Introduzione all'archiviazione cluster
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure disponibili in versione beta, in anteprima o non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti nella community di Azure HDInsight.
Azure HDInsight nel servizio Azure Kubernetes può integrarsi facilmente con Archiviazione di Azure, una soluzione di archiviazione per utilizzo generico che funziona bene con molti altri servizi di Azure. Azure Data Lake Archiviazione Gen2 (ADLS Gen 2) è il file system predefinito per i cluster.
L'account di archiviazione può essere usato come percorso predefinito per i dati, i log del cluster e altri output generati durante l'operazione del cluster. Potrebbe anche essere una risorsa di archiviazione predefinita per il catalogo Hive che dipende dal tipo di cluster.
Per altre informazioni, vedere Introduzione ad Azure Data Lake Storage Gen2.
Identità gestite per un accesso sicuro ai file
Azure HDInsight nel servizio Azure Kubernetes usa identità gestite (MSI) per proteggere l'accesso del cluster ai file in Azure Data Lake Archiviazione Gen2. L'identità gestita è una funzionalità di Microsoft Entra ID che fornisce ai servizi di Azure un set di credenziali gestite automaticamente. Queste credenziali possono essere usate per eseguire l'autenticazione per qualsiasi servizio che supporti l'autenticazione Active Directory. Inoltre, le identità gestite non richiedono l'archiviazione delle credenziali nei file di codice o di configurazione.
In Azure HDInsight nel servizio Azure Kubernetes, dopo aver selezionato un'identità gestita e una risorsa di archiviazione durante la creazione del cluster, l'identità gestita può funzionare senza problemi con l'archiviazione per la gestione dei dati, purché il ruolo proprietario dei dati BLOB Archiviazione sia assegnato all'identità del servizio gestito assegnata dall'utente.
La tabella seguente illustra le opzioni di archiviazione supportate per Azure HDInsight nel servizio Azure Kubernetes (anteprima pubblica):
| Tipo di cluster | Archiviazione supportate | Connessione | Ruolo in Archiviazione |
|---|---|---|---|
| Trino, Apache Flink e Apache Spark | ADLS Gen2 | Identità gestita assegnata dall'utente del cluster | L'identità del servizio gestito assegnata dall'utente deve avere Archiviazione ruolo Proprietario dati BLOB nell'account di archiviazione. |
Nota
Per condividere un account di archiviazione tra più cluster, è sufficiente assegnare l'identità del servizio gestito assegnata dall'utente del cluster corrispondente "Archiviazione proprietario dei dati BLOB" nell'account di archiviazione condiviso. Informazioni su come assegnare un ruolo.
Successivamente, è possibile usare il percorso di archiviazione abfs:// completo per accedere ai dati tramite le applicazioni.
Per altre informazioni, vedere Identità gestite per le risorse di Azure.
Informazioni su come creare un account ADLS Gen2.
Architettura di archiviazione di Azure HDInsight nel servizio Azure Kubernetes
Il diagramma seguente offre una visualizzazione astratta dell'architettura di Azure HDInsight nel servizio Azure Kubernetes di Archiviazione di Azure.
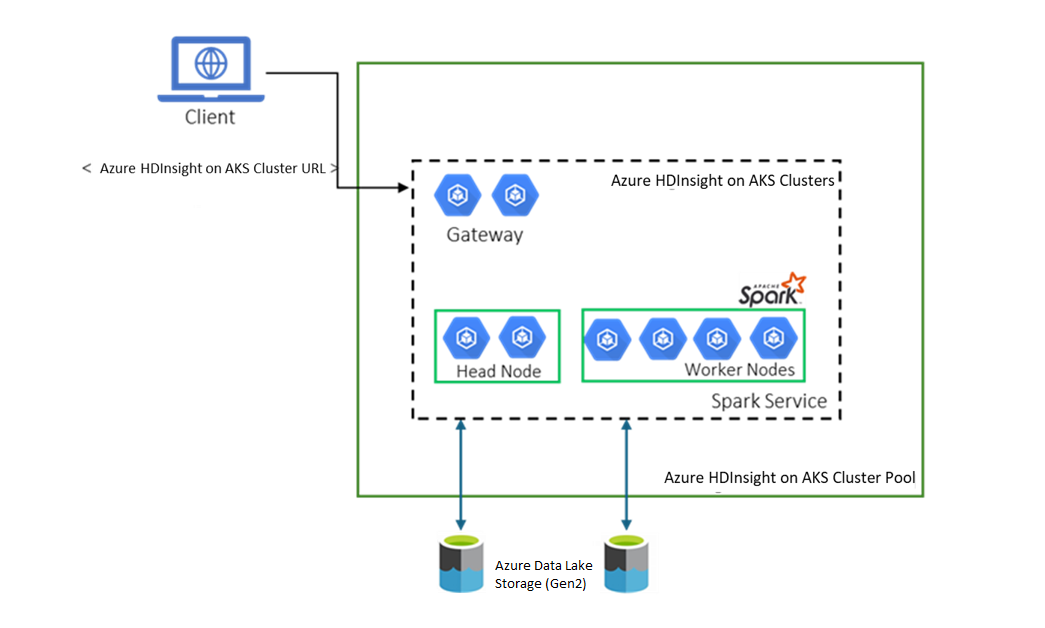
Gestione dell'archiviazione
Attualmente, Azure HDInsight nel servizio Azure Kubernetes non supporta gli account di archiviazione con eliminazione temporanea abilitata, assicurarsi di disabilitare l'eliminazione temporanea per l'account di archiviazione.

Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per