Eseguire test di migrazione
Il team è ora pronto per iniziare il processo di avvio di un'esecuzione di test della migrazione e infine una migrazione completa di produzione. In questa fase vengono illustrati i passaggi finali per accodare una migrazione oltre ad altre attività che in genere si presentano alla fine del progetto di migrazione.

Prerequisiti
Completare la fase di esecuzione del test di preparazione prima di iniziare una migrazione dell'esecuzione del test.
Convalidare una raccolta
Convalidare ogni raccolta di cui si vuole eseguire la migrazione ad Azure DevOps Services. Il passaggio di convalida esamina vari aspetti della raccolta, tra cui, ad esempio, dimensioni, regole di confronto, identità e processi.
Eseguire la convalida usando lo strumento di migrazione dei dati.
Scaricare lo strumento di migrazione dei dati.
Copiare il file ZIP in uno dei livelli dell'applicazione Azure DevOps Server.
Decomprimere il file . È anche possibile eseguire lo strumento da un computer diverso senza Azure DevOps Server installato, purché il computer possa connettersi al database di configurazione dell'istanza di Azure DevOps Server.
Aprire una finestra del prompt dei comandi nel server e immettere un comando cd per passare alla directory in cui è archiviato lo strumento di migrazione dei dati. Esaminare il contenuto della Guida per lo strumento.
a. Per visualizzare la Guida e le linee guida di primo livello, eseguire il comando seguente.
Migrator /helpb. Visualizzare il testo della Guida per il comando.
Migrator validate /helpLa prima volta che si convalida una raccolta, il comando deve avere la struttura semplice seguente.
Migrator validate /collection:{collection URL} /tenantDomainName:{name} /region:{region}Dove
{name}fornisce il nome del tenant di Microsoft Entra, ad esempio, per l'esecuzione in DefaultCollection e nel tenant fabrikam , il comando sarà simile all'esempio seguente.Migrator validate /collection:http://localhost:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region}Per eseguire lo strumento da un computer diverso da Azure DevOps Server, è necessario il parametro /connectionString . Il parametro stringa di connessione punta al database di configurazione di Azure DevOps Server. Ad esempio, se il comando convalidato viene eseguito dall'azienda Fabrikam, il comando sarà simile al seguente.
Migrator validate /collection:http://fabrikam:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region} /connectionString:"Data Source=fabrikam;Initial Catalog=Configuration;Integrated Security=True"Importante
Lo strumento di migrazione dei dati non modifica dati o strutture nella raccolta. Legge la raccolta solo per identificare i problemi.
Al termine della convalida, è possibile visualizzare i file di log e i risultati.
Durante la convalida, viene visualizzato un avviso se alcune pipeline contengono regole di conservazione per pipeline. Azure DevOps Services usa un modello di conservazione basato su progetto e non supporta i criteri di conservazione per pipeline. Se si procede con la migrazione, i criteri non vengono trasportati alla versione ospitata. Si applicano invece i criteri di conservazione a livello di progetto predefiniti. Conservare le compilazioni importanti per evitare la perdita.
Dopo aver superato tutte le convalide, è possibile passare al passaggio successivo del processo di migrazione. Se lo strumento di migrazione dei dati contrassegna eventuali errori, correggerli prima di procedere. Per indicazioni sulla correzione degli errori di convalida, vedere Risolvere gli errori di migrazione e migrazione.
Importare file di log
Quando si apre la directory di log, è possibile notare diversi file di registrazione.
Il file di log principale è denominato DataMigrationTool.log. Contiene informazioni dettagliate su tutto ciò che è stato eseguito. Per semplificare l'attenzione su aree specifiche, viene generato un log per ogni operazione di convalida principale.
Ad esempio, se TfsMigrator segnala un errore nel passaggio "Convalida dei processi di progetto", è possibile aprire il file di ProjectProcessMap.log per visualizzare tutti gli elementi eseguiti per tale passaggio invece di dover scorrere l'intero log.
Esaminare il file TryMatchOobProcesses.log solo se si sta tentando di eseguire la migrazione dei processi di progetto per usare il modello ereditato. Se non si vuole usare il modello ereditato, è possibile ignorare questi errori, perché non impediscono l'importazione in Azure DevOps Services. Per altre informazioni, vedere La fase di convalida della migrazione.
Generare file di migrazione
Lo strumento di migrazione dei dati ha convalidato la raccolta e restituisce un risultato di "Tutte le convalide della raccolta passate". Prima di portare una raccolta offline per eseguirne la migrazione, generare i file di migrazione. Quando si esegue il prepare comando , si generano due file di migrazione:
- IdentityMapLog.csv: delinea la mappa delle identità tra Active Directory e Microsoft Entra ID.
- migration.json: richiede di compilare la specifica di migrazione da usare per avviare la migrazione.
Comando Prepara
Il prepare comando consente di generare i file di migrazione necessari. Essenzialmente, questo comando analizza la raccolta per trovare un elenco di tutti gli utenti per popolare il log della mappa delle identità, IdentityMapLog.csv e quindi tenta di connettersi all'ID di Microsoft Entra per trovare la corrispondenza di ogni identità. A tale scopo, l'azienda deve usare lo strumento Microsoft Entra Connect (noto in precedenza come strumento di sincronizzazione directory, strumento di sincronizzazione directory o strumento di DirSync.exe).
Se la sincronizzazione della directory è configurata, lo strumento di migrazione dei dati deve trovare le identità corrispondenti e contrassegnarle come attive. Se non sono presenti corrispondenze, l'identità viene contrassegnata come Cronologia nel log della mappa delle identità, quindi è necessario esaminare il motivo per cui l'utente non è incluso nella sincronizzazione della directory. Il file delle specifiche di migrazione, migration.json, deve essere popolato prima della migrazione.
A differenza del validate comando, prepare richiede una connessione Internet, perché deve connettersi all'ID Microsoft Entra per popolare il file di log della mappa delle identità. Se l'istanza di Azure DevOps Server non ha accesso a Internet, eseguire lo strumento da un computer che esegue questa operazione. Finché è possibile trovare un computer con una connessione Intranet all'istanza di Azure DevOps Server e una connessione Internet, è possibile eseguire questo comando. Per assistenza con il prepare comando, eseguire il comando seguente:
Migrator prepare /help
Nella documentazione della Guida sono incluse istruzioni ed esempi per l'esecuzione del Migrator comando dall'istanza di Azure DevOps Server stessa e da un computer remoto. Se si esegue il comando da uno dei livelli di applicazione dell'istanza di Azure DevOps Server, il comando deve avere la struttura seguente:
Migrator prepare /collection:{collection URL} /tenantDomainName:{name} /region:{region}
Migrator prepare /collection:{collection URL} /tenantDomainName:{name} /region:{region} /connectionString:"Data Source={sqlserver};Initial Catalog=Configuration;Integrated Security=True"
Il parametro connectionString è un puntatore al database di configurazione dell'istanza di Azure DevOps Server. Ad esempio, se la società Fabrikam esegue il prepare comando , il comando sarà simile all'esempio seguente:
Migrator prepare /collection:http://fabrikam:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region} /connectionString:"Data Source=fabrikam;Initial Catalog=Configuration;Integrated Security=True"
Quando lo strumento di migrazione dei dati esegue il prepare comando , esegue una convalida completa per assicurarsi che non siano state apportate modifiche alla raccolta dopo l'ultima convalida completa. Se vengono rilevati nuovi problemi, non vengono generati file di migrazione.
Poco dopo l'avvio del comando, viene visualizzata una finestra di accesso di Microsoft Entra. Accedere con un'identità appartenente al dominio tenant, specificato nel comando . Assicurarsi che il tenant di Microsoft Entra specificato sia quello con cui si vuole eseguire il backup dell'organizzazione futura. Nell'esempio di Fabrikam, un utente immette credenziali simili allo screenshot di esempio seguente.
Importante
Non usare un tenant Microsoft Entra di test per una migrazione di test e il tenant Microsoft Entra di produzione per l'esecuzione di produzione. L'uso di un tenant di Microsoft Entra di test può causare problemi di migrazione delle identità quando si inizia l'esecuzione di produzione con il tenant Microsoft Entra di produzione dell'organizzazione.
Quando si esegue correttamente il prepare comando nello strumento di migrazione dei dati, nella finestra dei risultati viene visualizzato un set di log e due file di migrazione. Nella directory di log trovare una cartella logs e due file:
- migration.json è il file di specifica della migrazione. Ti consigliamo di dedicare del tempo per compilarlo.
- IdentityMapLog.csv contiene il mapping generato di Active Directory alle identità di Microsoft Entra. Esaminarlo per verificarne la completezza prima di avviare una migrazione.
I due file sono descritti in modo più dettagliato nelle sezioni successive.
File di specifica della migrazione
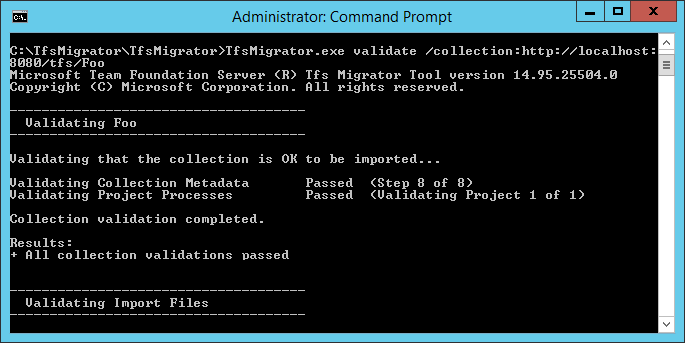
La specifica di migrazione, migration.json, è un file JSON che fornisce le impostazioni di migrazione. Include il nome dell'organizzazione desiderato, le informazioni sull'account di archiviazione e altre informazioni. La maggior parte dei campi viene popolata automaticamente e alcuni campi richiedono l'input prima di tentare una migrazione.
I campi visualizzati del file migration.json e le azioni necessarie sono descritti nella tabella seguente:
| Campo | Descrizione | Azione richiesta |
|---|---|---|
| Origine | Informazioni sul percorso e sui nomi dei file di dati di origine usati per la migrazione. | Nessuna azione richiesta. Esaminare le informazioni per le azioni del sottocampo da seguire. |
| Ufficio | Chiave di firma di accesso condiviso all'account di archiviazione di Azure che ospita il pacchetto dell'applicazione livello dati (DACPAC). | Nessuna azione richiesta. Questo campo è trattato in un passaggio successivo. |
| File | Nomi dei file contenenti i dati di migrazione. | Nessuna azione richiesta. Esaminare le informazioni per le azioni del sottocampo da seguire. |
| DACPAC | File DACPAC che crea un pacchetto del database di raccolta da usare per inserire i dati durante la migrazione. | Nessuna azione richiesta. In un passaggio successivo si crea questo file usando la raccolta e quindi la si carica in un account di archiviazione di Azure. Aggiornare il file in base al nome usato quando viene generato più avanti in questo processo. |
| Destinazione | Proprietà della nuova organizzazione in cui eseguire la migrazione. | Nessuna azione richiesta. Esaminare le informazioni per le azioni del sottocampo da seguire. |
| Nome | Nome dell'organizzazione da creare durante la migrazione. | Specificare un nome. Il nome può essere modificato rapidamente in un secondo momento dopo il completamento della migrazione. NOTA: non creare un'organizzazione con questo nome prima di eseguire la migrazione. L'organizzazione viene creata come parte del processo di migrazione. |
| ImportType | Tipo di migrazione da eseguire. | Nessuna azione richiesta. In un passaggio successivo selezionare il tipo di migrazione da eseguire. |
| Dati di convalida | Informazioni necessarie per favorire l'esperienza di migrazione. | Lo strumento di migrazione dei dati genera la sezione "ValidationData". Contiene informazioni utili per favorire l'esperienza di migrazione. Non* modificare i valori in questa sezione o l'avvio della migrazione potrebbe non riuscire. |
Dopo aver completato il processo precedente, dovrebbe essere presente un file simile all'esempio seguente.
Nell'immagine precedente, lo strumento di pianificazione della migrazione di Fabrikam ha aggiunto il nome dell'organizzazione fabrikam-import e l'opzione CUS (Central Stati Uniti) come posizione geografica per la migrazione. Altri valori sono stati lasciati così come devono essere modificati poco prima che lo strumento di pianificazione abbia portato offline la raccolta per la migrazione.
Nota
Le importazioni di esecuzione dei test hanno un '-dryrun' aggiunto automaticamente alla fine del nome dell'organizzazione, che è possibile modificare dopo la migrazione.
Aree di Azure supportate per la migrazione
Azure DevOps Services è disponibile in diverse località geografiche di Azure. Tuttavia, non tutte le posizioni in cui Azure DevOps Services è disponibile sono supportate per la migrazione. La tabella seguente elenca le località geografiche di Azure che è possibile selezionare per la migrazione. È incluso anche il valore che è necessario inserire nel file delle specifiche di migrazione per specificare tale area geografica per la migrazione.
| Posizione geografica | Località geografica di Azure | Valore della specifica di importazione |
|---|---|---|
| Stati Uniti | Stati Uniti centrale | CUS |
| Europa | Europa occidentale | WEU |
| Regno Unito | Regno Unito meridionale | UKS |
| Australia | Australia orientale | EAU |
| America del Sud | Brasile meridionale | SBR |
| Asia/Pacifico | India meridionale | MA |
| Asia/Pacifico | Asia sud-orientale (Singapore) | SEA |
| Canada | Canada centrale | CC |
Log della mappa delle identità
Il log della mappa delle identità è di uguale importanza ai dati effettivi di cui si esegue la migrazione ad Azure DevOps Services. Durante la revisione del file, è importante comprendere il funzionamento della migrazione delle identità e quali potrebbero comportare i potenziali risultati. Quando si esegue la migrazione di un'identità, può diventare attiva o cronologica. Le identità attive possono accedere ad Azure DevOps Services, ma le identità cronologiche non possono.
Identità attive
Le identità attive fanno riferimento alle identità utente in Azure DevOps Services dopo la migrazione. In Azure DevOps Services queste identità vengono concesse in licenza e vengono visualizzate come utenti dell'organizzazione. Le identità sono contrassegnate come attive nella colonna Stato importazione prevista nel file di log della mappa delle identità.
Identità cronologiche
Viene eseguito il mapping delle identità cronologiche, ad esempio nella colonna Stato importazione prevista nel file di log della mappa delle identità. Anche le identità senza una voce di riga nel file diventano cronologiche. Un esempio di identità senza una voce di riga potrebbe essere un dipendente che non lavora più in una società.
A differenza delle identità attive, le identità cronologiche:
- Non avere accesso a un'organizzazione dopo la migrazione.
- Non avere licenze.
- Non visualizzare come utenti dell'organizzazione. Tutto ciò che persiste è la nozione del nome dell'identità nell'organizzazione, in modo che la relativa cronologia possa essere eseguita in un secondo momento. È consigliabile usare le identità cronologiche per gli utenti che non lavorano più nella società o che non necessitano di ulteriore accesso all'organizzazione.
Nota
Dopo l'importazione di un'identità come cronologica, non può diventare attiva.
Informazioni sul file di log della mappa delle identità
Il file di log della mappa delle identità è simile all'esempio illustrato di seguito:

Le colonne nel file di log delle mappe delle identità sono descritte nella tabella seguente:
L'utente e l'amministratore di Microsoft Entra devono analizzare gli utenti contrassegnati come No Match Found (Controlla sincronizzazione ID Microsoft Entra) per capire perché non fanno parte della sincronizzazione Microsoft Entra Connect.
| Colonna | Descrizione |
|---|---|
| Active Directory: utente (Azure DevOps Server) | Nome visualizzato descrittivo usato dall'identità in Azure DevOps Server. Questo nome semplifica l'identificazione della linea nella mappa a cui fa riferimento l'utente. |
| Active Directory: Identificatore di sicurezza | Identificatore univoco per l'identità Active Directory locale in Azure DevOps Server. Questa colonna viene utilizzata per identificare gli utenti nella raccolta. |
| MICROSOFT Entra ID: utente di importazione previsto (Azure DevOps Services) | L'indirizzo di accesso previsto dell'utente presto attivo corrispondente o Nessuna corrispondenza trovata (Controlla sincronizzazione ID Entra Microsoft), che indica che l'identità è stata persa durante la sincronizzazione microsoft Entra ID e viene importata come cronologica. |
| Stato importazione previsto | Stato di migrazione utente previsto: Attivo se esiste una corrispondenza tra Active Directory e Microsoft Entra ID oppure Cronologia se non esiste una corrispondenza. |
| Data di convalida | Ora dell'ultima convalida del log della mappa delle identità. |
Durante la lettura del file, si noti se il valore nella colonna Stato importazione prevista è Attivo o Cronologico. Active indica che l'identità in questa riga viene mappata correttamente durante la migrazione diventa attiva. Cronologico significa che le identità diventano cronologiche durante la migrazione. È importante esaminare il file di mapping generato per completezza e correttezza.
Importante
La migrazione non riesce se si verificano modifiche importanti alla sincronizzazione dell'ID di sicurezza di Microsoft Entra Connect tra i tentativi di migrazione. È possibile aggiungere nuovi utenti tra esecuzioni di test e apportare correzioni per assicurarsi che le identità cronologiche importate in precedenza diventino attive. Tuttavia, non è possibile modificare un utente esistente importato in precedenza come attivo. In questo modo la migrazione non riesce. Un esempio di modifica potrebbe essere il completamento di una migrazione dell'esecuzione di test, l'eliminazione di un'identità dall'ID Microsoft Entra importato attivamente, la ricreazione di un nuovo utente nell'ID Di Microsoft Entra per la stessa identità e quindi il tentativo di un'altra migrazione. In questo caso, una migrazione delle identità attiva tenta tra Active Directory e l'identità Microsoft Entra appena creata, ma causa un errore di migrazione.
Esaminare le identità corrispondenti correttamente. Sono presenti tutte le identità previste? Gli utenti sono mappati all'identità corretta di Microsoft Entra?
Se è necessario modificare i valori, contattare l'amministratore di Microsoft Entra per verificare che l'identità Active Directory locale faccia parte della sincronizzazione con Microsoft Entra ID e configurare correttamente. Per altre informazioni, vedere Integrare le identità locali con Microsoft Entra ID.
Esaminare quindi le identità etichettate come cronologiche. Questa etichettatura implica che non è stato possibile trovare un'identità Microsoft Entra corrispondente, per uno dei motivi seguenti:
- L'identità non è configurata per la sincronizzazione tra Active Directory locale e Microsoft Entra ID.
- L'identità non viene ancora popolata nell'ID Microsoft Entra ( ad esempio, c'è un nuovo dipendente).
- L'identità non esiste nell'istanza di Microsoft Entra.
- L'utente proprietario di tale identità non funziona più all'interno dell'azienda.
Per risolvere i primi tre motivi, configurare l'identità Active Directory locale prevista per la sincronizzazione con Microsoft Entra ID. Per altre informazioni, vedere Integrare le identità locali con Microsoft Entra ID. È necessario configurare ed eseguire Microsoft Entra Connect per importare le identità come attive in Azure DevOps Services.
È possibile ignorare il quarto motivo, perché i dipendenti che non si trovano più nella società devono essere importati come cronologici.
Identità cronologiche (piccoli team)
Nota
La strategia di migrazione delle identità proposta in questa sezione deve essere considerata solo da piccoli team.
Se Microsoft Entra Connect non è configurato, tutti gli utenti nel file di log della mappa delle identità vengono contrassegnati come cronologici. L'esecuzione di una migrazione in questo modo comporta l'importazione di tutti gli utenti come cronologici. È consigliabile configurare Microsoft Entra Connect per assicurarsi che gli utenti vengano importati come attivi.
L'esecuzione di una migrazione con tutte le identità cronologiche ha conseguenze che devono essere considerate attentamente. Solo i team con pochi utenti e per i quali il costo di configurazione di Microsoft Entra Connect è considerato troppo elevato.
Per eseguire la migrazione di tutte le identità come cronologiche, seguire i passaggi descritti nelle sezioni successive. Quando si accoda una migrazione, l'identità usata per accodare la migrazione viene avviata nell'organizzazione come proprietario dell'organizzazione. Tutti gli altri utenti vengono importati come cronologici. I proprietari dell'organizzazione possono quindi aggiungere di nuovo gli utenti usando l'identità Microsoft Entra. Gli utenti aggiunti vengono considerati come nuovi utenti. Non sono proprietari della loro storia e non c'è modo di replicare questa storia all'identità di Microsoft Entra. Tuttavia, gli utenti possono comunque cercare la cronologia delle premigration cercando \<domain>\<Active Directory username>.
Lo strumento di migrazione dei dati visualizza un avviso se rileva lo scenario completo delle identità cronologiche. Se si decide di arrestare questo percorso di migrazione, è necessario fornire il consenso nello strumento alle limitazioni.
Sottoscrizioni di Visual Studio
Lo strumento di migrazione dei dati non riesce a rilevare le sottoscrizioni di Visual Studio (in precedenza note come vantaggi MSDN) quando genera il file di log della mappa delle identità. È invece consigliabile applicare la funzionalità di aggiornamento automatico delle licenze dopo la migrazione. Se gli account aziendali degli utenti sono collegati correttamente, Azure DevOps Services applica automaticamente i vantaggi della sottoscrizione di Visual Studio al primo accesso dopo la migrazione. Non vengono addebitati costi per le licenze assegnate durante la migrazione, in modo da poter gestire in modo sicuro le sottoscrizioni in un secondo momento.
Non è necessario ripetere una migrazione di esecuzione dei test se le sottoscrizioni di Visual Studio degli utenti non vengono aggiornate automaticamente in Azure DevOps Services. Il collegamento della sottoscrizione di Visual Studio si verifica all'esterno dell'ambito di una migrazione. Se l'account aziendale è collegato correttamente prima o dopo la migrazione, le licenze degli utenti vengono aggiornate automaticamente al successivo accesso. Dopo l'aggiornamento delle licenze, la volta successiva che si esegue una migrazione, gli utenti vengono aggiornati automaticamente al primo accesso all'organizzazione.
Preparare la migrazione
Ora si è pronti per l'esecuzione della migrazione dell'esecuzione del test. Pianificare il tempo di inattività con il team per portare offline la raccolta per la migrazione. Quando si accetta un orario per eseguire la migrazione, caricare gli asset necessari generati e una copia del database in Azure. La preparazione per la migrazione è costituita dai cinque passaggi seguenti.
Passaggio 1: Portare la raccolta offline e scollegarla.
Passaggio 2: Generare un file DACPAC dalla raccolta di cui si intende eseguire la migrazione.
Passaggio 3: Caricare il file DACPAC e i file di migrazione in un account di archiviazione di Azure.
Passaggio 4: Generare un token di firma di accesso condiviso per accedere all'account di archiviazione.
Passaggio 5: Completare la specifica della migrazione.
Nota
Prima di eseguire una migrazione di produzione, è consigliabile completare una migrazione di esecuzione dei test. Con un'esecuzione di test, è possibile verificare che il processo di migrazione funzioni per la raccolta e che non siano presenti forme di dati univoche che potrebbero causare un errore di migrazione di produzione.
Passaggio 1: Scollegare la raccolta
La rimozione della raccolta è un passaggio fondamentale del processo di migrazione. I dati di identità per la raccolta si trovano nel database di configurazione dell'istanza di Azure DevOps Server mentre la raccolta è collegata e online. Quando una raccolta viene disconnessa dall'istanza di Azure DevOps Server, accetta una copia di tali dati di identità e la inserisce nella raccolta per il trasporto. Senza questi dati, non è possibile eseguire la parte identity della migrazione.
Suggerimento
È consigliabile mantenere la raccolta disconnessa fino al completamento della migrazione, perché non esiste un modo per eseguire la migrazione delle modifiche apportate durante la migrazione. Ricollegare la raccolta dopo aver eseguito il backup per la migrazione, quindi non si è preoccupati di avere i dati più recenti per questo tipo di migrazione. Per evitare del tutto il tempo offline, è anche possibile scegliere di usare uno scollegamento offline per le esecuzioni di test.
È importante valutare il costo della scelta per incorrere in un tempo di inattività zero per un'esecuzione di test. Richiede l'esecuzione di backup del database di raccolta e configurazione, il ripristino in un'istanza DI SQL e la creazione di un backup scollegato. Un'analisi dei costi potrebbe dimostrare che la fine del backup scollegato richiede solo poche ore di inattività.
Passaggio 2: Generare un file DACPAC
I DACPAC offrono un metodo rapido e relativamente semplice per lo spostamento delle raccolte in Azure DevOps Services. Tuttavia, dopo che le dimensioni di un database di raccolta superano una determinata soglia, i vantaggi dell'uso di un pacchetto di applicazione livello dati iniziano a diminuire.
Nota
Se lo strumento di migrazione dei dati visualizza un avviso che indica che non è possibile usare il metodo DACPAC, è necessario eseguire la migrazione usando il metodo macchina virtuale (VM) di SQL Azure. Ignorare i passaggi da 2 a 5 in questo caso e seguire le istruzioni nella fase di preparazione dell'esecuzione dei test, nella sezione Eseguire la migrazione di raccolte di grandi dimensioni e quindi continuare a determinare il tipo di migrazione. Se lo strumento di migrazione dei dati non visualizza un avviso, usare il metodo DACPAC descritto in questo passaggio.
DACPAC è una funzionalità di SQL Server che consente di creare un pacchetto di database in un singolo file e distribuirlo in altre istanze di SQL Server. Un file DACPAC può anche essere ripristinato direttamente in Azure DevOps Services, in modo da poterlo usare come metodo di creazione del pacchetto per ottenere i dati della raccolta nel cloud.
Importante
- Quando si usa SqlPackage.exe, è necessario usare la versione di .NET Framework di SqlPackage.exe per preparare il file DACPAC. Il programma di installazione MSI deve essere usato per installare la versione di .NET Framework di SqlPackage.exe. Non usare l'interfaccia della riga di comando dotnet o le versioni di .zip (Windows .NET 6) di SqlPackage.exe perché tali versioni possono generare DACPAC incompatibili con Azure DevOps Services.
- La versione 161 di SqlPackage crittografa le connessioni di database per impostazione predefinita e potrebbe non connettersi. Se viene visualizzato un errore del processo di accesso, aggiungere
;Encrypt=False;TrustServerCertificate=Truealla stringa di connessione dell'istruzione SqlPackage.
Scaricare e installare SqlPackage.exe usando il programma di installazione MSI più recente dalle note sulla versione di SqlPackage.
Dopo aver usato il programma di installazione MSI, SqlPackage.exe viene installato in un percorso simile a %PROGRAMFILES%\Microsoft SQL Server\160\DAC\bin\.
Quando si genera un pacchetto di applicazione livello dati, tenere presenti due considerazioni: il disco in cui viene salvato il file DACPAC e lo spazio su disco nel computer che genera il pacchetto di applicazione livello dati. Si vuole assicurarsi di disporre di spazio su disco sufficiente per completare l'operazione.
Durante la creazione del pacchetto, SqlPackage.exe archivia temporaneamente i dati dalla raccolta nella directory temporanea nell'unità C del computer da cui si sta avviando la richiesta di creazione del pacchetto.
È possibile che l'unità C sia troppo piccola per supportare la creazione di un pacchetto daCPAC. È possibile stimare la quantità di spazio necessaria cercando la tabella più grande nel database di raccolta. I DACPAC vengono creati una tabella alla volta. Il requisito di spazio massimo per eseguire la generazione equivale approssimativamente alle dimensioni della tabella più grande nel database della raccolta. Se si salva il file daCPAC generato nell'unità C, prendere in considerazione le dimensioni del database di raccolta come indicato nel file DataMigrationTool.log da un'esecuzione di convalida.
Il file DataMigrationTool.log fornisce un elenco delle tabelle più grandi della raccolta ogni volta che viene eseguito il comando. Per un esempio di dimensioni di tabella per una raccolta, vedere l'output seguente. Confrontare le dimensioni della tabella più grande con lo spazio disponibile nell'unità che ospita la directory temporanea.
Importante
Prima di procedere con la generazione di un file DACPAC, assicurarsi che la raccolta sia scollegata.
[Info @08:23:59.539] Table name Size in MB
[Info @08:23:59.539] dbo.tbl_Content 38984
[Info @08:23:59.539] dbo.tbl_LocalVersion 1935
[Info @08:23:59.539] dbo.tbl_Version 238
[Info @08:23:59.539] dbo.tbl_FileReference 85
[Info @08:23:59.539] dbo.Rules 68
[Info @08:23:59.539] dbo.tbl_FileMetadata 61
Assicurarsi che l'unità che ospita la directory temporanea abbia almeno lo spazio disponibile. In caso contrario, è necessario reindirizzare la directory temporanea impostando una variabile di ambiente.
SET TEMP={location on disk}
Un'altra considerazione è la posizione in cui vengono salvati i dati daCPAC. Puntare la posizione salvata a un'unità remota lontana potrebbe comportare tempi di generazione più lunghi. Se un'unità veloce, ad esempio un'unità SSD ,è disponibile in locale, è consigliabile specificare come destinazione l'unità come percorso di salvataggio daCPAC. In caso contrario, è sempre più veloce usare un disco nel computer in cui risiede il database di raccolta anziché un'unità remota.
Dopo aver identificato il percorso di destinazione per il file DACPAC e aver verificato che lo spazio sia sufficiente, è possibile generare il file DACPAC.
Aprire una finestra del prompt dei comandi e passare al percorso SqlPackage.exe. Per generare il file DACPAC, sostituire i valori segnaposto con i valori necessari e quindi eseguire il comando seguente:
SqlPackage.exe /sourceconnectionstring:"Data Source={database server name};Initial Catalog={Database Name};Integrated Security=True" /targetFile:{Location & File name} /action:extract /p:ExtractAllTableData=true /p:IgnoreUserLoginMappings=true /p:IgnorePermissions=true /p:Storage=Memory
- Origine dati: istanza di SQL Server che ospita il database di raccolta di Azure DevOps Server.
- Catalogo iniziale: nome del database di raccolta.
- targetFile: il percorso sul disco e il nome del file DACPAC.
Nell'esempio seguente viene illustrato un comando di generazione DACPAC in esecuzione nel livello dati di Azure DevOps Server stesso:
SqlPackage.exe /sourceconnectionstring:"Data Source=localhost;Initial Catalog=Foo;Integrated Security=True" /targetFile:C:\DACPAC\Foo.dacpac /action:extract /p:ExtractAllTableData=true /p:IgnoreUserLoginMappings=true /p:IgnorePermissions=true /p:Storage=Memory
L'output del comando è un file DACPAC, generato dal database di raccolta Foo denominato Foo.dacpac.
Configurare la raccolta per la migrazione
Dopo il ripristino del database di raccolta nella macchina virtuale di Azure, configurare un accesso SQL per consentire ad Azure DevOps Services di connettersi al database per eseguire la migrazione dei dati. Questo accesso consente solo l'accesso in lettura a un singolo database.
Per iniziare, aprire SQL Server Management Studio nella macchina virtuale e quindi aprire una nuova finestra di query sul database da importare.
Impostare il ripristino del database su semplice:
ALTER DATABASE [<Database name>] SET RECOVERY SIMPLE;
Creare un accesso SQL per il database e assegnare l'accesso a 'TFSEXECROLE':
USE [<database name>]
CREATE LOGIN <pick a username> WITH PASSWORD = '<pick a password>'
CREATE USER <username> FOR LOGIN <username> WITH DEFAULT_SCHEMA=[dbo]
EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='<username>'
Dopo l'esempio di Fabrikam, i due comandi SQL sono simili all'esempio seguente:
ALTER DATABASE [Fabrikam] SET RECOVERY SIMPLE;
USE [Foo]
CREATE LOGIN fabrikam WITH PASSWORD = 'fabrikampassword'
CREATE USER fabrikam FOR LOGIN fabrikam WITH DEFAULT_SCHEMA=[dbo]
EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='fabrikam'
Nota
Abilitare SQL Server e autenticazione di Windows modalità in SQL Server Management Studio nella macchina virtuale. Se non si abilita la modalità di autenticazione, la migrazione non riesce.
Configurare il file della specifica di migrazione per la macchina virtuale
Aggiornare il file delle specifiche di migrazione per includere informazioni su come connettersi all'istanza di SQL Server. Aprire il file delle specifiche di migrazione e apportare gli aggiornamenti seguenti.
Rimuovere il parametro DACPAC dall'oggetto file di origine.
La specifica di migrazione prima della modifica viene illustrata nel codice seguente.

La specifica di migrazione dopo la modifica è illustrata nel codice seguente.

Compilare i parametri obbligatori e aggiungere l'oggetto proprietà seguente all'interno dell'oggetto di origine nel file di specifica.
"Properties": { "ConnectionString": "Data Source={SQL Azure VM Public IP};Initial Catalog={Database Name};Integrated Security=False;User ID={SQL Login Username};Password={SQL Login Password};Encrypt=True;TrustServerCertificate=True" }
Dopo aver applicato le modifiche, la specifica di migrazione sarà simile all'esempio seguente.
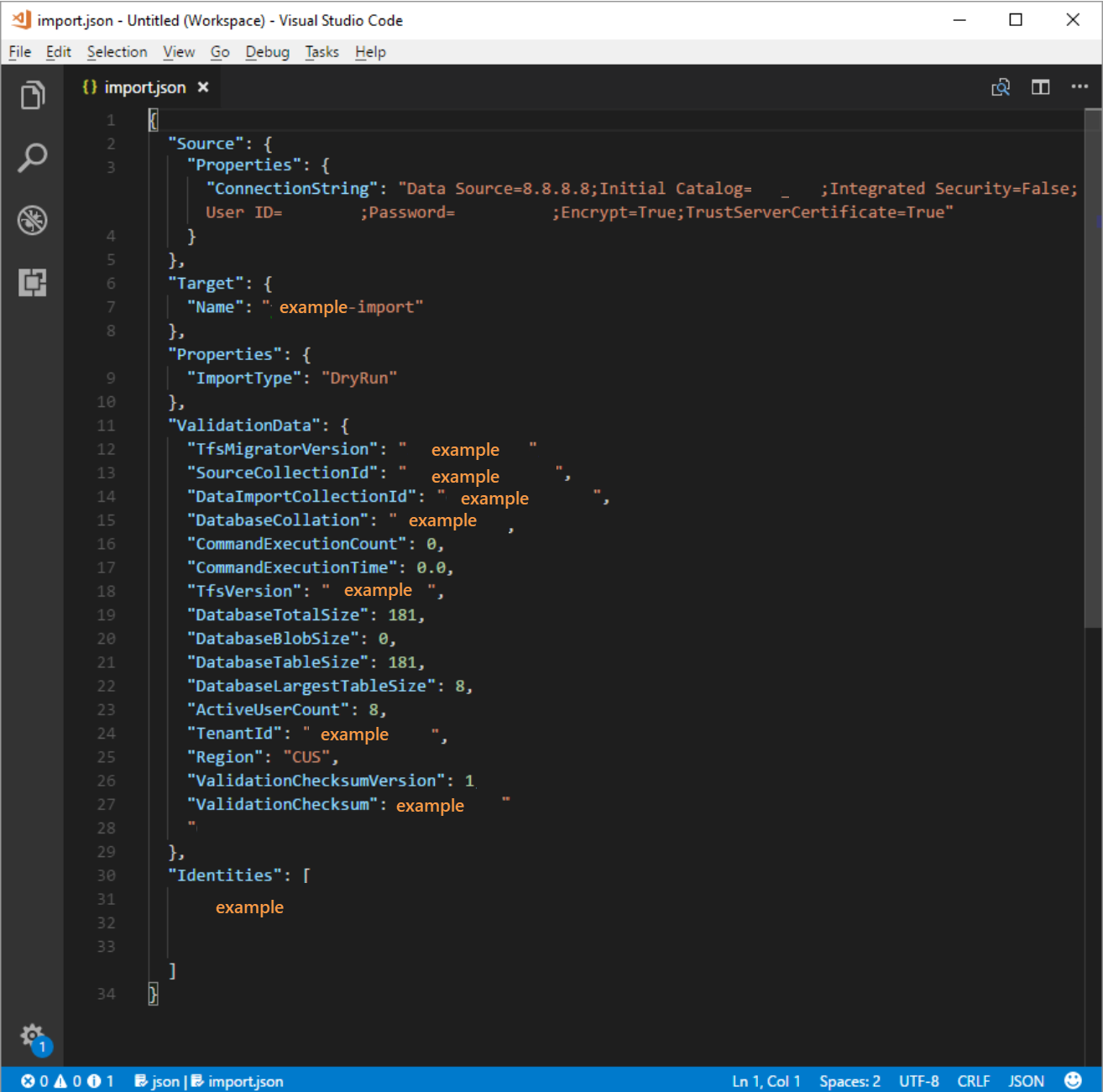
La specifica di migrazione è ora configurata per l'uso di una macchina virtuale di SQL Azure per la migrazione. Procedere con il resto dei passaggi di preparazione per la migrazione ad Azure DevOps Services. Al termine della migrazione, assicurarsi di eliminare l'accesso SQL o ruotare la password. Microsoft non mantiene le informazioni di accesso al termine della migrazione.
Passaggio 3: Caricare il file DACPAC
Nota
Se si usa il metodo della macchina virtuale di SQL Azure, è necessario fornire solo il stringa di connessione. Non è necessario caricare alcun file ed è possibile ignorare questo passaggio.
Il pacchetto di applicazione livello dati deve essere inserito in un contenitore di archiviazione di Azure, che può essere un contenitore esistente o creato in modo specifico per il lavoro di migrazione. È importante assicurarsi che il contenitore venga creato nelle posizioni geografiche corrette.
Azure DevOps Services è disponibile in più località geografiche. Quando si esegue l'importazione in queste posizioni, è fondamentale posizionare correttamente i dati per assicurarsi che la migrazione possa essere avviata correttamente. I dati devono essere inseriti nella stessa posizione geografica in cui si sta importando. L'inserimento dei dati in qualsiasi altra posizione comporta l'impossibilità di avviare la migrazione. La tabella seguente elenca le posizioni geografiche accettabili per la creazione dell'account di archiviazione e il caricamento dei dati.
| Località geografica di migrazione desiderata | Posizione geografica dell'account di archiviazione |
|---|---|
| Stati Uniti centrale | Stati Uniti centrale |
| Europa occidentale | Europa occidentale |
| Regno Unito | Regno Unito meridionale |
| Australia orientale | Australia orientale |
| Brasile meridionale | Brasile meridionale |
| India meridionale | India meridionale |
| Canada centrale | Canada centrale |
| Asia Pacifico (Singapore) | Asia Pacifico (Singapore) |
Anche se Azure DevOps Services è disponibile in più località geografiche negli Stati Uniti, solo la località di Stati Uniti centrale accetta nuovi servizi Azure DevOps. Al momento non è possibile eseguire la migrazione dei dati in altre località di Azure degli Stati Uniti.
Creare un contenitore BLOB dal portale di Azure. Dopo aver creato il contenitore, caricare il file DACPAC raccolta.
Al termine della migrazione, eliminare il contenitore BLOB e l'account di archiviazione associato con strumenti come AzCopy o qualsiasi altro strumento di Azure Storage Explorer, ad esempio Archiviazione di Azure Explorer.
Nota
Se il file DACPAC è maggiore di 10 GB, è consigliabile usare AzCopy. AzCopy include il supporto per il caricamento multithreading per caricamenti più veloci.
Passaggio 4: Generare un token di firma di accesso condiviso
Un token di firma di accesso condiviso fornisce l'accesso delegato alle risorse in un account di archiviazione. Il token consente di concedere a Microsoft il livello di privilegio più basso necessario per accedere ai dati per l'esecuzione della migrazione.
È possibile generare token di firma di accesso condiviso usando il portale di Azure. Da un punto di vista della sicurezza, è consigliabile eseguire le attività seguenti:
- Selezionare solo Lettura ed Elenco come autorizzazioni per il token di firma di accesso condiviso. Non sono necessarie altre autorizzazioni.
- Impostare un'ora di scadenza non superiore a sette giorni nel futuro.
- Limitare l'accesso solo agli indirizzi IP di Azure DevOps Services.
- Considerare la chiave di firma di accesso condiviso come segreto. Non lasciare la chiave in una posizione non sicura perché concede l'accesso in lettura ed elenco a tutti i dati archiviati nel contenitore.
Passaggio 5: Completare la specifica di migrazione
In precedenza nel processo è stato compilato parzialmente il file delle specifiche di migrazione, noto come migration.json. A questo punto, sono disponibili informazioni sufficienti per completare tutti i campi rimanenti, ad eccezione del tipo di migrazione. Il tipo di migrazione viene illustrato più avanti nella sezione relativa alla migrazione.
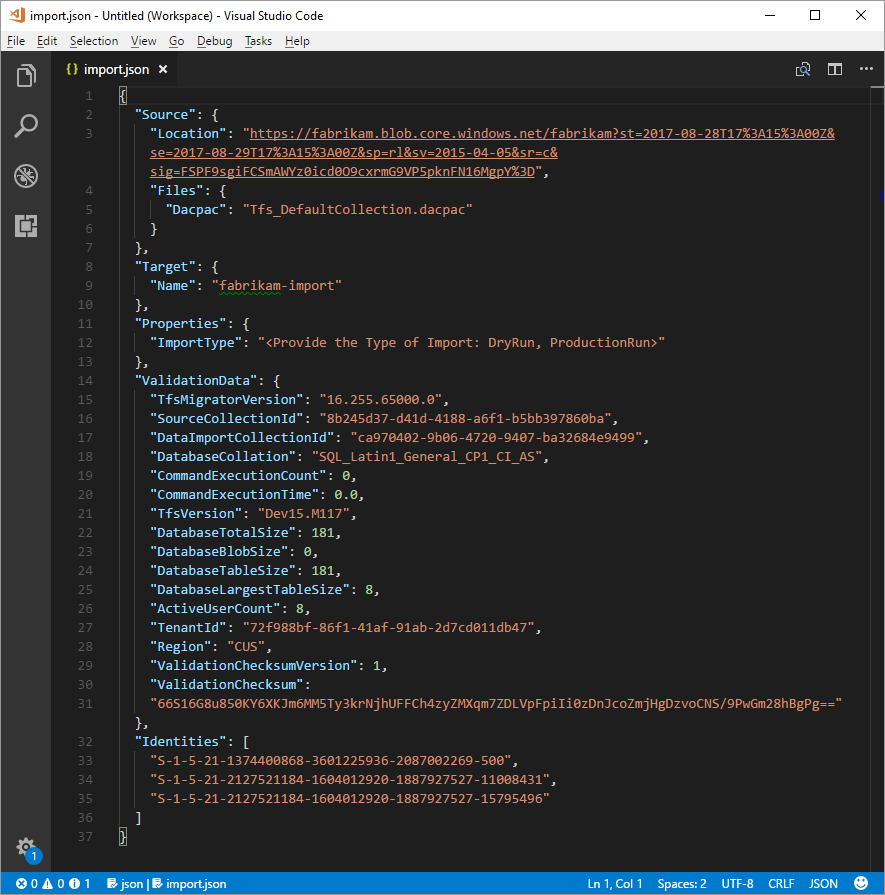
Nel file di specifica migration.json, in Origine, completare i campi seguenti.
- Percorso: incollare la chiave di firma di accesso condiviso generata dallo script e quindi copiata nel passaggio precedente.
- Dacpac: assicurarsi che il file, inclusa l'estensione con estensione dacpac , abbia lo stesso nome del file DACPAC caricato nell'account di archiviazione.
Il file della specifica di migrazione finale dovrebbe essere simile all'esempio seguente.
Determinare il tipo di migrazione
Le importazioni possono essere accodate come esecuzione di test o come esecuzione di produzione. Il parametro ImportType determina il tipo di migrazione:
- TestRun: usare un'esecuzione di test a scopo di test. Il sistema elimina le esecuzioni dei test dopo 45 giorni.
- ProductionRun: usare un'esecuzione di produzione quando si vuole mantenere la migrazione risultante e usare l'organizzazione a tempo pieno in Azure DevOps Services al termine della migrazione.
Suggerimento
È sempre consigliabile completare prima di tutto una migrazione di esecuzione dei test.
Organizzazioni di esecuzione dei test
Le organizzazioni di esecuzione dei test aiutano i team a testare la migrazione delle raccolte. Prima di poter eseguire una migrazione di produzione, è necessario eliminare tutte le organizzazioni di esecuzione di test completate. Tutte le organizzazioni di esecuzione dei test hanno un'esistenza limitata e vengono eliminate automaticamente dopo un determinato periodo di tempo. Le informazioni su quando l'organizzazione viene eliminata vengono incluse nel messaggio di posta elettronica con esito positivo che si dovrebbe ricevere al termine della migrazione. Assicurarsi di prendere nota di questa data e pianificare di conseguenza.
Le organizzazioni di esecuzione dei test hanno 45 giorni prima dell'eliminazione. Dopo il periodo di tempo specificato, l'organizzazione di esecuzione dei test viene eliminata. È possibile ripetere le importazioni di esecuzioni di test quante volte è necessario prima di eseguire una migrazione di produzione.
Eliminare le esecuzioni di test
Eliminare tutte le esecuzioni di test precedenti prima di tentare una nuova esecuzione. Quando il team è pronto per eseguire una migrazione di produzione, è necessario eliminare manualmente l'organizzazione di esecuzione dei test. Prima di poter eseguire una seconda migrazione di test o la migrazione di produzione finale, assicurarsi di eliminare tutte le organizzazioni di Azure DevOps Services precedenti create in un'esecuzione di test precedente. Per altre informazioni, vedere Eliminare l'organizzazione.
Suggerimento
Le informazioni facoltative per consentire a un utente di eseguire il test di una migrazione di test più efficace che segue il primo richiederà più tempo, dato il tempo aggiuntivo necessario per pulire le risorse dalle esecuzioni di test precedenti.
Il nome di un'organizzazione può richiedere fino a un'ora dopo l'eliminazione o la ridenominazione. Per altre informazioni, vedere l'articolo Attività post-migrazione .
Se si verificano problemi di migrazione, vedere Risolvere gli errori di migrazione e migrazione.
Eseguire una migrazione
Il team è ora pronto per iniziare il processo di esecuzione di una migrazione. È consigliabile iniziare con una migrazione corretta dell'esecuzione di test prima di tentare una migrazione in esecuzione in produzione. Con le importazioni di esecuzione dei test, è possibile vedere in anticipo l'aspetto di una migrazione, identificare i potenziali problemi e acquisire esperienza prima di passare all'esecuzione di produzione.
Nota
- Se è necessario ripetere una migrazione completata in fase di produzione per una raccolta, come in caso di rollback, contattare il supporto tecnico di Azure DevOps Services prima di accodare un'altra migrazione.
- Gli amministratori di Azure possono impedire agli utenti di creare nuove organizzazioni di Azure DevOps. Se i criteri del tenant di Microsoft Entra sono attivati, la migrazione non riesce a terminare. Prima di iniziare, verificare che il criterio non sia impostato o che sia presente un'eccezione per l'utente che esegue la migrazione. Per altre informazioni, vedere Limitare la creazione dell'organizzazione tramite i criteri del tenant di Microsoft Entra.
- Azure DevOps Services non supporta i criteri di conservazione per pipeline e non vengono trasportati nella versione ospitata.
Considerazioni per i piani di rollback
Un problema comune per i team che eseguono un'esecuzione di produzione finale è il piano di rollback, se si verificano problemi con la migrazione. È consigliabile eseguire un'esecuzione di test per assicurarsi di poter testare le impostazioni di migrazione fornite allo Strumento di migrazione dei dati per Azure DevOps.
Il rollback per l'esecuzione di produzione finale è piuttosto semplice. Prima di accodare la migrazione, scollegare la raccolta di progetti team da Azure DevOps Server, che lo rende non disponibile per i membri del team. Se per qualsiasi motivo è necessario eseguire il rollback dell'esecuzione di produzione e riportare online il server locale per i membri del team, è possibile farlo. Collegare nuovamente la raccolta di progetti team in locale e informare il team che continuano a funzionare normalmente mentre il team raggruppa per comprendere eventuali errori.
È quindi possibile contattare il supporto tecnico di Azure DevOps Services per informazioni sulla causa dell'errore se non è possibile determinare la causa. Per altre informazioni, vedere l'articolo Risoluzione dei problemi. I ticket di supporto clienti possono essere aperti dalla pagina https://aka.ms/AzureDevOpsImportSupportseguente. È importante notare che se il problema richiede ai tecnici del gruppo di prodotti di impegnarsi in questi casi verrà gestito durante l'orario di ufficio normale.
Scollegare la raccolta di progetti team da Azure DevOps Server per prepararla per la migrazione.
Prima di generare un backup del database SQL, lo strumento di migrazione dei dati richiede che la raccolta sia completamente scollegata da Azure DevOps Server (non DA SQL). Il processo di scollegamento in Azure DevOps Server trasferisce le informazioni sull'identità utente archiviate all'esterno del database di raccolta e lo rende portabile per passare a un nuovo server o, in questo caso, in Azure DevOps Services.
La rimozione di una raccolta viene eseguita facilmente dalla console di amministrazione del server Azure DevOps nell'istanza di Azure DevOps Server. Per altre informazioni, vedere Spostare la raccolta di progetti, Scollegare la raccolta.
Accodamento della migrazione
Importante
Prima di procedere, assicurarsi che la raccolta sia stata scollegata prima di generare un file DACPAC o caricare il database di raccolta in una macchina virtuale di SQL Azure. Se non si completa questo passaggio, la migrazione non riesce. Nel caso in cui la migrazione non riesca, vedere Risolvere gli errori di migrazione.
Avviare una migrazione usando il comando di importazione dello Strumento di migrazione dei dati. Il comando di migrazione accetta un file di specifica della migrazione come input. Analizza il file per assicurarsi che i valori forniti siano validi e, in caso di esito positivo, accoda una migrazione ad Azure DevOps Services. Il comando di migrazione richiede una connessione Internet, ma non richiede una connessione all'istanza di Azure DevOps Server.
Per iniziare, aprire una finestra del prompt dei comandi e modificare le directory nel percorso dello strumento di migrazione dei dati. È consigliabile esaminare il testo della Guida fornito con lo strumento. Eseguire il comando seguente per visualizzare le indicazioni e la Guida per il comando di migrazione:
Migrator import /help
Il comando per accodare una migrazione ha la struttura seguente:
Migrator import /importFile:{location of migration specification file}
L'esempio seguente mostra un comando di migrazione completato:
Migrator import /importFile:C:\DataMigrationToolFiles\migration.json
Al termine della convalida, accedere a Microsoft Entra ID con un'identità membro dello stesso tenant di Microsoft Entra rispetto al file di log della mappa delle identità. L'utente connesso è il proprietario dell'organizzazione importata.
Nota
Ogni tenant di Microsoft Entra è limitato a cinque importazioni per periodo di 24 ore. Solo le importazioni che vengono conteggiate in coda rispetto a questo limite.
Quando il team avvia una migrazione, viene inviata una notifica tramite posta elettronica all'utente che ha accodato la migrazione. Circa 5-10 minuti dopo aver accodato la migrazione, il team può passare all'organizzazione per verificare lo stato. Al termine della migrazione, il team viene indirizzato all'accesso e viene inviata una notifica tramite posta elettronica al proprietario dell'organizzazione.
Lo strumento di migrazione dei dati contrassegna gli errori che è necessario correggere prima della migrazione. Questo articolo descrive gli avvisi e gli errori più comuni che è possibile ricevere durante la preparazione della migrazione. Dopo aver corretto ogni errore, eseguire di nuovo il comando di convalida della migrazione per verificare la risoluzione.