Usare pacchetti esterni con notebook di Jupyter nei cluster Apache Spark in HDInsight
Informazioni su come configurare un oggetto Jupyter Notebook in un cluster Apache Spark in HDInsight per l'uso di pacchetti maven esterni creati dalla community e non inclusi per impostazione predefinita nel cluster.
Per un elenco completo dei pacchetti disponibili, è possibile eseguire ricerche nel repository Maven . È anche possibile ottenere un elenco dei pacchetti disponibili da altre origini. Ad esempio, un elenco completo dei pacchetti creati dalla community è disponibile nel sito Web spark-packages.org.
In questo articolo si apprenderà a usare il pacchetto spark-csv con Jupyter Notebook.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
Familiarità nell'uso di Jupyter Notebook con Spark in HDInsight. Per altre informazioni, vedere l'articolo su come caricare i dati ed eseguire query con Apache Spark in HDInsight.
Lo schema URI per l'archiviazione primaria dei cluster. Sarebbe
wasb://per Archiviazione di Azure,abfs://per Azure Data Lake Storage Gen2. Se il trasferimento sicuro è abilitato per Archiviazione di Azure o Data Lake Storage Gen2, l'URI è rispettivamentewasbs://oabfss://. Vedere anche trasferimento sicuro.
Usare pacchetti esterni con Jupyter Notebook
Passare a
https://CLUSTERNAME.azurehdinsight.net/jupyterdoveCLUSTERNAMEè il nome del cluster di Spark.Creare un nuovo notebook. Selezionare Nuovo seguito da Spark.
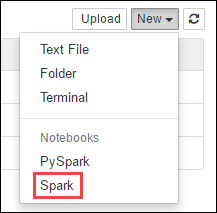
Un nuovo notebook verrà creato e aperto con il nome Untitled.pynb. Selezionare il nome del notebook nella parte superiore e immettere un nome descrittivo.
Si userà
%%configuremagic verrà usato per configurare il notebook per l'uso di un pacchetto esterno. Nei notebook che usano pacchetti esterni assicurarsi di richiamare%%configuremagic nella prima cella del codice. Questo accorgimento garantisce che il kernel sia configurato per l'uso del pacchetto prima dell'avvio della sessione.Importante
Se si dimentica di configurare il kernel nella prima cella, è possibile usare
%%configuremagic con il parametro-f. In questo modo, tuttavia, la sessione verrà riavviata e le operazioni eseguite andranno perse.Versione HDInsight Comando Per HDInsight 3.5 e HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}Per HDInsight 3.3 e HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Il frammento di codice riportato sopra attende le coordinate Maven per il pacchetto esterno nel repository centrale Maven. In questo frammento di codice
com.databricks:spark-csv_2.11:1.5.0è la coordinata Maven per il pacchetto spark-csv . Di seguito viene spiegato come creare le coordinate per un pacchetto.a. Individuare un pacchetto nel repository Maven. Per questo articolo viene usato spark-csv.
b. Recuperare dal repository i valori per GroupId, ArtifactId e Version. Assicurarsi che i valori che si raccolgono corrispondano al cluster. Si usano, in questo caso, un pacchetto Scala 2.11 e un pacchetto Spark 1.5.0, ma potrebbe essere necessario selezionare versioni differenti per la versione di Scala o di Spark appropriata al cluster. È possibile trovare la versione di Scala nel cluster eseguendo
scala.util.Properties.versionStringnel kernel Jupyter Spark o nell'invio di Spark. È possibile trovare la versione di Spark nel cluster eseguendosc.versionnei notebook Jupyter.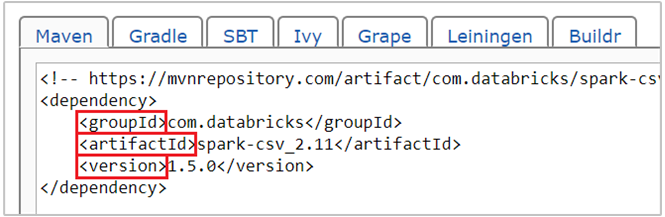
c. Concatenare i tre valori, separati da due punti (:).
com.databricks:spark-csv_2.11:1.5.0Eseguire la cella di codice con
%%configuremagic. Questa operazione configura la sessione Livy sottostante per l'uso del pacchetto fornito. Nelle celle successive del notebook è ora possibile usare il pacchetto, come mostrato di seguito.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Per HDInsight 3.4 e versioni precedenti, usare il frammento di codice seguente.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")È quindi possibile eseguire i frammenti di codice, come mostrato di seguito, per visualizzare i dati del frame di dati creato nel passaggio precedente.
df.show() df.select("Time").count()
Vedi anche
Scenari
- Apache Spark con Business Intelligence: eseguire l'analisi interattiva dei dati con strumenti di Business Intelligence mediante Spark in HDInsight
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per l'analisi della temperatura di compilazione utilizzando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
Creare ed eseguire applicazioni
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
Strumenti ed estensioni
- Usare pacchetti Python esterni con Jupyter Notebook nei cluster Apache Spark in HDInsight Linux
- Usare il plug-in degli strumenti HDInsight per IntelliJ IDEA per creare e inviare applicazioni Spark in Scala
- Usare il plug-in Strumenti HDInsight per IntelliJ IDEA per eseguire il debug di applicazioni Apache Spark in remoto
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark