Usare Azure Toolkit for IntelliJ per creare applicazioni Apache Spark per un cluster HDInsight
Questo articolo illustra come sviluppare applicazioni Apache Spark in Azure HDInsight usando il plug-in Azure Toolkit per l'IDE IntelliJ. Azure HDInsight è un servizio di analisi open source gestito nel cloud. Il servizio consente di usare framework open source come Hadoop, Apache Spark, Apache Hive e Apache Kafka.
È possibile usare il plug-in Azure Toolkit in vari modi:
- Sviluppare e inviare un'applicazione Spark in Scala in un cluster HDInsight Spark.
- Accedere alle risorse cluster HDInsight Spark di Azure.
- Sviluppare ed eseguire un'applicazione Spark in Scala localmente.
In questo articolo vengono illustrate le operazioni seguenti:
- Usare Azure Toolkit for IntelliJ
- Sviluppare applicazioni Apache Spark
- Inviare un'applicazione al cluster Azure HDInsight
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight. Solo i cluster HDInsight nel cloud pubblico sono supportati, mentre altri tipi di cloud sicuri (ad esempio, cloud per enti pubblici) non sono supportati.
Kit di sviluppo di Oracle Java. Questo articolo usa Java versione 8.0.202.
IntelliJ IDEA. Questo articolo usa IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Vedere Installazione di Azure Toolkit for IntelliJ.
Installare il plug-in Scala per IntelliJ IDEA
Procedura per installare il plug-in Scala:
Aprire IntelliJ IDEA.
Nella schermata iniziale, passare a Configure (Configura)>Plugin per aprire la finestra Plugin.
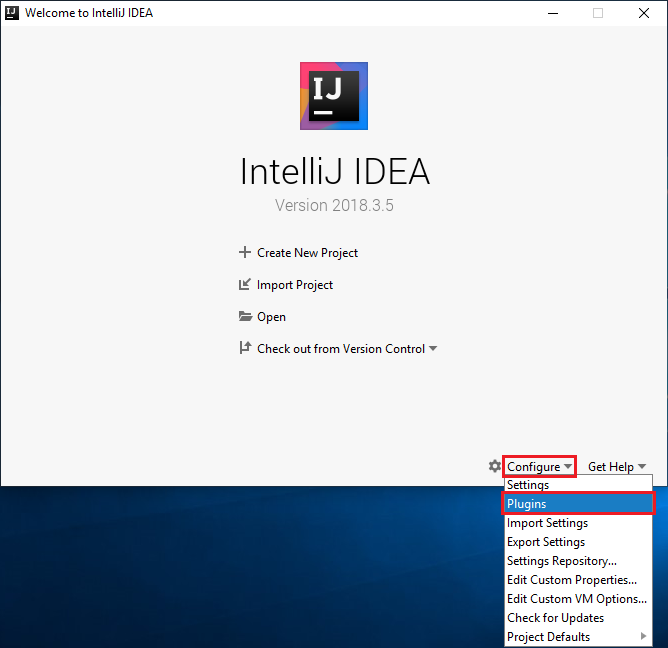
Selezionare Installa per il plug-in Scala che è disponibile nella nuova finestra.
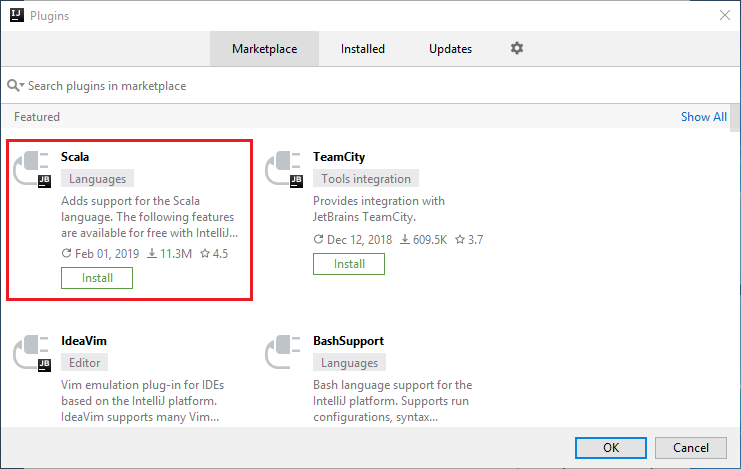
Dopo che il plug-in è stato installato correttamente, è necessario riavviare l'IDE.
Creare un'applicazione Scala Spark per un cluster HDInsight Spark
Avviare IntelliJ IDEA e selezionare Crea nuovo progetto per aprire la finestra Nuovo progetto.
Selezionare Azure Spark/HDInsight nel riquadro sinistro.
Selezionare Progetto Spark (Scala) dalla finestra principale.
Nell'elenco a discesa Strumento di compilazione selezionare una delle opzioni seguenti:
Maven, per ottenere supporto per la creazione guidata di un progetto Scala.
SBT, per la gestione delle dipendenze e la compilazione per il progetto Scala.
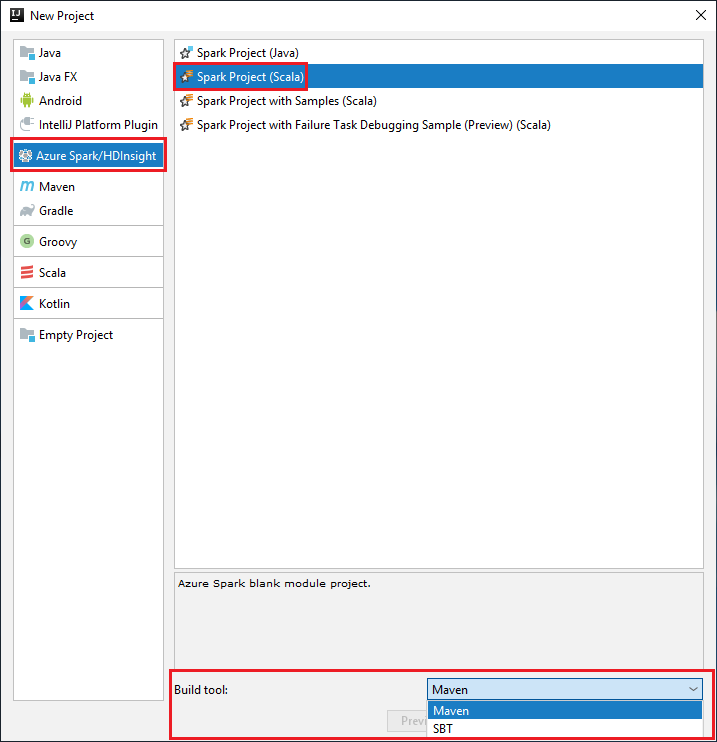
Selezionare Avanti.
Nella finestra Nuovo progetto specificare le informazioni seguenti:
Proprietà Descrizione Nome progetto Immetti un nome. Questo articolo usa myApp.Posizione del progetto Immettere il percorso in cui salvare il progetto. Project SDK (SDK progetto) Questo campo potrebbe essere vuoto al primo uso di IDEA. Selezionare New (Nuovo) e passare al proprio JDK. Versione Spark La creazione guidata integra la versione corretta dell'SDK di Spark e Scala. Se la versione del cluster Spark è precedente alla 2.0, selezionare Spark 1.x. In caso contrario, selezionare Spark2.x. In questo esempio viene usata la versione Spark 2.3.0 (Scala 2.11.8). 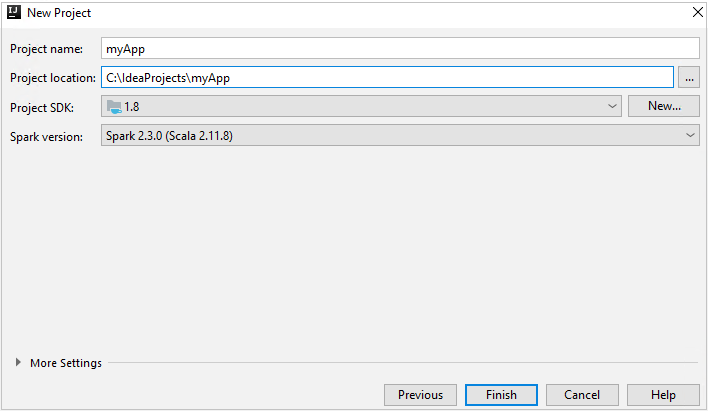
Selezionare Fine. Potrebbero occorrere alcuni minuti prima che il progetto diventi disponibile.
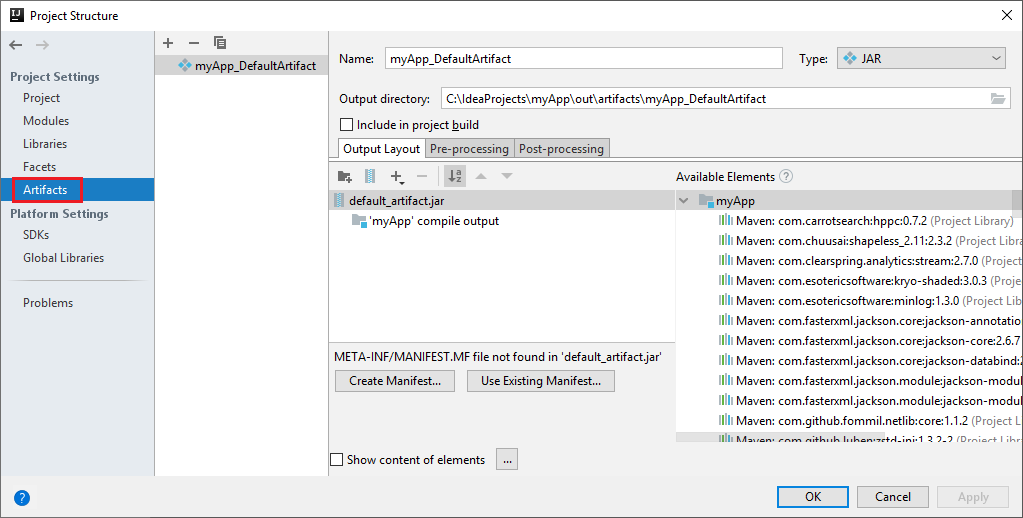
Il progetto Spark crea automaticamente un artefatto. Per visualizzare l'artefatto, eseguire questa procedura:
a. Dalla barra dei menu passare a File>Struttura del progetto....
b. Dalla finestra Struttura del progetto, selezionare Artefatti.
c. Selezionare Annulla dopo aver visualizzato l'elemento.
Aggiungere il codice sorgente dell'applicazione seguendo questa procedura:
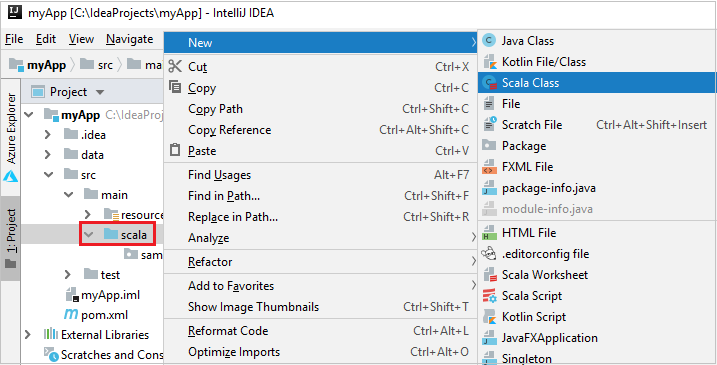
a. Dal progetto, passare a myApp>src>principale>scala.
b. Fare doppio clic su scala, quindi passare a Nuovo>classe Scala.
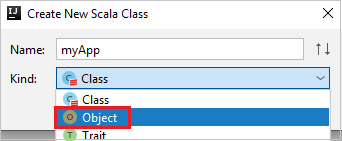
c. Nella finestra di dialogo Create New Scala Class (Crea nuova classe Scala) immettere un nome, selezionare Object (Oggetto) per il menu a discesa Kind (Tipologia) e quindi selezionare OK.
d. Il file myApp.scala viene quindi aperto nella visualizzazione principale. Sostituire il codice predefinito con il codice seguente:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Il codice legge i dati dal file HVAC.csv, disponibile in tutti i cluster HDInsight Spark, recupera le righe con una sola cifra nella settima colonna del file CSV e scrive l'output in
/HVACOutnel contenitore di archiviazione predefinito per il cluster.
Connettersi al cluster HDInsight
L'utente può accedere alla sottoscrizione di Azure o collegare un cluster HDInsight. Usare la credenziale Ambari username/password o aggiunta a un dominio per connettersi al cluster HDInsight.
Accedere alla sottoscrizione di Azure.
Dalla barra dei menu, passare a Visualizza>strumento Windows>Azure Explorer.
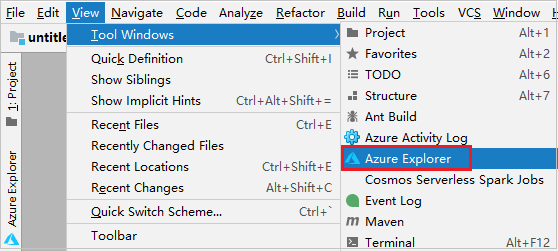
Da Azure Explorer, fare clic con il pulsante destro del mouse sul nodo Azure e quindi scegliere Sign In (Accedi).
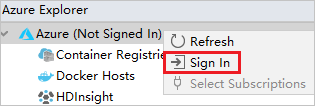
Nella finestra di dialogo Azure Sign In (Accesso ad Azure) scegliere Accesso dispositivo e quindi selezionare Accedi.
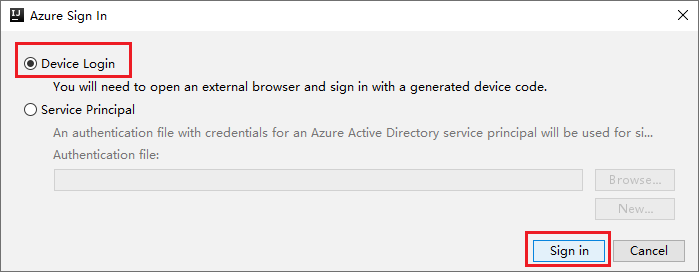
Nella finestra di dialogo Azure Device Login (Accesso dispositivo Azure) fare clic su Copy&Open (Copia e apri).
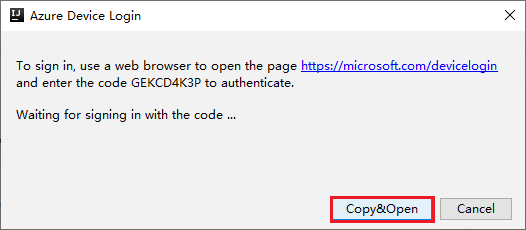
Nell'interfaccia del browser incollare il codice e quindi fare clic su Avanti.
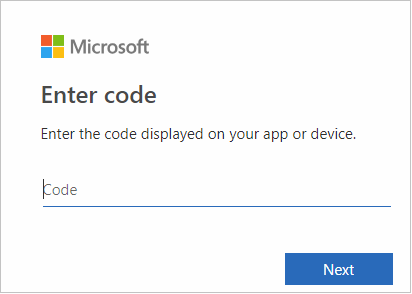
Immettere le credenziali di Azure e quindi chiudere il browser.
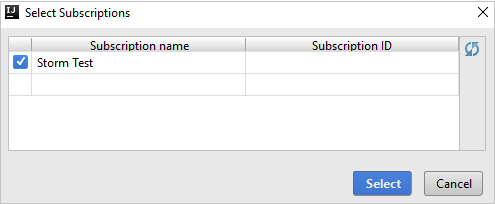
Dopo l'accesso, la finestra di dialogo Selezionare le sottoscrizioni elenca tutte le sottoscrizioni di Azure associate alle credenziali. Selezionare la sottoscrizione e quindi il pulsante Aggiorna.
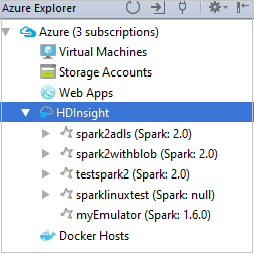
Da Azure Explorer espandere HDInsight per visualizzare i cluster HDInsight Spark disponibili nelle sottoscrizioni.
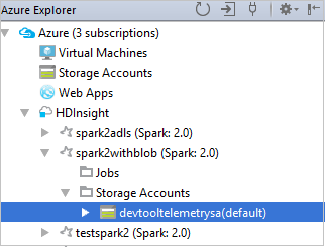
Per visualizzare le risorse, ad esempio gli account di archiviazione, associate al cluster, è possibile espandere ancora un nodo di tipo nome del cluster.
Collegare un cluster
È possibile collegare un cluster HDInsight usando lo username gestito di Apache Ambari. Analogamente, è possibile collegare un cluster HDInsight aggiunto al dominio tramite il dominio e il nome utente, come user1@contoso.com. È anche possibile collegare il cluster del servizio Livy.
Dalla barra dei menu, passare a Visualizza>strumento Windows>Azure Explorer.
Da Azure Explorer, fare clic con il pulsante destro del mouse sul nodo HDInsight e quindi scegliere Link A Cluster (collegare un cluster).
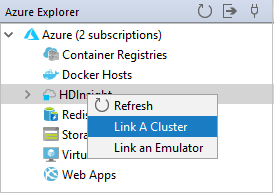
Le opzioni disponibili nella finestra Link A Cluster (collegare un cluster) variano a seconda di quale valore si seleziona dall'elenco a discesa Link Resource Type (tipo di risorsa di collegamento). Immettere i valori e quindi selezionare OK.
Cluster HDInsight
Proprietà valore Tipo di risorsa di collegamento Selezionare HDInsight Cluster nell'elenco a discesa. Nome/URL del cluster Immettere il nome del cluster. Tipo di autenticazione Lasciare come autenticazione di base Nome utente Immettere il nome utente del cluster, il cui valore predefinito è admin. Password Immettere la password per il nome utente. 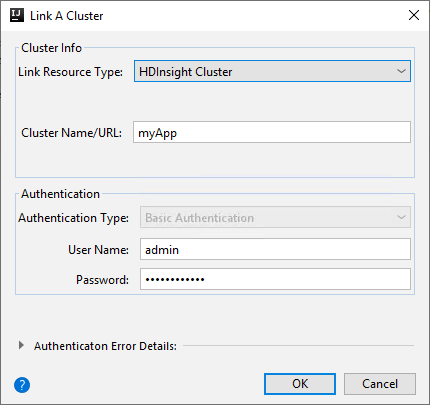
Livy Service
Proprietà valore Tipo di risorsa di collegamento Selezionare Livy Service nell'elenco a discesa. Livy Endpoint Inserire Livy Endpoint Nome del cluster Immettere il nome del cluster. Yarn Endpoint Facoltativo. Tipo di autenticazione Lasciare come autenticazione di base Nome utente Immettere il nome utente del cluster, il cui valore predefinito è admin. Password Immettere la password per il nome utente. 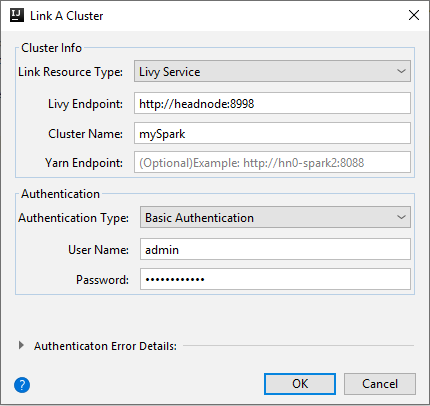
È possibile visualizzare il cluster collegato dal nodo HDInsight.
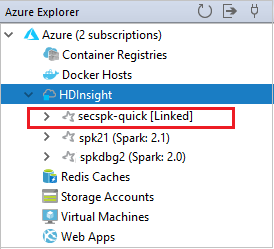
È inoltre possibile scollegare un cluster in Azure Explorer (Esplora Azure).
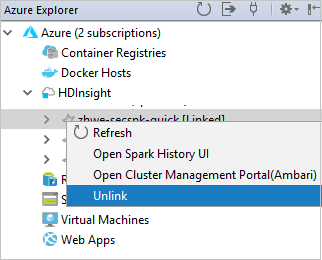
Eseguire un'applicazione Spark in Scala in un cluster HDInsight Spark
Dopo aver creato un'applicazione Scala, è possibile inviarla al cluster.
Da Project (Progetto) passare a myApp>src>main>scala>myApp. Fare clic con il pulsante destro del mouse su myApp e selezionare Submit Spark Application (probabilmente sarà disponibile nella parte inferiore dell'elenco).
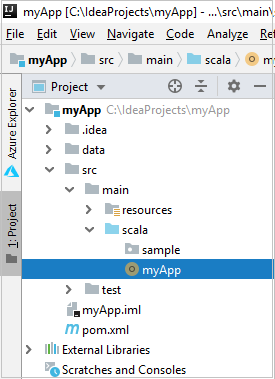
Nella finestra di dialogo Invia applicazione Spark selezionare 1. Spark in HDInsight.
