Creare una tabella Apache Kafka® su Apache Flink® su HDInsight su AKS
Importante
Azure HDInsight su AKS è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su Azure Kubernetes Service (AKS). Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti su community di Azure HDInsight.
Questo esempio illustra come creare una tabella Kafka in Apache FlinkSQL.
Prerequisiti
Connettore SQL Kafka su Apache Flink
Il connettore Kafka consente di leggere e scrivere dati in argomenti Kafka. Per altre informazioni, vedere Connettore Apache Kafka SQL.
Creare una tabella Kafka in Flink SQL
Preparare argomenti e dati in HDInsight Kafka
Preparare i messaggi con weblog.py
import random
import json
import time
from datetime import datetime
user_set = [
'John',
'XiaoMing',
'Mike',
'Tom',
'Machael',
'Zheng Hu',
'Zark',
'Tim',
'Andrew',
'Pick',
'Sean',
'Luke',
'Chunck'
]
web_set = [
'https://google.com',
'https://facebook.com?id=1',
'https://tmall.com',
'https://baidu.com',
'https://taobao.com',
'https://aliyun.com',
'https://apache.com',
'https://flink.apache.com',
'https://hbase.apache.com',
'https://github.com',
'https://gmail.com',
'https://stackoverflow.com',
'https://python.org'
]
def main():
while True:
if random.randrange(10) < 4:
url = random.choice(web_set[:3])
else:
url = random.choice(web_set)
log_entry = {
'userName': random.choice(user_set),
'visitURL': url,
'ts': datetime.now().strftime("%m/%d/%Y %H:%M:%S")
}
print(json.dumps(log_entry))
time.sleep(0.05)
if __name__ == "__main__":
main()
dell'argomento Pipeline to Kafka
sshuser@hn0-contsk:~$ python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Altri comandi:
-- create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 3 --topic click_events --bootstrap-server wn0-contsk:9092
-- delete topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic click_events --bootstrap-server wn0-contsk:9092
-- consume topic
sshuser@hn0-contsk:~$ /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server wn0-contsk:9092 --topic click_events --from-beginning
{"userName": "Luke", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Tom", "visitURL": "https://stackoverflow.com", "ts": "06/26/2023 14:33:43"}
{"userName": "Chunck", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Chunck", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Andrew", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Pick", "visitURL": "https://google.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Mike", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Zheng Hu", "visitURL": "https://tmall.com", "ts": "06/26/2023 14:33:44"}
{"userName": "Luke", "visitURL": "https://facebook.com?id=1", "ts": "06/26/2023 14:33:44"}
{"userName": "John", "visitURL": "https://flink.apache.com", "ts": "06/26/2023 14:33:44"}
Cliente Apache Flink SQL
Vengono fornite istruzioni dettagliate su come usare Secure Shell per client SQL Flink.
Scaricare il connettore SQL Kafka & dipendenze in SSH
Nel passaggio seguente viene usato il Kafka 3.2.0 dipendenze. È necessario aggiornare il comando in base alla versione kafka nel cluster HDInsight.
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.2.0/kafka-clients-3.2.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.0/flink-connector-kafka-1.17.0.jar
Connettersi al client SQL Apache Flink
Colleghiamoci ora al client SQL Flink utilizzando i file JAR del client SQL Kafka.
msdata@pod-0 [ /opt/flink-webssh ]$ bin/sql-client.sh -j flink-connector-kafka-1.17.0.jar -j kafka-clients-3.2.0.jar
Creare una tabella Kafka in Apache Flink SQL
Creare la tabella Kafka in Flink SQL e selezionare la tabella Kafka in Flink SQL.
È necessario aggiornare gli indirizzi IP del server di bootstrap Kafka nel frammento di codice seguente.
CREATE TABLE KafkaTable (
`userName` STRING,
`visitURL` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'click_events',
'properties.bootstrap.servers' = '<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092,<update-kafka-bootstrapserver-ip>:9092',
'properties.group.id' = 'my_group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
select * from KafkaTable;
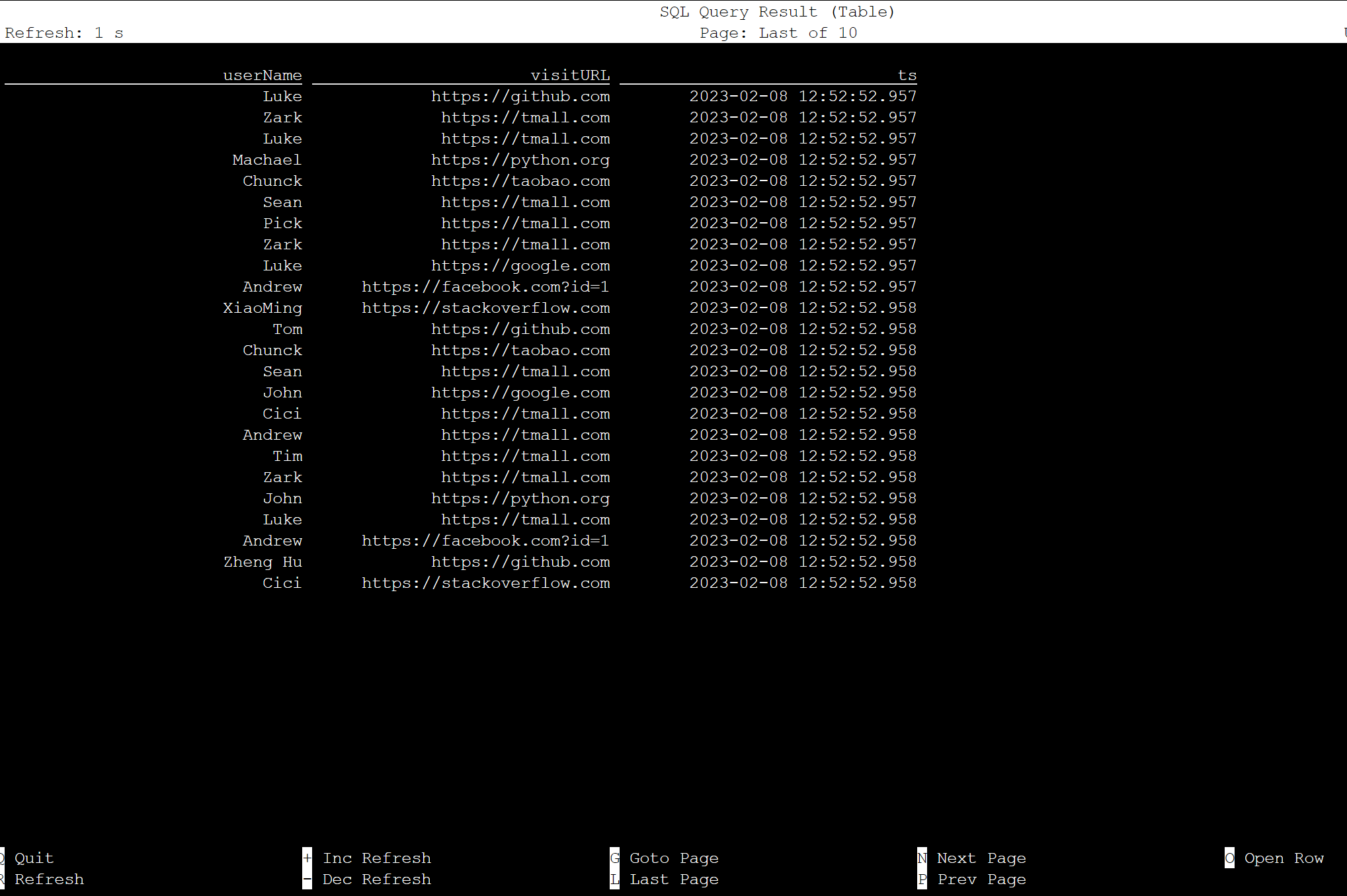
Produrre messaggi Kafka
Produciamo ora messaggi Kafka sullo stesso topic, utilizzando HDInsight Kafka.
python weblog.py | /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --bootstrap-server wn0-contsk:9092 --topic click_events
Tabella in Apache Flink SQL
È possibile monitorare la tabella in Flink SQL.
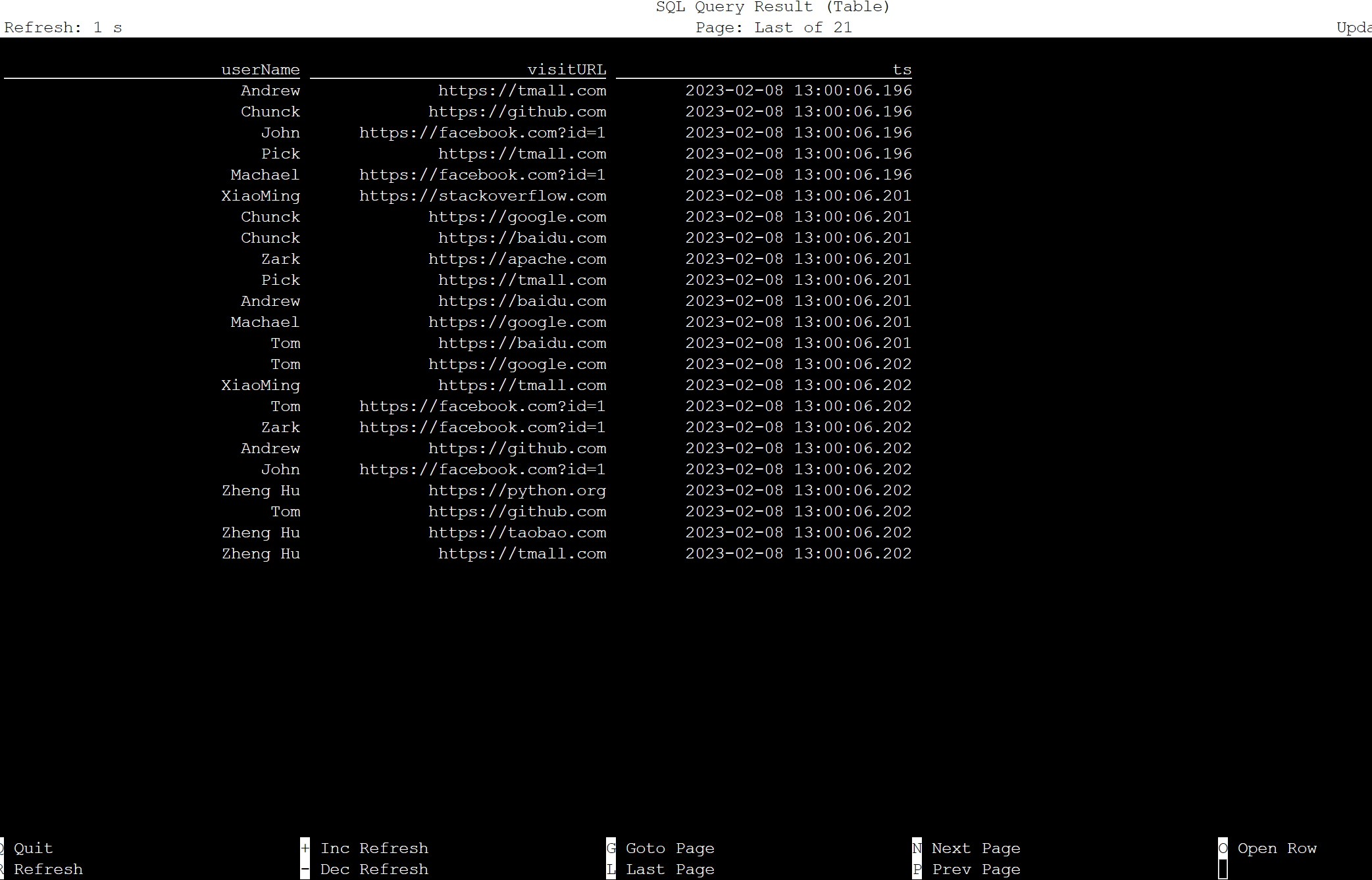
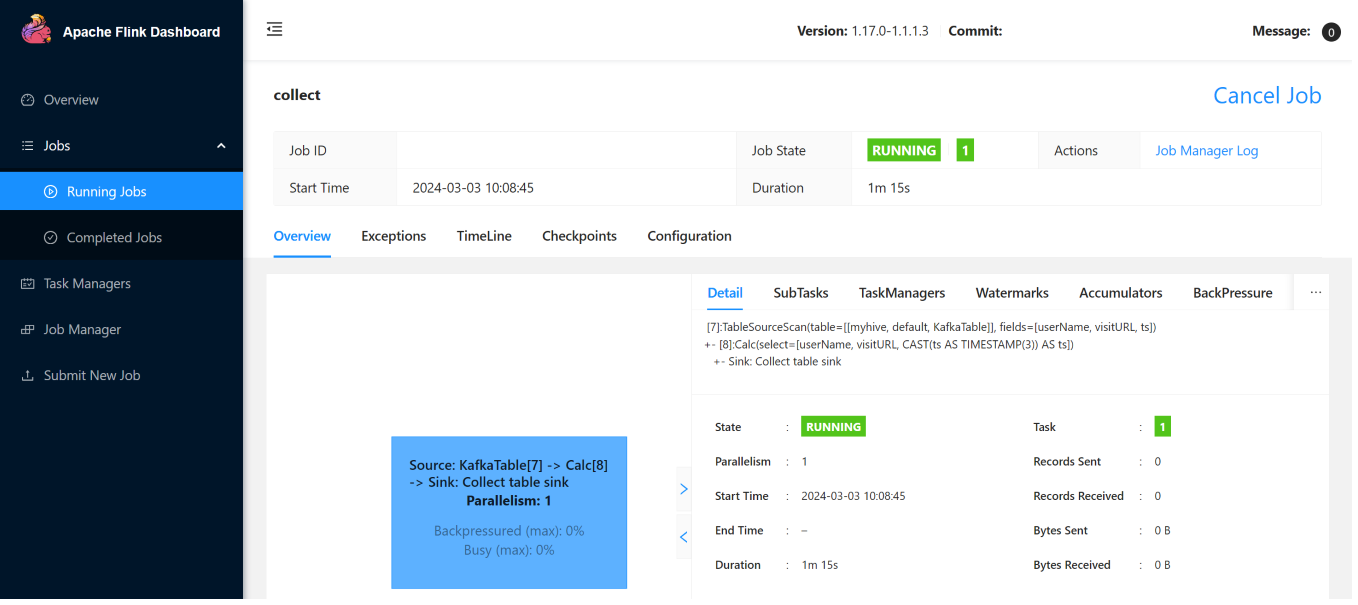
Ecco i processi di streaming nell'interfaccia utente Web Flink.
Riferimento
- Apache Kafka SQL Connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi della Apache Software Foundation (ASF).