Monitorare le prestazioni del cluster in Azure HDInsight
Monitorare l'integrità e le prestazioni di un cluster HDInsight è fondamentale per mantenere livelli ottimali di prestazioni e di utilizzo delle risorse. Il monitoraggio agevola l'individuazione e la risoluzione degli errori di configurazione del cluster e dei problemi del codice utente.
Le sezioni seguenti illustrano come monitorare e ottimizzare il carico nei cluster, le code Apache Hadoop YARN e come rilevare i problemi di limitazione del servizio di archiviazione.
Monitorare il carico del cluster
I cluster Hadoop offrono prestazioni ottimali quando il carico nel cluster viene distribuito in modo uniforme su tutti i nodi. In questo modo le attività di elaborazione vengono eseguite senza essere limitate da RAM, CPU o risorse del disco nei singoli nodi.
Per esaminare i nodi del cluster e il relativo caricamento, accedere all'interfaccia utente Web di Ambari e quindi selezionare la scheda Host . Gli host sono elencati in base ai nomi di dominio completi. Lo stato operativo di ogni host viene visualizzato tramite un indicatore di integrità colorato:
| Color | Descrizione |
|---|---|
| Rosso | Almeno un componente master dell'host è inattivo. Passare il mouse sull'indicatore per visualizzare una descrizione comando in cui sono elencati i componenti interessati. |
| Orange | Almeno un componente secondario nell'host è inattivo. Passare il mouse sull'indicatore per visualizzare una descrizione comando in cui sono elencati i componenti interessati. |
| Giallo | Il server Ambari non ha ricevuto un heartbeat dall'host per più di 3 minuti. |
| Verde | Stato di esecuzione normale. |
Verrà visualizzata anche una serie di colonne in cui sono riportati il numero di core e la quantità di RAM per ogni host, nonché l'utilizzo del disco e il carico medio.
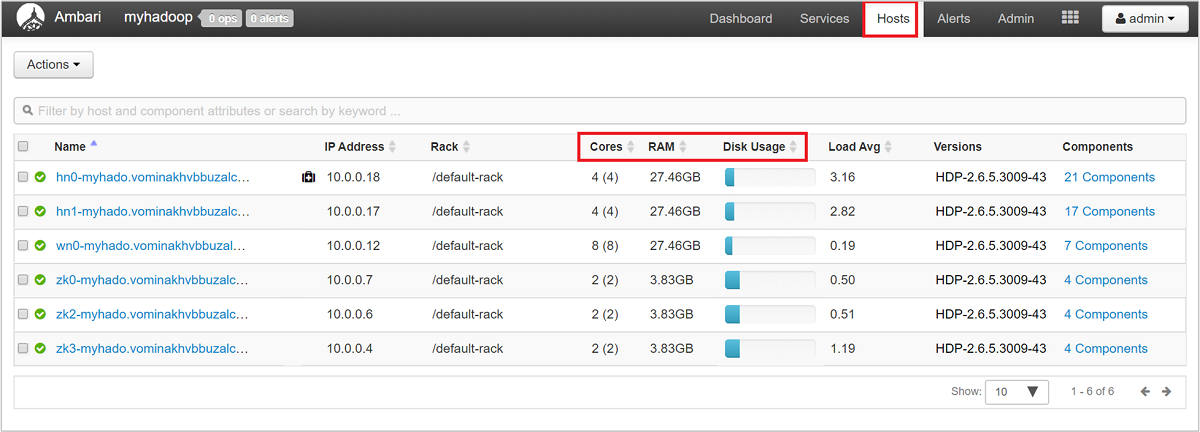
Selezionare uno dei nomi host per visualizzare informazioni dettagliate sui componenti in esecuzione sull'host e le relative metriche. Le metriche vengono visualizzate come sequenze temporali selezionabili e riguardano l'utilizzo della CPU, il carico, l'utilizzo del disco, l'utilizzo della memoria, l'utilizzo della rete e il numero di processi.
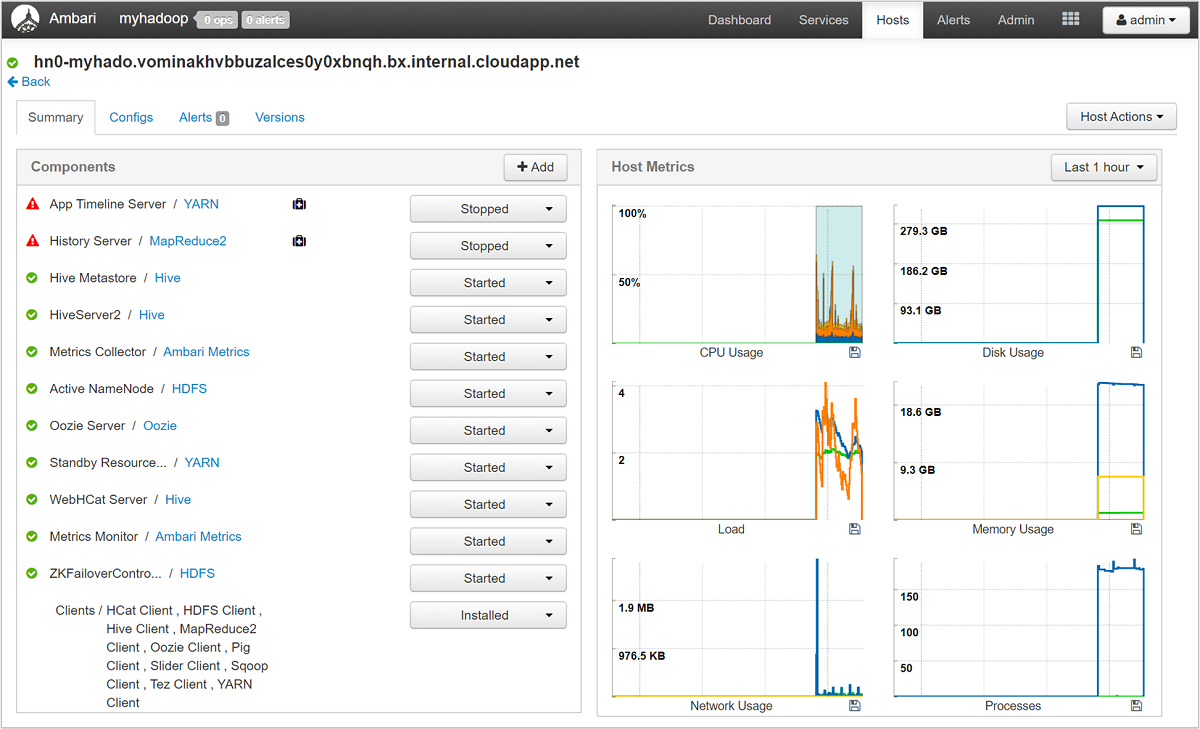
Per informazioni dettagliate sull'impostazione degli avvisi e la visualizzazione delle metriche, vedere Gestire i cluster HDInsight tramite l'utilizzo dell'interfaccia utente Web Apache Ambari.
Configurazione della coda YARN
Hadoop include vari servizi in esecuzione sulla relativa piattaforma distribuita. YARN (Yet Another Resource Negotiator) coordina tali servizi e alloca le risorse cluster per garantire la distribuzione uniforme dei carichi nel cluster.
YARN divide inoltre le due responsabilità del JobTracker (gestione delle risorse e pianificazione/monitoraggio dei processi) in due daemon: un ResourceManager globale e un ApplicationMaster per ogni applicazione.
ResourceManager è un'utilità di pianificazione ed esegue esclusivamente l'arbitraggio delle risorse disponibili tra le applicazioni concorrenti. Garantisce inoltre che tutte le risorse siano sempre in uso, ottimizzandole per varie costanti come i contratti di servizio, le garanzie di capacità e così via. ApplicationMaster negozia invece le risorse da ResourceManager e interagisce con NodeManager per eseguire e monitorare i contenitori e il relativo consumo di risorse.
Quando più tenant condividono un cluster di grandi dimensioni, c'è concorrenza per le risorse del cluster. CapacityScheduler è un'utilità di pianificazione collegabile che semplifica la condivisione delle risorse disponendo le richieste in coda. CapacityScheduler supporta anche code gerarchiche per garantire che le risorse vengano condivise tra le sottoquery di un'organizzazione, prima che le code di altre applicazioni siano autorizzate a usare risorse gratuite.
YARN consente di allocare le risorse a queste code e indica se tutte le risorse disponibili sono assegnate. Per visualizzare informazioni sulle code, accedere all'interfaccia utente Web Ambari e quindi selezionare YARN Queue Manager (Gestore code YARN) dal menu principale.
Sul lato sinistro della pagina YARN Queue Manager (Gestore code YARN) viene visualizzato un elenco di code, con la relativa percentuale di capacità assegnata.
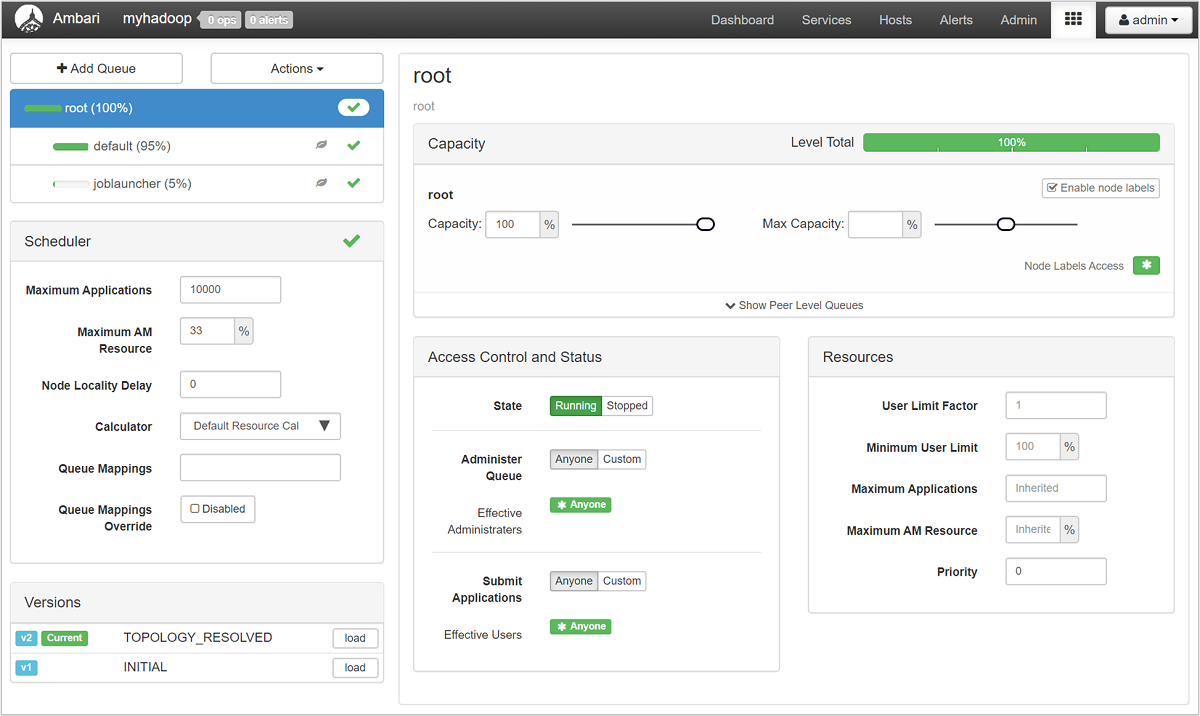
Per un'analisi più approfondita delle code, nell'elenco a sinistra del dashboard Ambari selezionare il servizio YARN. Nel menu a discesa Quick Links (Collegamenti rapidi) selezionare ResourceManager UI (Interfaccia utente di ResourceManager) sotto il nodo attivo.
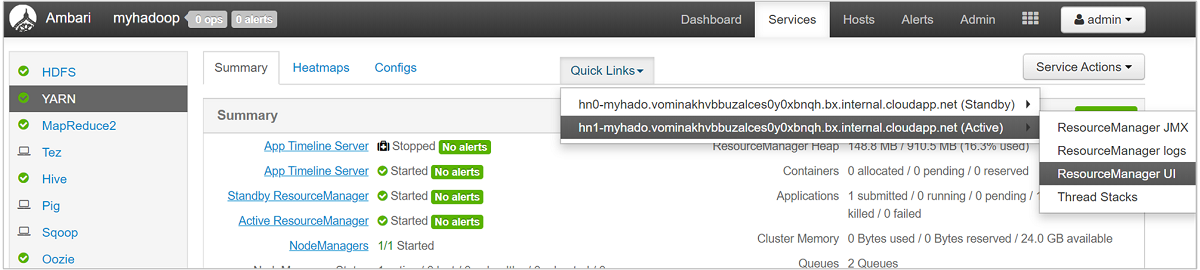
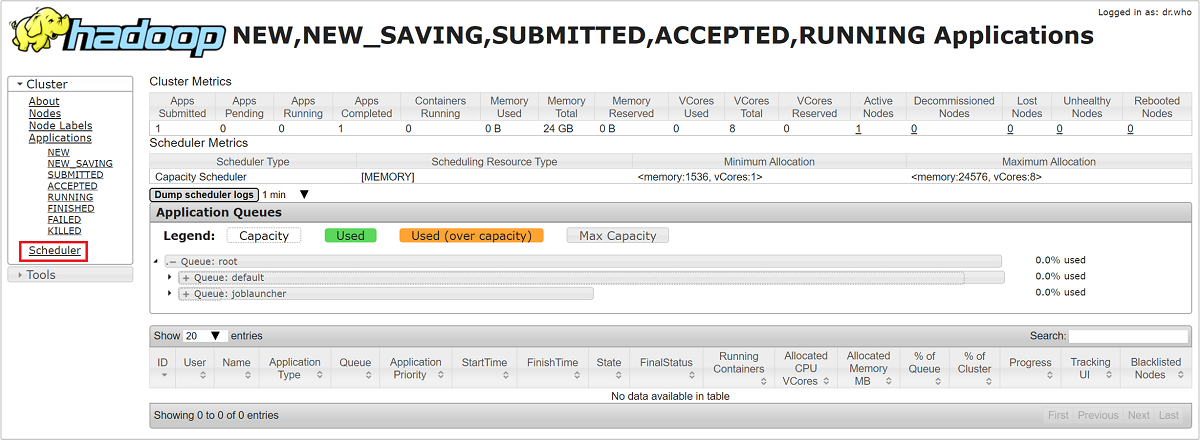
Nell'interfaccia utente di ResourceManager selezionare Scheduler (Utilità di pianificazione) dal menu a sinistra. Viene visualizzato un elenco delle code disponibili in Application Queues (Code dell'applicazione). In quest'area è possibile visualizzare la capacità usata per ognuna delle code, come vengono distribuiti i processi tra di esse e se i processi hanno risorse limitate.
Limitazione del servizio di archiviazione
È possibile che si verifichi un collo di bottiglia delle prestazioni del cluster a livello di archiviazione. Questo tipo di collo di bottiglia è spesso dovuto al blocco delle operazioni di input/output (I/O), che si verificano quando le attività in esecuzione inviano più operazioni di I/O rispetto al servizio di archiviazione. Questo blocco crea una coda di richieste di I/O in attesa di essere elaborate al termine dell'elaborazione delle richieste di I/O correnti. I blocchi sono causati dalla limitazione dell'archiviazione, che non è un limite fisico, ma piuttosto un limite imposto dal servizio di archiviazione da un contratto di servizio (SLA). Questo limite impedisce infatti che il servizio venga monopolizzato da un singolo client o tenant. Il contratto di servizio limita il numero di operazioni di I/O al secondo (IOPS) per Archiviazione di Azure. Per informazioni dettagliate, vedere Obiettivi di scalabilità e prestazioni per gli account di archiviazione standard.
Se si usa Archiviazione di Azure, per informazioni sul monitoraggio dei problemi correlati all'archiviazione, inclusa la limitazione, vedere Monitorare, diagnosticare e risolvere i problemi Archiviazione di Microsoft Azure.
Se l'archivio di backup del cluster è Azure Data Lake Archiviazione (ADLS), la limitazione è molto probabile a causa dei limiti di larghezza di banda. La limitazione, in questo caso, può essere identificata verificando la presenza di errori di limitazione nei log delle attività. Per Azure Data Lake Store, vedere la sezione sulla limitazione relativa al servizio desiderato in questi articoli:
- Linee guida per l'ottimizzazione delle prestazioni di Apache Hive in HDInsight e di Azure Data Lake Storage
- Linee guida per l'ottimizzazione delle prestazioni di MapReduce in HDInsight e di Azure Data Lake Storage
Risolvere i problemi relativi alle prestazioni dei nodi lente
In alcuni casi la lentezza può verificarsi a causa di spazio su disco insufficiente sul cluster. Esaminare i passaggi seguenti:
Usare il comando ssh per connettersi a ognuno dei nodi.
Controllare l'utilizzo del disco eseguendo uno dei comandi seguenti:
df -h du -h --max-depth=1 / | sort -hEsaminare l'output e verificare la presenza di file di grandi dimensioni nella
mntcartella o in altre cartelle.usercacheLe cartelle , eappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) contengono file di grandi dimensioni.Se sono presenti file di grandi dimensioni, un processo corrente causa l'aumento del file o un processo precedente non riuscito potrebbe aver contribuito a questo problema. Per verificare se questo comportamento è causato da un processo corrente, eseguire il comando seguente:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Se questo comando indica un processo specifico, è possibile scegliere di terminare il processo usando un comando simile al seguente:
yarn application -kill -applicationId <application_id>Sostituire
application_idcon l'ID applicazione. Se non sono indicati processi specifici, andare al passaggio successivo.Al termine del comando precedente o se non sono indicati processi specifici, eliminare i file di grandi dimensioni identificati eseguendo un comando simile al seguente:
rm -rf filecache usercache
Per altre informazioni sui problemi di spazio su disco, vedere Spazio su disco insufficiente.
Nota
Se si hanno file di grandi dimensioni che si desidera mantenere ma contribuiscono al problema di spazio su disco insufficiente, è necessario aumentare le prestazioni del cluster HDInsight e riavviare i servizi. Dopo aver completato questa procedura e attendere alcuni minuti, si noterà che lo spazio di archiviazione viene liberato e che le normali prestazioni del nodo vengono ripristinate.
Passaggi successivi
Per altre informazioni sulla risoluzione dei problemi e il monitoraggio dei cluster, visitare i collegamenti seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per