Nella finestra Modifica configurazione specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Cluster Spark (solo Linux) Selezionare il cluster HDInsight Spark in cui eseguire l'applicazione. Selezionare un artefatto da inviare Lasciare l'impostazione predefinita. Nome della classe principale Il valore predefinito corrisponde alla classe principale del file selezionato. È possibile modificare la classe selezionando i puntini di sospensione (...) e scegliendo una classe diversa. Configurazioni del processo È possibile modificare le chiavi e i valori predefiniti. Per altre informazioni, vedere Apache Livy REST API (API REST di Apache Livy). Argomenti della riga di comando È possibile immettere gli argomenti divisi da uno spazio per la classe principale, se necessario. Referenced Jars (file JAR di riferimento) e Referenced Files (file di riferimento) È possibile immettere i percorsi per file e jar di riferimento, se presenti. È anche possibile selezionare i file nel file system virtuale di Azure, che attualmente supporta solo cluster di Azure Data Lake Store Gen 2. Per altre informazioni: Configurazione di Apache Spark. Vedere anche Come caricare le risorse nel cluster. Archivio di caricamento del processo Espandere per visualizzare le opzioni aggiuntive. Tipo di archiviazione Selezionare Usare Azure Blob per caricare nell'elenco a discesa. Account di archiviazione Immettere l'account di archiviazione. Chiave di archiviazione Immettere la chiave di archiviazione. Contenitore di archiviazione Selezionare il contenitore di archiviazione dall'elenco a discesa una volta immessi Account di archiviazione e chiave di archiviazione. 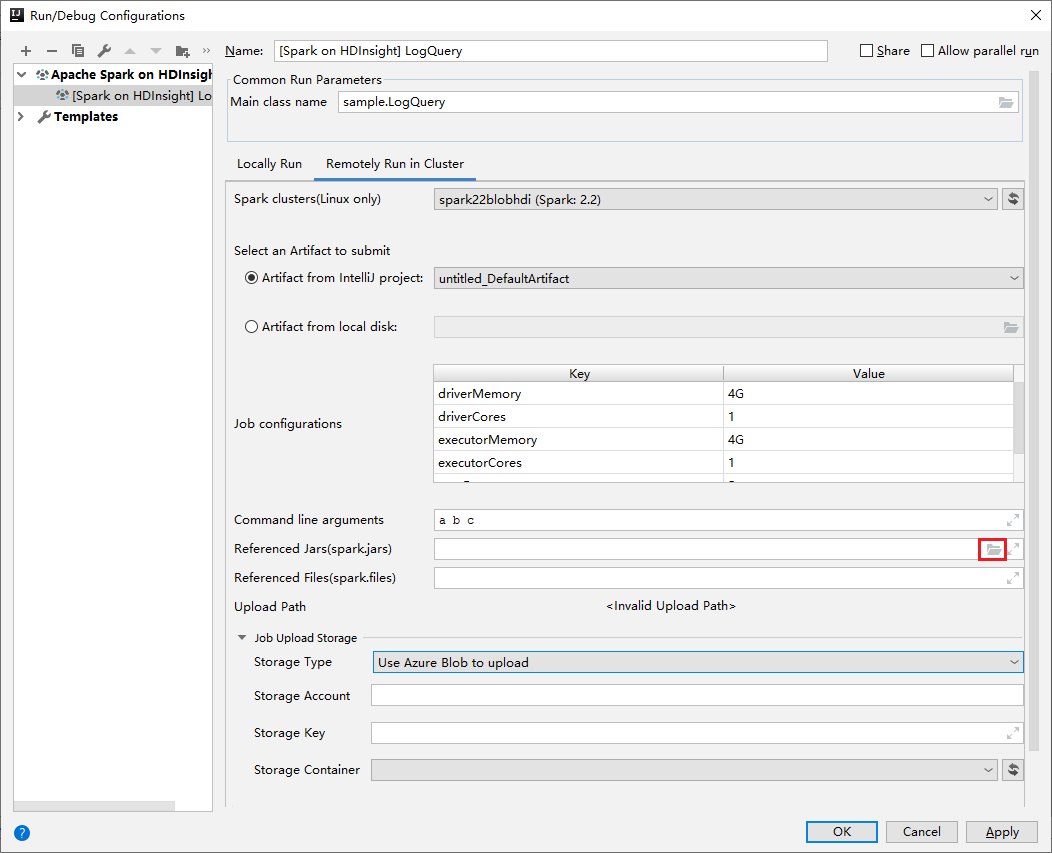
Fare clic su SparkJobRun per inviare il progetto al cluster selezionato. La scheda Remote Spark Job in Cluster (Processo Spark remoto nel cluster) visualizza lo stato dell'esecuzione del processo, nella parte inferiore. È possibile arrestare l'applicazione facendo clic sul pulsante rosso.
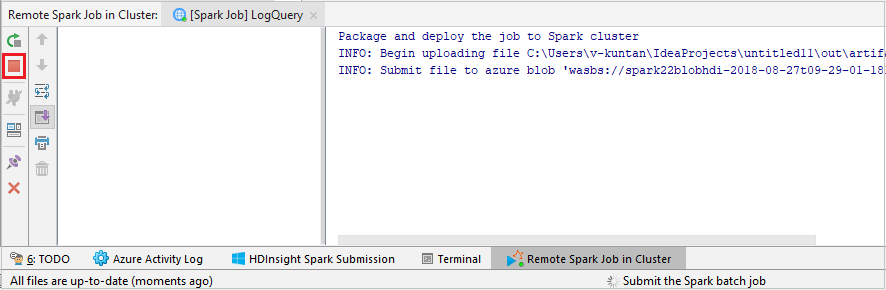
Eseguire il debug di applicazioni Apache Spark in modalità locale o remota in un cluster HDInsight
Si consiglia anche di usare un altro modo per inviare l'applicazione Spark al cluster. È ad esempio possibile configurare i parametri nell'IDE Run/Debug configurations (Esegui/Esegui il debug delle configurazioni). Vedere Eseguire il debug di applicazioni Apache Spark in locale o in remoto in un cluster HDInsight con Azure Toolkit for IntelliJ tramite SSH.
Accedere e gestire i cluster HDInsight Spark tramite il Toolkit di Azure per IntelliJ
È possibile eseguire varie operazioni usando Azure Toolkit for IntelliJ. La maggior parte delle operazioni viene avviata da Azure Explorer. Dalla barra dei menu, passare a Visualizza>strumento Windows>Azure Explorer.
Accedere alla visualizzazione del processo
Da Azure Explorer passare a HDInsight<>Processi del cluster.>>
Nel riquadro destro la scheda Spark Job View (Visualizzazione processi Spark) visualizza tutte le applicazioni eseguite nel cluster. Selezionare il nome dell'applicazione per cui si vogliono visualizzare altri dettagli.
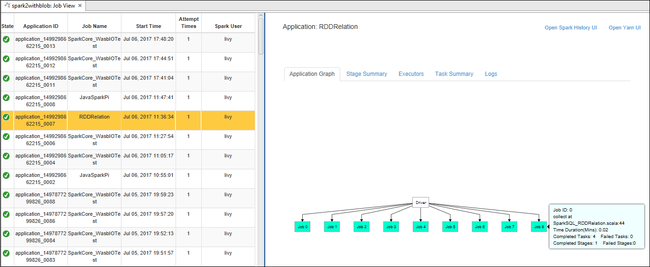
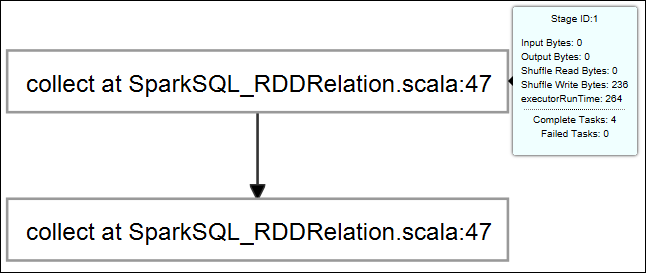
Per visualizzare le informazioni di base sui processi in esecuzione, passare il mouse sopra il grafico relativo al processo. Per visualizzare i grafici sulle fasi e le informazioni generate da ogni processo, selezionare un nodo nel grafico relativo al processo.
