Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo notebook dimostra come analizzare i dati dei log mediante una libreria personalizzata con Apache Spark in HDInsight. La libreria personalizzata usata è una libreria di Python chiamata iislogparser.py.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
Salvare i dati non elaborati come RDD
In questa sezione viene usato Jupyter Notebook associato a un cluster Apache Spark in HDInsight per eseguire processi che elaborano i dati di esempio non elaborati e salvarli come tabella Hive. I dati di esempio sono un file con estensione csv (hvac.csv) disponibile in tutti i cluster per impostazione predefinita.
Dopo aver salvato i dati come tabella Apache Hive, nella sezione successiva ci si connetterà alla tabella Hive usando strumenti bi come Power BI e Tableau.
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyterdoveCLUSTERNAMEè il nome del cluster.Creare un nuovo notebook. Selezionare Nuovo e quindi PySpark.
 Notebook" border="true":::
Notebook" border="true":::Un nuovo notebook verrà creato e aperto con il nome Untitled.pynb. Selezionare il nome del notebook nella parte superiore e immettere un nome descrittivo.
Poiché è stato creato un notebook usando il kernel PySpark, non è necessario creare contesti in modo esplicito. I contesti Spark e Hive vengono creati automaticamente quando si esegue la prima cella di codice. È possibile iniziare con l'importazione dei tipi necessari per questo scenario. Incollare il frammento di codice seguente in una cella vuota e quindi premere MAIUSC + INVIO.
from pyspark.sql import Row from pyspark.sql.types import *Creare un RDD con i dati di log di esempio già disponibili nel cluster. È possibile accedere ai dati nell'account di archiviazione predefinito associato al cluster all'indirizzo
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Eseguire questo codice:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Recuperare un set di log di esempio per verificare che il passaggio precedente sia stato completato correttamente.
logs.take(5)L'output dovrebbe essere simile al seguente:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analizzare i dati di log usando una libreria personalizzata di Python
Nell'output precedente, le prime due righe includono le informazioni di intestazione e ogni riga rimanente corrisponde allo schema descritto nell'intestazione. L'analisi di tali log potrebbe essere complessa. Quindi, viene usata una libreria personalizzata di Python (iislogparser.py) che semplifica notevolmente l'analisi di tali log. Per impostazione predefinita, questa libreria è inclusa nel cluster Spark in HDInsight all'indirizzo
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Tuttavia, questa libreria non è presente in
PYTHONPATH, quindi non è possibile usarla usando un'istruzione import comeimport iislogparser. Per usare questa libreria è necessario distribuirla a tutti i nodi di lavoro. Eseguire il frammento di codice seguente.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparseroffre una funzioneparse_log_lineche restituisceNonese una riga del log è una riga di intestazione e restituisce un'istanza della classeLogLinese viene rilevata una riga del log. Usare la classeLogLineper estrarre solo le righe del log dall'RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Recuperare un paio di righe estratte del log per verificare che il passaggio sia stato completato correttamente.
logLines.take(2)L'output dovrebbe essere simile al testo seguente:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]La classe
LogLine, a sua volta, offre alcuni metodi utili, ad esempiois_error(), che determina se una voce di log contiene un codice di errore. Usare questa classe per calcolare il numero di errori nelle righe di log estratte e quindi registrare tutti gli errori in un file diverso.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')L'output deve dichiarare
There are 30 errors and 646 log entries.È anche possibile usare Matplotlib per costruire una visualizzazione dei dati. Ad esempio, se si vuole isolare la causa delle richieste in esecuzione da molto tempo si potrebbero trovare i file che mediamente richiedono più tempo per servire una richiesta. Il frammento di codice seguente recupera le 25 risorse principali che hanno impiegato più tempo per servire una richiesta.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Verrà visualizzato un output simile al testo seguente:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]È anche possibile presentare queste informazioni sotto forma di tracciato. Come primo passaggio per creare un tracciato, creeremo prima di tutto una tabella temporanea, AverageTime. La tabella raggruppa i log in base all'ora per vedere se si sono verificati eventuali picchi di latenza insoliti in un determinato momento.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Quindi, per ottenere tutti i record della tabella AverageTime , è possibile eseguire la query SQL seguente.
%%sql -o averagetime SELECT * FROM AverageTimeIl comando speciale
%%sqlseguito da-o averagetimeassicura che l'output della query venga mantenuto in locale nel server Jupyter, di solito il nodo head del cluster. L'output viene mantenuto come frame di dati Pandas con il nome specificato averagetime.Verrà visualizzato un output simile all'immagine seguente:
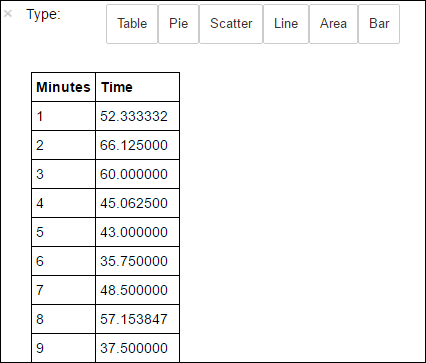 yter sql query output" border="true":::
yter sql query output" border="true":::Per altre informazioni sul comando Magic
%%sql, vedere Parametri supportati con il comando Magic %%sql.È ora possibile creare un tracciato tramite Matplotlib, una libreria che consente di creare visualizzazioni di dati. Dato che il tracciato deve essere creato dal frame di dati averagetime con salvataggio permanente in locale, il frammento di codice deve iniziare con il magic
%%local. Ciò garantisce che il codice venga eseguito localmente nel server di Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Verrà visualizzato un output simile all'immagine seguente:
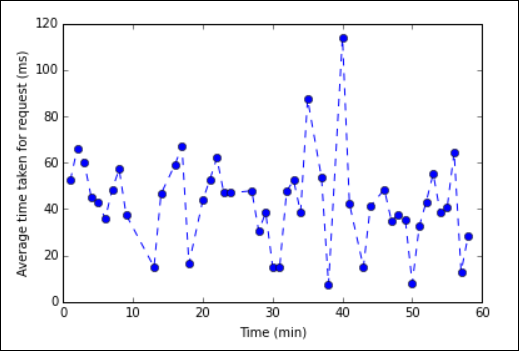 tracciato di analisi dei log eb" border="true":::
tracciato di analisi dei log eb" border="true":::Al termine dell'esecuzione dell'applicazione, è necessario arrestare il notebook per rilasciare le risorse. Per fare ciò, dal menu File del notebook fare clic su Close and Halt (Chiudi e interrompi). Questa azione arresterà e chiuderà il notebook.
Passaggi successivi
Esplorare gli articoli seguenti: