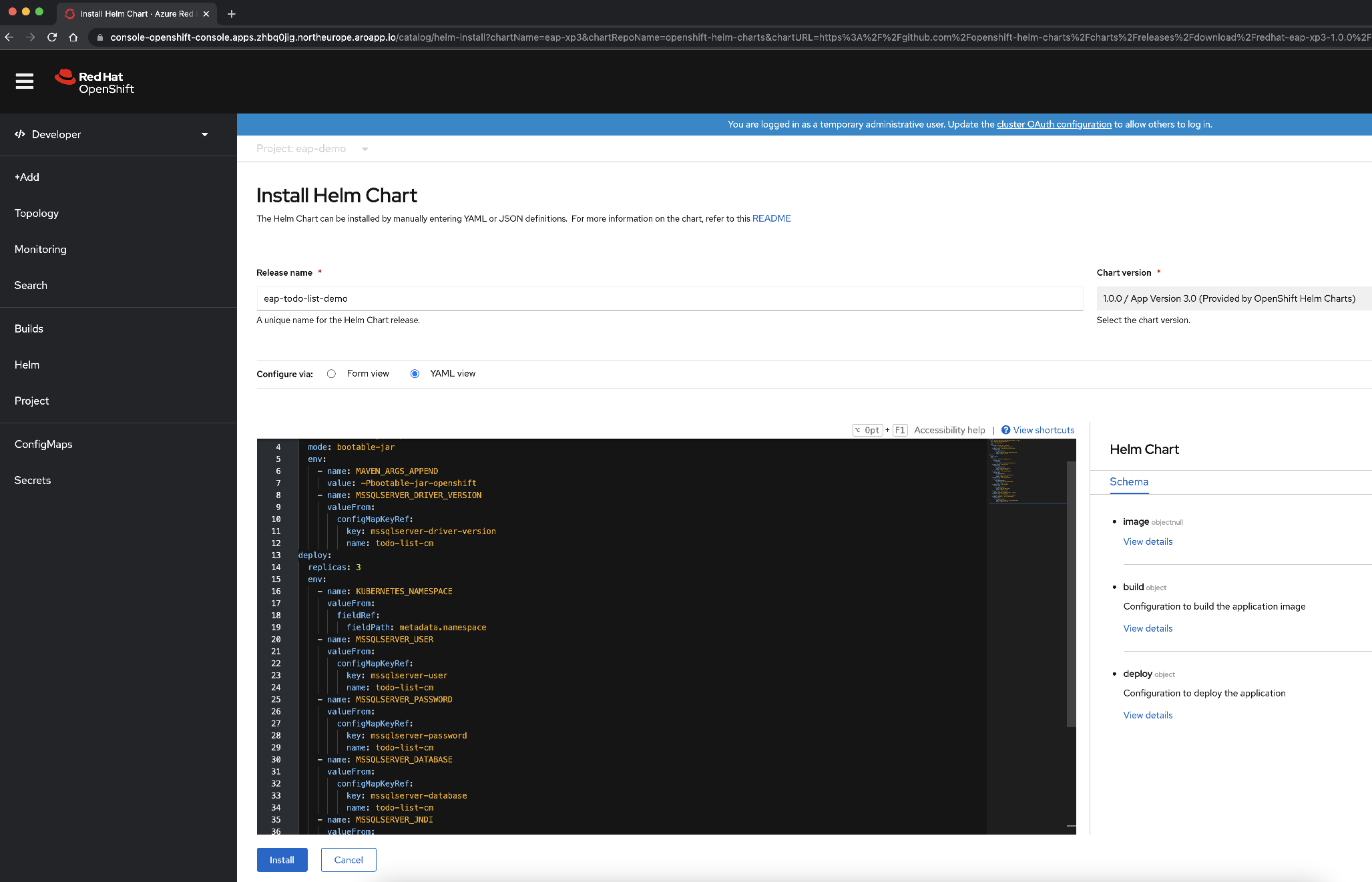
Questo contenuto fa riferimento ai segreti impostati in precedenza.
Infine, selezionare Installa per avviare la distribuzione dell'applicazione. Questa azione apre la visualizzazione Topologia con una rappresentazione grafica della versione Helm (denominata eap-todo-list-demo) e delle relative risorse associate.
