Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa esercitazione si apprenderà come creare un frame di dati da un file CSV e come eseguire query interattive Spark SQL in un cluster Apache Spark in Azure HDInsight. In Spark un frame di dati è una raccolta distribuita di dati organizzati in colonne denominate. Dal punto di vista concettuale in frame di dati equivale a una tabella in un database relazionale o a un frame di dati in R/Python.
In questa esercitazione apprenderai a:
- Creare un frame di dati da un file csv
- Eseguire query sul frame di dati
Prerequisiti
Un cluster Apache Spark in HDInsight. Vedere Creare un cluster Apache Spark.
Creare un notebook di Jupyter Notebook
Jupyter Notebook è un ambiente notebook interattivo che supporta diversi linguaggi di programmazione. Il notebook consente di interagire con i dati, combinare codice e testo Markdown ed eseguire visualizzazioni semplici.
Modificare l'URL
https://SPARKCLUSTER.azurehdinsight.net/jupytersostituendoSPARKCLUSTERcon lo stesso nome del cluster Spark. Immettere quindi l'URL modificato in un Web browser. Se richiesto, immettere le credenziali di accesso del cluster.Nella pagina Web di Jupyter Per i cluster di Spark 2.4, selezionare Nuovo>PySpark per creare un notebook. Per la versione di Spark 3.1, selezionare Nuovo>PySpark3 invece di creare un notebook perché il kernel PySpark non è più disponibile in Spark 3.1.
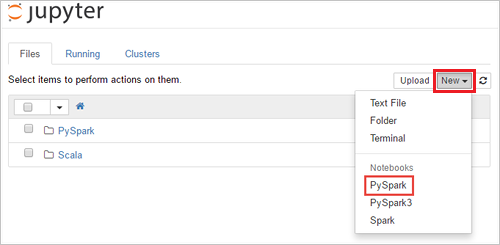
Un nuovo notebook verrà creato e aperto con il nome Untitled(
Untitled.ipynb).Nota
Usando il kernel PySpark o PySpark3 per creare un notebook, la sessione
sparkviene creata automaticamente quando si esegue la prima cella di codice. Non è necessario creare in modo esplicito la sessione.
Creare un frame di dati da un file csv
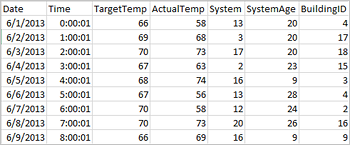
Le applicazioni possono creare frame di dati direttamente da file o cartelle nell'archiviazione remota, ad esempio Archiviazione di Azure o Azure Data Lake Storage, da una tabella Hive o da altre origini dati supportate da Spark, come Azure Cosmos DB, data warehouse, database SQL di Azure e così via. Lo screenshot seguente mostra uno snapshot del file HVAC.csv usato in questa esercitazione. Il file csv è disponibile con tutti i cluster HDInsight Spark. I dati acquisiscono le variazioni di temperatura di alcuni edifici.
Incollare il codice seguente in una cella vuota di Jupyter Notebook e quindi premere MAIUSC+INVIO per eseguire il codice. Il codice importa i tipi necessari per questo scenario:
from pyspark.sql import * from pyspark.sql.types import *Quando si esegue una query interattiva in Jupyter, la barra del titolo della scheda o della finestra del Web browser visualizza lo stato (Occupato) accanto al titolo del notebook. È anche visibile un cerchio pieno accanto al testo PySpark nell'angolo in alto a destra. Al termine del processo viene visualizzato un cerchio vuoto.