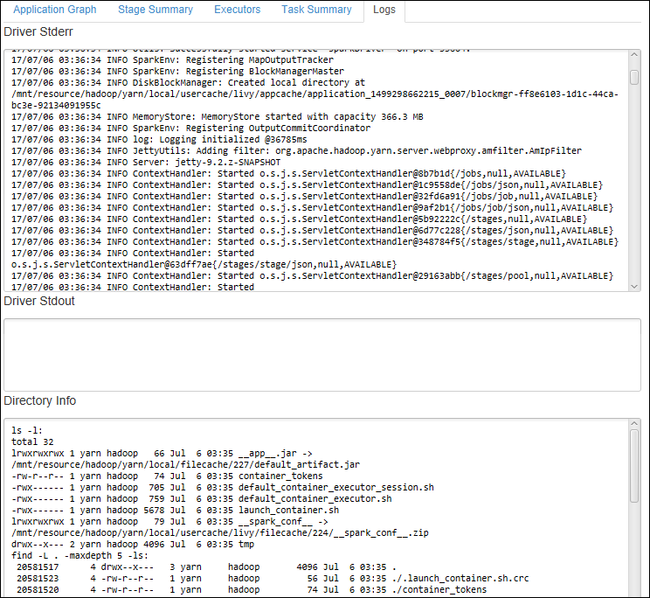
Per visualizzare i log di uso più frequente, ad esempio Driver Stderr, Driver Stdout e Directory Info, selezionare la scheda Log.
È possibile visualizzare l'interfaccia utente della cronologia spark e l'interfaccia utente YARN (a livello di applicazione). Selezionare un collegamento nella parte superiore della finestra.
Accedere al Server cronologia Spark
Da Azure Explorer espandere HDInsight, fare clic con il pulsante destro del mouse sul nome del cluster Spark e quindi scegliere Open Spark History UI (Apri UI cronologia Spark).
Quando richiesto, immettere le credenziali dell'amministratore del cluster, specificate durante la configurazione del cluster.
Nel dashboard del server della cronologia di Spark è possibile usare il nome dell'applicazione per cercare l'applicazione di cui è appena stata completata l'esecuzione. Nel codice precedente impostare il nome dell'applicazione usando
val conf = new SparkConf().setAppName("myApp"). Il nome dell'applicazione Spark è myApp.
Avviare il portale di Ambari
Da Azure Explorer espandere HDInsight, fare clic con il pulsante destro del mouse sul nome del cluster Spark e quindi scegliere Open Cluster Management Portal (Ambari) (Apri il portale di gestione cluster - Ambari).
Quando richiesto, immettere le credenziali dell'amministratore per il cluster. Queste credenziali sono state specificate durante il processo di configurazione del cluster.
Gestire le sottoscrizioni di Azure
Per impostazione predefinita, il Toolkit di Azure per IntelliJ elenca i cluster Spark di tutte le sottoscrizioni di Azure. Se necessario, è possibile specificare le sottoscrizioni a cui si vuole accedere.
Da Azure Explorer fare clic con il pulsante destro del mouse sul nodo radice Azure e quindi scegliere Scegli sottoscrizioni.
Dalla finestra Seleziona sottoscrizioni, deselezionare le caselle di controllo accanto alla sottoscrizione alla quale non si vuole accedere e quindi selezionare Chiudi.
Console Spark
È possibile eseguire la console locale Spark (Scala) o eseguire la console della sessione Spark Livy interattiva (Scala).
Console locale Spark (Scala)
Assicurarsi di aver soddisfatto il prerequisito relativo al file WINUTILS.EXE.
Dalla barra dei menu passare a Run>Edit Configurations... (Esegui > Modifica configurazioni).
Dalla finestra Eseguire configurazioni di debug, nel riquadro a sinistra, passare a Apache Spark in HDInsight>[Spark in HDInsight] myApp.
Nella finestra principale selezionare la
Locally Runscheda .Specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Job main class (Classe principale del processo) Il valore predefinito corrisponde alla classe principale del file selezionato. È possibile modificare la classe selezionando i puntini di sospensione (...) e scegliendo una classe diversa. Variabili di ambiente Verificare che il valore di HADOOP_HOME sia corretto. WINUTILS.exe location (Percorso di WINUTILS.exe) Assicurarsi che il percorso sia corretto. 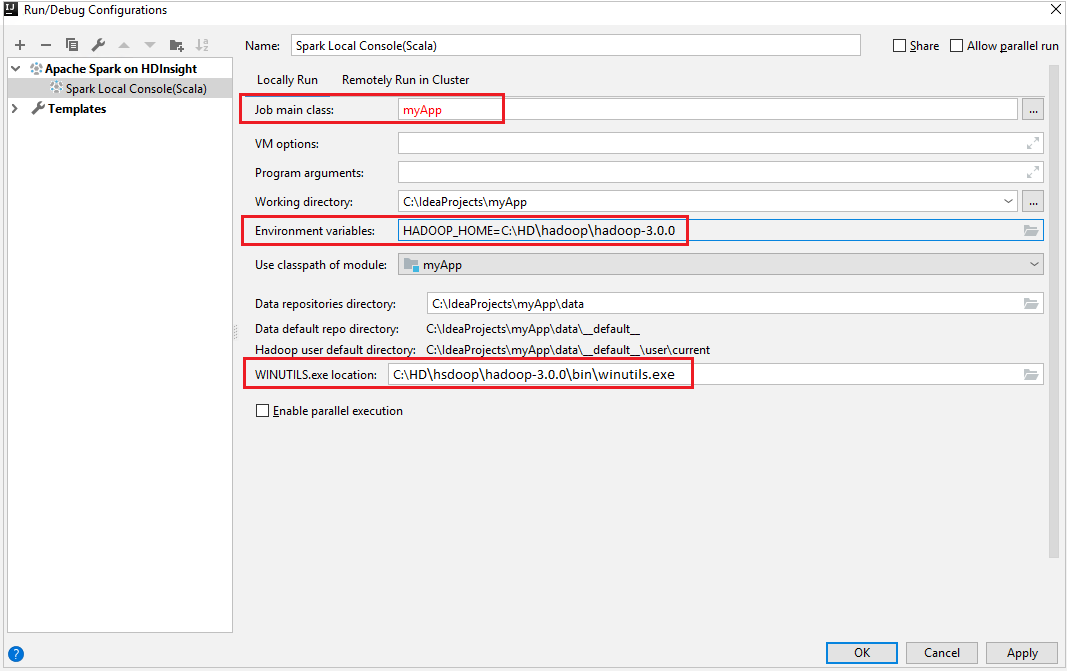
Da Project (Progetto) passare a myApp>src>main>scala>myApp.
Dalla barra dei menu passare a Tools>Spark Console>Run Spark Local Console(Scala) (Strumenti > Console Spark > Esegui console locale Spark - Scala).
Potrebbero venire visualizzate due finestre di dialogo in cui viene chiesto se si vuole correggere automaticamente le dipendenze. In caso affermativo, selezionare Auto Fix (Correggi automaticamente).
La console dovrebbe essere simile all'immagine seguente. Nella finestra della console digitare
sc.appNamee quindi premere CTRL+INVIO. Verrà visualizzato il risultato. È possibile terminare la console locale facendo clic sul pulsante rosso.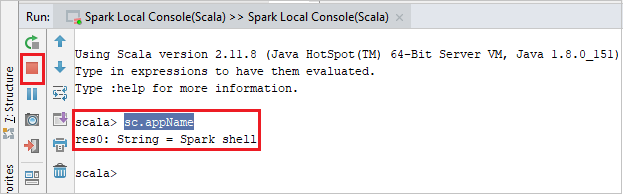
Console della sessione Spark Livy interattiva (Scala)
Dalla barra dei menu passare a Run>Edit Configurations... (Esegui > Modifica configurazioni).
Dalla finestra Eseguire configurazioni di debug, nel riquadro a sinistra, passare a Apache Spark in HDInsight>[Spark in HDInsight] myApp.
Nella finestra principale selezionare la
Remotely Run in Clusterscheda .Specificare i valori seguenti e quindi selezionare OK:
Proprietà valore Cluster Spark (solo Linux) Selezionare il cluster HDInsight Spark in cui eseguire l'applicazione. Nome della classe principale Il valore predefinito corrisponde alla classe principale del file selezionato. È possibile modificare la classe selezionando i puntini di sospensione (...) e scegliendo una classe diversa. 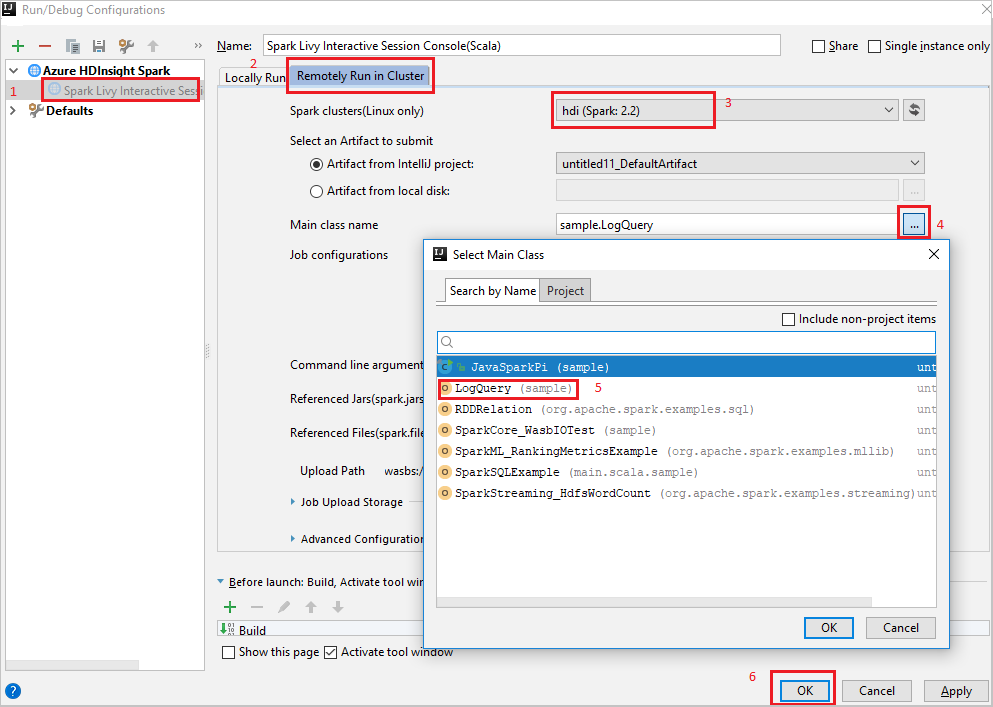
Da Project (Progetto) passare a myApp>src>main>scala>myApp.
Dalla barra dei menu passare a Tools>Spark Console>Run Spark Livy Interactive Session Console(Scala) (Strumenti > Console Spark > Esegui console della sessione Spark Livy interattiva -Scala).
La console dovrebbe essere simile all'immagine seguente. Nella finestra della console digitare
sc.appNamee quindi premere CTRL+INVIO. Verrà visualizzato il risultato. È possibile terminare la console locale facendo clic sul pulsante rosso.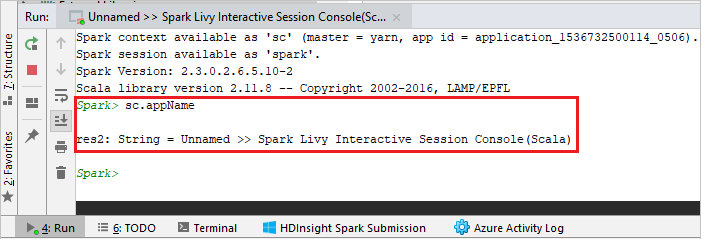
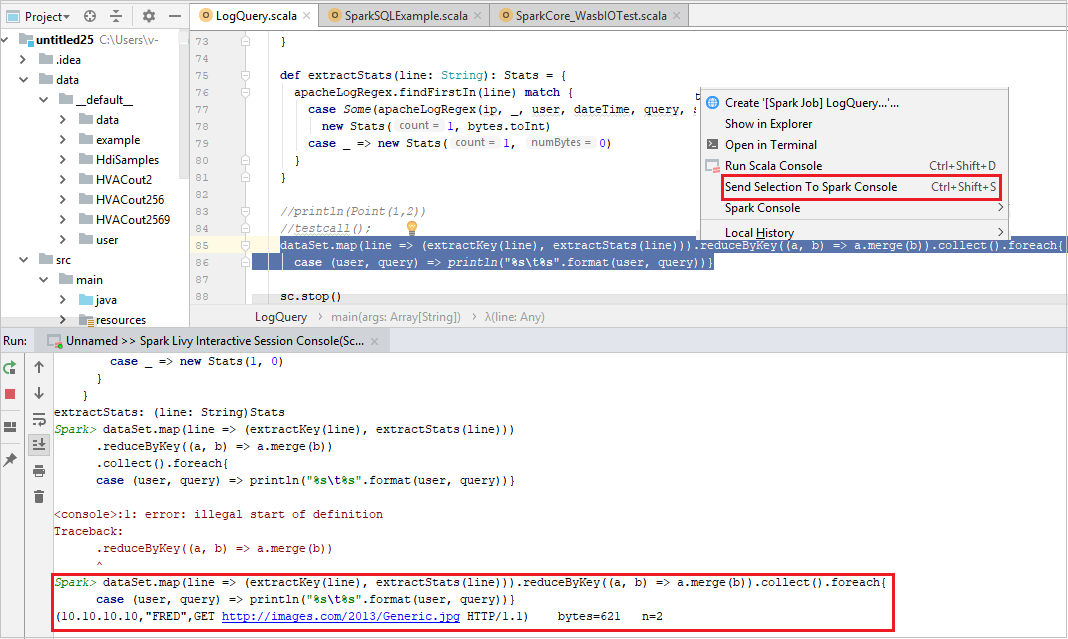
Send Selection to Spark Console (Invia selezione alla console Spark)
È utile prevedere il risultato dello script inviando una parte di codice alla console locale o alla console di sessione interattiva Livy (Scala). È possibile evidenziare il codice nel file Scala e quindi fare clic con il pulsante destro del mouse su Send Selection To Spark Console (Invia selezione alla console Spark). Il codice selezionato verrà inviato alla console. Il risultato verrà visualizzato dopo il codice nella console. La console controllerà gli errori, se presenti.
Eseguire l'integrazione con broker di identità di HDInsight
Connessione al cluster HDInsight ESP con ID Broker (HIB)
È possibile seguire la procedura normale per accedere alla sottoscrizione di Azure per connettersi al cluster ESP HDInsight con ID Broker (HIB). Dopo l'accesso, verrà visualizzato l'elenco dei cluster in Azure Explorer. Per altre istruzioni, vedere Connettersi al cluster HDInsight.
Eseguire un'applicazione Spark Scala in un cluster HDInsight ESP con ID Broker (HIB)
È possibile seguire i normali passaggi per inviare il processo al cluster HDInsight ESP con ID Broker (HIB). Per altre istruzioni, vedere Eseguire un'applicazione Spark in Scala in un cluster HDInsight Spark.
I file necessari vengono caricati in una cartella denominata con l'account di accesso ed è possibile visualizzare il percorso di caricamento nel file di configurazione.

Console Spark in un cluster HDInsight ESP con ID Broker (HIB)
È possibile eseguire la console locale Spark (Scala) o la console di sessione interattiva Spark Livy (Scala) in un cluster HDInsight ESP con ID Broker (HIB). Per altre istruzioni, vedere Console Spark.
Nota
Per il cluster ESP HDInsight con broker di identità, il collegamento di un cluster e il debug di applicazioni Apache Spark in remoto non sono attualmente supportati.
Ruolo di sola lettura
Quando gli utenti inviano processi a un cluster con autorizzazione di sola lettura, le credenziali di Ambari sono obbligatorie.
Collegare un cluster dal menu di scelta rapida
Accedere con l'account di un ruolo di sola lettura.
Da Azure Explorer espandere HDInsight per visualizzare i cluster HDInsight Spark disponibili nella sottoscrizione. I cluster contrassegnati da "Role:Reader" (Ruolo:Lettore) hanno autorizzazioni di ruolo di sola lettura.
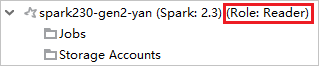
Fare clic con il pulsante destro del mouse sul cluster con autorizzazione di ruolo di sola lettura. Selezionare Link this cluster (Collega questo cluster) dal menu di scelta rapida per collegare il cluster. Immettere il nome utente e la password di Ambari.
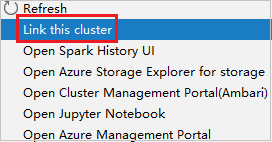
Se il cluster è stato collegato correttamente, HDInsight viene aggiornato. La fase del cluster diventerà Linked (Collegato).
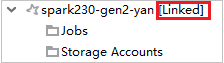
Collegare un cluster espandendo il nodo Jobs (Processi)
Fare clic sul nodo Jobs (Processi). Verrà visualizzata la finestra Cluster Job Access Denied (Accesso negato al cluster Jobs).
Fare clic su Link this cluster (Collega questo cluster) per collegare il cluster.

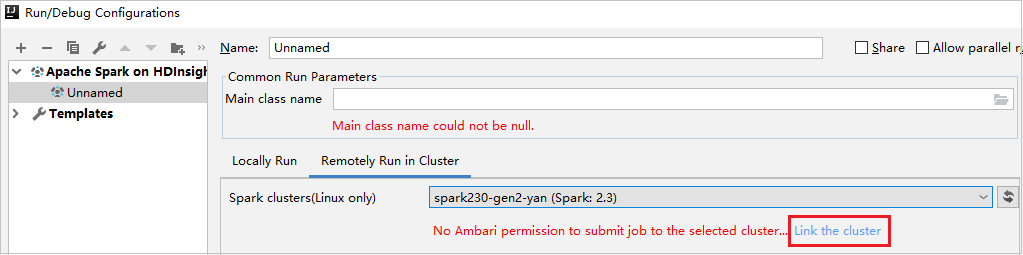
Collegare un cluster dalla finestra Run/Debug Configurations (Configurazioni di esecuzione/debug)
Creare una configurazione di HDInsight e quindi selezionare Remotely Run in Cluster (Esecuzione remota nel cluster).
Selezionare un cluster con autorizzazione di ruolo di sola lettura per Spark clusters(Linux only) (Spark cluster (solo Linux)). Viene visualizzato un messaggio di avviso. È possibile fare clic su Collega questo cluster per collegare il cluster.
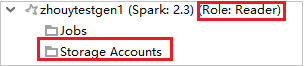
Visualizzare gli account di archiviazione
Per i cluster con autorizzazione di ruolo di sola lettura fare clic sul nodo Storage Accounts (Account di archiviazione). Verrà visualizzata la finestra Storage Access Denied (Accesso negato alla risorsa di archiviazione). È possibile fare clic su Apri Azure Storage Explorer per aprire Storage Explorer.

Per i cluster collegati fare clic sul nodo Storage Accounts (Account di archiviazione). Verrà visualizzata la finestra Storage Access Denied (Accesso negato alla risorsa di archiviazione). È possibile fare clic su Apri Azure Storage Explorer per aprire Storage Explorer.

Convertire le applicazioni IntelliJ IDEA esistenti per usare il Toolkit di Azure per IntelliJ
È possibile convertire le applicazioni Spark Scala esistenti create in IntelliJ IDEA per renderle compatibili con Azure Toolkit for IntelliJ. È possibile usare il plug-in per inviare le applicazioni a un cluster HDInsight Spark.
Per un'applicazione Spark Scala esistente creata tramite IntelliJ IDEA, aprire il file associato
.iml.A livello radice, è un elemento del modulo come il testo seguente:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Modificare l'elemento da aggiungere
UniqueKey="HDInsightTool"in modo che l'elemento del modulo abbia un aspetto simile al testo seguente:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Salvare le modifiche. L'applicazione dovrebbe ora essere compatibile con il Toolkit di Azure per IntelliJ. È possibile verificarlo facendo clic con il pulsante destro del mouse sul nome del progetto in Progetti. Nel menu a comparsa viene ora visualizzata l'opzione Submit Spark Application to HDInsight(Invia applicazione Spark a HDInsight).
Pulire le risorse
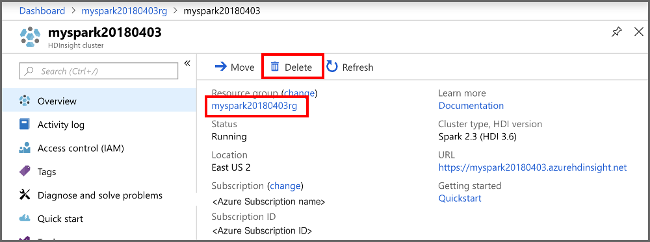
Se non si intende continuare a usare questa applicazione, eliminare il cluster creato con i passaggi seguenti:
Accedere al portale di Azure.
Nella casella Ricerca in alto digitare HDInsight.
Selezionare Cluster HDInsight in Servizi.
Nell'elenco dei cluster HDInsight visualizzati selezionare ... accanto al cluster creato per questo articolo.
Selezionare Elimina. Selezionare Sì.
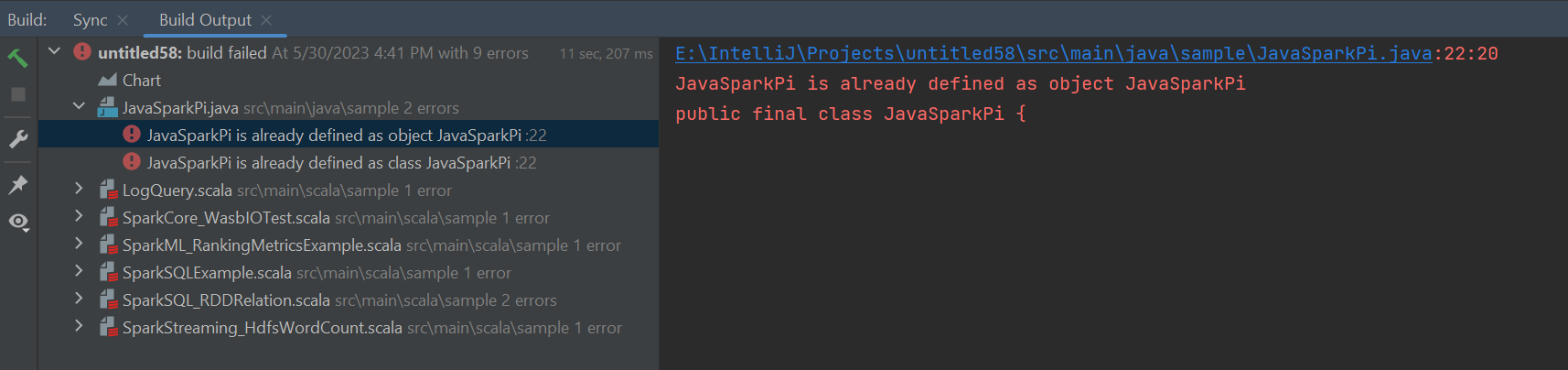
Errori e soluzioni
Deselezionare la cartella src come Origini se si verificano errori di compilazione non riusciti come indicato di seguito:
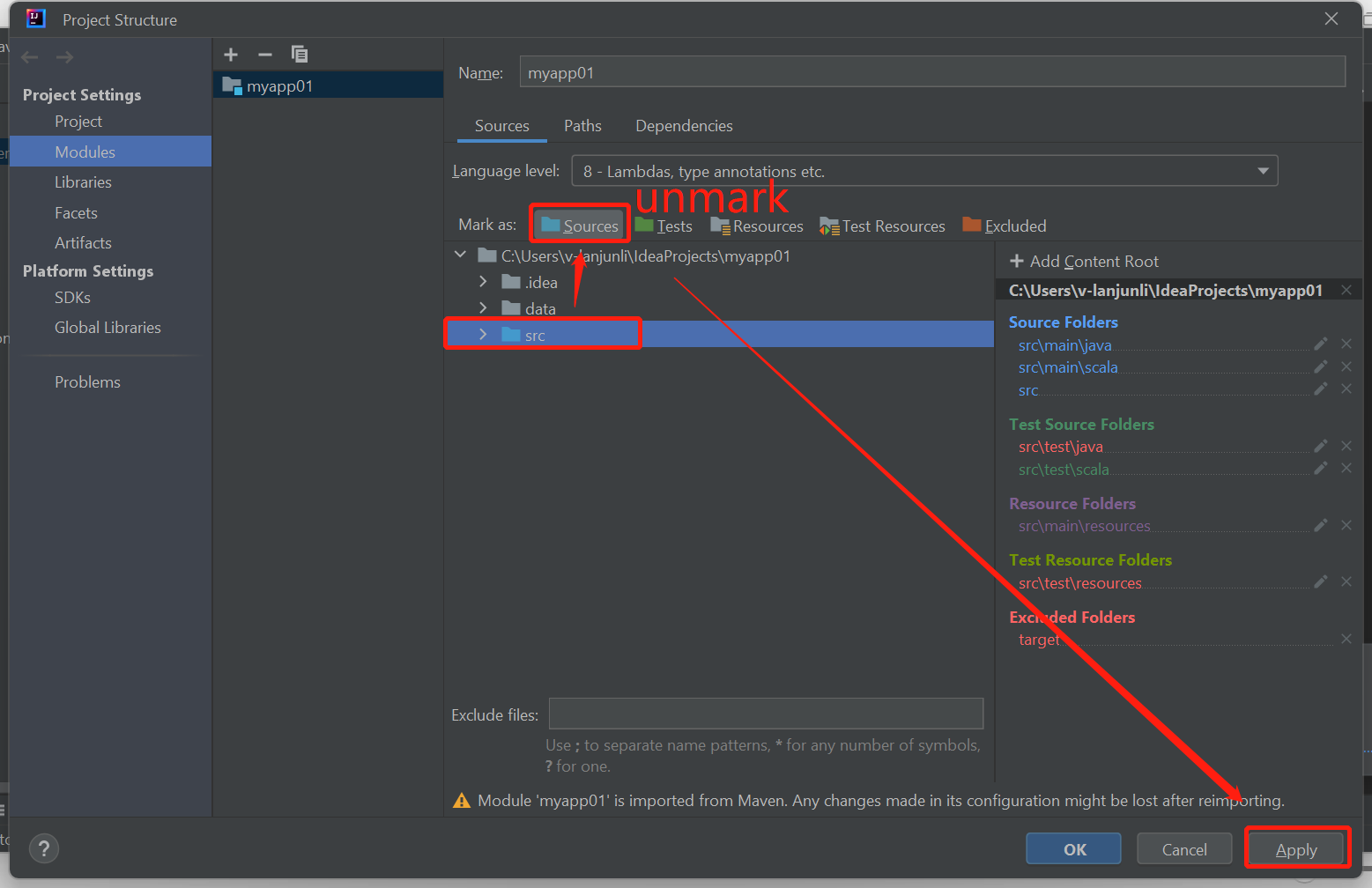
Deselezionare la cartella src come Origini per risolvere questo problema:
Passare a File e selezionare La struttura del progetto.
Selezionare i moduli in Project Impostazioni.
Selezionare il file src e deselezionare il nome Sources (Origini).
Fare clic sul pulsante Applica e quindi sul pulsante OK per chiudere la finestra di dialogo.
Passaggi successivi
In questo articolo si è appreso come usare il plug-in Azure Toolkit for IntelliJ per sviluppare applicazioni Apache Spark scritte in Scala. Quindi li ha inviati a un cluster HDInsight Spark direttamente dall'ambiente di sviluppo integrato (IDE) di IntelliJ. Passare all'articolo successivo per scoprire come eseguire il pull dei dati registrati in Apache Spark in uno strumento di analisi BI come Power BI.