Esercitazione: Eseguire la migrazione di Oracle WebLogic Server ad Azure Macchine virtuali con disponibilità elevata e ripristino di emergenza
Questa esercitazione illustra un modo semplice ed efficace per implementare disponibilità elevata e ripristino di emergenza (HA/DR) per Java usando Oracle WebLogic Server (WLS) in Azure Macchine virtuali (VM). La soluzione illustra come ottenere un obiettivo del tempo di recupero basso (RTO) e un obiettivo del punto di ripristino (RPO) usando una semplice applicazione Jakarta EE basata su database in esecuzione in WLS. Disponibilità elevata/ripristino di emergenza è un argomento complesso, con molte possibili soluzioni. La soluzione migliore dipende dai requisiti specifici. Per altri modi per implementare disponibilità elevata/ripristino di emergenza, vedere le risorse alla fine di questo articolo.
In questa esercitazione apprenderai a:
- Usare le procedure consigliate ottimizzate per Azure per ottenere disponibilità elevata e ripristino di emergenza.
- Configurare un gruppo di failover database SQL di Microsoft Azure in aree abbinate.
- Configurare cluster WLS associati in macchine virtuali di Azure.
- Configurare un Gestione traffico di Azure.
- Configurare i cluster WLS per la disponibilità elevata e il ripristino di emergenza.
- Failover di test da primario a secondario.
Il diagramma seguente illustra l'architettura compilata:

Gestione traffico di Azure controlla l'integrità delle aree e indirizza il traffico di conseguenza al livello applicazione. Sia l'area primaria che l'area secondaria hanno una distribuzione completa del cluster WLS. Tuttavia, solo l'area primaria sta eseguendo attivamente la manutenzione delle richieste di rete dagli utenti. L'area secondaria è passiva e attivata per ricevere traffico solo quando l'area primaria subisce un'interruzione del servizio. Gestione traffico di Azure usa la funzionalità di controllo dell'integrità del gateway di app Azure lication per implementare questo routing condizionale. Il cluster WLS primario è in esecuzione e il cluster secondario viene arrestato. L'RTO di failover geografico del livello applicazione dipende dal tempo necessario per avviare le macchine virtuali ed eseguire il cluster WLS secondario. L'RPO dipende dal database SQL di Azure perché i dati vengono mantenuti e replicati nel gruppo di failover database SQL di Azure.
Il livello di database è costituito da un gruppo di failover database SQL di Azure con un server primario e un server secondario. Il server primario è in modalità di lettura/scrittura attiva e connesso al cluster WLS primario. Il server secondario è in modalità di sola preparazione passiva e connesso al cluster WLS secondario. Un failover geografico passa tutti i database secondari del gruppo al ruolo primario. Per rpo di failover geografico e RTO di database SQL di Azure, vedere Panoramica della continuità aziendale.
Questo articolo è stato scritto con il servizio database SQL di Azure perché l'articolo si basa sulle funzionalità a disponibilità elevata di tale servizio. Sono possibili altre opzioni di database, ma è necessario considerare le funzionalità a disponibilità elevata di qualsiasi database scelto. Per altre informazioni, incluse le informazioni su come ottimizzare la configurazione delle origini dati per la replica, vedere Configuring Data Sources for Oracle Fusion Middleware Active-Passive Deployment.For more information, including information on how to optimize the configuration of data sources for replication, see Configuring Data Sources for Oracle Fusion Middleware Active-Passive Deployment.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Assicurarsi di avere il
Ownerruolo o iContributorruoli eUser Access Administratornella sottoscrizione. È possibile verificare l'assegnazione seguendo la procedura descritta in Elencare le assegnazioni di ruolo di Azure usando il portale di Azure. - Preparare un computer locale con Windows, Linux o macOS installato.
- Installare e configurare Git.
- Installare un'implementazione java SE, versione 17 o successiva( ad esempio, la build Microsoft di OpenJDK).
- Installare Maven, versione 3.9.3 o successiva.
Configurare un gruppo di failover database SQL di Azure in aree abbinate
In questa sezione viene creato un gruppo di failover database SQL di Azure in aree abbinate da usare con i cluster e l'app WLS. In una sezione successiva si configura WLS per archiviare i dati di sessione e i dati del log delle transazioni (TLOG) in questo database. Questa procedura è coerente con l'architettura di disponibilità massima (MAA) di Oracle. Queste linee guida forniscono un adattamento di Azure per MAA. Per altre informazioni su MAA, vedere Architettura di disponibilità massima oracle.
Creare prima di tutto il database SQL di Azure primario seguendo la procedura portale di Azure descritta in Avvio rapido: Creare un database singolo - database SQL di Azure. Seguire i passaggi fino a, ma non includere, la sezione "Pulire le risorse". Usare le istruzioni seguenti durante l'articolo, quindi tornare a questo articolo dopo aver creato e configurato il database SQL di Azure:
Quando si raggiunge la sezione Creare un database singolo, seguire questa procedura:
- Nel passaggio 4 per la creazione di un nuovo gruppo di risorse salvare il valore del nome del gruppo di risorse, ad esempio myResourceGroup.
- Nel passaggio 5 per il nome del database salvare il valore Nome database, ad esempio mySampleDatabase.
- Nel passaggio 6 per la creazione del server, seguire questa procedura:
- Salvare il nome univoco del server, ad esempio sqlserverprimary-ejb120623.
- In Località selezionare (USA) Stati Uniti orientali.
- Per Metodo di autenticazione selezionare Usa autenticazione SQL.
- Salvare il valore dell'account di accesso amministratore del server, ad esempio azureuser.
- Salvare il valore password .
- Nel passaggio 8, per Ambiente del carico di lavoro, selezionare Sviluppo. Esaminare la descrizione e prendere in considerazione altre opzioni per il carico di lavoro.
- Nel passaggio 11, per Ridondanza dell'archiviazione di backup, selezionare Archiviazione di backup con ridondanza locale. Prendere in considerazione altre opzioni per i backup. Per altre informazioni, vedere la sezione Ridondanza dell'archiviazione di backup in Backup automatici in database SQL di Azure.
- Nel passaggio 14, nella configurazione delle regole del firewall, per Consenti ai servizi e alle risorse di Azure di accedere a questo server, selezionare Sì.
Quando si raggiunge la sezione Eseguire una query sul database, seguire questa procedura:
Nel passaggio 3 immettere le informazioni di accesso dell'amministratore del server di autenticazione SQL per l'accesso .
Nota
Se l'accesso non riesce con un messaggio di errore simile al client con indirizzo IP 'xx.xx.xx.xx.xx' non è autorizzato ad accedere al server, selezionare Allowlist IP xx.xx.xx.xx nel server <your-sqlserver-name> alla fine del messaggio di errore. Attendere il completamento dell'aggiornamento delle regole del firewall del server, quindi selezionare di nuovo OK .
Dopo aver eseguito la query di esempio nel passaggio 5, cancellare l'editor e creare tabelle.
Immettere la query seguente per creare lo schema per TLOG.
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));
Dopo un'esecuzione riuscita, verrà visualizzato il messaggio Query completata: Righe interessate: 0.
Queste tabelle di database vengono usate per archiviare i dati di log delle transazioni (TLOG) e di sessione per i cluster e le app WLS. Per altre informazioni, vedere Uso di un archivio TLOG JDBC e Uso di un database per l'archiviazione persistente (persistenza JDBC).
Creare quindi un gruppo di failover database SQL di Azure seguendo la procedura portale di Azure descritta in Configurare un gruppo di failover per database SQL di Azure. Sono necessarie solo le sezioni seguenti: Creare un gruppo di failover e Testare il failover pianificato. Usare la procedura seguente durante l'articolo, quindi tornare a questo articolo dopo aver creato e configurato il gruppo di failover database SQL di Azure:
Quando si raggiunge la sezione Creare un gruppo di failover, seguire questa procedura:
- Nel passaggio 5 per la creazione del gruppo di failover selezionare l'opzione per creare un nuovo server secondario e quindi seguire questa procedura:
- Immettere e salvare il nome del gruppo di failover, ad esempio failovergroupname-ejb120623.
- Immettere e salvare il nome univoco del server, ad esempio sqlserversecondary-ejb120623.
- Immettere lo stesso amministratore del server e la stessa password del server primario.
- In Località selezionare un'area diversa da quella usata per il database primario.
- Assicurarsi che l'opzione Consenti ai servizi di Azure di accedere al server sia selezionata.
- Nel passaggio 5 per la configurazione dei database all'interno del gruppo selezionare il database creato nel server primario, ad esempio mySampleDatabase.
- Nel passaggio 5 per la creazione del gruppo di failover selezionare l'opzione per creare un nuovo server secondario e quindi seguire questa procedura:
Dopo aver completato tutti i passaggi nella sezione Testare il failover pianificato, tenere aperta la pagina del gruppo di failover e usarla per il test di failover dei cluster WLS in un secondo momento.
Configurare cluster WLS associati in macchine virtuali di Azure
In questa sezione vengono creati due cluster WLS in macchine virtuali di Azure usando l'offerta Oracle WebLogic Server Cluster in macchine virtuali di Azure. Il cluster negli Stati Uniti orientali è primario ed è configurato come cluster attivo in un secondo momento. Il cluster negli Stati Uniti occidentali è secondario e viene configurato come cluster passivo in un secondo momento.
Configurare il cluster WLS primario
Aprire prima di tutto l'offerta Oracle WebLogic Server Cluster in macchine virtuali di Azure nel browser e selezionare Crea. Verrà visualizzato il riquadro Informazioni di base dell'offerta.
Per compilare il riquadro Informazioni di base, seguire questa procedura:
- Assicurarsi che il valore visualizzato per Subscription sia lo stesso che include i ruoli elencati nella sezione prerequisiti.
- È necessario distribuire l'offerta in un gruppo di risorse vuoto. Nel campo Gruppo di risorse selezionare Crea nuovo e compilare un valore univoco per il gruppo di risorse, ad esempio wls-cluster-eastus-ejb120623.
- In Dettagli istanza selezionare Stati Uniti orientali in Area.
- In Credenziali per Macchine virtuali e WebLogic specificare rispettivamente una password per l'account amministratore della macchina virtuale e dell'amministratore WebLogic. Salvare il nome utente e la password per l'amministratore WebLogic.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Avanti per passare al riquadro Configurazione TLS/SSL.

Lasciare le impostazioni predefinite nel riquadro Configurazione TLS/SSL, selezionare Avanti per passare al riquadro gateway di app Azure lication e quindi seguire questa procedura.
- Per Connetti a app Azure lication Gateway?, selezionare Sì.
- Per Selezionare l'opzione Selezionare il certificato TLS/SSL desiderato, selezionare Genera un certificato autofirmato.
- Selezionare Avanti per passare al riquadro Rete .

Nel riquadro Rete verranno visualizzati tutti i campi precompilato con le impostazioni predefinite. Per salvare la configurazione di rete, seguire questa procedura:
Selezionare Modifica rete virtuale. Salvare lo spazio indirizzi della rete virtuale, ad esempio 10.1.4.0/23.
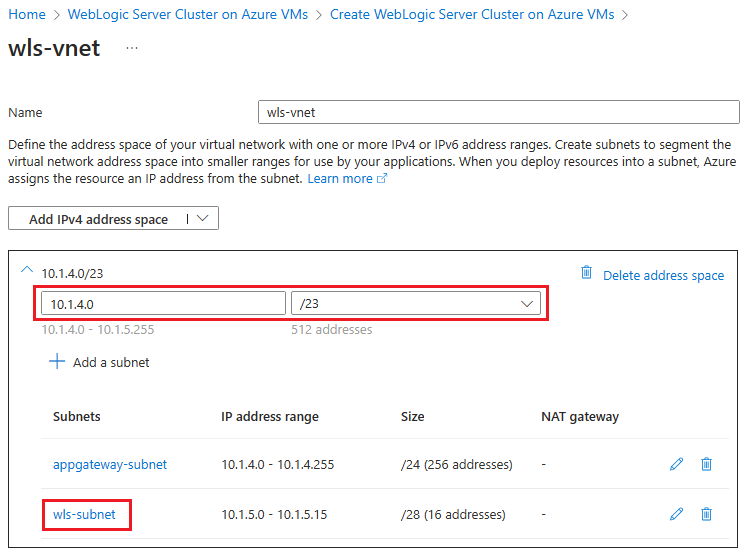
Selezionare questa opzione
wls-subnetper modificare la subnet. In Dettagli subnet salvare a parte l'indirizzo iniziale e le dimensioni della subnet, ad esempio 10.1.5.0 e /28.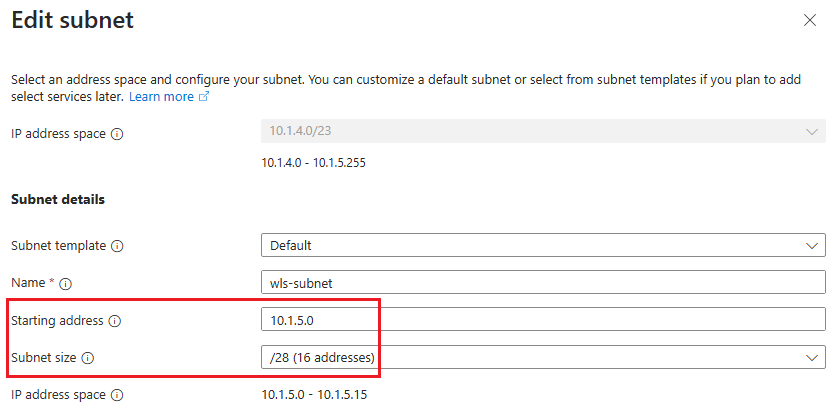
Se si apportano modifiche, salvare le modifiche.
Tornare al riquadro Rete .
Selezionare Avanti per passare al riquadro Database .


I passaggi seguenti illustrano come compilare il riquadro Database :
- Per Connetti al database? selezionare Sì.
- Per Scegliere il tipo di database selezionare Microsoft SQL Server (supporto connessione senza password).
- Per Nome JNDI immettere jdbc/WebLogicCafeDB.
- Per DataSource Connection String sostituire i segnaposto con i valori salvati nella sezione precedente per il database SQL primario, ad esempio jdbc:sqlserver://sqlserverprimary-ejb120623.database.windows.net:1433; database=mySampleDatabase.
- Per Protocollo di transazione globale selezionare Nessuno.
- Per Nome utente database sostituire i segnaposto con i valori salvati nella sezione precedente per il database SQL primario, ad esempio azureuser@sqlserverprimary-ejb120623.
- Immettere la password di accesso dell'amministratore del server salvata in precedenza per Password database. Immettere lo stesso valore per Conferma password.
- Lasciare le impostazioni predefinite per gli altri campi.
- Selezionare Rivedi e crea.
- Attendere il completamento dell'esecuzione della convalida finale e quindi selezionare Crea.

Dopo un po', verrà visualizzata la pagina Distribuzione in cui è in corso la distribuzione.
Nota
Se si verificano problemi durante l'esecuzione della convalida finale, correggerli e riprovare.
A seconda delle condizioni di rete e di altre attività nell'area selezionata, il completamento della distribuzione può richiedere fino a 50 minuti. Successivamente, verrà visualizzato il testo La distribuzione è stata completata nella pagina di distribuzione.
Nel frattempo, è possibile configurare il cluster WLS secondario in parallelo.
Configurare il cluster WLS secondario
Seguire la stessa procedura descritta nella sezione Configurare il cluster WLS primario per configurare il cluster WLS secondario nell'area Stati Uniti occidentali, ad eccezione delle differenze seguenti:
Nel riquadro Informazioni di base seguire questa procedura:
- Nel campo Gruppo di risorse selezionare Crea nuovo e compilare un valore univoco diverso per il gruppo di risorse, ad esempio wls-cluster-westtus-ejb120623.
- In Dettagli istanza selezionare Stati Uniti occidentali in Area.
Nel riquadro Rete seguire questa procedura:
Per Modifica rete virtuale immettere lo stesso spazio indirizzi della rete virtuale del cluster WLS primario, ad esempio 10.1.4.0/23.
Nota
Verrà visualizzato un messaggio di avviso simile al seguente: Spazio indirizzi '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' si sovrappone con spazio indirizzi '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' della rete virtuale 'wls-vnet'. Non è possibile eseguire il peering di reti virtuali con spazio indirizzi sovrapposto. Se si intende eseguire il peering di queste reti virtuali, modificare lo spazio degli indirizzi "10.1.4.0/23 (10.1.4.0 - 10.1.5.255)". È possibile ignorare questo messaggio perché sono necessari due cluster WLS con la stessa configurazione di rete.
Per
wls-subnetimmettere lo stesso indirizzo iniziale e le stesse dimensioni della subnet del cluster WLS primario, ad esempio 10.1.5.0 e /28.
Nel riquadro Database seguire questa procedura:
- Per DataSource Connection String sostituire i segnaposto con i valori salvati nella sezione precedente per il database SQL secondario, ad esempio jdbc:sqlserver://sqlserversecondary-ejb120623.database.windows.net:1433; database=mySampleDatabase.
- Per Nome utente database sostituire i segnaposto con i valori salvati nella sezione precedente per il database SQL secondario, ad esempio azureuser@sqlserversecondary-ejb120623.
Eseguire il mirroring delle impostazioni di rete per i due cluster
Durante la fase di ripresa delle transazioni in sospeso nel cluster WLS secondario dopo un failover, WLS controlla la proprietà dell'archivio TLOG. Per superare correttamente il controllo, tutti i server gestiti nel cluster secondario devono avere lo stesso indirizzo IP privato del cluster primario.
Questa sezione illustra come eseguire il mirroring delle impostazioni di rete dal cluster primario al cluster secondario.
Prima di tutto, seguire questa procedura per configurare le impostazioni di rete per il cluster primario al termine della distribuzione:
Nel riquadro Panoramica della pagina Distribuzione selezionare Vai al gruppo di risorse.
Selezionare l'interfaccia
adminVM_NIC_with_pub_ipdi rete .- In Impostazioni selezionare Configurazioni IP.
- Selezionare
ipconfig1. - In Impostazioni indirizzo IP privato selezionare Statico per Allocazione. Salvare da parte l'indirizzo IP privato.
- Seleziona Salva.
Tornare al gruppo di risorse del cluster WLS primario, quindi ripetere il passaggio 3 per le interfacce
mspVM1_NIC_with_pub_ipdi rete ,mspVM2_NIC_with_pub_ipemspVM3_NIC_with_pub_ip.Attendere il completamento di tutti gli aggiornamenti. È possibile selezionare l'icona delle notifiche nel portale di Azure per aprire il riquadro Notifiche per il monitoraggio dello stato.

Tornare al gruppo di risorse del cluster WLS primario, quindi copiare il nome per la risorsa con il tipo Endpoint privato, ad esempio 7e8c8bsaep. Usare tale nome per trovare l'interfaccia di rete rimanente, ad esempio 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a. Selezionarlo e seguire i passaggi precedenti per ottenere l'indirizzo IP privato.
Usare quindi la procedura seguente per configurare le impostazioni di rete per il cluster secondario al termine della distribuzione:
Nel riquadro Panoramica della pagina Distribuzione selezionare Vai al gruppo di risorse.
Per le interfacce di
adminVM_NIC_with_pub_iprete ,mspVM1_NIC_with_pub_ip,mspVM2_NIC_with_pub_ipemspVM3_NIC_with_pub_ip, seguire i passaggi precedenti per aggiornare l'allocazione degli indirizzi IP privati a Statico.Attendere il completamento di tutti gli aggiornamenti.
Per le interfacce di
mspVM1_NIC_with_pub_iprete ,mspVM2_NIC_with_pub_ipemspVM3_NIC_with_pub_ip, seguire i passaggi precedenti, ma aggiornare l'indirizzo IP privato allo stesso valore usato con il cluster primario. Attendere il completamento dell'aggiornamento corrente dell'interfaccia di rete prima di procedere con quello successivo.Nota
Non è possibile modificare l'indirizzo IP privato dell'interfaccia di rete che fa parte di un endpoint privato. Per eseguire facilmente il mirroring degli indirizzi IP privati delle interfacce di rete per i server gestiti, è consigliabile aggiornare l'indirizzo IP privato per
adminVM_NIC_with_pub_ipa un indirizzo IP non usato. A seconda dell'allocazione di indirizzi IP privati nei due cluster, potrebbe essere necessario aggiornare anche l'indirizzo IP privato nel cluster primario.
La tabella seguente illustra un esempio di mirroring delle impostazioni di rete per due cluster:
| Cluster | Interfaccia di rete | Indirizzo IP privato (prima) | Indirizzo IP privato (dopo) | Sequenza di aggiornamento |
|---|---|---|---|---|
| Server/istanza primaria | 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a |
10.1.5.4 |
10.1.5.4 |
|
| Server/istanza primaria | adminVM_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.7 |
|
| Server/istanza primaria | mspVM1_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.5 |
|
| Server/istanza primaria | mspVM2_NIC_with_pub_ip |
10.1.5.8 |
10.1.5.9 |
1 |
| Primaria | mspVM3_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.6 |
|
| Secondari | 1696b0saep.nic.2e19bf46-9799-4acc-b64b-a2cd2f7a4ee1 |
10.1.5.8 |
10.1.5.8 |
|
| Secondari | adminVM_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.4 |
4 |
| Secondari | mspVM1_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.5 |
5 |
| Secondari | mspVM2_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.9 |
2 |
| Secondari | mspVM3_NIC_with_pub_ip |
10.1.5.4 |
10.1.5.6 |
3 |
Controllare il set di indirizzi IP privati per tutti i server gestiti, costituito dal pool back-end del gateway di app Azure lication distribuito in ogni cluster. Se viene aggiornato, seguire questa procedura per aggiornare di conseguenza il pool back-end del gateway di app Azure lication:
- Aprire il gruppo di risorse del cluster.
- Trovare la risorsa myAppGateway con il tipo Gateway applicazione. Selezionare l'account per aprirlo.
- Nella sezione Impostazioni selezionare Pool back-end e quindi selezionare
myGatewayBackendPool. - Modificare i valori delle destinazioni back-end con l'indirizzo IP privato o gli indirizzi aggiornati e quindi selezionare Salva. Attendere il completamento.
- Nella sezione Impostazioni selezionare Probe di integrità, quindi selezionare HTTPhealthProbe.
- Assicurarsi di voler testare l'integrità del back-end prima di aggiungere il probe di integrità, quindi selezionare Test. Si noterà che il valore Stato del pool
myGatewayBackendPoolback-end è contrassegnato come integro. In caso contrario, verificare se gli indirizzi IP privati vengono aggiornati come previsto e le macchine virtuali sono in esecuzione, quindi testare di nuovo il probe di integrità. Prima di continuare, è necessario risolvere il problema.
Nell'esempio seguente viene aggiornato il pool back-end del gateway di app Azure lication per ogni cluster:
| Cluster | pool back-end del gateway di app Azure lication | Destinazioni back-end (prima) | Destinazioni back-end (dopo) |
|---|---|---|---|
| Server/istanza primaria | myGatewayBackendPool |
(10.1.5.5, 10.1.5.8, 10.1.5.6) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
| Secondari | myGatewayBackendPool |
(10.1.5.7, 10.1.5.6, 10.1.5.4) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
Per automatizzare il mirroring delle impostazioni di rete, è consigliabile usare l'interfaccia della riga di comando di Azure. Per altre informazioni, vedere Attività iniziali con l’interfaccia della riga di comando di Azure.
Verificare le distribuzioni dei cluster
È stato distribuito un gateway di app Azure lication e un server di amministrazione WLS in ogni cluster. Il gateway di app Azure lication funge da servizio di bilanciamento del carico per tutti i server gestiti nel cluster. Il server di amministrazione WLS fornisce una console Web per la configurazione del cluster.
Usare la procedura seguente per verificare se il gateway di app Azure lication e la console di amministrazione WLS in ogni cluster funzionano prima di passare al passaggio successivo:
- Tornare alla pagina Distribuzione e quindi selezionare Output.
- Copiare il valore della proprietà appGatewayURL. Aggiungere la stringa weblogic/ready e quindi aprire tale URL in una nuova scheda del browser. Verrà visualizzata una pagina vuota senza alcun messaggio di errore. In caso contrario, è necessario risolvere il problema prima di continuare.
- Copiare e salvare il valore della proprietà adminConsole. Aprirlo in una nuova scheda del browser. Verrà visualizzata la pagina di accesso della Console di amministrazione di WebLogic Server. Accedere alla console con il nome utente e la password per l'amministratore webLogic salvato in precedenza. Se non è possibile accedere, è necessario risolvere il problema prima di continuare.
Usare la procedura seguente per ottenere l'indirizzo IP del gateway di app Azure lication per ogni cluster. Questi valori vengono usati quando si configura il Gestione traffico di Azure in un secondo momento.
- Aprire il gruppo di risorse in cui viene distribuito il cluster, ad esempio selezionare Panoramica per tornare al riquadro Panoramica della pagina di distribuzione. Selezionare quindi Vai al gruppo di risorse.
- Trovare la risorsa
gwipcon il tipo Indirizzo IP pubblico e quindi selezionarla per aprirla. Cercare il campo Indirizzo IP e salvare il relativo valore.
Configurare un Gestione traffico di Azure
In questa sezione viene creato un Gestione traffico di Azure per distribuire il traffico alle applicazioni pubbliche nelle aree di Azure globali. L'endpoint primario punta al gateway di app Azure lication nel cluster WLS primario e l'endpoint secondario punta al gateway di app Azure lication nel cluster WLS secondario.
Creare un profilo Gestione traffico di Azure seguendo Avvio rapido: Creare un profilo Gestione traffico usando il portale di Azure. Ignorare la sezione Prerequisiti . Sono necessarie solo le sezioni seguenti: Creare un profilo di Gestione traffico, Aggiungere endpoint Gestione traffico e Testare Gestione traffico profilo. Usare la procedura seguente durante l'esecuzione di queste sezioni, quindi tornare a questo articolo dopo aver creato e configurato il Gestione traffico di Azure.
Quando si raggiunge la sezione Creare un profilo di Gestione traffico, seguire questa procedura:
- Nel passaggio 2 Creare un profilo Gestione traffico seguire questa procedura:
- Salvare il nome univoco del profilo Gestione traffico per Nome, ad esempio tmprofile-ejb120623.
- Salvare il nuovo nome del gruppo di risorse per Gruppo di risorse, ad esempio myResourceGroupTM1.
- Nel passaggio 2 Creare un profilo Gestione traffico seguire questa procedura:
Quando si raggiunge la sezione Aggiungere endpoint Gestione traffico, seguire questa procedura:
- Eseguire questa azione aggiuntiva dopo il passaggio Selezionare il profilo dai risultati della ricerca.
- In Impostazioni selezionare Configurazione.
- Per durata (TTL) dns immettere 10.
- In Impostazioni monitoraggio endpoint immettere /weblogic/ready in Percorso.
- In Impostazioni di failover rapido dell'endpoint usare i valori seguenti:
- Per Ricerca interna immettere 10.
- Per Numero tollerato di errori, immettere 3.
- Per Timeout probe, 5.
- Seleziona Salva. Attendere il completamento.
- Nel passaggio 4 per aggiungere l'endpoint
myPrimaryEndpointprimario, seguire questa procedura:- In Tipo di risorsa di destinazione selezionare Indirizzo IP pubblico.
- Selezionare l'elenco a discesa Scegli indirizzo IP pubblico e immettere l'indirizzo IP di gateway applicazione distribuito nel cluster WLS stati Uniti orientali salvato in precedenza. Dovrebbe essere visualizzata una voce corrispondente. Selezionarlo per Indirizzo IP pubblico.
- Nel passaggio 6 per aggiungere un endpoint di failover/secondario myFailoverEndpoint, seguire questa procedura:
- In Tipo di risorsa di destinazione selezionare Indirizzo IP pubblico.
- Selezionare l'elenco a discesa Scegli indirizzo IP pubblico e immettere l'indirizzo IP di gateway applicazione distribuito nel cluster WLS Stati Uniti occidentali salvato in precedenza. Dovrebbe essere visualizzata una voce corrispondente. Selezionarlo per Indirizzo IP pubblico.
- Aspetta un po' di tempo. Selezionare Aggiorna fino a quando il valore Dello stato di monitoraggio per entrambi gli endpoint è Online.
- Eseguire questa azione aggiuntiva dopo il passaggio Selezionare il profilo dai risultati della ricerca.
Quando si raggiunge la sezione Test Gestione traffico profilo, seguire questa procedura:
- Nella sottosezione Controllare il nome DNS usare il passaggio seguente:
- Nel passaggio 3 salvare il nome DNS del profilo Gestione traffico,
http://tmprofile-ejb120623.trafficmanager.netad esempio .
- Nel passaggio 3 salvare il nome DNS del profilo Gestione traffico,
- Nella sottosezione Visualizza Gestione traffico in azione, seguire questa procedura:
- Nel passaggio 1 e 3 aggiungere /weblogic/ready al nome DNS del profilo Gestione traffico nel Web browser,
http://tmprofile-ejb120623.trafficmanager.net/weblogic/readyad esempio . Verrà visualizzata una pagina vuota senza alcun messaggio di errore. - Dopo aver completato tutti i passaggi, assicurarsi di abilitare l'endpoint primario facendo riferimento al passaggio 2, ma sostituendo Disabilitato con Abilitato. Tornare quindi alla pagina Endpoint .
