Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come usare Apache Oozie con Apache Hadoop in Azure HDInsight. Oozie è un sistema di coordinamento dei flussi di lavoro che consente di gestire i processi Hadoop. Oozie è integrato con lo stack Hadoop e supporta i processi seguenti:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Oozie può anche essere usato per pianificare processi specifici di un sistema, come programmi Java o script della shell.
Nota
Per definire i flussi di lavoro con HDInsight, è anche possibile usare Azure Data Factory. Per altre informazioni su Azure Data Factory, vedere Trasformare i dati in Azure Data Factory. Per usare Oozie nei cluster con Enterprise Security Package, vedere Eseguire Apache Oozie nei cluster HDInsight Hadoop con Enterprise Security Package.
Prerequisiti
Un cluster Hadoop in HDInsight. Vedere Guida introduttiva: Introduzione ad Apache Hadoop e Apache Hive in Azure HDInsight usando il modello di Resource Manager.
Un client SSH. Connettersi a HDInsight (Apache Hadoop) con SSH.
Un database SQL di Azure. Vedere Creare un database in database SQL di Azure nel portale di Azure. Questo articolo usa un database denominato oozietest.
Lo schema URI per l'archiviazione primaria dei cluster.
wasb://per Archiviazione di Azure,abfs://per Azure Data Lake Storage Gen2 oadl://per Azure Data Lake Storage Gen1. Se il trasferimento sicuro è abilitato per Archiviazione di Azure, l'URI saràwasbs://. Vedere anche l'articolo sul trasferimento sicuro.
Esempio di flusso di lavoro
Il flusso di lavoro usato in questo documento prevede due azioni. Le azioni sono definizioni di attività, ad esempio l'esecuzione di processi Hive, Sqoop, MapReduce o altri:
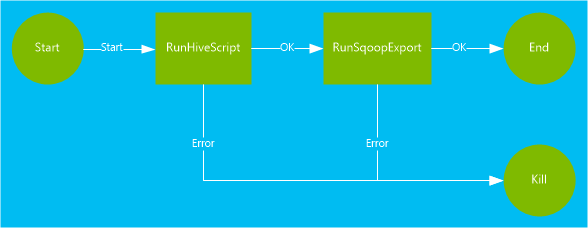
Un'azione Hive esegue uno script HiveQL per estrarre i record dall'oggetto
hivesampletableincluso in HDInsight. Ogni riga di dati descrive una visita da un dispositivo mobile specifico. Il formato del record risulterà simile al testo seguente:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1Lo script Hive usato in questo documento conta le visite totali per ogni piattaforma (ad esempio Android o iPhone) e archivia i conteggi in una nuova tabella Hive.
Per altre informazioni su Hive, vedere [Usare Apache Hive con HDInsight][hdinsight-use-hive].
Un'azione di Sqoop esporta il contenuto della nuova tabella Hive in una tabella creata nel database SQL di Azure. Per altre informazioni su Sqoop, vedere Usare Apache Sqoop con HDInsight.
Nota
Per informazioni sulle versioni di Oozie supportate nei cluster HDInsight, vedere Novità delle versioni cluster di Hadoop incluse in HDInsight.
Creare la directory di lavoro
Oozie presuppone che tutte le risorse necessarie per un processo siano archiviate nella stessa directory. In questo esempio viene utilizzato wasbs:///tutorials/useoozie. Per creare questa directory, completare la procedura seguente:
Modificare il codice seguente per sostituire
sshusercon il nome utente SSH per il cluster e sostituireCLUSTERNAMEcon il nome del cluster. Immettere quindi il codice per connettersi al cluster HDInsight usando SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPer creare la directory, usare il comando seguente:
hdfs dfs -mkdir -p /tutorials/useoozie/dataNota
Il parametro
-pcrea tutte le directory nel percorso. Ladatadirectory viene utilizzata per contenere i dati usati dallouseooziewf.hqlscript.Modificare il codice seguente per sostituire
sshusercon il nome utente SSH. Per assicurarsi che Oozie possa rappresentare l'account utente, usare il comando seguente:sudo adduser sshuser usersNota
È possibile ignorare gli errori che indicano che l'utente è già un membro del gruppo
users.
Aggiungere un driver di database
Questo flusso di lavoro usa Sqoop per esportare i dati nel database SQL. È quindi necessario fornire una copia del driver JDBC usato per interagire con il database SQL. Per copiare il driver JDBC nella directory di lavoro, usare il comando seguente della sessione SSH:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Importante
Verificare il driver JDBC effettivo presente in /usr/share/java/.
Se il flusso di lavoro ha usato altre risorse, ad esempio un file con estensione jar contenente un'applicazione MapReduce, è necessario aggiungere anche queste risorse.
Definire la query Hive
Usare la procedura seguente per creare uno script HiveQL (linguaggio di query Hive) che definisce una query La query verrà usata in un flusso di lavoro Oozie più avanti in questo documento.
Dalla connessione SSH, usare il comando seguente per creare un file denominato
useooziewf.hql:nano useooziewf.hqlAll'apertura dell'editor nano GNU, usare la query seguente come contenuto del file:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Nello script vengono usate due variabili:
${hiveTableName}: contiene il nome della tabella da creare.${hiveDataFolder}: contiene il percorso in cui archiviare i file di dati per la tabella.Il file di definizione del flusso di lavoro, workflow.xml in questo articolo, passa questi valori a questo script HiveQL in fase di esecuzione.
Per salvare il file, selezionare CTRL+X, immettere Y e quindi premere INVIO.
Usare il comando seguente per copiare
useooziewf.hqlinwasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlQuesto comando archivia il file
useooziewf.hqlnella risorsa di archiviazione compatibile con HDFS per il cluster.
Definire il flusso di lavoro
Le definizioni del flusso di lavoro di Oozie sono scritte in un linguaggio di definizione dei processi XML denominato hPDL (Hadoop Process Definition Language). Usare i passaggi seguenti per definire il flusso di lavoro:
Usare l'istruzione seguente per creare e modificare un nuovo file:
nano workflow.xmlAll'apertura dell'editor nano, immettere il codice XML seguente come contenuto del file:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Nel flusso di lavoro vengono definite due azioni:
RunHiveScript: azione di avvio che esegue lo scriptuseooziewf.hqldi Hive.RunSqoopExport: questa azione esporta i dati creati dallo script Hive in un database SQL usando Sqoop. Questa azione viene eseguita solo se l'azioneRunHiveScriptha esito positivo.Il flusso di lavoro include molte voci, ad esempio
${jobTracker}. Queste voci verranno sostituite con i valori usati nella definizione del processo. La definizione del processo verrà creata più avanti in questo documento.Notare anche la voce
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>nella sezione Sqoop. Questa voce indica a Oozie di rendere disponibile questo archivio per Sqoop quando l'azione viene eseguita.
Per salvare il file, selezionare CTRL+X, immettere Y e quindi premere INVIO.
Usare il comando seguente per copiare il file
workflow.xmlin/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Crea una tabella
Nota
Sono disponibili diversi modi per connettersi al database SQL per creare una tabella. Nei seguenti passaggi viene usato FreeTDS dal cluster HDInsight.
Usare il comando seguente per installare FreeTDS nel cluster HDInsight:
sudo apt-get --assume-yes install freetds-dev freetds-binModificare il codice seguente per sostituire
<serverName>con il nome logico del server SQL e<sqlLogin>con l'account di accesso del server. Immettere il comando per connettersi al database SQL prerequisito. Immettere la password al prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestL'output ricevuto ha un aspetto simile al testo seguente:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Al prompt
1>, immettere il codice seguente:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GODopo aver immesso l'istruzione
GO, vengono valutate le istruzioni precedenti. Queste istruzioni creano una tabella denominatamobiledata, usata dal flusso di lavoro.Per verificare che la tabella sia stata creata, usare i comandi seguenti:
SELECT * FROM information_schema.tables GOViene visualizzato un output simile al testo seguente:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEUscire dall'utilità tsql immettendo
exital1>prompt.
Creare la definizione del processo
La definizione del processo descrive dove trovare il file workflow.xml. Descrive inoltre dove trovare altri file usati dal flusso di lavoro, ad esempio useooziewf.hql. Definisce anche i valori per le proprietà usate all'interno del flusso di lavoro e i file associati.
Per ottenere l'indirizzo completo della risorsa di archiviazione predefinita, usare il comando seguente. L'indirizzo viene usato nel file di configurazione che verrà creato nel passaggio successivo.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlQuesto comando restituisce informazioni simili al codice XML seguente:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Nota
Se il cluster HDInsight usa l'archiviazione di Azure come percorso di archiviazione predefinito, il contenuto dell'elemento
<value>inizia conwasbs://. Se invece si usa Azure Data Lake Storage Gen1, l'elemento inizia conadl://. Se si usa Azure Data Lake Storage Gen2, l'elemento inizia conabfs://.Salvare il contenuto dell'elemento
<value>, necessario nei passaggi successivi.Modificare il codice XML seguente come indicato di seguito:
Valore segnaposto Valore sostituito wasbs://mycontainer@mystorageaccount.blob.core.windows.net Valore ricevuto dal passaggio 1. amministratore Nome dell'account di accesso per il cluster HDInsight, se non amministratore. serverName database SQL di Azure nome del server. sqlLogin database SQL di Azure account di accesso al server. sqlPassword database SQL di Azure password di accesso al server. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>La maggior parte delle informazioni in questo file viene usata per popolare i valori usati nel file workflow.xml o ooziewf.hql (ad esempio
${nameNode}). Se il percorso è un percorsowasbs, è necessario usare il percorso completo, Non abbreviarla solowasbs:///con . La voceoozie.wf.application.pathdefinisce il percorso in cui trovare il file workflow.xml, che contiene il flusso di lavoro eseguito da questo processo.Per creare la configurazione della definizione del processo Oozie, usare il comando seguente:
nano job.xmlDopo l'apertura dell'editor nano, incollare il codice XML modificato come contenuto del file.
Per salvare il file, selezionare CTRL+X, immettere Y e quindi premere INVIO.
Inviare e gestire il processo
La procedura seguente usa il comando Oozie per inviare e gestire i flussi di lavoro di Oozie nel cluster. Il comando Oozie è un'interfaccia utente semplice per l' API REST di Oozie.
Importante
Quando si usa il comando Oozie, è necessario usare l'FQDN per il nodo head di HDInsight. Questo FQDN è accessibile solo dal cluster o, se il cluster si trova in una rete virtuale di Azure, da altri computer nella stessa rete.
Per ottenere l'URL del servizio di Oozie, usare questo comando:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlVengono restituite informazioni simili al codice XML seguente:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>La parte
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieè l'URL da usare con il comando Oozie.Modificare il codice per sostituire l'URL con quello ricevuto in precedenza. Per creare una variabile di ambiente per l'URL, usare il codice seguente, in modo che non sia necessario eseguirne la digitazione per ogni comando:
export OOZIE_URL=http://HOSTNAMEt:11000/ooziePer inviare il processo, usare il codice seguente:
oozie job -config job.xml -submitQuesto comando carica le informazioni sul processo da
job.xmle lo invia a Oozie, ma non lo esegue.Dopo il completamento, il comando dovrebbe restituire l'ID del processo, ad esempio
0000005-150622124850154-oozie-oozi-W. L'ID viene usato per gestire il processo.Modificare il codice seguente per sostituire
<JOBID>con l'ID restituito nel passaggio precedente. Per visualizzare lo stato del processo, usare il comando seguente:oozie job -info <JOBID>Verranno restituite informazioni simili al testo seguente:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Lo stato del processo è
PREP. Questo stato indica che il processo è stato creato, ma non avviato.Modificare il codice seguente per sostituire
<JOBID>con l'ID restituito in precedenza. Per avviare il processo, usare il comando seguente:oozie job -start <JOBID>Dopo questo comando, lo stato risulterà in esecuzione e verranno restituite informazioni relative alle azioni all'interno del processo. Il completamento del processo richiederà alcuni minuti.
Modificare il codice seguente per sostituire
<serverName>con il nome del server e<sqlLogin>con l'account di accesso del server. Al termine dell'attività, è possibile verificare che i dati siano stati generati ed esportati nella tabella del database SQL usando il comando seguente. Immettere la password al prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestAl prompt di
1>immettere la query seguente:SELECT * FROM mobiledata GOLe informazioni restituite sono simili al testo seguente:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Per altre informazioni sul comando Oozie, vedere Oozie command-line tool (Strumento da riga di comando di Apache Oozie).
API REST di Oozie
Con l'API REST di Oozie, è possibile compilare strumenti personalizzati che funzionano con Oozie. Le informazioni specifiche di HDInsight seguenti sull'uso dell'API REST di Oozie:
URI: è possibile accedere all'API REST all'esterno del cluster in
https://CLUSTERNAME.azurehdinsight.net/oozie.Autenticazione: per eseguire l'autenticazione, usare l'API, l'account (admin) e la password HTTP del cluster, Ad esempio:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Per altre informazioni sull'uso dell'API REST di Oozie, vedere la pagina relativa all'API dei servizi Web di Apache Oozie.
Interfaccia utente Web di Oozie
L'interfaccia utente Web di Oozie fornisce una visualizzazione basata sul Web dello stato dei processi Oozie nel cluster. L'interfaccia utente Web consente di visualizzare le informazioni seguenti:
- Stato processo
- Definizione del processo
- Impostazione
- Grafico delle azioni nel processo
- Log per il processo
È anche possibile visualizzare i dettagli delle azioni all'interno di un processo.
Per accedere all'interfaccia utente Web di Oozie, completare la procedura seguente:
Creare un tunnel SSH per il cluster HDInsight. Per altre informazioni, vedere Usare il tunneling SSH con HDInsight.
Dopo aver creato un tunnel, aprire l'interfaccia utente Web di Ambari nel Web browser usando l'URI
http://headnodehost:8080.Nel lato sinistro della pagina selezionare Oozie>Quick Links (Collegamenti rapidi)>Oozie Web UI (Interfaccia utente Web di Oozie).
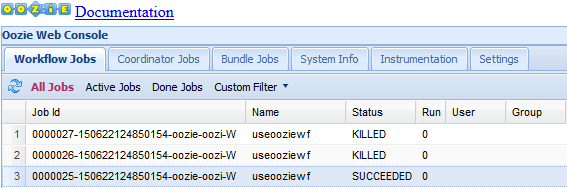
Per impostazione predefinita, nell'interfaccia utente Web di Oozie sono visualizzati i processi del flusso di lavoro in esecuzione. Per visualizzare tutti i processi del flusso di lavoro, selezionare All Jobs (Tutti i processi).
Per visualizzare altre informazioni specifiche di un processo, selezionarlo.
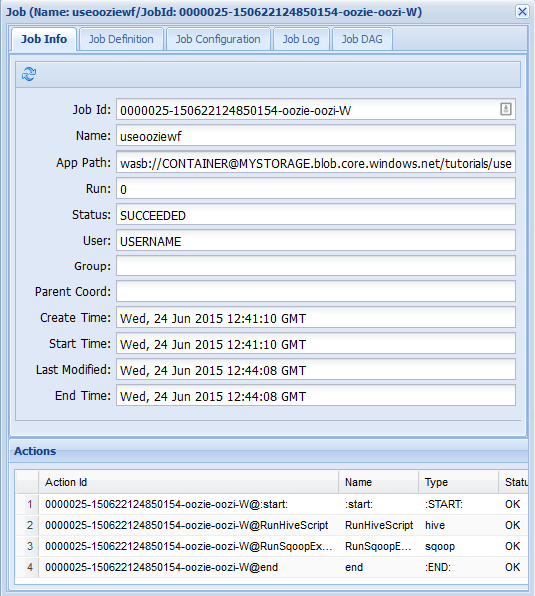
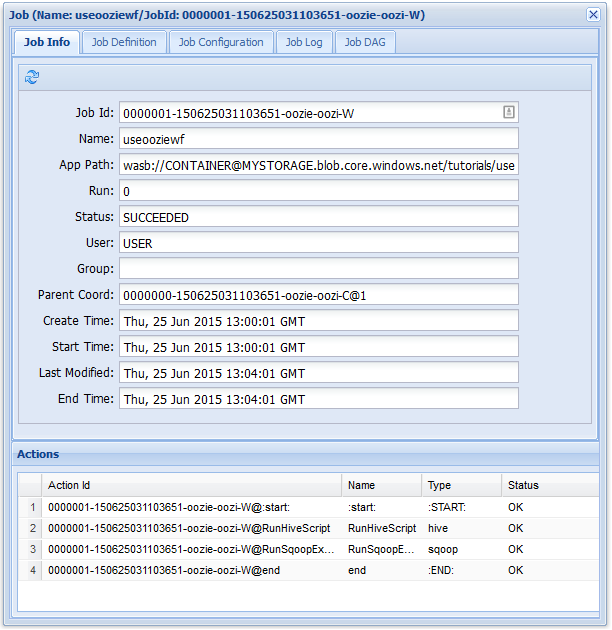
Nella scheda Job Info (Informazioni processo) è possibile visualizzare informazioni di base sul processo e le singole azioni all'interno del processo. È possibile usare le schede nella parte superiore per visualizzare Job Definition (Definizione processo) e Job Configuration (Configurazione processo), accedere a Job Log (Log processo) o visualizzare un grafo aciclico diretto (DAG) del processo in Job DAG (DAG processo).
Log processo: selezionare il pulsante Recupera log per ottenere tutti i log per il processo oppure usare il
Enter Search Filtercampo per filtrare i log.
Job DAG (DAG processo): il grafo aciclico diretto (DAG) è una rappresentazione grafica dei percorsi dati rilevati nel flusso di lavoro.
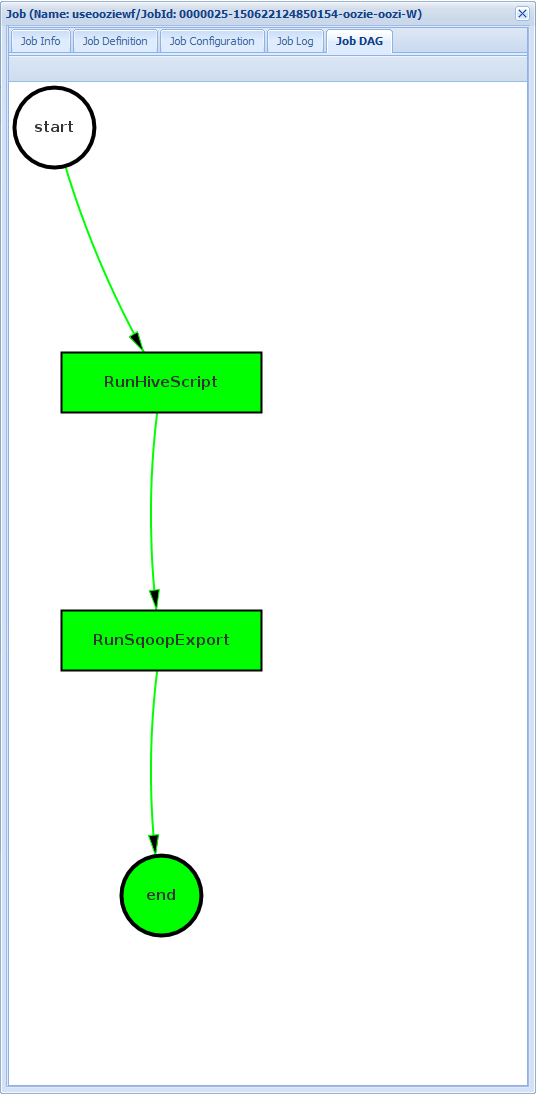
Se si seleziona una delle azioni dalla scheda Job Info (Informazioni processo), vengono visualizzate informazioni sull'azione. Selezionare ad esempio l'azione RunSqoopExport.
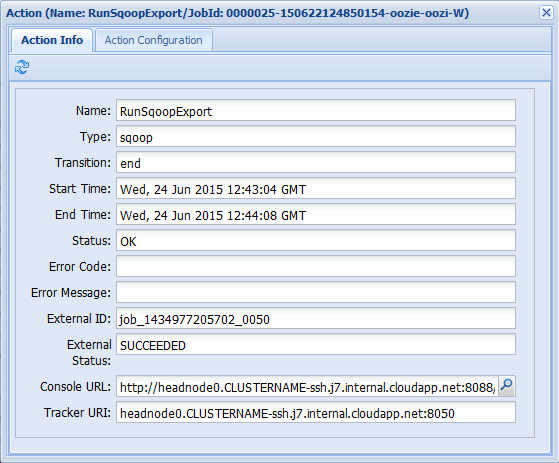
È possibile visualizzare i dettagli per l'azione, ad esempio un collegamento a Console URL (URL della console). Usare questo collegamento per visualizzare le informazioni di JobTracker per il processo.
Pianificare i processi
È possibile usare il coordinatore per specificare inizio, fine e frequenza dei processi. Per definire una pianificazione per il flusso di lavoro, completare la procedura seguente:
Usare il comando seguente per creare un file denominato coordinator.xml:
nano coordinator.xmlUsare il codice XML seguente come contenuto del file:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Nota
Le variabili
${...}vengono sostituite dai valori nella definizione del processo in fase di esecuzione. Le variabili sono:${coordFrequency}: tempo trascorso tra l'esecuzione delle istanze del processo.${coordStart}: ora di inizio del processo.${coordEnd}: ora di fine del processo.${coordTimezone}: i processi del coordinatore si trovano in un fuso orario fisso che non tiene conto dell'ora legale (in genere rappresentato dall'acronimo UTC). Questo fuso orario viene definito Fuso orario di elaborazione Oozie.${wfPath}: percorso del file workflow.xml.
Per salvare il file, selezionare CTRL+X, immettere Y e quindi premere INVIO.
Per copiare il file nella directory di lavoro del processo, usare il comando seguente:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlPer modificare il
job.xmlfile creato in precedenza, usare il comando seguente:nano job.xmlApportare le modifiche seguenti:
Per indicare a Oozie di eseguire il file del coordinatore invece del flusso di lavoro, sostituire
<name>oozie.wf.application.path</name>con<name>oozie.coord.application.path</name>.Per impostare la variabile
workflowPathusata dal coordinatore, aggiornare il codice XML seguente:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Sostituire il testo
wasbs://mycontainer@mystorageaccount.blob.core.windowscon il valore usato nelle altre voci del file job.xlm.Per definire l'inizio, la fine e la frequenza per il coordinatore, aggiungere il codice XML seguente:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Questi valori impostano l'ora di inizio su 12:00 il 10 maggio 2018 e l'ora di fine al 12 maggio 2018. L'intervallo per l'esecuzione del processo viene impostato come giornaliero. La frequenza è espressa in minuti, quindi 24 ore x 60 minuti = 1440 minuti. Il fuso orario è infine impostato su UTC.
Per salvare il file, selezionare CTRL+X, immettere Y e quindi premere INVIO.
Per inviare e avviare il processo, usare il comando seguente:
oozie job -config job.xml -runSe si accede all'interfaccia utente Web di Oozie e si seleziona la scheda Coordinator Jobs (Processi coordinatore), si ottengono informazioni simili a quelle nell'immagine seguente:

La voce Next Materialization (Materializzazione successiva) contiene l'orario per l'esecuzione successiva del processo.
Come per il processo del flusso di lavoro precedente, se si seleziona la voce del processo nell'interfaccia utente Web vengono visualizzate informazioni sul processo:
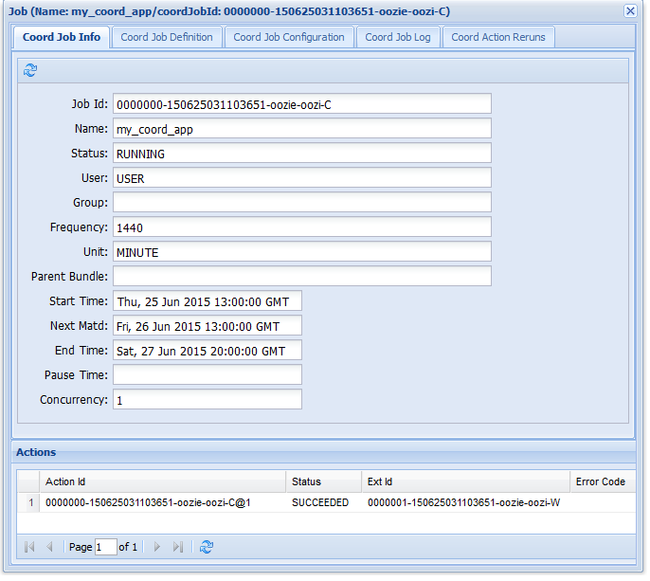
Nota
Questa immagine visualizza solo le esecuzioni riuscite del processo, non le singole azioni nel flusso di lavoro pianificato. Per visualizzare le singole azioni, selezionare una delle voci relative alle azioni.
Passaggi successivi
In questo articolo si è appreso come definire un flusso di lavoro Oozie e come eseguire un processo Oozie. Per altre informazioni sull'uso di HDInsight, vedere gli articoli seguenti: