Configurare la memorizzazione nella cache
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Solo il supporto di base sarà disponibile fino alla data di ritiro.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
L'esecuzione di query sull'archiviazione di oggetti tramite il connettore Hive è un caso d'uso comune per Trino. Questo processo comporta spesso l'invio di grandi quantità di dati. Gli oggetti vengono recuperati da HDFS o da un altro archivio oggetti supportato da più worker ed elaborati da tali worker. Query ripetute con parametri diversi o anche query diverse da utenti diversi spesso accedono e trasferiscono gli stessi oggetti.
HDInsight su AKS ha aggiunto funzionalità di memorizzazione nella cache del risultato finale per Trino, che offre i vantaggi seguenti:
- Ridurre il carico sull'archivio oggetti.
- Migliorare le prestazioni delle query.
- Ridurre il costo delle query.
Opzioni di memorizzazione nella cache
Varie opzioni per la memorizzazione nella cache:
- Memorizzazione nella cache del risultato finale: se abilitata (nella sezione di configurazione del componente coordinator), viene restituito un risultato per qualsiasi query per qualsiasi cache di catalogo in una VM coordinator.
- Memorizzazione nella cache del catalogo Hive/Iceberg/Delta Lake: se abilitata (per un catalogo specifico di tipo corrispondente), i dati suddivisi per ogni cache di query all'interno del cluster nelle VM worker.
Memorizzazione nella cache del risultato finale
La memorizzazione nella cache del risultato finale può essere configurata in due modi:
I parametri di configurazione disponibili sono:
| Proprietà | Predefinito | Descrizione |
|---|---|---|
query.cache.enabled |
false | Abilita la memorizzazione nella cache del risultato finale se è true. |
query.cache.ttl |
- | Definisce un periodo di tempo fino a quando i dati della cache vengono mantenuti prima della rimozione. Ad esempio: "10 m", "1 h" |
query.cache.disk-usage-percentage |
80 | Percentuale di spazio su disco usato per i dati memorizzati nella cache. |
query.cache.max-result-data-size |
0 | Dimensioni massime dei dati per un risultato. Se questo valore è stato superato, il risultato non viene memorizzato nella cache. |
Nota
La memorizzazione nella cache del risultato finale usa il piano di query e ttl come chiave della cache.
La memorizzazione nella cache del risultato finale può essere controllata anche tramite i parametri di sessione seguenti:
| Parametro di sessione | Default | Descrizione |
|---|---|---|
query_cache_enabled |
Valore di configurazione originale | Abilita/disabilita la memorizzazione nella cache del risultato finale per una query/sessione. |
query_cache_ttl |
Valore di configurazione originale | Definisce un periodo di tempo fino a quando i dati della cache vengono mantenuti prima della rimozione. |
query_cache_max_result_data_size |
Valore di configurazione originale | Dimensioni massime dei dati per un risultato. Se questo valore è stato superato, il risultato non viene memorizzato nella cache. |
query_cache_forced_refresh |
false | Se impostato su true, forza la memorizzazione nella cache del risultato dell'esecuzione della query; il risultato sostituisce eventuali dati memorizzati nella cache esistenti. |
Nota
I parametri di sessione possono essere impostati per una sessione (ad esempio se viene usata l'interfaccia della riga di comando di Trino) o possono essere impostati in istruzioni multiple prima del testo della query. ad esempio:
set session query_cache_enabled=true;
select cust.name, *
from tpch.tiny.orders
join tpch.tiny.customer as cust on cust.custkey = orders.custkey
order by cust.name
limit 10;
La memorizzazione nella cache del risultato finale produce metriche JMX che possono essere visualizzate usando Prometheus gestito e Grafana. Sono disponibili le metriche seguenti:
| Metrico | Descrizione |
|---|---|
trino_cache_cachestats_requestcount |
Numero totale di query che passano attraverso il livello della cache. Questo numero non include le query eseguite con la cache disattivata. |
trino_cache_cachestats_hitcount |
Numero di riscontri nella cache, ossia il numero di query quando i dati erano disponibili e restituiti dalla cache. |
trino_cache_cachestats_misscount |
Numero di mancati riscontri nella cache, ossia il numero di query quando i dati non erano disponibili e dovevano essere memorizzati nella cache. |
trino_cache_cachestats_hitrate |
Rappresentazione percentuale dei riscontri nella cache rispetto al numero totale di query. |
trino_cache_cachestats_totalevictedcount |
Numero di query memorizzate nella cache rimosse dalla cache. |
trino_cache_cachestats_totalbytesfromsource |
Numero di byte letti dall'origine. |
trino_cache_cachestats_totalbytesfromcache |
Numero di byte letti dalla cache. |
trino_cache_cachestats_totalcachedbytes |
Numero totale di byte memorizzati nella cache. |
trino_cache_cachestats_totalevictedbytes |
Numero totale di byte rimossi. |
trino_cache_cachestats_spaceused |
Dimensioni correnti della cache. |
trino_cache_cachestats_cachereadfailures |
Numero di volte in cui i dati non possono essere letti dalla cache a causa di un errore. |
trino_cache_cachestats_cachewritefailures |
Numero di volte in cui i dati non possono essere scritti nella cache a causa di un errore. |
Con il portale di Azure
Accedi al portale di Azure.
Nella barra di ricerca del portale di Azure digita "HDInsight nel cluster del servizio Azure Kubernetes" e seleziona "Azure HDInsight nei cluster del servizio Azure Kubernetes" nell'elenco a discesa.

Selezionare il nome del cluster dalla pagina dell'elenco.
Passare al pannello Gestione della configurazione.
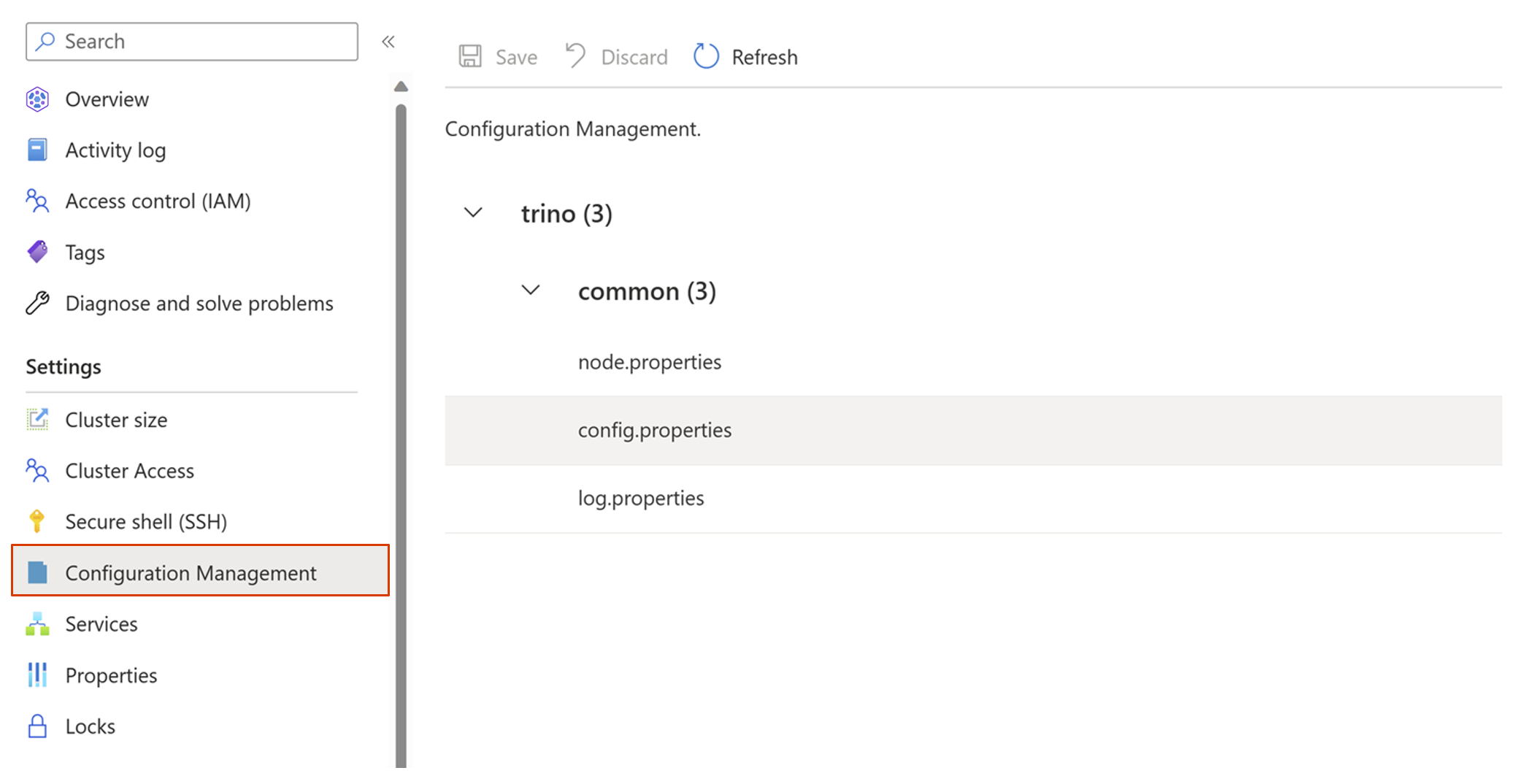
Passare a config.properties -> Configurazioni personalizzate e quindi fare clic su Aggiungi.
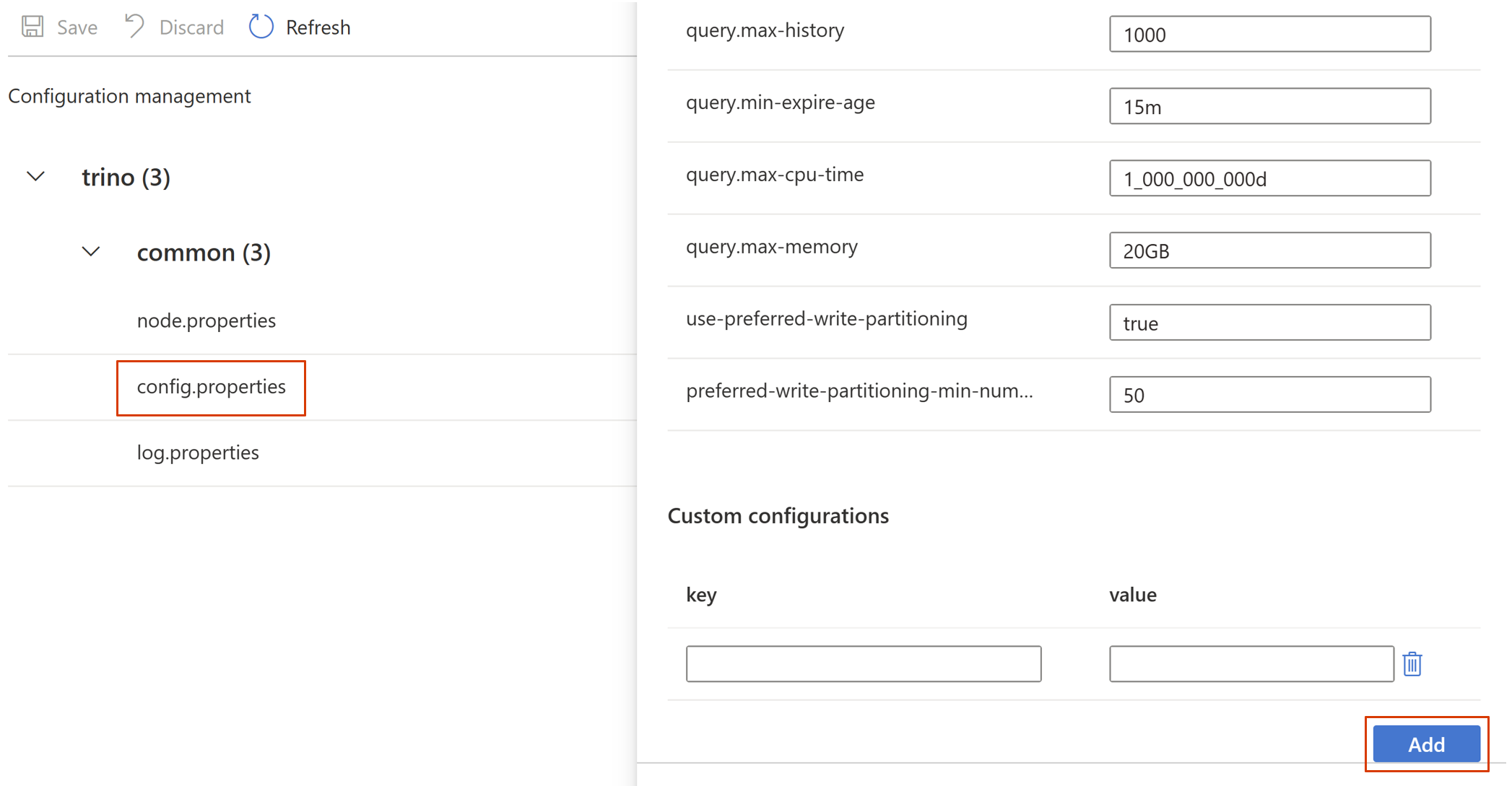
Impostare le proprietà necessarie e fare clic su OK.
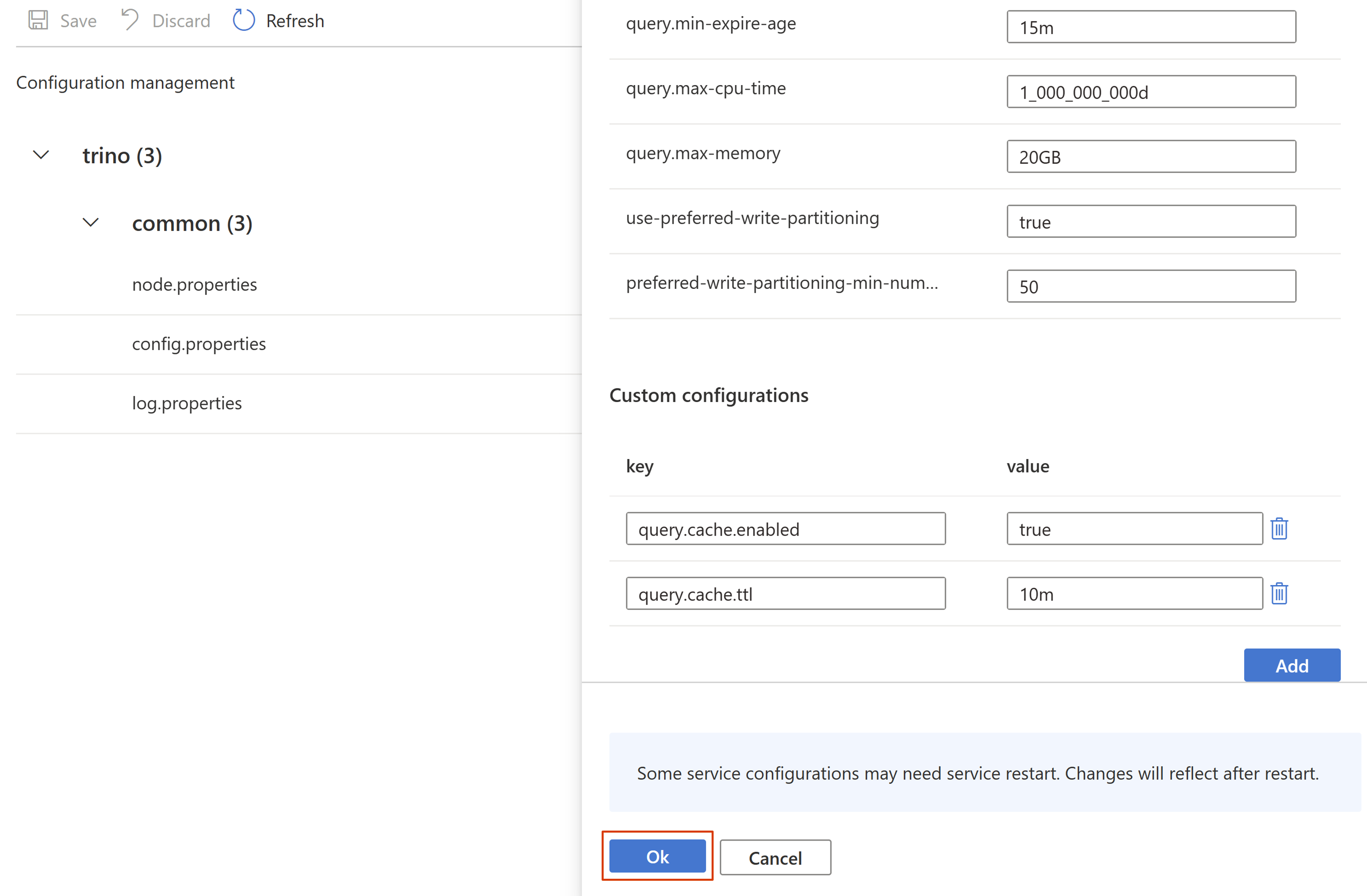
Fare clic su Salva per salvare la configurazione.
Uso di un modello di Resource Manager
Prerequisiti
- Cluster Trino operativo con HDInsight su AKS.
- Creare un modello di Resource Manager per il cluster.
- Esaminare l’esempio del modello di Resource Manager del cluster completo.
- Familiarità con la creazione e la distribuzione di un modello di ARM.
È necessario definire le proprietà nel componente coordinator nella sezione properties.clusterProfile.serviceConfigsProfiles del modello di ARM.
L'esempio seguente spiega dove aggiungere le proprietà.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "coordinator",
"files": [
{
"fileName": "config.properties",
"values": {
"query.cache.enabled": "true",
"query.cache.ttl": "10m"
}
}
]
}
]
}
]
}
}
}
]
}
Memorizzazione nella cache Hive/Iceberg/Delta Lake
Tutti e tre i connettori condividono lo stesso set di parametri descritto in memorizzazione nella cache di Hive.
Nota
Determinati parametri non sono configurabili e sono sempre impostati sui loro valori predefiniti:
hive.cache.data-transfer-port=8898,
hive.cache.bookkeeper-port=8899,
hive.cache.location=/etc/trino/cache,
hive.cache.disk-usage-percentage=80
L'esempio seguente spiega dove aggiungere le proprietà per abilitare la memorizzazione nella cache di Hive usando un modello di ARM.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "catalogs",
"files": [
{
"fileName": "hive1.properties",
"values": {
"connector.name": "hive"
"hive.cache.enabled": "true",
"hive.cache.ttl": "5d"
}
}
]
}
]
}
]
}
}
}
]
}
Distribuire il modello di Resource Manager aggiornato per riflettere le modifiche nel cluster. Informazioni su come distribuire un modello di Resource Manager.