- Nel passaggio 1 e 3 aggiungere /weblogic/ready al nome DNS del profilo Gestione traffico nel Web browser,
- Nella sottosezione Controllare il nome DNS usare il passaggio seguente:
A questo punto, entrambi gli endpoint sono abilitati e online nel profilo di Gestione traffico. Mantenere aperta la pagina e usarla per monitorare lo stato dell'endpoint in un secondo momento.
Configurare i cluster WLS per la disponibilità elevata e il ripristino di emergenza
In questa sezione vengono configurati cluster WLS per la disponibilità elevata e il ripristino di emergenza.
Preparare l'app di esempio
In questa sezione si compila e si crea un pacchetto di un'applicazione CRUD Java/JakartaEE di esempio distribuita ed eseguita in un secondo momento nei cluster WLS per i test di failover.
L'app usa la persistenza della sessione JDBC di WebLogic Server per archiviare i dati della sessione HTTP. L'origine jdbc/WebLogicCafeDB dati archivia i dati della sessione per abilitare il failover e il bilanciamento del carico in un cluster di WebLogic Servers. Configura uno schema di persistenza per rendere persistenti i dati coffee dell'applicazione nella stessa origine jdbc/WebLogicCafeDBdati.
Usare la procedura seguente per compilare e creare un pacchetto dell'esempio:
Usare i comandi seguenti per clonare il repository di esempio ed eseguire il check-out del tag corrispondente a questo articolo:
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206Se viene visualizzato un messaggio su
Detached HEAD, è possibile ignorare.Usare i comandi seguenti per passare alla directory di esempio e quindi compilare e creare il pacchetto dell'esempio:
cd weblogic-cafe mvn clean package
Quando il pacchetto viene generato correttamente, è possibile trovarlo in parent-path-to-your-local-clone>/azure-café/weblogic-café/target/weblogic-café.war.< Se il pacchetto non viene visualizzato, è necessario risolvere il problema prima di continuare.
Distribuire l'app di esempio
A questo punto, usare la procedura seguente per distribuire l'app di esempio nei cluster, a partire dal cluster primario:
- Aprire adminConsole del cluster in una nuova scheda del Web browser. Accedere alla Console di amministrazione di WebLogic Server con il nome utente e la password dell'amministratore WebLogic salvato in precedenza.
- Individuare La struttura>di dominio wlsd>Deployments nel riquadro di spostamento. Selezionare Distribuzioni.
- Selezionare Blocca e Modifica>installa>Carica file.Select> File.Select File. Selezionare il file weblogic-café.war preparato in precedenza.
- Selezionare Avanti>successivo.> Selezionare
cluster1con l'opzione Tutti i server nel cluster per le destinazioni di distribuzione. Selezionare Next>Finish (Avanti > Fine). Selezionare Attiva modifiche. - Passare alla scheda Controllo e selezionare
weblogic-cafedalla tabella distribuzioni. Selezionare Inizia con l'opzione Manutenzione di tutte le richieste>Sì. Attendere un po' di tempo e aggiornare la pagina fino a quando non viene visualizzato lo stato della distribuzioneweblogic-cafeè Attivo. Passare alla scheda Monitoraggio e verificare che la radice del contesto dell'applicazione distribuita sia /weblogic-café. Mantenere aperta la console di amministrazione di WLS in modo da poterla usare in un secondo momento per un'ulteriore configurazione.
Ripetere gli stessi passaggi in WebLogic Server Administration Console, ma per il cluster secondario nell'area Stati Uniti occidentali.
Aggiornare l'host front-end
Usare la procedura seguente per rendere i cluster WLS consapevoli delle Gestione traffico di Azure. Poiché il Gestione traffico di Azure è il punto di ingresso per le richieste degli utenti, aggiornare l'host front del cluster WebLogic Server al nome DNS del profilo Gestione traffico, a partire dal cluster primario.
- Assicurarsi di aver eseguito l'accesso alla Console di amministrazione di WebLogic Server.
- Passare a Struttura>di dominio wlsd>Environment>Clusters nel riquadro di spostamento. Selezionare Cluster.
- Selezionare
cluster1dalla tabella cluster. - Selezionare Blocca e Modifica>HTTP. Rimuovere il valore corrente per l'host front-end e immettere il nome DNS del profilo di Gestione traffico salvato in precedenza, senza il carattere iniziale
http://, ad esempio tmprofile-ejb120623.trafficmanager.net. Selezionare Salva>attiva modifiche.
Ripetere gli stessi passaggi nella Console di amministrazione di WebLogic Server, ma per il cluster secondario nell'area Stati Uniti occidentali.
Configurare l'archivio log delle transazioni
Configurare quindi l'archivio log delle transazioni JDBC per tutti i server gestiti di cluster, a partire dal cluster primario. Questa procedura è descritta in Uso dei file di log delle transazioni per ripristinare le transazioni.
Usare la procedura seguente nel cluster WLS primario nell'area Stati Uniti orientali:
- Assicurarsi di aver eseguito l'accesso alla Console di amministrazione di WebLogic Server.
- Passare a Struttura>di dominio wlsd>Environment>Servers nel riquadro di spostamento. Selezione dei Server.
- Nella tabella server dovrebbero essere visualizzati i server
msp1,msp2emsp3. - Selezionare
msp1>Blocco servizi>e modifica. In Archivio log delle transazioni selezionare JDBC. - In Tipo origine> dati selezionare .
jdbc/WebLogicCafeDB - Verificare che il valore per Nome prefisso sia TLOG_msp1_, ovvero il valore predefinito. Se il valore è diverso, modificarlo in TLOG_msp1_.
- Seleziona Salva.
- Selezionare Server>
msp2e ripetere gli stessi passaggi, ad eccezione del fatto che il valore predefinito per Nome prefisso è TLOG_msp2_. - Selezionare Server>
msp3e ripetere gli stessi passaggi, ad eccezione del fatto che il valore predefinito per Nome prefisso è TLOG_msp3_. - Selezionare Attiva modifiche.
Ripetere gli stessi passaggi in WebLogic Server Administration Console, ma per il cluster secondario nell'area Stati Uniti occidentali.
Riavviare i server gestiti del cluster primario
Usare quindi la procedura seguente per riavviare tutti i server gestiti del cluster primario per rendere effettive le modifiche:
- Assicurarsi di aver eseguito l'accesso alla Console di amministrazione di WebLogic Server.
- Passare a Struttura>di dominio wlsd>Environment>Servers nel riquadro di spostamento. Selezione dei Server.
- Selezionare la scheda Controllo . Selezionare
msp1,msp2emsp3. Selezionare Arresta con l'opzione Al termine del>lavoro Sì. Selezionare l'icona di aggiornamento. Attendere che lo stato dell'ultima azione sia COMPLETATO. Si noterà che il valore Di stato per i server selezionati è SHUTDOWN. Selezionare di nuovo l'icona di aggiornamento per arrestare il monitoraggio dello stato. - Selezionare
msp1,msp2emsp3di nuovo. Selezionare Avvia>sì. Selezionare l'icona di aggiornamento. Attendere che lo stato dell'ultima azione sia COMPLETATO. Si noterà che il valore Di stato per i server selezionati è IN ESECUZIONE. Selezionare di nuovo l'icona di aggiornamento per arrestare il monitoraggio dello stato.
Arrestare le macchine virtuali nel cluster secondario
A questo punto, usare la procedura seguente per arrestare tutte le macchine virtuali nel cluster secondario per renderla passiva:
- Aprire la portale di Azure home in una nuova scheda del browser e quindi selezionare Tutte le risorse. Nella casella Filtro per qualsiasi campo immettere il nome del gruppo di risorse in cui viene distribuito il cluster secondario, ad esempio wls-cluster-westus-ejb120623.
- Selezionare Tipo è uguale a tutto per aprire il filtro Tipo . In Valore immettere Macchina virtuale. Dovrebbe essere visualizzata una voce corrispondente. Selezionarlo per Valore. Selezionare Applica. Verranno visualizzate 4 macchine virtuali elencate, tra cui
adminVM,mspVM1mspVM2, emspVM3. - Selezionare questa opzione per aprire ognuna delle macchine virtuali. Selezionare Arresta e conferma per ogni macchina virtuale.
- Selezionare l'icona delle notifiche nel portale di Azure per aprire il riquadro Notifiche.
- Monitorare l'evento Arresto della macchina virtuale per ogni macchina virtuale fino a quando il valore non viene arrestato correttamente. Mantenere aperta la pagina in modo da poterla usare per il test di failover in un secondo momento.
Passare ora alla scheda del browser in cui si monitora lo stato degli endpoint del Gestione traffico. Aggiornare la pagina fino a visualizzare che l'endpoint myFailoverEndpoint è Danneggiato e l'endpoint myPrimaryEndpoint è Online.
Nota
Una soluzione di disponibilità elevata/ripristino di emergenza pronta per la produzione potrebbe voler ottenere un RTO inferiore lasciando le macchine virtuali in esecuzione ma arrestando solo il software WLS in esecuzione nelle macchine virtuali. Quindi, in caso di failover, le macchine virtuali sarebbero già in esecuzione e il software WLS richiederebbe meno tempo per l'avvio. Questo articolo ha scelto di arrestare le macchine virtuali perché il software distribuito dal cluster Oracle WebLogic Server in macchine virtuali di Azure avvia automaticamente il software WLS all'avvio delle macchine virtuali.
Verificare l'app
Poiché il cluster primario è operativo, funge da cluster attivo e gestisce tutte le richieste utente indirizzate dal profilo Gestione traffico.
Aprire il nome DNS del profilo Gestione traffico di Azure in una nuova scheda del browser, aggiungendo la radice del contesto /weblogic-café dell'app distribuita, http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafead esempio . Creare un nuovo caffè con nome e prezzo, ad esempio Caffè 1 con prezzo 10. Questa voce viene salvata in modo permanente sia nella tabella dei dati dell'applicazione che nella tabella di sessione del database. L'interfaccia utente visualizzata dovrebbe essere simile alla schermata seguente:

Se l'interfaccia utente non è simile, risolvere e risolvere il problema prima di continuare.
Mantenere aperta la pagina in modo da poterla usare per i test di failover in un secondo momento.
Failover di test da primario a secondario
Per testare il failover, eseguire manualmente il failover del server di database primario e del cluster nel server di database e nel cluster secondario e quindi eseguire il failback usando il portale di Azure in questa sezione.
Failover nel sito secondario
Prima di tutto, usare la procedura seguente per arrestare le macchine virtuali nel cluster primario:
- Trovare il nome del gruppo di risorse in cui viene distribuito il cluster WLS primario, ad esempio wls-cluster-eastus-ejb120623. Seguire quindi la procedura descritta nella sezione Arrestare le macchine virtuali nel cluster secondario, ma modificare il gruppo di risorse di destinazione nel cluster WLS primario per arrestare tutte le macchine virtuali in tale cluster.
- Passare alla scheda del browser del Gestione traffico, aggiornare la pagina fino a quando non viene visualizzato il valore di stato Monitoraggio dell'endpoint myPrimaryEndpoint diventa danneggiato.
- Passare alla scheda del browser dell'app di esempio e aggiornare la pagina. Verrà visualizzato il timeout del gateway 504 o 502 Gateway non valido perché nessuno degli endpoint è accessibile.
Usare quindi i passaggi seguenti per eseguire il failover del database SQL di Azure dal server primario al server secondario:
- Passare alla scheda del browser del gruppo di failover database SQL di Azure.
- Selezionare Failover>Sì.
- Attendere il completamento.
Usare quindi la procedura seguente per avviare tutti i server nel cluster secondario:
- Passare alla scheda del browser in cui sono state arrestate tutte le macchine virtuali nel cluster secondario.
- Selezionare la macchina virtuale
adminVM. Selezionare Inizio. - Monitorare l'evento Avvio della macchina
adminVMvirtuale nel riquadro Notifiche e attendere che il valore diventi Macchina virtuale avviata. - Passare alla scheda del browser della Console di amministrazione di WebLogic Server per il cluster secondario, quindi aggiornare la pagina fino a visualizzare la pagina iniziale per l'accesso.
- Tornare alla scheda del browser in cui sono elencate tutte le macchine virtuali nel cluster secondario. Per le macchine virtuali
mspVM1,mspVM2emspVM3, selezionare ognuna di esse per aprirla e quindi selezionare Avvia. - Per le macchine virtuali
mspVM1,mspVM2emspVM3, monitorare l'evento Avvio della macchina virtuale nel riquadro Notifiche e attendere che i valori diventino Macchina virtuale avviata.
Infine, usare la procedura seguente per verificare l'app di esempio dopo che l'endpoint myFailoverEndpoint si trova nello stato Online :
Passare alla scheda del browser del Gestione traffico, quindi aggiornare la pagina fino a quando non viene visualizzato il valore di stato Monitoraggio dell'endpoint
myFailoverEndpointpassa allo stato Online.Passare alla scheda del browser dell'app di esempio e aggiornare la pagina. Verranno visualizzati gli stessi dati salvati in modo permanente nella tabella dei dati dell'applicazione e nella tabella di sessione visualizzata nell'interfaccia utente, come illustrato nello screenshot seguente:
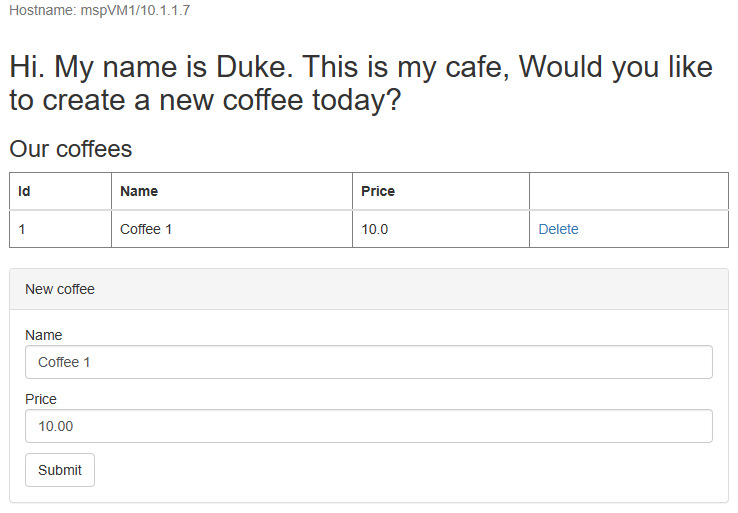
Se non si osserva questo comportamento, la Gestione traffico richiede tempo per aggiornare IL DNS in modo che punti al sito di failover. Il problema potrebbe anche essere che il browser ha memorizzato nella cache il risultato della risoluzione dei nomi DNS che punta al sito non riuscito. Attendere un po' e aggiornare di nuovo la pagina.
Nota
Una soluzione di disponibilità elevata/ripristino di emergenza pronta per la produzione tiene conto della copia continua della configurazione WLS dal cluster primario ai cluster secondari in base a una pianificazione regolare. Per informazioni su come eseguire questa operazione, vedere i riferimenti alla documentazione di Oracle alla fine di questo articolo.
Per automatizzare il failover, è consigliabile usare gli avvisi per le metriche Gestione traffico e Automazione di Azure. Per altre informazioni, vedere la sezione Avvisi sulle metriche Gestione traffico di Gestione traffico metriche e avvisi e Usare un avviso per attivare un runbook Automazione di Azure.
Eseguire il failback nel sito primario
Usare gli stessi passaggi della sezione Failover nel sito secondario per eseguire il failback nel sito primario, incluso il server di database e il cluster, ad eccezione delle differenze seguenti:
- Arrestare prima di tutto le macchine virtuali nel cluster secondario. Si noterà che l'endpoint
myFailoverEndpointdiventa Danneggiato. - Eseguire quindi il failover del database SQL di Azure dal server secondario al server primario.
- Avviare quindi tutti i server nel cluster primario.
- Infine, verificare l'app di esempio dopo che l'endpoint
myPrimaryEndpointè Online.
Pulire le risorse
Se non si intende continuare a usare i cluster WLS e altri componenti, seguire questa procedura per eliminare i gruppi di risorse per pulire le risorse usate in questa esercitazione:
- Immettere il nome del gruppo di risorse di database SQL di Azure server (ad esempio ,
myResourceGroup) nella casella di ricerca nella parte superiore del portale di Azure e selezionare il gruppo di risorse corrispondente nei risultati della ricerca. - Selezionare Elimina gruppo di risorse.
- In Immettere il nome del gruppo di risorse per confermare l'eliminazione immettere il nome del gruppo di risorse.
- Selezionare Elimina.
- Ripetere i passaggi da 1 a 4 per il gruppo di risorse del Gestione traffico,
myResourceGroupTM1ad esempio . - Ripetere i passaggi da 1 a 4 per il gruppo di risorse del cluster WLS primario,
wls-cluster-eastus-ejb120623ad esempio . - Ripetere i passaggi da 1 a 4 per il gruppo di risorse del cluster WLS secondario,
wls-cluster-westus-ejb120623ad esempio .
Passaggi successivi
In questa esercitazione è stata configurata una soluzione di disponibilità elevata/ripristino di emergenza costituita da un livello di infrastruttura di applicazione attivo-passivo con un livello di database attivo-passivo e in cui entrambi i livelli si estendono su due siti geograficamente diversi. Nel primo sito, sia il livello di infrastruttura dell'applicazione che il livello di database sono attivi. Nel secondo sito, il dominio secondario viene arrestato e il database secondario è in standby.
Continuare a esplorare i riferimenti seguenti per altre opzioni per creare soluzioni di disponibilità elevata/ripristino di emergenza ed eseguire WLS in Azure: