Estrarre, trasformare e caricare (ETL) su larga scala
Il processo di estrazione, trasformazione e caricamento (ETL, Extract, Transform, and Load) è il processo mediante il quale i dati vengono acquisiti da varie origini. I dati vengono raccolti in una posizione standard, puliti, elaborati e infine caricati in un archivio dati da cui è possibile eseguire query. I processi ETL legacy importano i dati, li puliscono sul posto e quindi li archiviano in un motore dati relazionale. Con Azure HDInsight, un'ampia gamma di componenti dell'ambiente Apache Hadoop supporta i processi ETL su larga scala.
L'uso di HDInsight nel processo ETL è illustrato da questa pipeline:
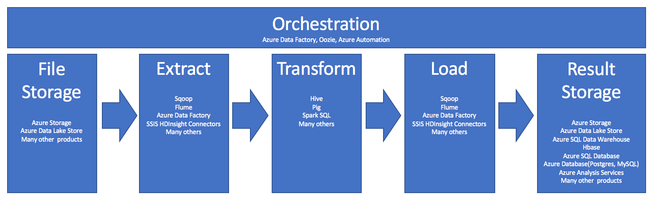
Le sezioni seguenti illustrano ogni fase del processo ETL e i relativi componenti associati.
Orchestrazione
L'orchestrazione comprende tutte le fasi della pipeline ETL. I processi ETL in HDInsight interessano spesso prodotti diversi che funzionano in combinazione tra loro. Ad esempio:
- È possibile usare Apache Hive per pulire una parte dei dati e Apache Pig per pulire un'altra parte.
- È possibile usare Azure Data Factory per caricare i dati nel database SQL di Azure da Azure Data Lake Store.
L'orchestrazione è necessaria per eseguire il processo appropriato al momento giusto.
Apache Oozie
Apache Oozie è un sistema di coordinamento dei flussi di lavoro che consente di gestire i processi Hadoop. Viene eseguito all'interno di un cluster HDInsight ed è integrato con lo stack di Hadoop. Oozie supporta i processi Hadoop per Apache Hadoop MapReduce, Pig, Hive e Sqoop. Oozie può essere usato per pianificare processi specifici di un sistema, come programmi Java o script della shell.
Per altre informazioni, vedere Usare Apache Oozie con Hadoop per definire ed eseguire un flusso di lavoro in HDInsight. Vedere anche Rendere operativa una pipeline di analisi dei dati.
Azure Data Factory
Azure Data Factory offre funzionalità di orchestrazione sotto forma di piattaforma distribuita come servizio (PaaS). Azure Data Factory è un servizio di integrazione dati basato su cloud. Consente di creare flussi di lavoro basati sui dati per orchestrare e automatizzare le attività di spostamento e trasformazione dei dati.
Usare Azure Data Factory per eseguire le operazioni seguenti:
- Creare e pianificare flussi di lavoro basati sui dati. In queste pipeline vengono inseriti dati provenienti da archivi diversi.
- Elaborare e trasformare i dati usando servizi di calcolo, ad esempio HDInsight o Hadoop. Per questo passaggio è anche possibile usare Spark, Azure Data Lake Analytics, Azure Batch o Azure Machine Learning.
- Pubblicare i dati di output negli archivi dati, ad esempio Azure Synapse Analitica, per consentire alle applicazioni BI di usare.
Per altre informazioni su Azure Data Factory, vedere la documentazione.
Inserire dati nell'archiviazione file e nell'archivio risultati
I file di dati di origine vengono in genere caricati in una posizione di Archiviazione di Azure o di Azure Data Lake Store. I file sono in genere in formato flat, ad esempio CSV, ma possono essere in qualsiasi formato.
Archiviazione di Azure
Archiviazione di Azure presenta obiettivi di adattabilità specifici. Per altre informazioni, vedere Obiettivi di scalabilità e prestazioni per l'archiviazione BLOB. Per la maggior parte dei nodi analitici, le prestazioni di Archiviazione di Azure risultano ottimali quando vengono gestiti molti file di piccole dimensioni. A condizione che non vengano superati i limiti, Archiviazione di Azure garantisce prestazioni identiche, a prescindere dalle dimensioni dei file. È possibile archiviare terabyte di dati e ottenere comunque prestazioni coerenti. Questa affermazione è vera indipendentemente dal fatto che si usi un subset o la totalità dei dati.
Archiviazione di Azure ha diversi tipi di BLOB. Un BLOB di aggiunta è un'ottima scelta per archiviare blog o dati sensore.
Più BLOB possono essere distribuiti in più server per migliorare la possibilità di accesso, ma un singolo BLOB viene servito da un solo server. Anche se i BLOB possono essere raggruppati logicamente in contenitori di BLOB, non vi sono implicazioni sul partizionamento derivanti da questo raggruppamento.
Archiviazione di Azure include anche un livello API WebHDFS per l'archiviazione dei BLOB. Tutti i servizi HDInsight possono accedere ai file in Archiviazione BLOB di Azure per la pulizia e l'elaborazione dei dati. Questa operazione è simile a quella usata dai servizi Hadoop Distributed File System (HDFS).
I dati vengono in genere inseriti in Archiviazione di Azure tramite PowerShell, Archiviazione di Azure SDK o AzCopy.
Archiviazione di Azure Data Lake
Azure Data Lake Storage è un repository gestito con iperscalabilità per i dati di analisi. È compatibile con un paradigma di progettazione simile a HDFS e fa uso di tale paradigma. Data Lake Storage offre un'adattabilità illimitata in termini di capacità totale e dimensioni dei singoli file. È una scelta ottimale quando si lavora con file di grandi dimensioni, perché possono essere archiviati in più nodi. Il partizionamento dei dati in Data Lake Storage viene eseguito dietro le quinte. Si ottiene una velocità effettiva molto elevata per l'esecuzione di processi di analisi con migliaia di esecutori simultanei che leggono e scrivono centinaia di terabyte di dati in modo efficiente.
I dati vengono in genere inseriti in Data Lake Storage tramite Azure Data Factory. È anche possibile usare Data Lake Storage SDK, il servizio AdlCopy, Apache DistCp o Apache Sqoop. Il servizio scelto dipende dalla posizione dei dati. Se si trovano in un cluster Hadoop esistente, si può usare Apache DistCp, il servizio AdlCopy o Azure Data Factory. Per i dati in Archiviazione BLOB di Azure, si può usare Azure Data Lake Storage .NET SDK, Azure PowerShell o Azure Data Factory.
Data Lake Storage è ottimizzato per l'inserimento di eventi tramite Hub eventi di Azure.
Considerazioni per entrambe le opzioni di archiviazione
Per il caricamento dei set di dati a livello di terabyte, la latenza di rete può costituire un problema grave. Ciò è particolarmente vero se i dati provengono da una posizione locale. In questi casi, è possibile usare le opzioni seguenti:
Azure ExpressRoute: creare connessioni private tra i data center di Azure e l'infrastruttura locale. Queste connessioni costituiscono un'opzione affidabile per il trasferimento di grandi quantità di dati. Per altre informazioni, vedere la Documentazione su ExpressRoute.
Caricamento dei dati da unità disco rigido: è possibile usare il servizio Importazione/Esportazione di Azure per spedire unità disco rigido con i dati a un data center di Azure. I dati vengono caricati prima di tutto in Archiviazione BLOB di Azure. È quindi possibile usare Azure Data Factory o lo strumento AdlCopy per copiare i dati da Archiviazione BLOB di Azure in Data Lake Storage.
Azure Synapse Analytics
Azure Synapse Analitica è una scelta appropriata per archiviare i risultati preparati. È possibile usare Azure HDInsight per eseguire questi servizi per Azure Synapse Analitica.
Azure Synapse Analitica è un archivio di database relazionale ottimizzato per i carichi di lavoro analitici. Viene ridimensionato in base a tabelle che possono essere partizionate tra più nodi. I nodi vengono selezionati al momento della creazione. Successivamente possono essere ridimensionati, ma si tratta di un processo attivo che può richiedere lo spostamento dei dati. Per altre informazioni, vedere Gestire le risorse di calcolo in Azure Synapse Analitica.
Apache HBase
Apache HBase è un archivio chiave-valore disponibile in Azure HDInsight. È un database NoSQL open source basato su Hadoop e modellato su Google BigTable. HBase offre accesso casuale e coerenza assoluta per quantità elevate di dati non strutturati e semistrutturati.
Poiché HBase è un database privo di schema, non è necessario definire le colonne e i tipi di dati prima di usarli. I dati sono archiviati nelle righe di una tabella e raggruppati in base al tipo di colonna.
Il codice open source offre scalabilità lineare, in modo da gestire petabyte di dati in migliaia di nodi. HBase può contare su ridondanza dei dati, elaborazione batch e altre funzionalità offerte dalle applicazioni distribuite nell'ambiente di Hadoop.
HBase è una buona destinazione per le analisi future di dati di log e di sensori.
L'adattabilità di HBase dipende dal numero di nodi del cluster HDInsight.
Database SQL di Azure
Azure offre tre database relazionali PaaS:
- Il database SQL di Azure è un'implementazione di Microsoft SQL Server. Per altre informazioni sulle prestazioni, vedere Ottimizzazione delle prestazioni del database SQL di Azure.
- Database di Azure per MySQL è un'implementazione di Oracle MySQL.
- Database di Azure per PostgreSQL è un'implementazione di PostgreSQL.
Per aumentare le prestazioni di questi prodotti incrementare la CPU e la memoria. Con questi prodotti è anche possibile scegliere di usare dischi premium per migliorare le prestazioni di I/O.
Azure Analysis Services
Azure Analysis Services è un motore di dati analitici usato per facilitare i processi decisionali e l'analisi aziendale, in grado di offrire i dati analitici per i report aziendali e le applicazioni client, ad esempio Power BI. I dati analitici funzionano anche con Excel, i report di SQL Server Reporting Services e altri strumenti di visualizzazione dei dati.
È possibile ridimensionare i cubi di analisi modificando i livelli per ogni singolo cubo. Per altre informazioni, vedere Prezzi di Azure Analysis Services.
Estrarre e caricare
Quando i dati sono presenti in Azure, è possibile estrarli e caricarli in altri prodotti tramite numerosi servizi. HDInsight supporta Sqoop e Flume.
Apache Sqoop
Apache Sqoop è uno strumento progettato per trasferire dati in modo efficiente tra origini strutturate, semistrutturate e non strutturate.
Sqoop usa MapReduce per l'importazione e l'esportazione dei dati per assicurare operazioni parallele e tolleranza di errore.
Apache Flume
Apache Flume è un servizio distribuito, affidabile e disponibile per raccogliere, aggregare e spostare in modo efficiente grandi quantità di dati di log. La sua architettura flessibile si basa sui flussi di dati in streaming. Flume è affidabile e a tolleranza d'errore con meccanismi di affidabilità ottimizzabili. Dispone di molti meccanismi di failover e di ripristino. Usa un modello di dati estensibile semplice per consentire applicazioni analitiche online.
Apache Flume non può essere usato con Azure HDInsight. Un'installazione locale di Hadoop può tuttavia usare Flume per inviare dati ad Archiviazione BLOB di Azure o ad Azure Data Lake Storage. Per altre informazioni, vedere Using Apache Flume with HDInsigh (Uso di Apache Flume con HDInsight).
Trasformazione
Quando i dati sono presenti nella posizione scelta, è necessario pulirli, combinarli o prepararli per un modello di utilizzo specifico. Hive, Pig e Spark SQL sono soluzioni ottime per questo tipo di attività e sono tutte supportate in HDInsight.