Accedere ai log dell'applicazione YARN di Apache Hadoop in HDInsight basato su Linux
Informazioni su come accedere ai log per le applicazioni Apache Hadoop YARN (Yet Another Resource Negotiator) in un cluster Apache Hadoop in Azure HDInsight.
Che cos'è Apache YARN?
YARN supporta diversi modelli di programmazione, tra cui Apache Hadoop MapReduce, separando la gestione delle risorse dalla pianificazione e dal monitoraggio dell'applicazione. YARN usa un'istanza globale ResourceManager (RM), node node NodeManagers (NMS) e ApplicationMasters (AMS) per applicazione. L'AM per applicazione negozia le risorse (CPU, memoria, disco e rete) per l'esecuzione dell'applicazione con l'RM. L'oggetto RM opera con gli oggetti NM per concedere queste risorse come contenitori. L'AM è responsabile del monitoraggio dello stato dei contenitori assegnati dall'RM. A seconda del tipo, un'applicazione può richiedere più contenitori.
Ogni applicazione può essere costituita da più tentativi dell'applicazione. Se si verifica un errore in un'applicazione, è possibile ripetere un nuovo tentativo. Ogni tentativo viene eseguito in un contenitore. In un certo senso, un contenitore fornisce il contesto per l'unità di lavoro di base eseguita da un'applicazione YARN. Tutte le operazioni eseguite all'interno del contesto di un contenitore vengono eseguite sul singolo nodo di lavoro in cui è stato assegnato il contenitore. Per altre informazioni di riferimento, vedere Hadoop: Scrittura di applicazioni YARN o Apache Hadoop YARN .
Per ridimensionare il cluster per supportare una maggiore velocità effettiva di elaborazione, è possibile usare la scalabilità automatica o ridimensionare manualmente i cluster usando alcuni linguaggi diversi.
Server di sequenza temporale YARN
Il server di sequenza temporale YARN di Apache Hadoop offre informazioni generiche sulle applicazioni completate
Il server di sequenza temporale YARN include i tipi di dati seguenti:
- ID applicazione, un identificatore univoco di un'applicazione
- Utente che ha avviato l'applicazione
- Informazioni sui tentativi effettuati per completare l'applicazione
- Contenitori usati da qualsiasi tentativo dell'applicazione specifico
Log e applicazioni YARN
I log applicazione (e i log contenitore associati) sono essenziali per il debug di applicazioni Hadoop problematiche. YARN offre un framework utile per la raccolta, l'aggregazione e l'archiviazione dei log applicazioni con aggregazione log.
La funzione di aggregazione dei log rende più deterministico l'accesso ai log dell'applicazione. Aggrega i log di tutti i contenitori in un nodo di lavoro e li archivia come file di log aggregati per ogni nodo di lavoro. Quando un'applicazione termina, il log viene archiviato nel file system predefinito. L'applicazione può usare centinaia o migliaia di contenitori, ma i log di tutti i contenitori eseguiti su un singolo nodo di lavoro vengono sempre aggregati in un unico file. È quindi presente un solo log per nodo di lavoro usato dall'applicazione. La funzione di aggregazione dei log è abilitata per impostazione predefinita nei cluster HDInsight versione 3.0 o successiva. I log aggregati sono disponibili nella risorsa di archiviazione predefinita per il cluster. Il percorso seguente è il percorso HDFS dei log:
/app-logs/<user>/logs/<applicationId>
In questo percorso, user è il nome dell'utente che ha avviato l'applicazione e applicationId è l'identificatore univoco assegnato a un'applicazione dall'oggetto YARN RM.
I log aggregati non sono direttamente leggibili, perché vengono scritti in un TFileformato binario indicizzato dal contenitore. Usare i log YARN ResourceManager o gli strumenti dell'interfaccia della riga di comando per visualizzare questi log come testo normale per applicazioni o contenitori di interesse.
Log yarn in un cluster ESP
È necessario aggiungere due configurazioni all'oggetto personalizzato mapred-site in Ambari.
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.netdoveCLUSTERNAMEè il nome del cluster.Dall'interfaccia utente di Ambari passare a MapReduce2 Configs Advanced Custom mapred-site (MapReduce2>Configs>Advanced>Custom mapred-site).
Aggiungere uno dei set di proprietà seguenti:
Imposta 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Imposta 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Salvare le modifiche e riavviare tutti i servizi interessati.
Strumenti dell’interfaccia di riga di comando YARN
Usare il comando ssh per connettersi al cluster. Modificare il comando seguente sostituendo CLUSTERNAME con il nome del cluster e quindi immettere il comando :
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netElencare tutti gli ID applicazione delle applicazioni YARN attualmente in esecuzione con il comando seguente:
yarn topPrendere nota dell'ID applicazione dalla
APPLICATIONIDcolonna i cui log devono essere scaricati.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerÈ possibile visualizzare questi log come testo normale eseguendo uno dei seguenti comandi:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Specificare le <informazioni applicationId>, <user-who-started-the-application, <containerId> e <worker-node-address> durante l'esecuzione> di questi comandi.
Altri comandi di esempio
Scaricare i log dei contenitori Yarn per tutti i master applicazioni con il comando seguente. Questo passaggio crea il file di log denominato
amlogs.txtin formato testo.yarn logs -applicationId <application_id> -am ALL > amlogs.txtScaricare i log dei contenitori YARN solo per gli schemi dell'applicazione più recenti con il comando seguente:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtScaricare i log dei contenitori YARN per i primi due schemi dell'applicazione con il comando seguente:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtScaricare tutti i log dei contenitori di YARN con il comando seguente:
yarn logs -applicationId <application_id> > logs.txtScaricare i log dei contenitori di YARN per un determinato contenitore con il comando seguente:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
INTERFACCIA UTENTE YARN ResourceManager
L'interfaccia utente yarn ResourceManager viene eseguita nel nodo head del cluster. È accessibile tramite l'interfaccia utente Web di Ambari. Per visualizzare i log di YARN, procedere come segue:
Nel Web browser passare a
https://CLUSTERNAME.azurehdinsight.net. Sostituire CLUSTERNAME con il nome del cluster HDInsight.Nell'elenco dei servizi a sinistra, selezionare YARN.
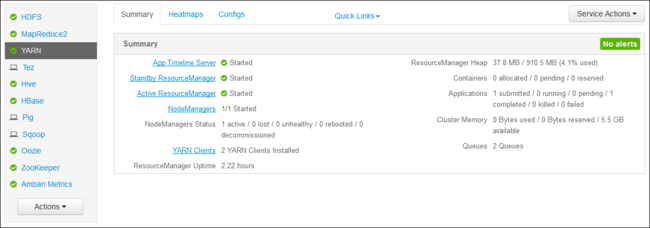
Nell'elenco a discesa Collegamenti rapidi selezionare uno dei nodi head del cluster e quindi selezionare
ResourceManager Log.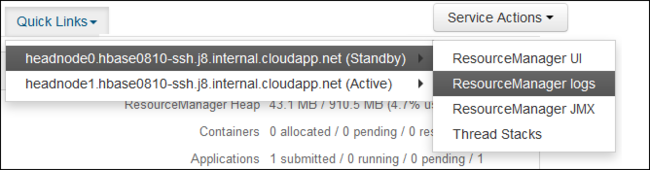
Viene visualizzato un elenco di collegamenti ai log YARN.