Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Apache Kafka è una piattaforma di streaming open source distribuita. Viene spesso usata come broker di messaggi perché offre funzionalità simili a una coda messaggi di pubblicazione/sottoscrizione.
Questa guida di avvio rapido illustra come creare un cluster Apache Kafka con il portale di Azure. Illustra anche come usare le utilità incluse per inviare e ricevere messaggi tramite Apache Kafka. Per una spiegazione approfondita delle configurazioni disponibili, vedere Configurare i cluster in HDInsight. Per altre informazioni sull'uso del portale per la creazione di cluster, vedere Creare cluster nel portale.
Avviso
La fatturazione dei cluster HDInsight viene calcolata al minuto, indipendentemente dal fatto che siano usati o meno. Assicurarsi di eliminare il cluster dopo aver finito di usarlo. Vedere Come eliminare un cluster HDInsight.
Possono accedere all'API Apache Kafka solo risorse interne alla stessa rete virtuale. In questa guida di avvio rapido si accede al cluster direttamente usando SSH. Per connettere altri servizi, reti o macchine virtuali ad Apache Kafka, è necessario prima di tutto creare una rete virtuale e quindi creare le risorse all'interno della rete. Per altre informazioni, vedere il documento Connettersi ad Apache Kafka da una rete locale. Per informazioni generali sulla pianificazione di reti virtuali per HDInsight, vedere Pianificare una rete virtuale per Azure HDInsight.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Un client SSH. Per altre informazioni, vedere Connettersi a HDInsight (Apache Hadoop) con SSH.
Creare un cluster Apache Kafka
Per creare un cluster Apache Kafka in HDInsight seguire questa procedura:
Accedere al portale di Azure.
Nel menu in alto selezionare + Crea una risorsa.
Selezionare Analytics>Azure HDInsight per passare alla pagina Crea cluster HDInsight.
Nella scheda Nozioni di base specificare le informazioni seguenti:
Proprietà Descrizione Subscription Nell'elenco a discesa selezionare la sottoscrizione di Azure che viene usata per il cluster. Gruppo di risorse Creare un gruppo di risorse o selezionarne uno esistente. Un gruppo di risorse è un contenitore di componenti di Azure. In questo caso, il gruppo di risorse contiene il cluster HDInsight e l'account di Archiviazione di Azure dipendente. Nome cluster Immettere un nome globalmente univoco. Il nome può includere al massimo 59 caratteri, tra cui lettere, numeri e trattini. Si noti che il primo e l'ultimo carattere del nome non possono essere trattini. Paese Nell'elenco a discesa selezionare un'area in cui viene creato il cluster. Scegliere un'area vicina all'utente per ottenere prestazioni migliori. Tipo di cluster Scegliere Selezionare il tipo di cluster per aprire un elenco. Nell'elenco selezionare Kafka come tipo di cluster. Versione Verrà specificata la versione predefinita per il tipo di cluster. Selezionare dall'elenco a discesa se si vuole specificare una versione diversa. Nome utente e password di accesso del cluster Il nome di accesso predefinito è admin. La password deve avere una lunghezza minima di 10 caratteri e contenere almeno una cifra, una lettera maiuscola, una lettera minuscola e un carattere non alfanumerico (eccetto i caratteri' ` "). Assicurarsi di non fornire password comuni, comePass@word1.Nome utente Secure Shell (SSH) Il nome utente predefinito è sshuser. È possibile fornire un altro nome come nome utente SSH.Usare la password di accesso del cluster per SSH Selezionare questa casella di controllo se si vuole usare per l'utente SSH la stessa password fornita per l'utente di accesso del cluster. 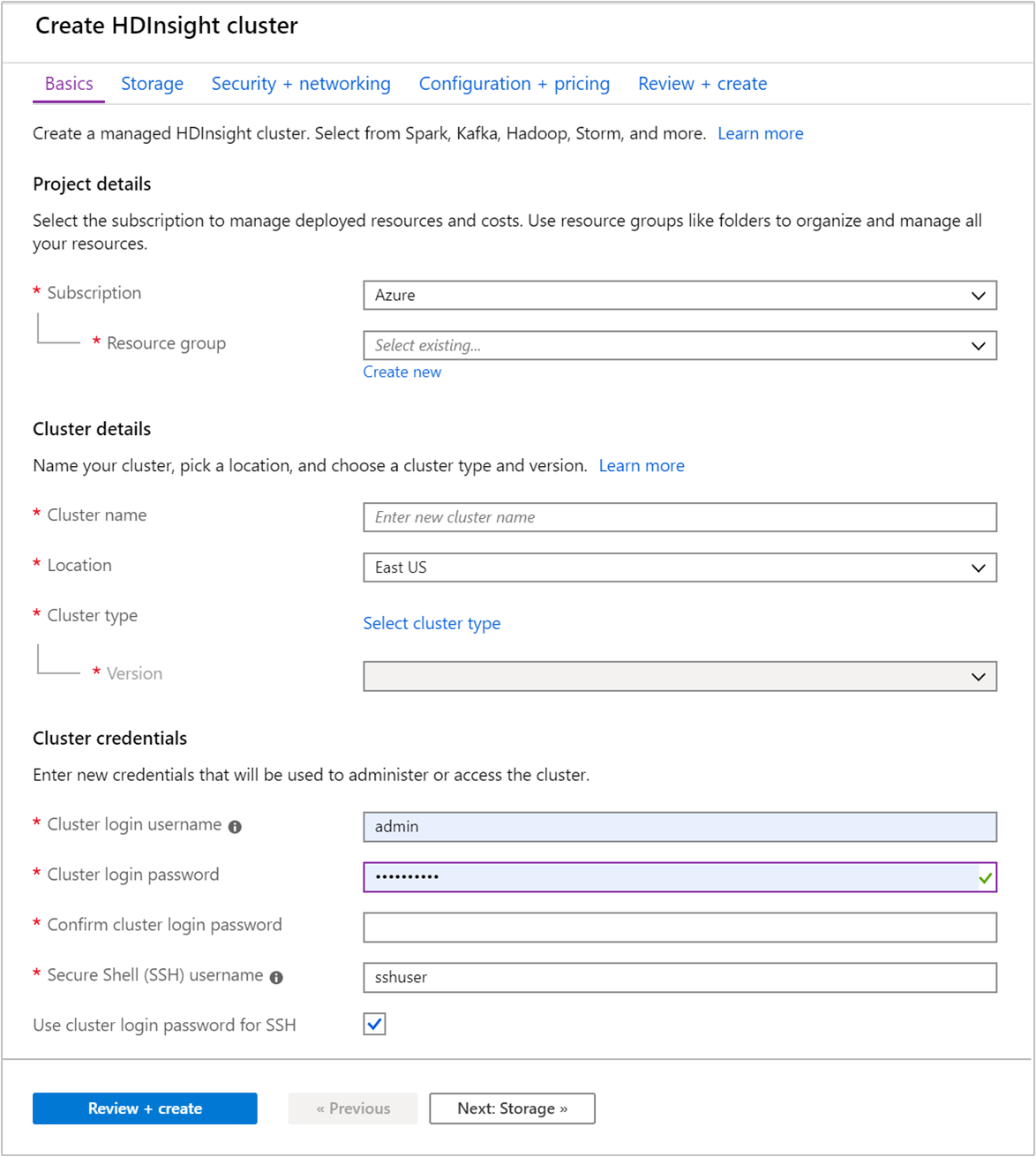
Ogni area (posizione) di Azure fornisce domini di errore. Un dominio di errore è un raggruppamento logico dell'hardware sottostante in un data center di Azure. Ogni dominio di errore condivide una fonte di alimentazione e un commutatore di rete comuni. Le macchine virtuali e i dischi gestiti che implementano i nodi in un cluster HDInsight sono distribuiti tra i domini di errore. Questa architettura limita il potenziale impatto dei guasti dell'hardware fisico.
Per la disponibilità elevata dei dati, selezionare una posizione (area) contenente tre domini di errore. Per informazioni sul numero di domini di errore in un'area, vedere il documento Disponibilità delle macchine virtuali Linux.
Selezionare la scheda Avanti: Archiviazione>> per andare alle impostazioni di archiviazione.
