Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In genere è necessario pulire e trasformare i dati in ingresso prima di caricarli in una destinazione adatta all'analisi. Le operazioni di estrazione, trasformazione e caricamento consentono di preparare i dati e caricarli in una destinazione dati. Apache Hive in HDInsight è in grado di leggere i dati non strutturati, elaborare i dati in base alle esigenze e quindi caricarli in un data warehouse relazionale per sistemi di supporto decisionale. In questo approccio, i dati vengono estratti dall'origine. Quindi archiviato in un archivio adattabile, ad esempio BLOB di Archiviazione di Azure o azure Data Lake Archiviazione. I dati vengono quindi trasformati usando una sequenza di query Hive. Viene quindi inserita in staging all'interno di Hive in preparazione per il caricamento bulk nell'archivio dati di destinazione.
Panoramica del caso d'uso e del modello
La figura seguente mostra una panoramica del caso d'uso e del modello per l'automazione ETL. I dati di input vengono trasformati per generare l'output appropriato. Durante tale trasformazione, i dati cambiano forma, tipo di dati e anche lingua. I processi ETL possono convertire unità imperiali in unità di misura decimali, modificare i fusi orari e migliorare la precisione per un corretto allineamento con i dati esistenti nella destinazione. I processi ETL possono anche combinare nuovi dati con i dati esistenti per mantenere aggiornati i report o fornire ulteriori informazioni sui dati esistenti. Le applicazioni come gli strumenti di creazione di report e i servizi possono quindi utilizzare questi dati nel formato desiderato.
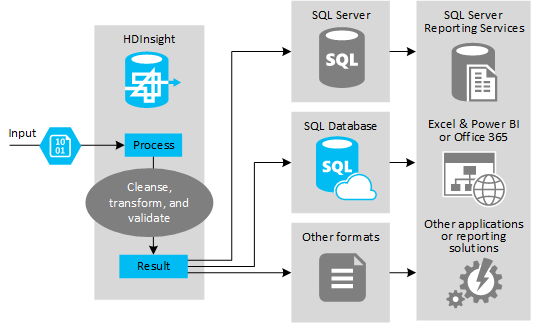
Hadoop viene in genere usato nei processi ETL che importano un numero elevato di file di testo ,ad esempio i volumi condivisi cluster. Oppure un numero di file di testo più piccolo ma spesso modificato o entrambi. Hive è un ottimo strumento per preparare i dati prima di caricarli nella destinazione dati. Hive consente di creare uno schema tramite il file CSV e di usare un linguaggio simile a SQL per generare programmi di MapReduce che interagiscono con i dati.
I passaggi tipici per l'uso di Hive per eseguire ETL sono i seguenti:
Caricare dati in Azure Data Lake Storage o nell'archivio BLOB di Azure.
Creare un database dell'archivio di metadati tramite il database SQL di Azure per la memorizzazione degli schemi da parte di Hive.
Creare un cluster HDInsight e connettere l'archivio dati.
Definire lo schema da applicare in fase di lettura dei dati nell'archivio dati:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Trasformare i dati e caricarli nella destinazione. È possibile usare Hive in diversi modi durante la trasformazione e il caricamento:
- Eseguire query e preparare i dati usando Hive e salvarli come file CSV in Azure Data Lake Storage o nell'archivio BLOB di Azure. Usare quindi uno strumento come SQL Server Integration Services (SSIS) per acquisire i file CSV e caricare i dati in un database relazionale di destinazione, ad esempio SQL Server.
- Eseguire query sui dati direttamente da Excel o C# tramite il driver ODBC di Hive.
- Usare Apache Sqoop per leggere i file CSV flat preparati e caricarli nel database relazionale di destinazione.
Origini dati
Le origini dati in genere sono rappresentate da dati esterni corrispondenti a dati esistenti nell'archivio dati, ad esempio:
- Dati relativi ai social media, file di log, sensori e applicazioni che generano file di dati.
- Set di dati ottenuti dai provider di dati, ad esempio statistiche sul meteo o cifre di vendita.
- Dati in streaming acquisiti, filtrati ed elaborati tramite un framework o uno strumento appropriato.
Destinazioni di output
È possibile usare Hive per restituire i dati a diversi tipi di destinazioni, tra cui:
- Un database relazionale, ad esempio SQL Server o un database SQL di Azure.
- Un data warehouse, ad esempio Azure Synapse Analytics.
- Excel.
- Una tabella e un archivio BLOB di Azure.
- Applicazioni o servizi che richiedono l'elaborazione dei dati in formati specifici, oppure file che contengono tipi specifici di struttura delle informazioni.
- Archivio documenti JSON come Azure Cosmos DB.
Considerazioni
Il modello ETL in genere viene usato per:
* Caricare dati di flusso o grandi volumi di dati semistrutturati o non strutturati da origini esterne in un database o un sistema informativo esistente.
* Pulire, trasformare e convalidare i dati prima di caricarli, ad esempio usando più trasformazioni passate attraverso il cluster.
* Generare report e visualizzazioni che vengono aggiornate regolarmente. Ad esempio, se la generazione di un report richiede troppo tempo durante il giorno, è possibile pianificarne l'esecuzione durante la notte. Per eseguire automaticamente una query Hive, è possibile usare App per la logica di Azure e PowerShell.
Se la destinazione per i dati non è un database, è possibile generare un file nel formato appropriato all'interno della query, ad esempio un file CSV. Questo file può essere quindi importato in Excel o in Power BI.
Se è necessario eseguire diverse operazioni sui dati come parte del processo ETL, valutare la relativa modalità di gestione. Con le operazioni controllate da un programma esterno, anziché come flusso di lavoro all'interno della soluzione, decidere se alcune operazioni possono essere eseguite in parallelo. E per rilevare il completamento di ogni processo. Potrebbe essere più semplice usare un meccanismo di flusso di lavoro, ad esempio Oozie in Hadoop, che tentare di orchestrare una sequenza di operazioni mediante script esterni o programmi personalizzati.