Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le soluzioni Big Data in tempo reale agiscono sui dati in movimento. In genere, questi dati hanno il maggior valore al momento dell'arrivo. Se il flusso di dati in ingresso diventa più grande delle dimensioni gestibili in quel momento, potrebbe risultare necessario limitare le risorse. In alternativa, un cluster HDInsight può aumentare le prestazioni per soddisfare la soluzione di streaming aggiungendo nodi su richiesta.
In un'applicazione di streaming, una o più origini dati generano eventi (talvolta in milioni al secondo) che devono essere inseriti rapidamente senza eliminare informazioni utili. Gli eventi in entrata vengono gestiti tramite la memorizzazione nel buffer del flusso, tecnica nota anche come accodamento degli eventi, eseguita da un servizio come Apache Kafka o Hub eventi. Dopo aver raccolto gli eventi, è possibile analizzare i dati usando un sistema di analisi in tempo reale all'interno del livello di elaborazione del flusso . I dati elaborati possono essere archiviati in sistemi di archiviazione a lungo termine, come Azure Data Lake Storage e visualizzati in tempo reale in un dashboard di business intelligence, come Power BI, Tableau o una pagina Web personalizzata.
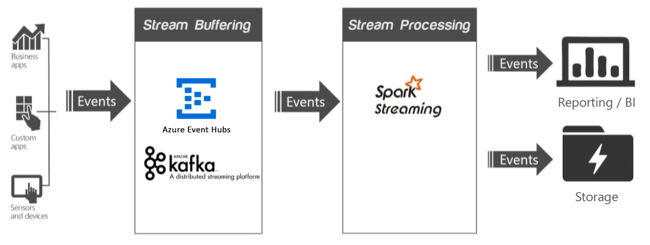
Apache Kafka
Apache Kafka offre un servizio di accodamento dei messaggi con velocità effettiva elevata e bassa latenza e fa ora parte della famiglia di prodotti software open source di Apache. Kafka usa un modello di messaggistica basato su pubblicazione e sottoscrizione e archivia i flussi di dati partizionati in modo sicuro in un cluster distribuito con replica. Kafka viene ridimensionato in modo lineare man mano che aumenta la velocità effettiva.
Per altre informazioni, vedere Introduzione ad Apache Kafka in HDInsight.
Spark Streaming
Spark Streaming è un'estensione di Spark, che consente di riutilizzare lo stesso codice usato per l'elaborazione batch. È possibile combinare query batch e interattive nella stessa applicazione. A differenza di Spark, Streaming fornisce una semantica di elaborazione con stato esattamente una volta. Se usato in combinazione con l'API Kafka Direct, che garantisce che tutti i dati Kafka ricevuti in Spark Streaming una sola volta, sia possibile ottenere esattamente una volta le garanzie end-to-end. Uno dei punti di forza di Spark Streaming è il supporto della tolleranza di errore, con ripristino rapido dei nodi con errori quando si usano più nodi all'interno del cluster.
Per altre informazioni, vedere Informazioni su Apache Spark Streaming.
Scalabilità di un cluster
Anche se è possibile specificare il numero di nodi del cluster durante la fase di creazione, in seguito può essere necessario aumentare o ridurre il cluster sulla base del carico di lavoro. Tutti i cluster HDInsight consentono di modificare il numero di nodi del cluster. I cluster Spark possono essere eliminati senza perdita di dati, perché tutti i dati vengono archiviati in Archiviazione di Azure o Data Lake Storage.
Esistono dei vantaggi rispetto alle tecnologie di separazione. Ad esempio, Kafka è una tecnologia di buffering di eventi, quindi è molto intensivo di I/O e non richiede molta potenza di elaborazione. In confronto, gli elaboratori di flussi come Spark Streaming, richiedono grandi quantità di risorse di calcolo e quindi macchine virtuali più potenti. Separando queste tecnologie in cluster diversi è possibile gestirne la scalabilità in modo indipendente e usare al tempo stesso in modo ottimale le macchine virtuali.
Scalabilità del livello di memorizzazione nel buffer dei flussi
Le tecnologie per la memorizzazione nel buffer dei flussi Hub eventi e Kafka usano entrambe le partizioni e i consumer leggono da tali partizioni. Per la scalabilità della velocità effettiva di input è necessario aumentare il numero di partizioni e l'aggiunta di partizioni comporta una parallelismo crescente. In Hub eventi il numero di partizioni non può essere modificato dopo la distribuzione, quindi è importante iniziare tenendo conto della scalabilità di destinazione. Con Kafka è possibile aggiungere partizioni, anche mentre Kafka elabora i dati. Kafka fornisce uno strumento per riassegnare le partizioni, kafka-reassign-partitions.sh. HDInsight offre uno strumento di ribilanciamento della replica di partizione, rebalance_rackaware.py. Questo strumento di ribilanciamento chiama lo strumento kafka-reassign-partitions.sh in modo che ogni replica si trovi in un dominio di errore e un dominio di aggiornamento separati, rendendo Kafka in grado di riconoscere il rack e migliorando la tolleranza di errore.
Scalabilità del livello di elaborazione dei flussi
Apache Spark Streaming supporta l'aggiunta di nodi di lavoro ai cluster, anche durante l'elaborazione dei dati.
Apache Spark usa tre parametri chiave per la configurazione dell'ambiente, a seconda dei requisiti dell'applicazione: spark.executor.instances, spark.executor.cores e spark.executor.memory. Un executor è un processo avviato per un'applicazione Spark. Un executor viene eseguito nel nodo di lavoro ed è responsabile dell'esecuzione delle attività dell'applicazione. Il numero predefinito di executor e le relative dimensioni per ogni cluster vengono calcolati in base al numero di nodi di lavoro e alle relative dimensioni. Questi numeri sono archiviati nel file spark-defaults.conf in ogni nodo head del cluster.
Questi tre parametri possono essere configurati a livello di cluster, per tutte le applicazioni eseguite nel cluster e possono essere specificati anche per ogni singola applicazione. Per altre informazioni, vedere Gestire le risorse del cluster Apache Spark in Azure HDInsight.