Nella scheda Archiviazione specificare i valori seguenti:
Proprietà Descrizione Tipo di archiviazione primario Usare il valore predefinito Archiviazione di Azure. Metodo di selezione Usare il valore predefinito Selezionare dall'elenco. Account di archiviazione primario Usare l'elenco a discesa per scegliere un account di archiviazione esistente oppure selezionare Crea nuovo. Se si crea un nuovo account, il nome deve avere una lunghezza compresa tra 3 e 24 caratteri e può contenere solo numeri e lettere minuscole Contenitore Usare il valore inserito automaticamente. 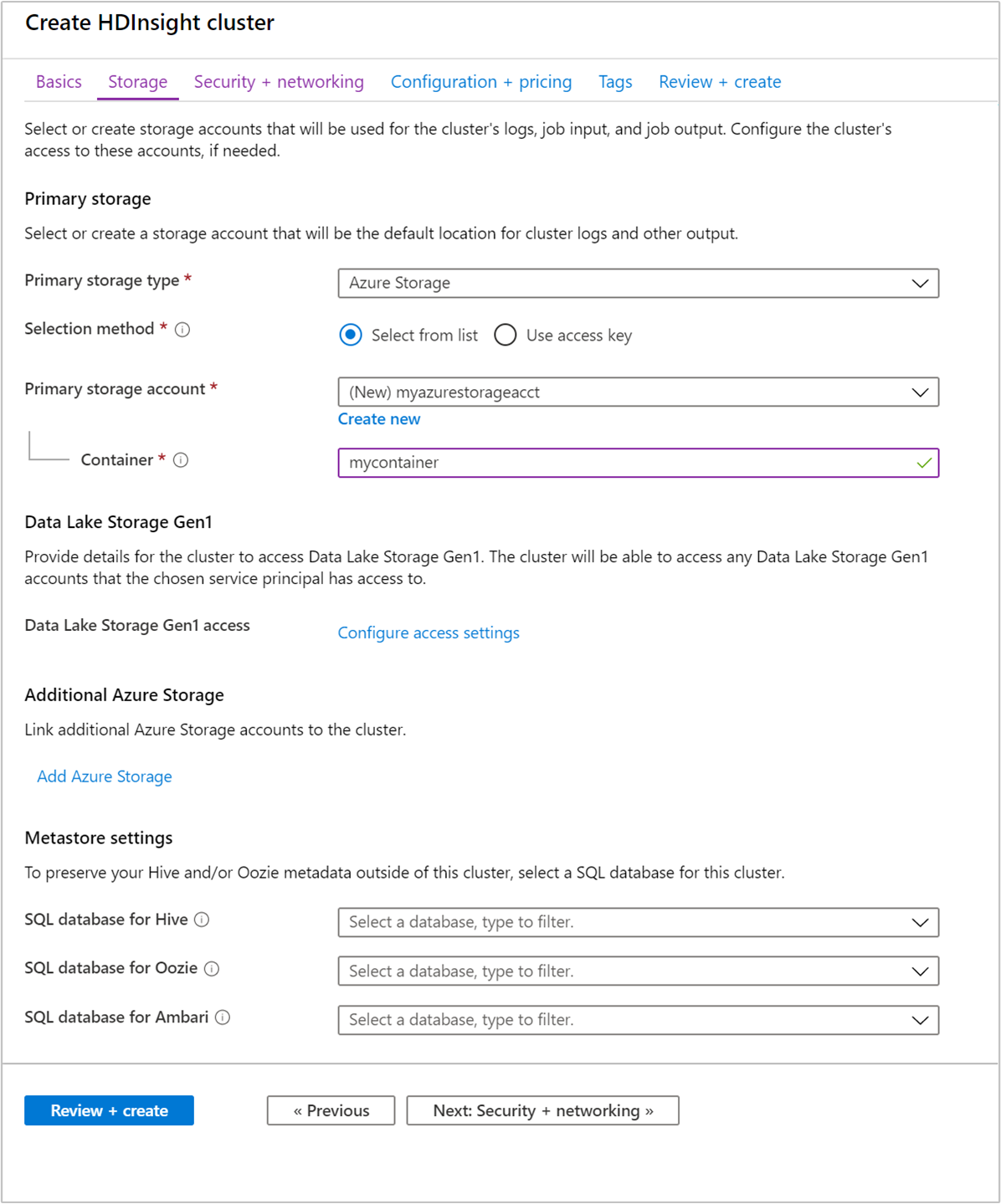
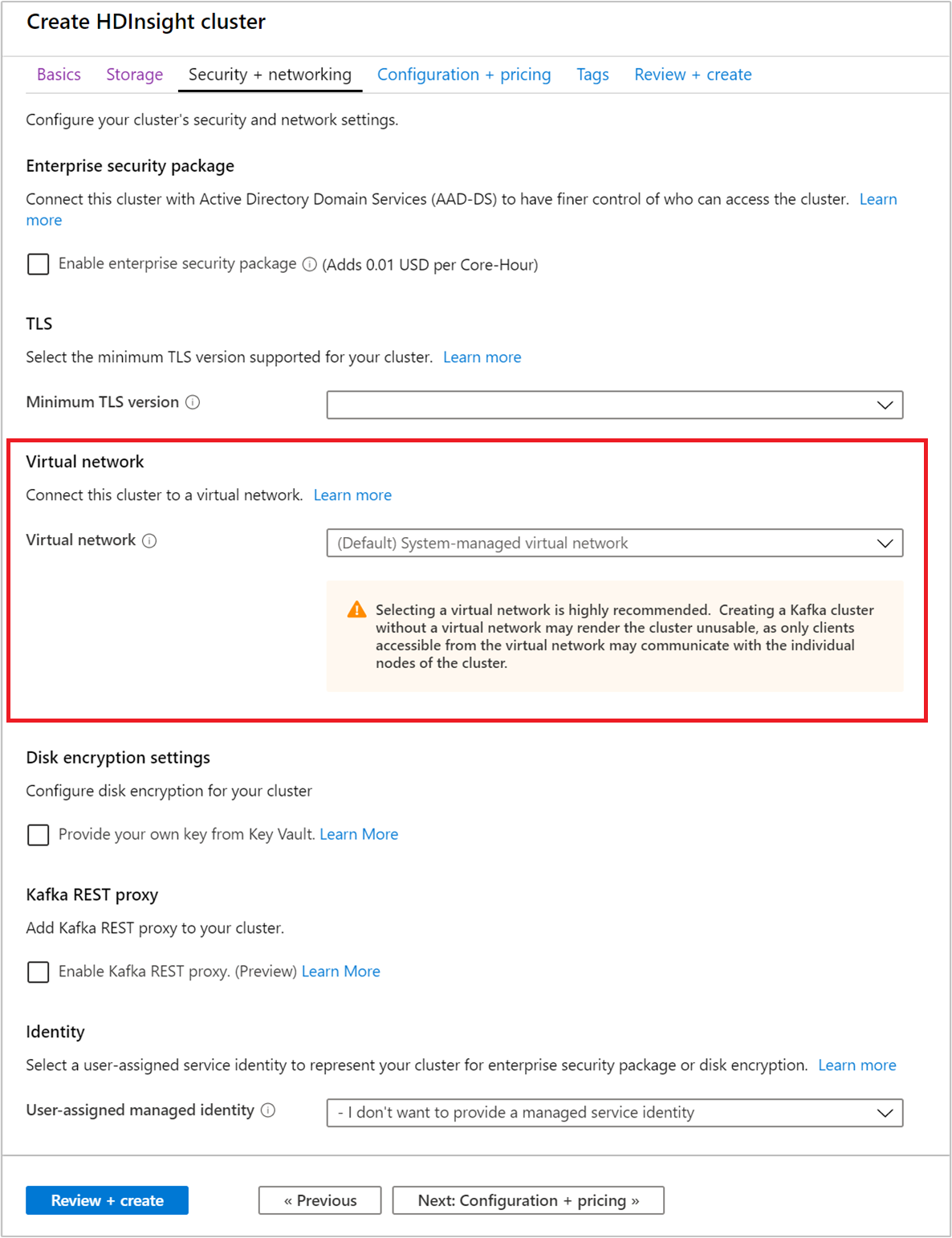
Selezionare la scheda Sicurezza + rete.
Per questa guida di avvio rapido non modificare le impostazioni di sicurezza predefinite. Per altre informazioni su Enterprise Security Package, vedere Configurare un cluster HDInsight con Enterprise Security Package usando Microsoft Entra Domain Services. Per informazioni su come usare una chiave personalizzata per la crittografia dei dischi per Apache Kafka, vedere Crittografia dischi con chiavi gestite dal cliente
Se si vuole connettere il cluster a una rete virtuale, selezionare una rete virtuale nell'elenco a discesa Rete virtuale.
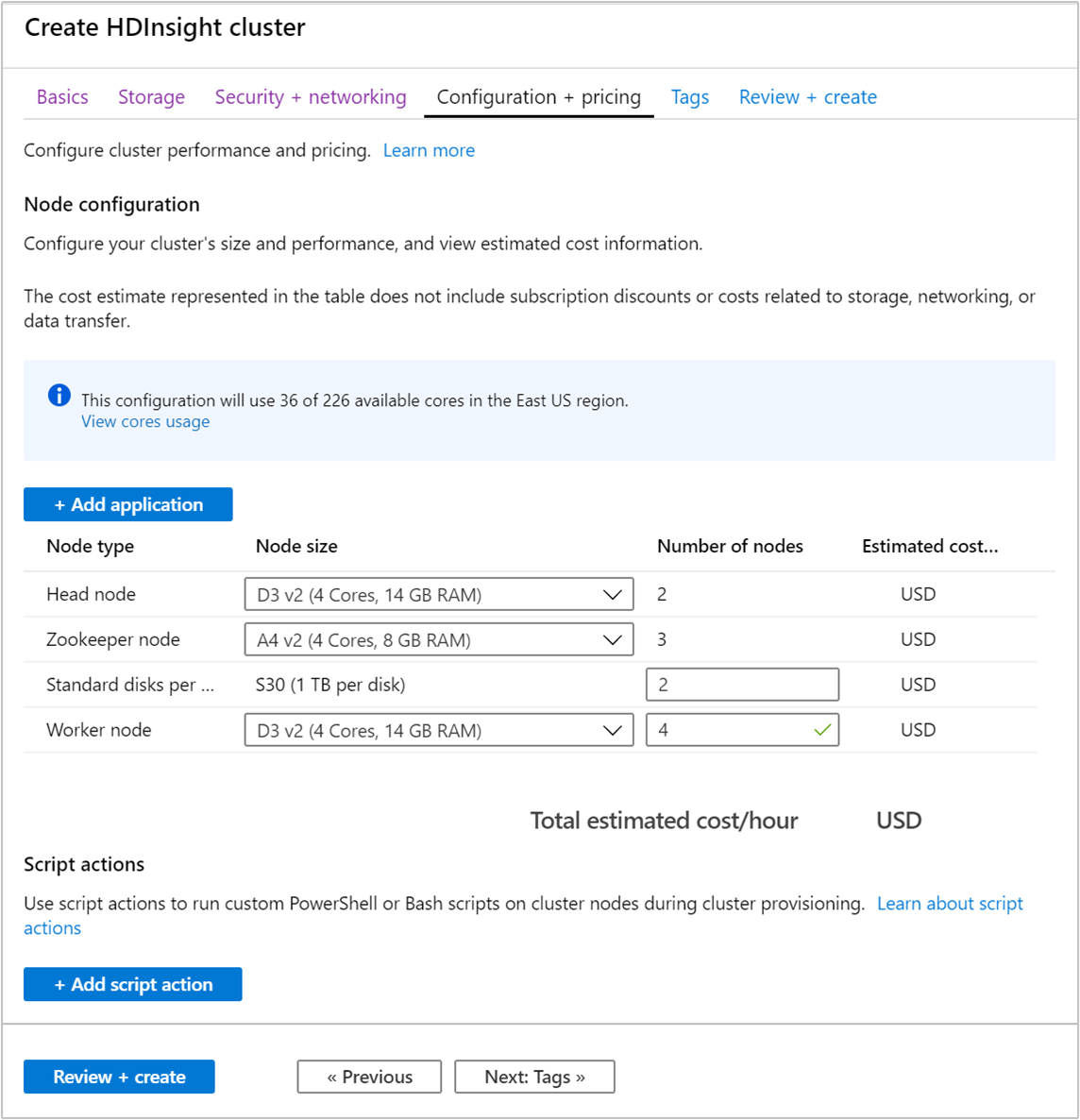
Scegliere la scheda Configurazione + prezzi.
Per garantire la disponibilità di Apache Kafka in HDInsight, la voce relativa al numero di nodi per il nodo di lavoro deve essere impostata almeno su 3. Il valore predefinito è 4.
La voce relativa ai dischi standard per nodo di lavoro consente di configurare la scalabilità di Apache Kafka in HDInsight. Per archiviare i dati, Apache Kafka in HDInsight usa il disco locale delle macchine virtuali nel cluster. Dal momento che in Apache Kafka i processi I/O sono intensivi, viene usato il servizio Azure Managed Disks per assicurare una velocità effettiva elevata e fornire maggiore spazio di archiviazione per ogni nodo. Il tipo di disco gestito può essere Standard (HDD) o Premium (SSD). Il tipo di disco dipende dalle dimensioni della macchina virtuale usate dai nodi del ruolo di lavoro (broker Apache Kafka). I dischi Premium vengono usati con le macchine virtuali serie DS e GS. Tutti gli altri tipi di macchine virtuali usano dischi Standard.
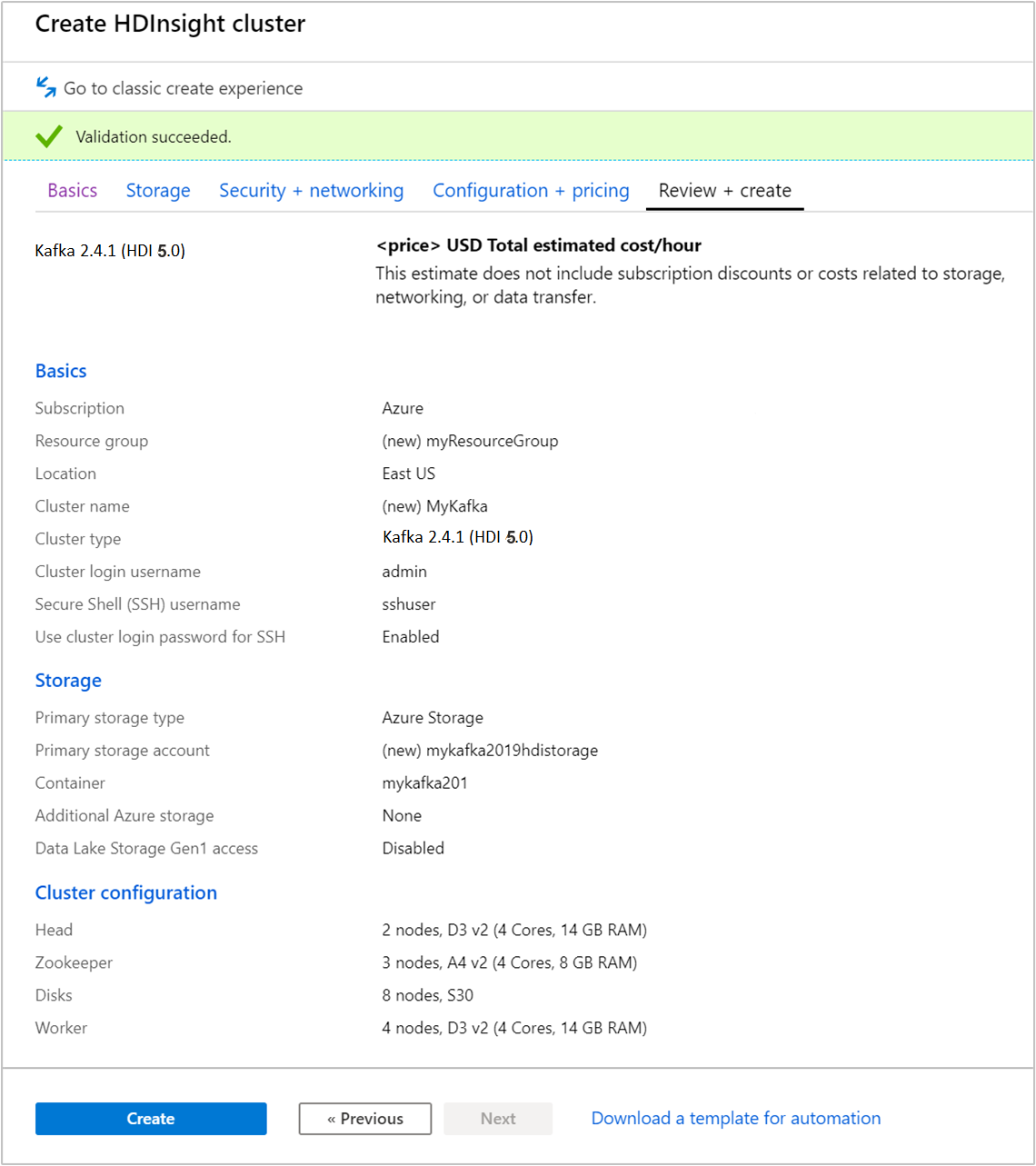
Selezionare la scheda Rivedi e crea.
Verificare la configurazione del cluster. Modificare le impostazioni non corrette. Infine, scegliere Crea per creare il cluster.
La creazione del cluster può richiedere fino a 20 minuti.
Stabilire la connessione al cluster
Usare il comando ssh per connettersi al cluster. Modificare il comando seguente sostituendo CLUSTERNAME con il nome del cluster in uso e quindi immettere il comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netQuando richiesto, immettere la password per l'utente SSH.
Dopo avere eseguito la connessione, vengono visualizzate informazioni simili al testo seguente:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Ottenere le informazioni sugli host Apache Zookeeper e broker
Quando si usa Kafka, è necessario conoscere gli host Apache Zookeeper e broker. Questi host vengono usati con l'API Apache Kafka e molte delle utilità offerte con Kafka.
In questa sezione si ottengono le informazioni sull'host dall'API REST Apache Ambari nel cluster.
Installare jq, un processore JSON da riga di comando. Questa utilità consente di analizzare i documenti JSON ed è utile nell'analisi delle informazioni sull'host. Dalla connessione SSH aperta, immettere il comando seguente per installare
jq:sudo apt -y install jqConfigurare la variabile di password. Sostituire
PASSWORDcon la password di accesso al cluster e quindi immettere il comando:export PASSWORD='PASSWORD'Estrarre il nome del cluster con l'uso corretto di maiuscole e minuscole. L'uso effettivo di maiuscole e minuscole nel nome del cluster può differire dal previsto, a seconda della modalità di creazione del cluster. Questo comando otterrà la combinazione di maiuscole e minuscole effettiva e quindi la archivierà in una variabile. Immettere il comando seguente:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Nota
Se si esegue questo processo dall'esterno del cluster, è disponibile una procedura diversa per l'archiviazione del nome del cluster. Recuperare il nome del cluster in lettere minuscole dal portale di Azure. Sostituire quindi
<clustername>con il nome del cluster nel comando seguente ed eseguire il comando:export clusterName='<clustername>'.Per impostare una variabile di ambiente con le informazioni degli host Zookeeper, usare il comando seguente. Il comando recupera tutti gli host Zookeeper, quindi restituisce solo le prime due voci. per mantenere un certo livello di ridondanza nel caso in cui un host fosse irraggiungibile.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Nota
Questo comando richiede l'accesso ad Ambari. Se il cluster è protetto da un gruppo NSG, eseguire questo comando da un computer in grado di accedere ad Ambari.
Usare il comando seguente per verificare che la variabile di ambiente sia impostata correttamente:
echo $KAFKAZKHOSTSQuesto comando restituisce informazioni simili al testo seguente:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Per impostare una variabile di ambiente con le informazioni degli host broker Apache Kafka, usare il comando seguente:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Nota
Questo comando richiede l'accesso ad Ambari. Se il cluster è protetto da un gruppo NSG, eseguire questo comando da un computer in grado di accedere ad Ambari.
Usare il comando seguente per verificare che la variabile di ambiente sia impostata correttamente:
echo $KAFKABROKERSQuesto comando restituisce informazioni simili al testo seguente:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Gestire gli argomenti di Apache Kafka
Kafka archivia i flussi di dati in argomenti. Per gestire gli argomenti è possibile usare l'utilità kafka-topics.sh.
Per creare un argomento usare il comando seguente nella connessione SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSQuesto comando si connette a Broker usando le informazioni sull'host archiviate in
$KAFKABROKERS. e quindi crea un argomento di Apache Kafka denominato test.I dati archiviati in questo argomento vengono divisi in otto partizioni.
Ogni partizione è replicata in tre nodi di ruolo di lavoro nel cluster.
Se il cluster è stato creato in un'area di Azure con tre domini di errore, usare il fattore di replica 3. In caso contrario usare il fattore di replica 4.
Nelle aree con tre domini di errore, il fattore di replica 3 consente di distribuire le repliche tra i domini di errore. Nelle aree con due domini di errore, il fattore di replica 4 distribuisce le repliche uniformemente tra i domini.
Per informazioni sul numero di domini di errore in un'area, vedere il documento Disponibilità delle macchine virtuali Linux.
Apache Kafka non rileva i domini di errore di Azure. Quando si creano le repliche di partizione per gli argomenti, è possibile che le repliche non vengano distribuite in modo corretto per la disponibilità elevata.
Per garantire la disponibilità elevata, usare lo strumento per il ribilanciamento delle partizioni Apache Kafka. Questo strumento deve essere eseguito da una connessione SSH al nodo head del cluster Apache Kafka.
Per garantire la massima disponibilità dei dati Apache Kafka, è consigliabile ribilanciare le repliche di partizione per l'argomento nelle situazioni seguenti:
Quando si crea un nuovo argomento o una nuova partizione
Quando si aumentano le prestazioni di un cluster
Per elencare gli argomenti usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSQuesto comando consente di elencare gli argomenti disponibili nel cluster Apache Kafka.
Per eliminare un argomento usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSQuesto comando elimina l'argomento denominato
topicname.Avviso
Se si elimina l'argomento
testcreato in precedenza, è necessario crearlo di nuovo. Questo argomento si userà in passaggi indicati più avanti in questo documento.
Per altre informazioni sui comandi disponibili con l'utilità kafka-topics.sh, usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produrre e utilizzare record
Kafka archivia i record in argomenti. I record vengono prodotti da producer e usati da consumer. I producer e i consumer comunicano con il servizio broker Kafka. Ogni nodo del ruolo di lavoro nel cluster HDInsight è un host del broker Apache Kafka.
Seguire questa procedura per archiviare i record nell'argomento test creato in precedenza e quindi leggerli usando un consumer:
Per scrivere i record nell'argomento usare l'utilità
kafka-console-producer.shdalla connessione SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testDopo questo comando viene visualizzata una riga vuota.
Digitare un messaggio di testo nella riga vuota e premere INVIO. Digitare invece alcuni messaggi in questo modo e quindi usare Ctrl + C per tornare al prompt normale. Ogni riga viene inviata come record distinto all'argomento Apache Kafka.
Per scrivere i record dall'argomento usare l'utilità
kafka-console-consumer.shdalla connessione SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningQuesto comando recupera i record dall'argomento e li visualizza. L'uso di
--from-beginningindica al consumer di partire dall'inizio del flusso, quindi verranno recuperati tutti i record.Se si usa una versione meno recente di Kafka, sostituire
--bootstrap-server $KAFKABROKERScon--zookeeper $KAFKAZKHOSTS.Usare Ctrl + C per arrestare il consumer.
È possibile creare producer e consumer anche a livello di codice. Per un esempio dell'uso di questa API, vedere il documento relativo alle API Producer e Consumer Apache Kafka con HDInsight.
Pulire le risorse
Per pulire le risorse create da questa guida introduttiva, è possibile eliminare il gruppo di risorse. Se si elimina il gruppo di risorse, vengono eliminati anche il cluster HDInsight associato e tutte le altre risorse correlate al gruppo di risorse.
Per rimuovere il gruppo di risorse usando il portale di Azure:
- Nel portale di Azure espandere il menu a sinistra per aprire il menu dei servizi e quindi scegliere Gruppi di risorse per visualizzare l'elenco dei gruppi di risorse.
- Individuare il gruppo di risorse da eliminare e quindi fare clic con il pulsante destro del mouse su Altro (...) a destra dell'elenco.
- Scegliere Elimina gruppo di risorse e quindi confermare.
Avviso
Se si elimina un cluster Apache Kafka in HDInsight, vengono eliminati anche eventuali dati archiviati in Kafka.