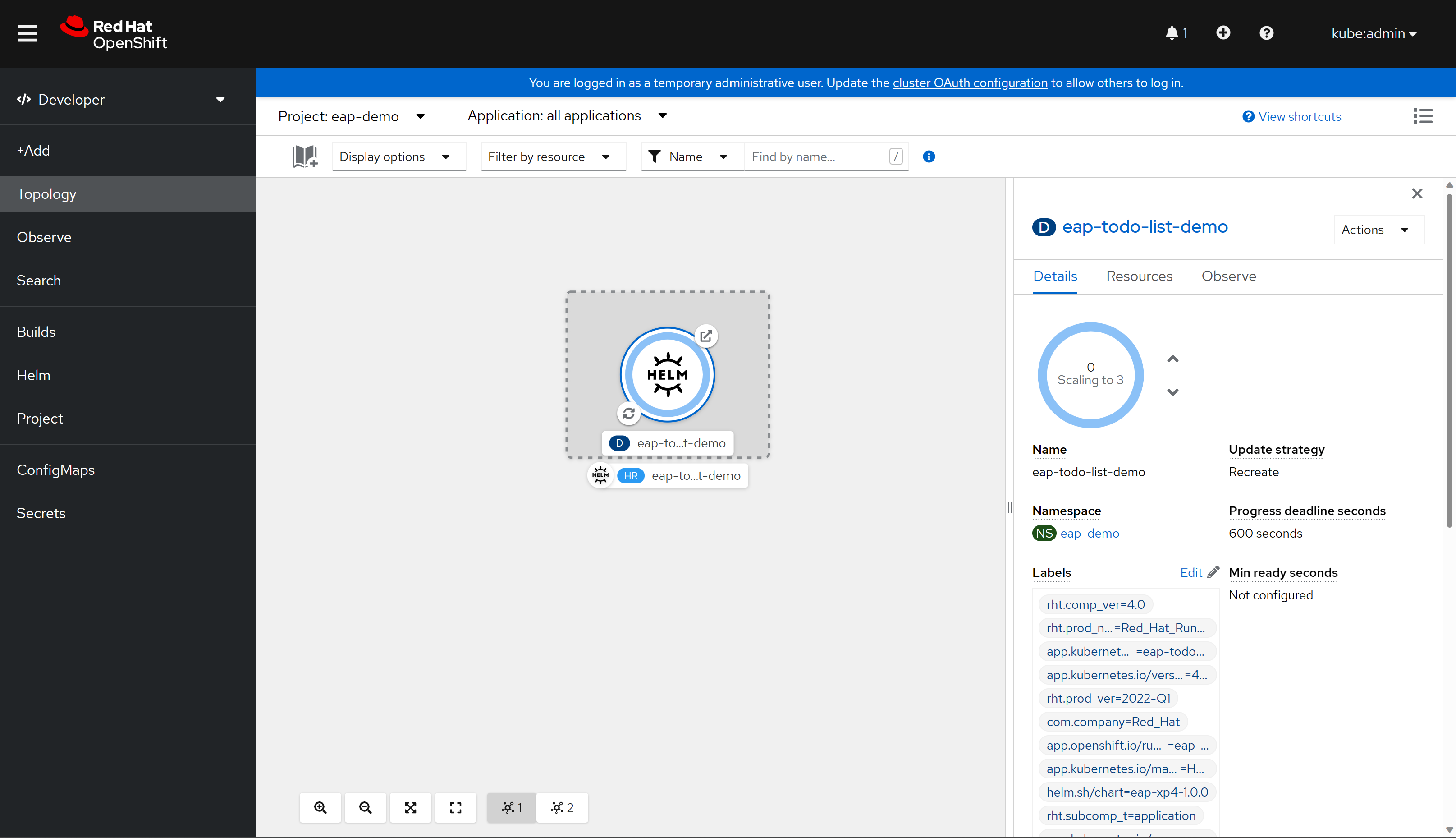
Helm Release (abbreviato HR) è denominato eap-todo-list-demo. Include una risorsa di distribuzione (abbreviata D) denominata anche eap-todo-list-demo.
Se si seleziona l'icona con due frecce in un cerchio in basso a sinistra nella casella D , si accede al riquadro Log . Qui è possibile osservare lo stato di avanzamento della compilazione. Per tornare alla visualizzazione topologia, selezionare Topologia nel riquadro di spostamento a sinistra.
Al termine della compilazione, l'icona in basso a sinistra visualizza un segno di spunta verde.
Al termine della distribuzione, il contorno del cerchio è blu scuro. Se si passa il puntatore del mouse sul blu scuro, verrà visualizzato un messaggio simile a
3 Running. Quando viene visualizzato il messaggio, è possibile passare all'applicazione dell'URL (usando l'icona in alto a destra) dalla route associata alla distribuzione.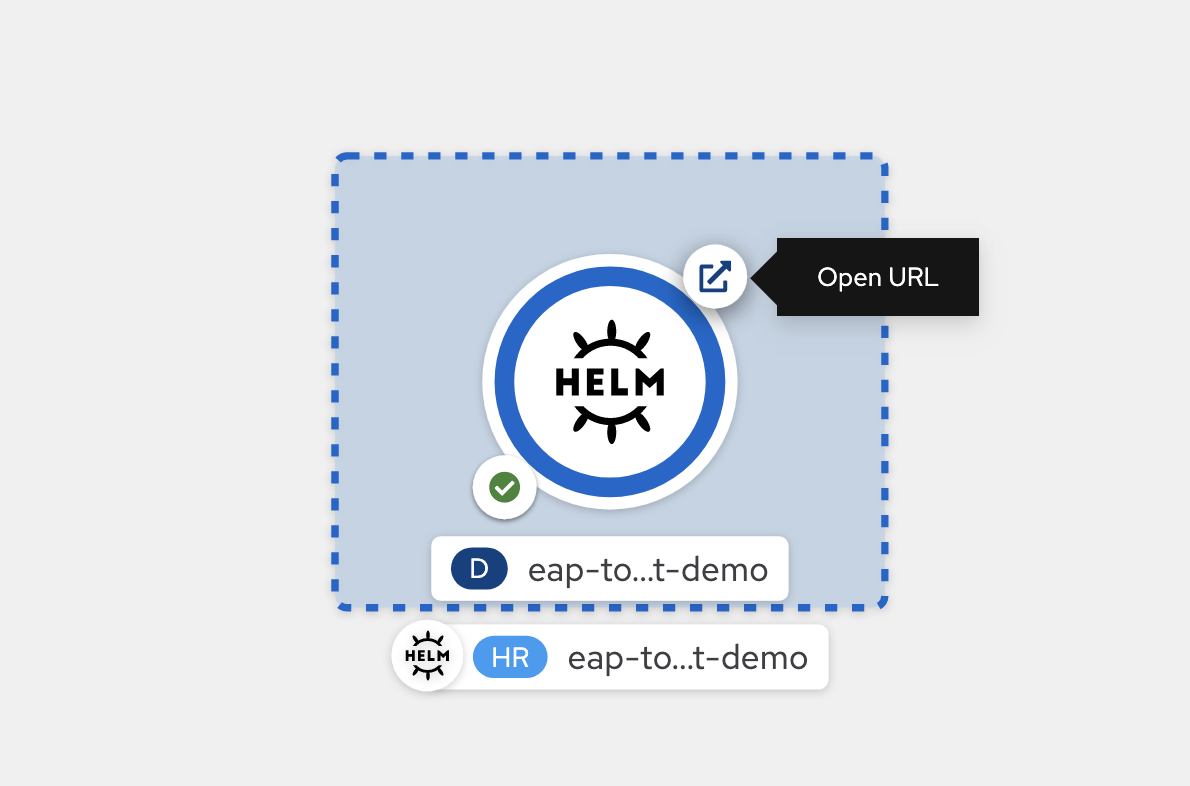
L'applicazione viene aperta nel browser in modo simile all'immagine seguente pronta per l'uso:
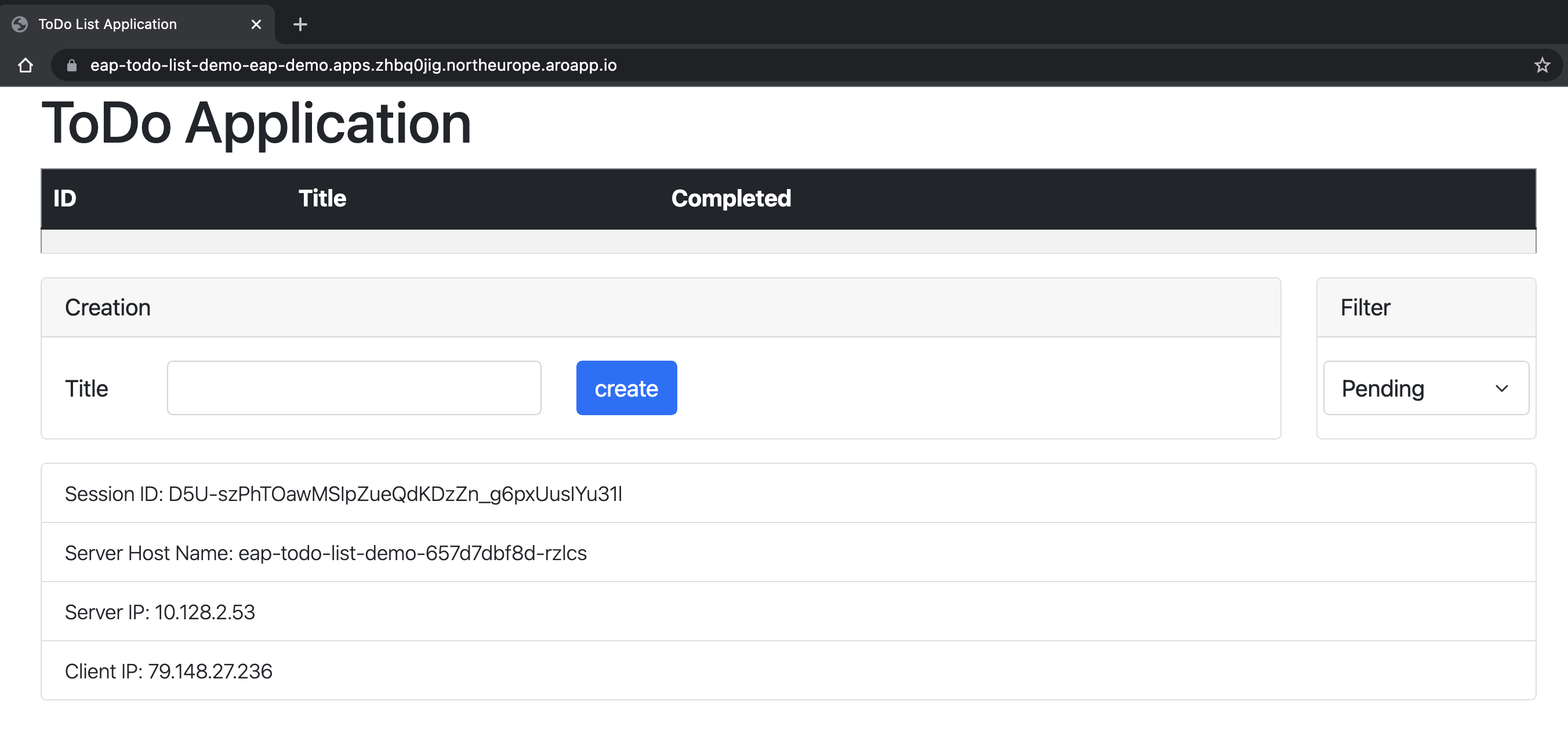
L'applicazione mostra il nome del pod che fornisce le informazioni. Per verificare le funzionalità di clustering, è possibile aggiungere alcuni elementi Todo. Eliminare quindi il pod con il nome indicato nel campo Nome host server visualizzato nell'applicazione usando
oc delete pod <pod-name>. Dopo aver eliminato il pod, creare un nuovo todo nella stessa finestra dell'applicazione. Puoi vedere che il nuovo Todo viene aggiunto tramite una richiesta Ajax, e ora il campo Nome host server mostra un nome diverso. Dietro le quinte, il servizio di bilanciamento del carico OpenShift ha inviato la nuova richiesta e l'ha recapitata a un pod disponibile. La visualizzazione Jakarta Faces viene ripristinata dalla copia della sessione HTTP archiviata nel pod che elabora la richiesta. In effetti, è possibile notare che il campo ID sessione non è stato modificato. Se la sessione non viene replicata tra i pod, si ottiene un Jakarta FacesViewExpiredExceptione l'applicazione non funziona come previsto.

Pulire le risorse
Eliminare l'applicazione
Se si vuole eliminare solo l'applicazione, è possibile aprire la console OpenShift e, nella visualizzazione dello sviluppatore, passare all'opzione di menu Helm . In questo menu è possibile visualizzare tutte le versioni di Helm Chart installate nel cluster.

Individuare eap-todo-list-demo Helm Chart. Alla fine della riga, selezionare i tre punti verticali per aprire la voce del menu contestuale delle azioni.
Selezionare Disinstalla Helm Release per rimuovere l'applicazione. Si noti che l'oggetto segreto usato per fornire la configurazione dell'applicazione non fa parte del grafico. È necessario rimuoverlo separatamente se non è più necessario.
Eseguire il comando seguente se si vuole eliminare il segreto che contiene la configurazione dell'applicazione:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Eliminare il progetto OpenShift
È anche possibile eliminare tutte le configurazioni create per questa demo eliminando il eap-demo progetto. A tale scopo, eseguire il comando seguente:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Eliminare il cluster Azure Red Hat OpenShift
Eliminare il cluster Azure Red Hat OpenShift seguendo la procedura descritta in Esercitazione: Eliminare un cluster Azure Red Hat OpenShift 4.
Eliminare il gruppo di risorse
Per eliminare tutte le risorse create dai passaggi precedenti, eliminare il gruppo di risorse creato per il cluster Azure Red Hat OpenShift.
Passaggi successivi
Per altre informazioni, vedere i riferimenti usati in questa guida:
- Red Hat JBoss Enterprise Application Platform
- Uso di JBoss EAP su OpenShift Container Platform
- Azure Red Hat OpenShift
- Grafici Helm JBoss EAP
- JBoss EAP Bootable JAR
Continuare a esplorare le opzioni per eseguire JBoss EAP in Azure.