Creare un cluster Spark in HDInsight nel servizio Azure Kubernetes (anteprima)
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure disponibili in versione beta, in anteprima o non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti nella community di Azure HDInsight.
Dopo aver completato i prerequisiti della sottoscrizione e i prerequisiti delle risorse e aver distribuito un pool di cluster, continuare a usare il portale di Azure per creare un cluster Spark. È possibile usare il portale di Azure per creare un cluster Apache Spark nel pool di cluster. È quindi possibile creare un notebook di Jupyter e usarlo per eseguire query Spark SQL sulle tabelle Apache Hive.
Nella portale di Azure digitare pool di cluster e selezionare pool di cluster per passare alla pagina pool di cluster. Nella pagina Pool di cluster selezionare il pool di cluster in cui è possibile aggiungere un nuovo cluster Spark.
Nella pagina specifica del pool di cluster fare clic su + Nuovo cluster.
Questo passaggio apre la pagina di creazione del cluster.
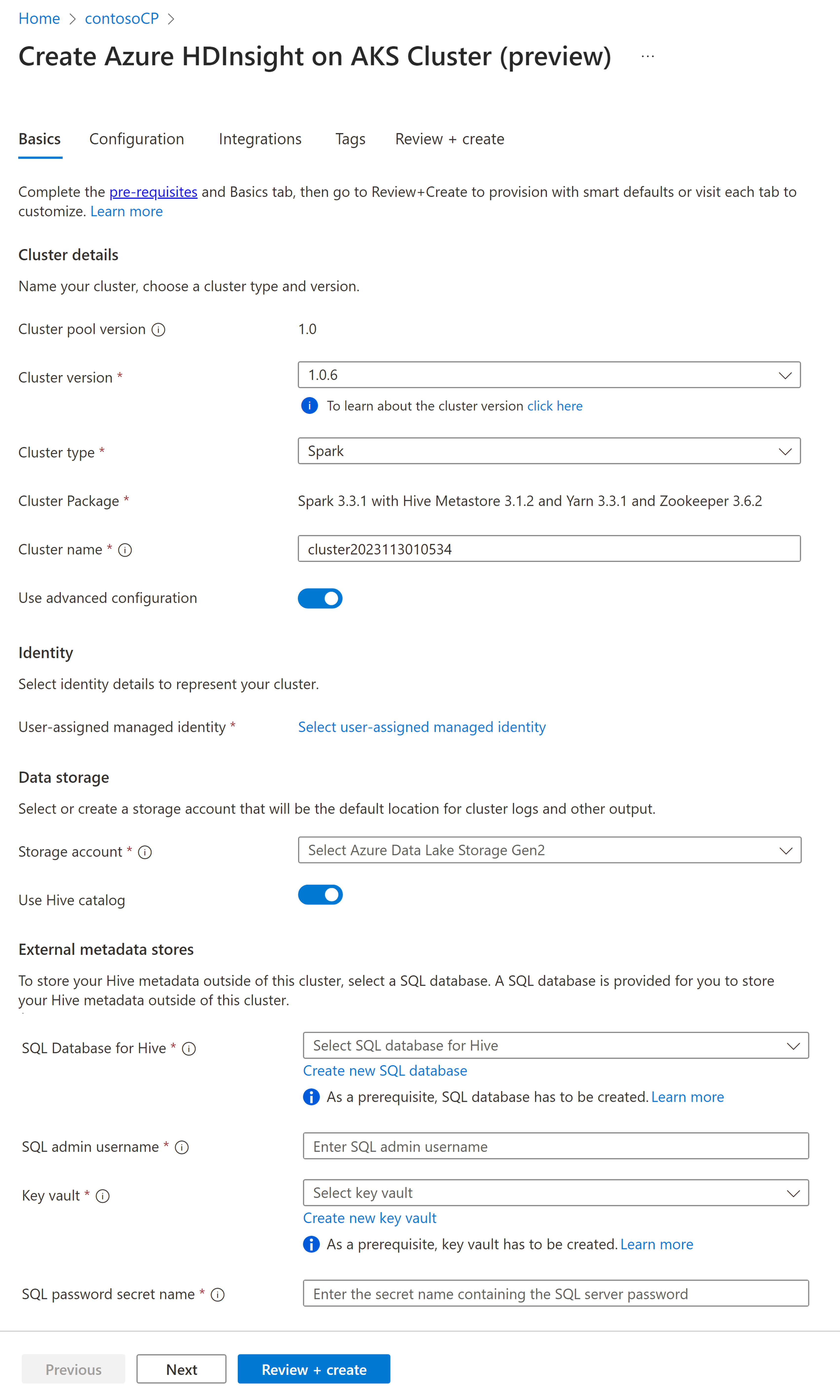
Proprietà Descrizione Abbonamento La sottoscrizione di Azure registrata per l'uso con HDInsight nel servizio Azure Kubernetes nella sezione Prerequisiti con essere prepopolata Gruppo di risorse Lo stesso gruppo di risorse del pool di cluster verrà prepopolato Paese La stessa area del pool di cluster e della macchina virtuale verrà prepopolato Pool di cluster Il nome del pool di cluster verrà prepopolato Versione del pool HDInsight La versione del pool di cluster verrà prepopolato dalla selezione della creazione del pool HDInsight nella versione del servizio Azure Kubernetes Specificare l'infrastruttura HDI nella versione del servizio Azure Kubernetes Tipo di cluster Nell'elenco a discesa selezionare Spark Versione cluster Selezionare la versione della versione dell'immagine da usare Nome cluster Immettere il nome del nuovo cluster Identità gestita assegnata dall'utente Selezionare l'identità gestita assegnata dall'utente che funzionerà come stringa di connessione con l'archiviazione Account di archiviazione Selezionare l'account di archiviazione precedentemente creato che deve essere usato come risorsa di archiviazione primaria per il cluster Nome contenitore Selezionare il nome del contenitore (univoco) se è stato creato o creato un nuovo contenitore Catalogo Hive (facoltativo) Selezionare il metastore Hive creato in anteprima (database SQL di Azure) Database SQL per Hive Nell'elenco a discesa, selezionare il database SQL in cui aggiungere tabelle hive-metastore. Nome utente amministratore SQL Immettere il nome utente dell'amministratore SQL Insieme di credenziali delle chiavi Nell'elenco a discesa selezionare l'insieme di credenziali delle chiavi, che contiene un segreto con password per il nome utente amministratore SQL Nome del segreto password SQL Immettere il nome del segreto dall'insieme di credenziali delle chiavi in cui è archiviata la password del database SQL Nota
- Attualmente HDInsight supporta solo i database MS SQL Server.
- A causa della limitazione di Hive, il carattere "-" (trattino) nel nome del database metastore non è supportato.
Selezionare Avanti: Configurazione e prezzi per continuare.


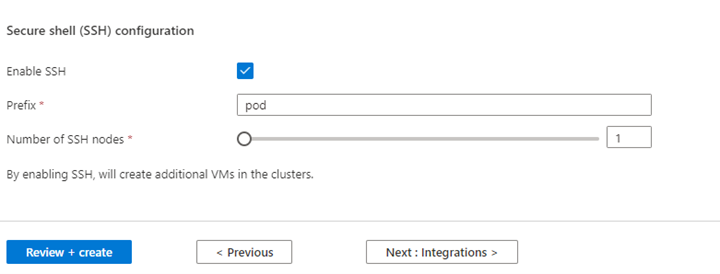
Proprietà Descrizione Dimensioni nodo Selezionare le dimensioni del nodo da usare per i nodi Spark Numero di nodi di lavoro Selezionare il numero di nodi per il cluster Spark. Al di fuori di questi, tre nodi sono riservati per coordinatori e servizi di sistema, i nodi rimanenti sono dedicati ai ruoli di lavoro Spark, un ruolo di lavoro per nodo. Ad esempio, in un cluster a cinque nodi sono presenti due ruoli di lavoro Autoscale Fare clic sul pulsante Attiva/Disattiva per abilitare la scalabilità automatica Tipo di scalabilità automatica Selezionare una scalabilità automatica basata sul carico o su pianificazione Timeout di decomissione normale Specificare il timeout delle autorizzazioni graceful Nessun nodo di lavoro predefinito Selezionare il numero di nodi per la scalabilità automatica Fuso orario Selezionare il fuso orario Regole di scalabilità automatica Selezionare il giorno, l'ora di inizio, l'ora di fine, no. dei nodi di lavoro Abilitare SSH Se abilitata, consente di definire il prefisso e il numero di nodi SSH Fare clic su Avanti : Integrazioni per abilitare e selezionare Log Analytics per la registrazione.
È possibile abilitare Azure Prometheus per il monitoraggio e le metriche dopo la creazione del cluster.
Fare clic su Avanti: Tag per passare alla pagina successiva.

Nella pagina Tag immettere i tag da aggiungere alla risorsa.
Proprietà Descrizione Name Facoltativo. Immettere un nome, ad esempio HDInsight nell'anteprima privata del servizio Azure Kubernetes, per identificare facilmente tutte le risorse associate alle risorse Valore Lasciare vuoto questo campo Conto risorse Selezionare Tutte le risorse selezionate Fare clic su Avanti: Rivedi e crea.
Nella pagina Rivedi e crea cercare il messaggio Convalida riuscita nella parte superiore della pagina e quindi fare clic su Crea.
Viene visualizzata la pagina Distribuzione in fase di elaborazione che viene creata dal cluster. La creazione del cluster richiede 5-10 minuti. Dopo aver creato il cluster, viene visualizzato il messaggio Di completamento della distribuzione. Se si esce dalla pagina, è possibile controllare lo stato delle notifiche.
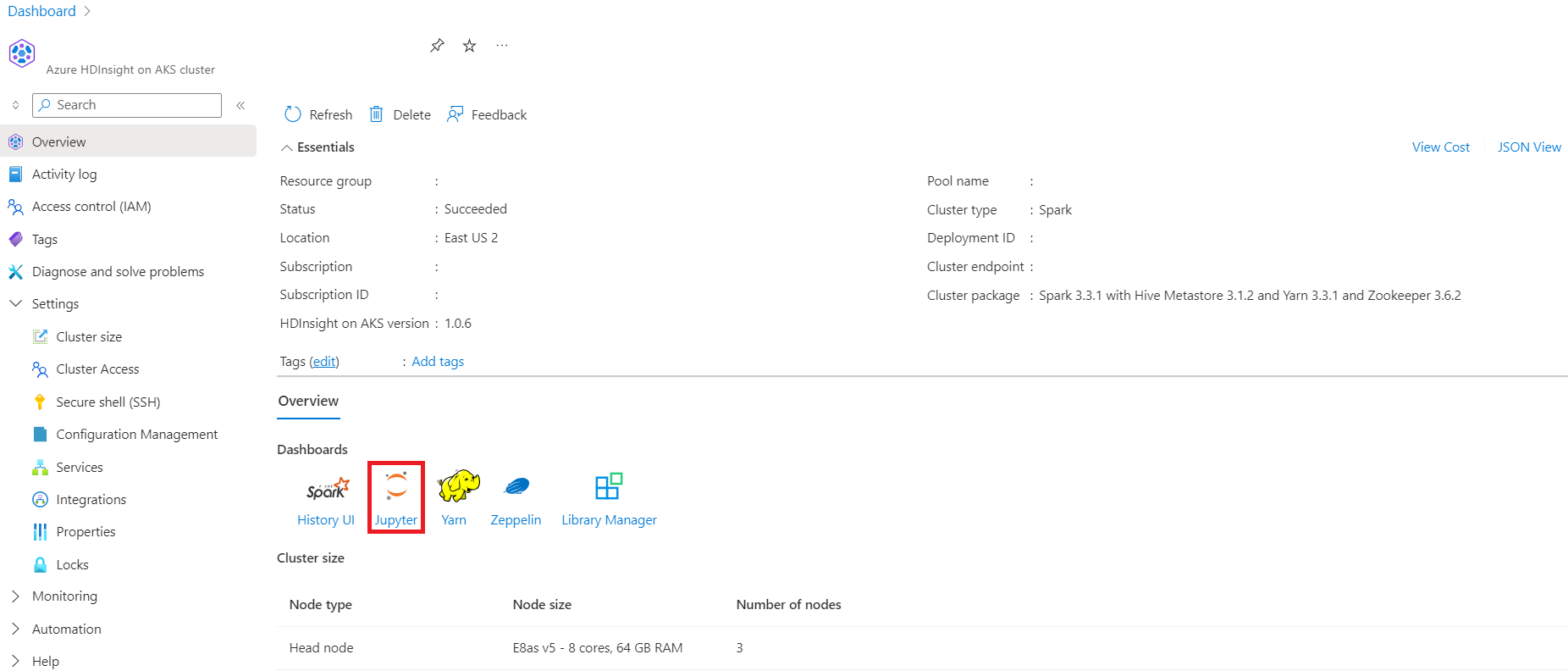
Passare alla pagina di panoramica del cluster. È possibile visualizzare i collegamenti agli endpoint.








Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per