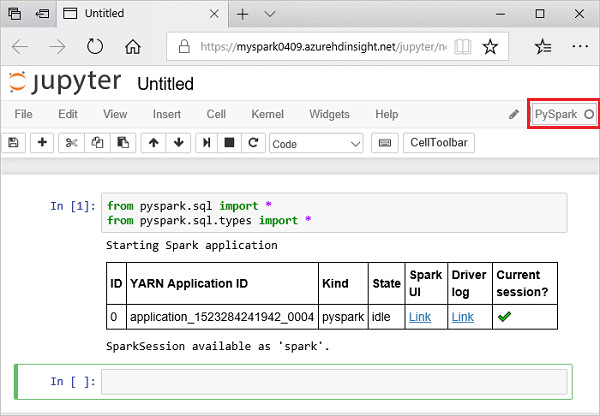
Prendere nota dell'ID di sessione restituito. Nell'immagine precedente l'ID sessione è 0. Se si vuole, è possibile recuperare i dettagli della sessione passando a
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsdove CLUSTERNAME è il nome del cluster Spark e ID è il numero dell'ID sessione.Eseguire il codice seguente per creare un frame di dati e una tabella temporanea (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Eseguire query su datanami
Dopo aver creato la tabella, è possibile eseguire una query interattiva sui dati.
Eseguire il codice seguente in una cella vuota del notebook:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Viene visualizzato l'output tabulare seguente.
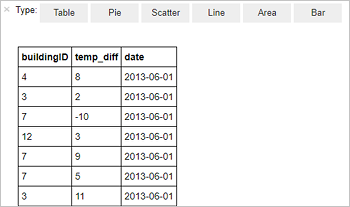
È anche possibile visualizzare i risultati in altri formati. Per visualizzare un grafico ad area per lo stesso output, selezionare Area e quindi impostare altri valori, come illustrato.
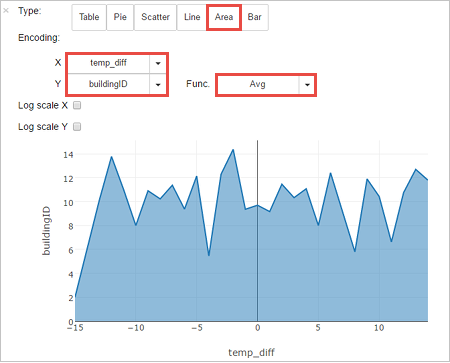
Dalla barra dei menu del notebook, passare a File>Save and Checkpoint (Salva e checkpoint).
Se si intende iniziare l'esercitazione successiva a questo punto, lasciare aperto il notebook. In caso contrario, arrestare il notebook per rilasciare le risorse cluster: dalla barra dei menu del notebook, passare a File>Close and Halt (Chiudi e interrompi).
Pulire le risorse
Con HDInsight i dati e Jupyter Notebook vengono salvati in Archiviazione di Azure o Azure Data Lake Storage, in modo che sia possibile eliminare un cluster in modo sicuro quando non viene usato. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente. Se si prevede di lavorare immediatamente nell'esercitazione successiva, si potrebbe voler mantenere il cluster.
Aprire il cluster nel portale di Azure e selezionare Elimina.
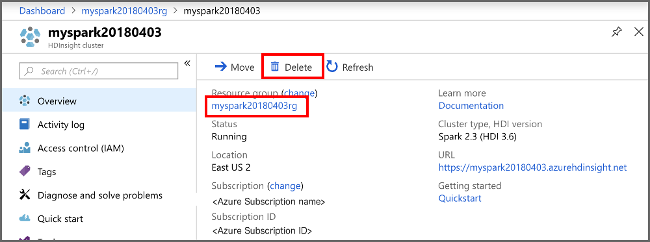
È anche possibile selezionare il nome del gruppo di risorse per aprire la pagina del gruppo di risorse e quindi selezionare Elimina gruppo di risorse. Eliminando il gruppo di risorse, si elimina sia il cluster HDInsight Spark che l'account di archiviazione predefinito.
Passaggi successivi
In questa esercitazione si è appreso come creare un frame di dati da un file CSV e come eseguire query interattive Spark SQL in un cluster Apache Spark in Azure HDInsight. Passare all'articolo successivo per scoprire come eseguire il pull dei dati registrati in Apache Spark in uno strumento di analisi BI come Power BI.