Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo contiene istruzioni dettagliate su come usare gli strumenti HDInsight in Azure Toolkit for IntelliJ per eseguire il debug remoto di applicazioni in un cluster di HDInsight.
Prerequisiti
Un cluster Apache Spark in HDInsight. Vedere Creare un cluster Apache Spark.
Per gli utenti di Windows: durante l'esecuzione dell'applicazione Spark Scala locale in un computer Windows, è possibile che venga generata un'eccezione, come illustrato in SPARK-2356. che si verifica a causa di un file WinUtils.exe mancante in Windows.
Per risolvere questo errore, scaricare Winutils.exe in un percorso come C:\WinUtils\bin. È quindi necessario aggiungere una variabile di ambiente HADOOP_HOME e impostare il valore della variabile su C:\WinUtils.
IntelliJ IDEA (l'edizione Community è gratuita).
Un client SSH. Per altre informazioni, vedere Connettersi a HDInsight (Apache Hadoop) con SSH.
Creare un'applicazione Spark Scala
Avviare IntelliJ IDEA e selezionare Crea nuovo progetto per aprire la finestra Nuovo progetto.
Selezionare Apache Spark/HDInsight nel riquadro sinistro.
Selezionare Progetto Spark con esempi (Scala) nella finestra principale.
Nell'elenco Strumento di compilazione selezionare uno degli strumenti seguenti:
- Maven, per ottenere supporto per la creazione guidata di un progetto Scala.
- SBT, per la gestione delle dipendenze e la compilazione per il progetto Scala.
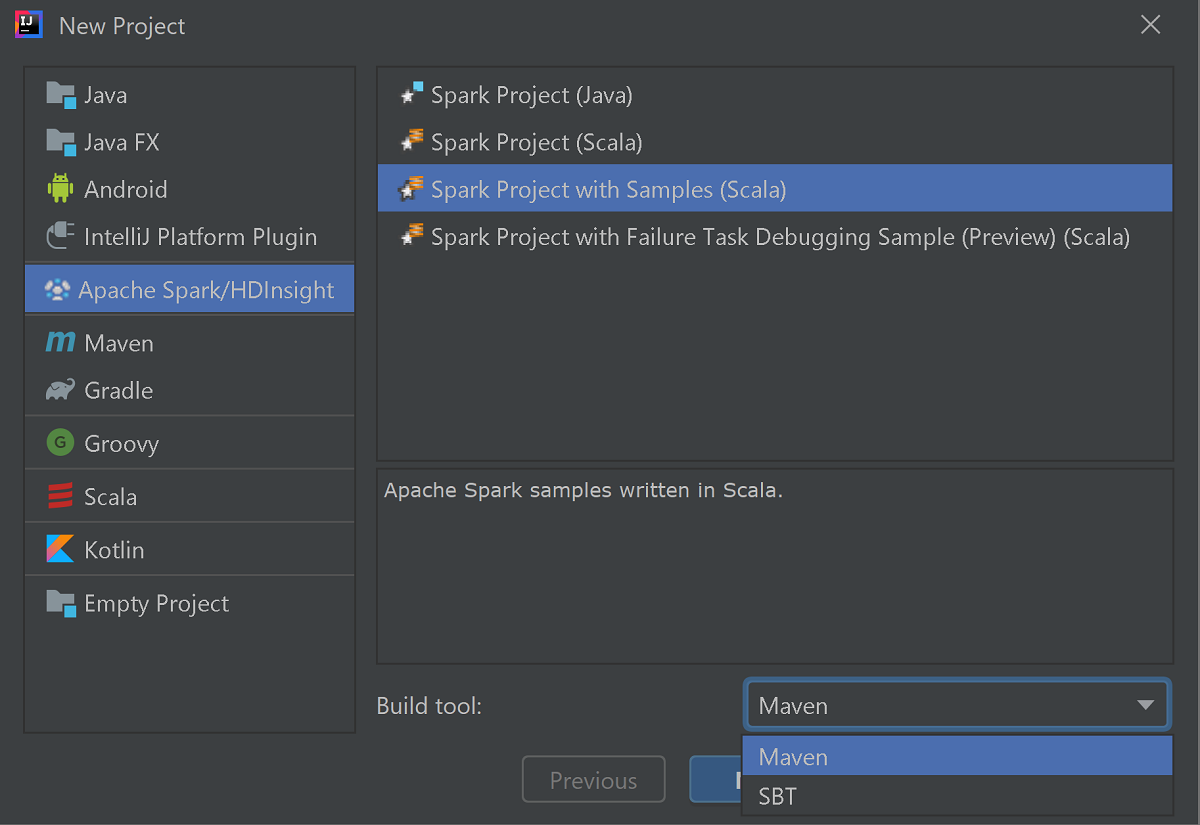
Selezionare Avanti.
Nella finestra Nuovo progetto successiva specificare le informazioni seguenti:
Proprietà Descrizione Nome progetto Immetti un nome. Questa procedura dettagliata usa myApp.Posizione del progetto Immettere il percorso desiderato in cui salvare il progetto. Project SDK (SDK progetto) Se vuoto, selezionare Nuovo e passare a JDK. Versione Spark La creazione guidata integra la versione corretta dell'SDK di Spark e Scala. Se la versione del cluster Spark è precedente alla 2.0, selezionare Spark 1.x. In caso contrario, selezionare Spark 2.x.. In questo esempio viene usata la versione Spark 2.3.0 (Scala 2.11.8). 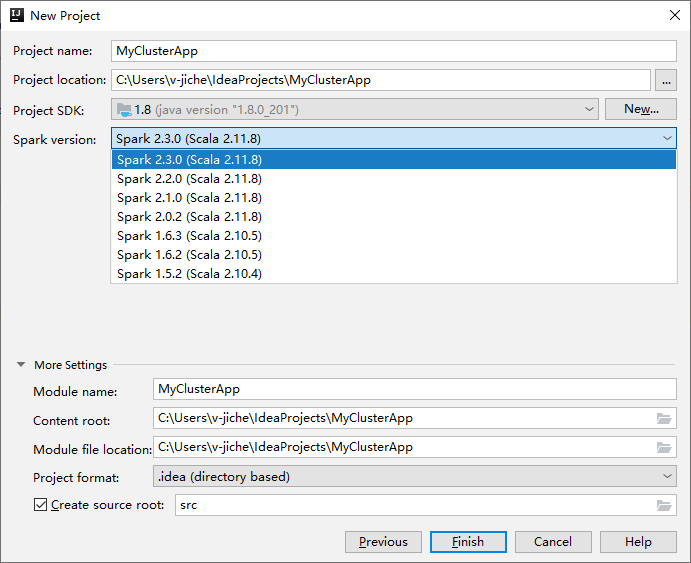
Selezionare Fine. Potrebbero occorrere alcuni minuti prima che il progetto diventi disponibile. Osservare l'angolo inferiore destro per lo stato di avanzamento.
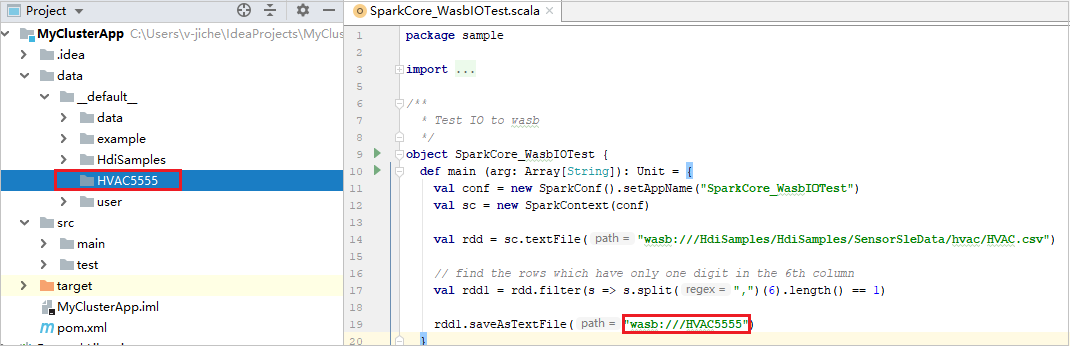
Espandere il progetto e passare all'esempio scala>principale>di src.> Fare doppio clic su SparkCore_WasbIOTest.
Eseguire l'esecuzione in locale
Nello script SparkCore_WasbIOTest fare clic con il pulsante destro del mouse sull'editor di script e quindi selezionare l'opzione Esegui 'SparkCore_WasbIOTest' per eseguire l'esecuzione locale.
Dopo aver completato l'esecuzione in locale, è possibile visualizzare il file di output salvato nella directory data>default della finestra di gestione del progetto corrente.
Per questi strumenti la configurazione dell'esecuzione in locale predefinita viene impostata automaticamente quando l'esecuzione e il debug vengono eseguiti in modalità locale. Aprire la configurazione [Spark in HDInsight] XXX nell'angolo in alto a destra. È possibile visualizzare [ Spark in HDInsight]XXX già creato in Apache Spark in HDInsight. Passare alla scheda Locally Run (Esecuzione in locale).
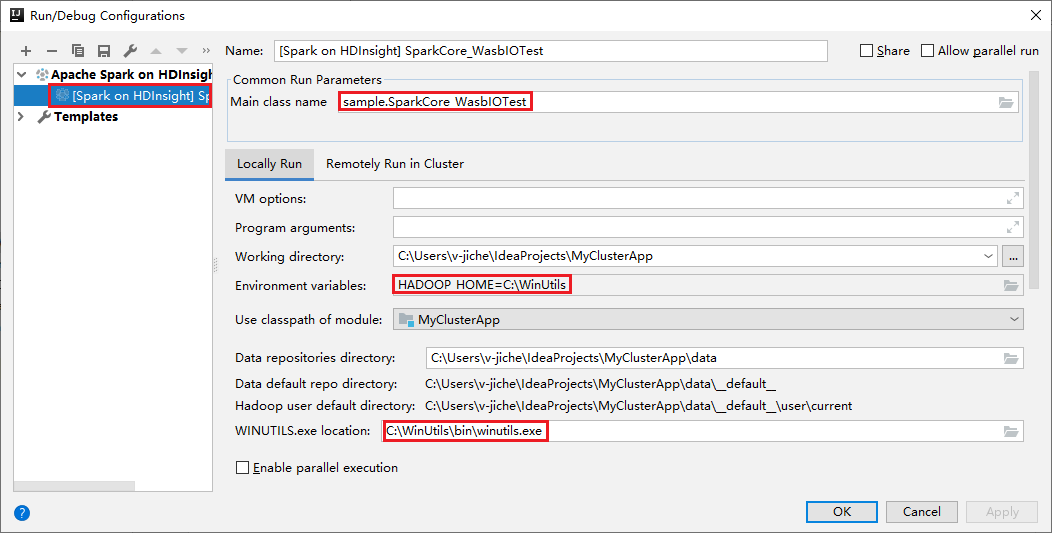
- Environment variables (Variabili di ambiente): se la variabile di ambiente di sistema HADOOP_HOME è già stata impostata su C:\WinUtils, viene automaticamente rilevato che l'aggiunta manuale non è necessaria.
- WinUtils.exe Location (Posizione WinUtils.exe): se la variabile di ambiente di sistema non è stata impostata, per trovare la posizione è sufficiente fare clic sul relativo pulsante.
- È sufficiente scegliere una delle due opzioni e non sono necessarie in macOS e Linux.
È anche possibile impostare la configurazione manualmente prima di eseguire l'esecuzione e il debug in modalità locale. Nello screenshot precedente selezionare il segno più (+). Selezionare quindi l'opzione Apache Spark in HDInsight . Immettere le informazioni per il nome e il nome della classe principale da salvare e quindi fare clic sul pulsante Esecuzione in locale.
Eseguire il debug in locale
Aprire lo script SparkCore_wasbloTest e impostare i punti di interruzione.
Fare clic con il pulsante destro del mouse sull'editor di script e quindi selezionare l'opzione Debug '[Spark in HDInsight]XXX' per eseguire il debug locale.
Esecuzione remota
Passare a Esegui>configurazioni di modifica.... Da questo menu è possibile creare o modificare le configurazioni per il debug remoto.
Nella finestra di dialogo Run/Debug Configurations (Esegui/Debug delle configurazioni) selezionare il segno più (+). Selezionare quindi l'opzione Apache Spark in HDInsight .
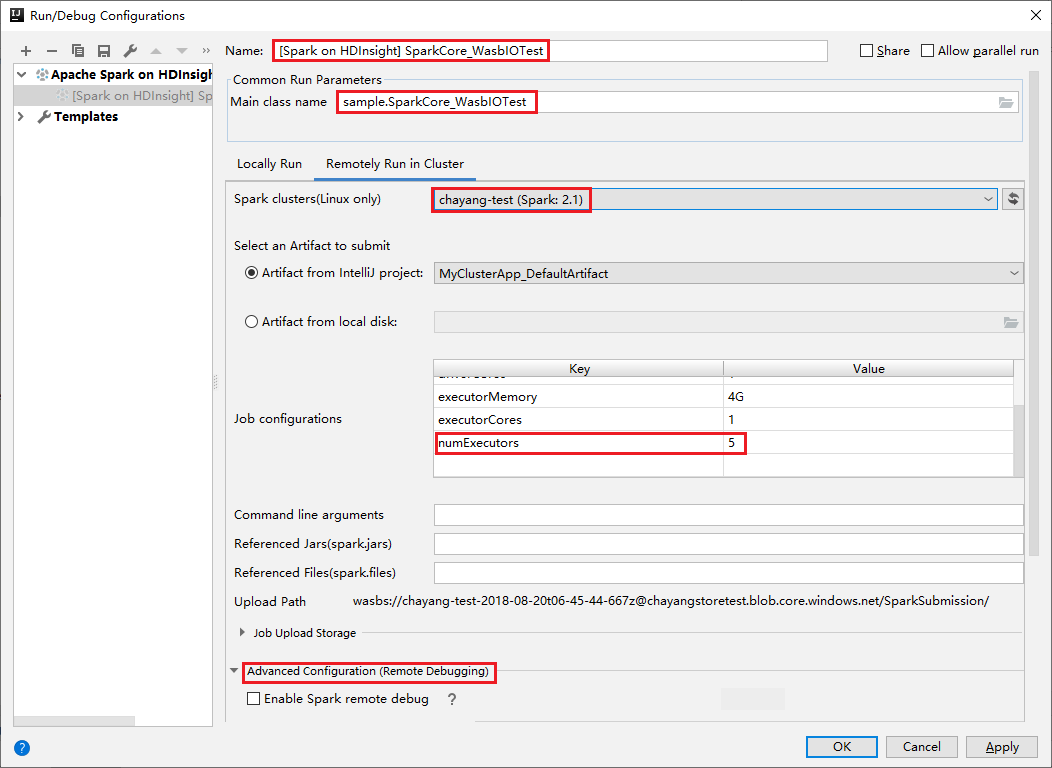
Passare alla scheda Esecuzione remota nel cluster . Immettere le informazioni per Nome, Cluster Spark e Nome classe principale. Fare quindi clic su Configurazione avanzata (debug remoto). Questi strumenti supportano il debug con executor. numExecutors, il valore predefinito è 5. È consigliabile non impostarlo su un valore maggiore di 3.
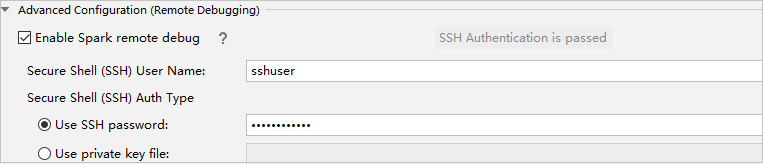
Nella parte Configurazione avanzata (debug remoto) selezionare Abilita debug remoto Spark. Immettere il nome utente SSH e inserire una password oppure usare un file di chiave privata. Se si desidera eseguire il debug in modalità remota, è necessario impostare questa opzione. Non è necessario impostarla se si desidera usare l'esecuzione in modalità remota.
A questo punto, la configurazione viene salvata con il nome specificato. Per visualizzare i dettagli della configurazione, selezionare il relativo nome. Per apportare modifiche, selezionare Modifica configurazioni.
Dopo aver completato le impostazioni di configurazione, è possibile eseguire il progetto con il cluster remoto oppure eseguire il debug remoto.

Fare clic sul pulsante Disconnetti. I log di invio non vengono visualizzati nel riquadro sinistro, ma l'esecuzione è ancora in corso nel back-end.
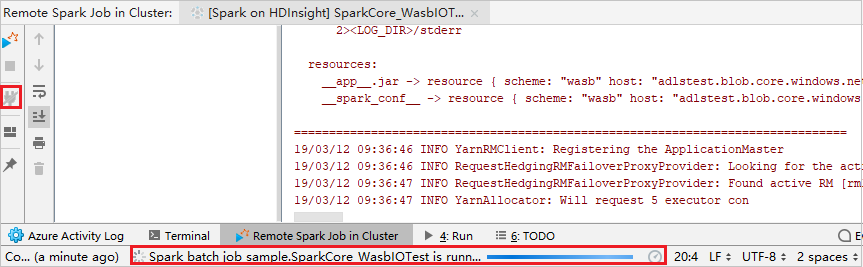
Eseguire l'esecuzione da remoto
Impostare i punti di interruzione e quindi fare clic sull'icona Remote debug (Debug remoto). La differenza rispetto all'invio remoto risiede nel fatto che non è necessario configurare il nome utente/password SSH.

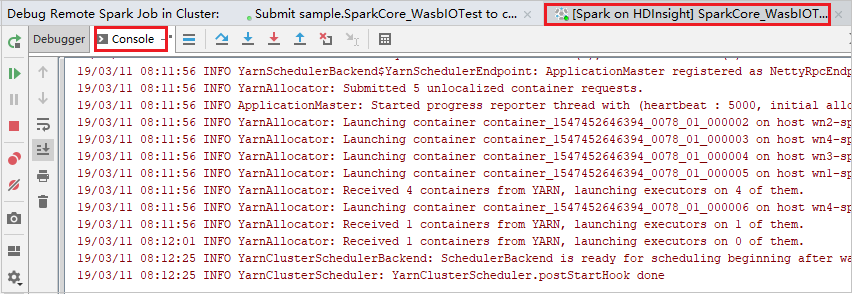
Quando l'esecuzione del programma raggiunge il punto di interruzione, nel riquadro Debugger vengono visualizzate la scheda Diver e le due schede Executor. Selezionare l'icona Resume Program (Riprendi programma) per continuare l'esecuzione del codice, che raggiungerà il punto di interruzione successivo. È necessario passare alla scheda Executor (Esecutore) corretta per trovare l'esecutore di destinazione da sottoporre a debug. È possibile visualizzare i log di esecuzione nella scheda Console corrispondente.
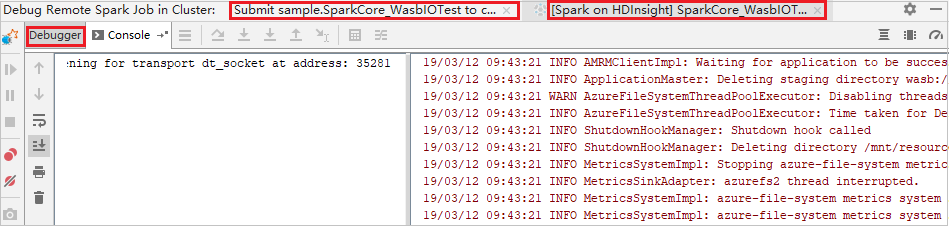
Eseguire il debug e la correzione di bug da remoto
Impostare due punti di interruzione e quindi selezionare l'icona Debug per avviare il processo di debug remoto.
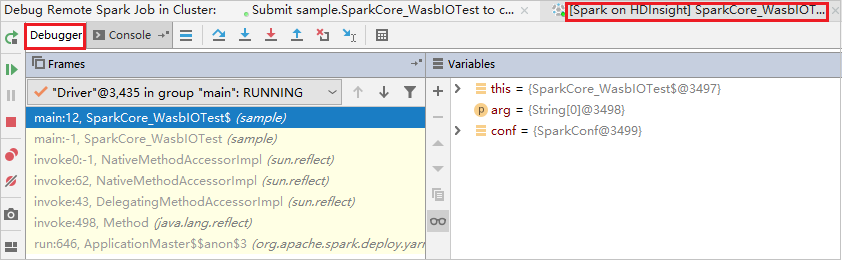
Il codice si interrompe in corrispondenza del primo punto di interruzione e le informazioni di parametro e variabile vengono visualizzate nella finestra Variables (Variabili).
Selezionare l'icona Resume Program (Riprendi programma) per continuare. Il codice si interrompe in corrispondenza del secondo punto. L'eccezione viene rilevata come previsto.
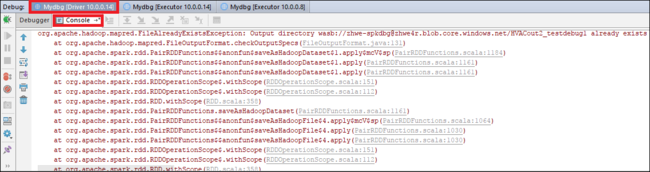
Selezionare di nuovo l'icona Resume Program (Riprendi programma). La finestra HDInsight Spark Submission (Invio Spark in HDInsight) mostra un errore di "esecuzione processo non riuscita".
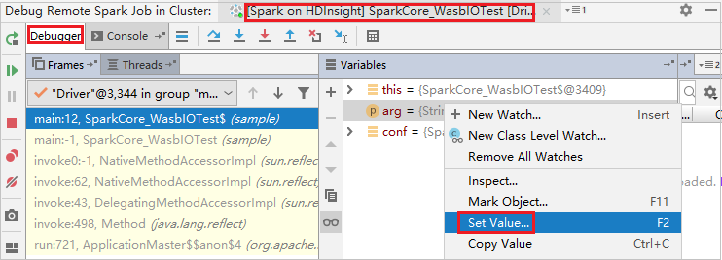
Per aggiornare dinamicamente il valore della variabile usando la funzionalità di debug di IntelliJ, selezionare nuovamente Debug. Viene visualizzato di nuovo il riquadro Variables (Variabili).
Fare clic con il pulsante destro del mouse sulla destinazione nella scheda Debug, quindi selezionare Imposta valore. Successivamente inserire un nuovo valore per la variabile. e selezionare Invia per salvarlo.
Selezionare l'icona Resume Program (Riprendi programma) per continuare a eseguire il programma. Questa volta, non viene rilevata alcuna eccezione. È possibile notare come il progetto venga eseguito correttamente senza eccezioni.
Passaggi successivi
Scenari
- Apache Spark con Business Intelligence: eseguire l'analisi interattiva dei dati con strumenti di Business Intelligence mediante Spark in HDInsight
- Apache Spark con Machine Learning: usare Spark in HDInsight per l'analisi della temperatura di compilazione usando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
Creare ed eseguire applicazioni
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
Strumenti ed estensioni
- Usare Azure Toolkit for IntelliJ per creare applicazioni Apache Spark per un cluster HDInsight
- Usare Azure Toolkit for IntelliJ per il debug remoto di applicazioni Apache Spark tramite VPN
- Usare gli strumenti HDInsight in Azure Toolkit for Eclipse per creare applicazioni Apache Spark
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Usare pacchetti esterni con Jupyter Notebook
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark