Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si usa il portale di Azure per creare un cluster Apache Spark in Azure HDInsight. Si crea quindi un notebook di Jupyter e lo si usa per eseguire query Spark SQL sulle tabelle Apache Hive. Azure HDInsight è un servizio di analisi open source gestito e a spettro completo per le aziende. Il framework Apache Spark per HDInsight consente di velocizzare cluster computing e analisi dei dati grazie all'elaborazione in memoria. Jupyter Notebook consente di interagire con i dati, combinare il codice con il testo markdown ed eseguire visualizzazioni semplici.
Per una spiegazione approfondita delle configurazioni disponibili, vedere Configurare i cluster in HDInsight. Per altre informazioni sull'uso del portale per creare cluster, vedere Creare cluster nel portale.
Se si usano più cluster insieme, è possibile creare una rete virtuale; se si usa un cluster Spark può anche voler usare Hive Warehouse Connector. Per altre informazioni, vedere Pianificare una rete virtuale per Azure HDInsight e Integrare Apache Spark e Apache Hive con Hive Warehouse Connector.
Importante
La fatturazione per i cluster HDInsight viene ripartita al minuto, indipendentemente dal fatto che vengano usati o meno. Assicurarsi di eliminare il cluster al termine dell'uso. Per altre informazioni, vedere la sezione Pulire le risorse di questo articolo.
Prerequisiti
Un account Azure con una sottoscrizione attiva. Creare un account gratuito.
Creare un cluster Apache Spark in HDInsight
Usare il portale di Azure per creare un cluster HDInsight che usa BLOB del servizio di archiviazione di Azure come risorsa di archiviazione del cluster. Per altre informazioni sull'uso di Data Lake Storage Gen2, vedere Avvio rapido: Configurare cluster in HDInsight.
Accedi al portale di Azure.
Nel menu in alto selezionare + Crea una risorsa.
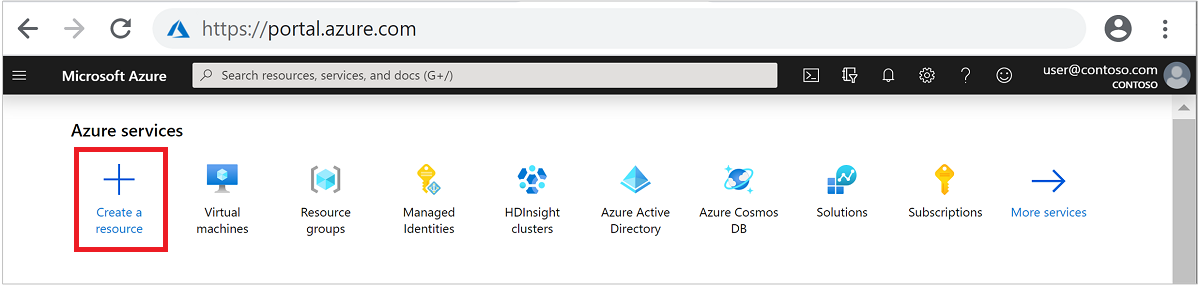
Selezionare Analytics>Azure HDInsight per passare alla pagina Crea cluster HDInsight.
Nella scheda Informazioni di base specificare le informazioni seguenti:
Proprietà Description Subscription Nell'elenco a discesa selezionare la sottoscrizione di Azure usata per il cluster. Gruppo di risorse Nell'elenco a discesa selezionare il gruppo di risorse esistente oppure selezionare Crea nuovo. Nome del cluster Immettere un nome univoco globale. Area geografica Nell'elenco a discesa selezionare un'area in cui viene creato il cluster. Zona di disponibilità Facoltativo: specificare una zona di disponibilità in cui distribuire il cluster Tipo di cluster Selezionare il tipo di cluster per aprire un elenco. Nell'elenco selezionare Spark. Versione del cluster Questo campo viene popolato automaticamente con la versione predefinita dopo che è stato selezionato il tipo di cluster. Nome utente di accesso al cluster Immettere il nome utente dell'account di accesso del cluster. Il nome predefinito è admin. Questo account viene usato per accedere a Jupyter Notebook più avanti nella guida introduttiva. Password di accesso del cluster Immettere la password di accesso al cluster. Nome utente Secure Shell (SSH) Immettere il nome utente SSH. Il nome utente SSH usato per questa guida introduttiva è sshuser. Per impostazione predefinita, questo account condivide la stessa password dell'account di accesso del cluster . 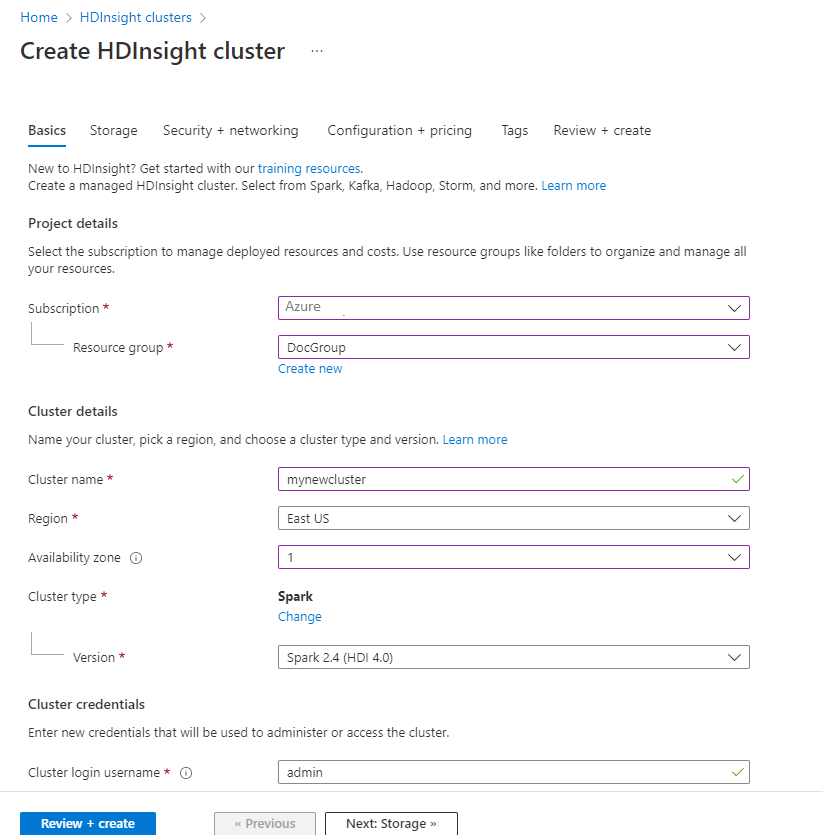
Selezionare Avanti: Archiviazione >> per passare alla pagina Archiviazione .
In Archiviazione specificare i valori seguenti:
Proprietà Description Tipo di archiviazione primario Usare il valore predefinito Archiviazione di Azure. Metodo di selezione Usare il valore predefinito Seleziona dall'elenco. Account di archiviazione primario Usare il valore inserito automaticamente. Contenitore Usare il valore inserito automaticamente. 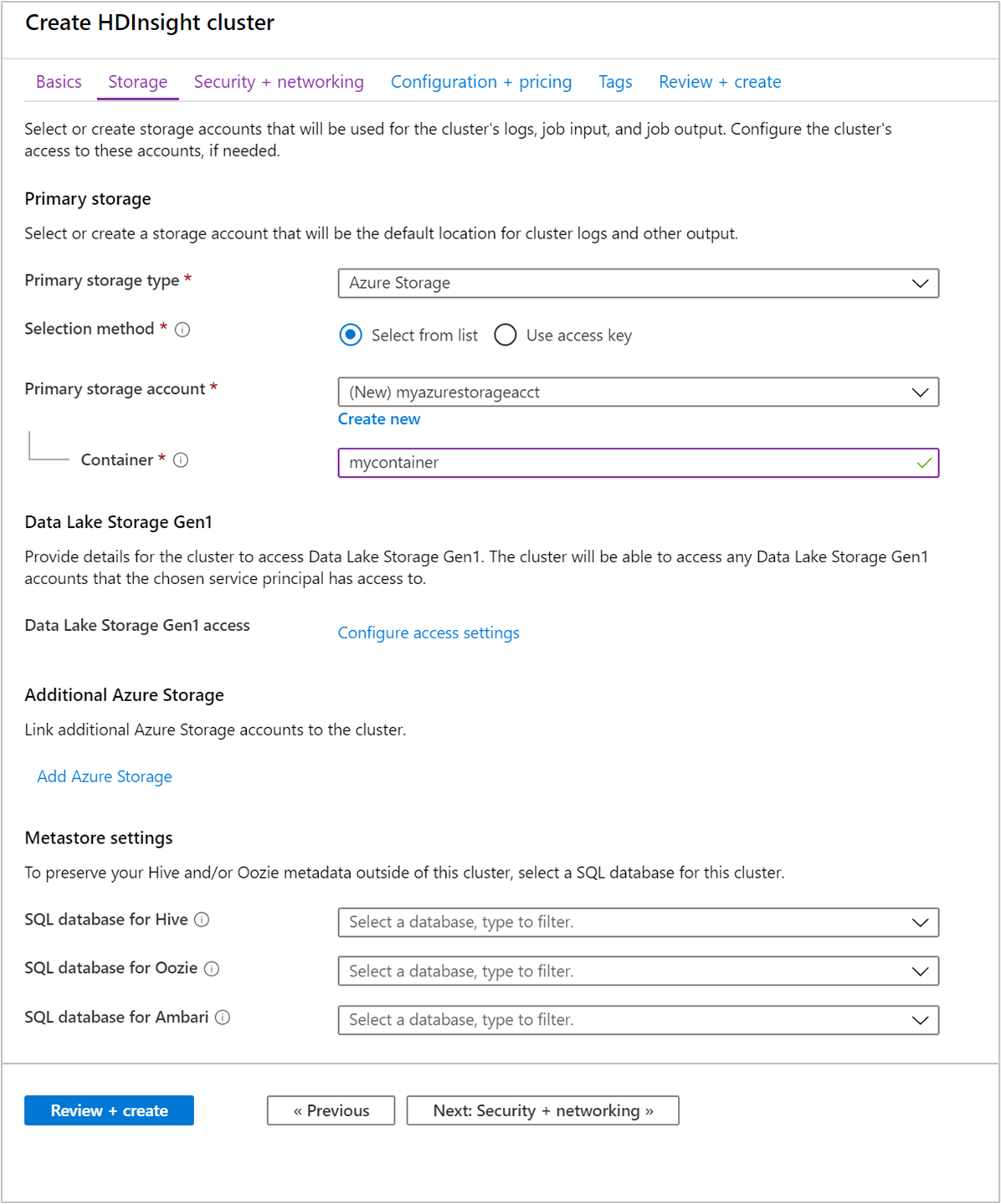
Selezionare Rivedi e crea per continuare.
In Rivedi e crea selezionare Crea. La creazione del cluster richiede circa 20 minuti. Prima di procedere con la sessione successiva, è necessario creare il cluster.
Se si verifica un problema con la creazione di cluster HDInsight, è possibile che non si disponga delle autorizzazioni appropriate per farlo. Per altre informazioni, vedere Requisiti di controllo di accesso.
Creare un notebook di Jupyter
Jupyter Notebook è un ambiente notebook interattivo che supporta vari linguaggi di programmazione. Il notebook consente di interagire con i dati, combinare il codice con il testo markdown ed eseguire visualizzazioni semplici.
Da un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyter, doveCLUSTERNAMEè il nome del cluster. Se richiesto, immettere le credenziali di accesso del cluster per il cluster.Selezionare Nuovo>PySpark per creare un notebook.
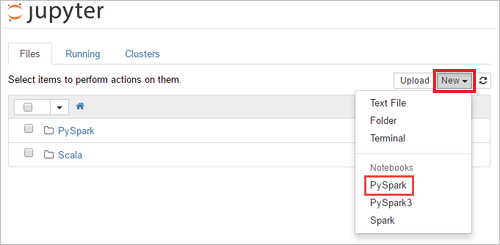
Viene creato e aperto un nuovo notebook con il nome Untitled(Untitled.pynb).
Eseguire istruzioni SQL di Apache Spark
SQL (Structured Query Language) è il linguaggio più comune e ampiamente usato per l'esecuzione di query e la definizione dei dati. Spark SQL funziona come estensione di Apache Spark per l'elaborazione di dati strutturati, usando la sintassi SQL familiare.
Verificare che il kernel sia pronto. Il kernel è pronto quando viene visualizzato un cerchio vuoto accanto al nome del kernel nel notebook. Il cerchio pieno indica che il kernel è occupato.

Quando si avvia il notebook per la prima volta, il kernel esegue alcune attività in background. Attendere che il kernel sia pronto.
Incollare il codice seguente in una cella vuota e quindi premere MAIUSC + INVIO per eseguire il codice. Il comando elenca le tabelle Hive nel cluster:
%%sql SHOW TABLESQuando si usa jupyter Notebook con il cluster HDInsight, si ottiene un set di impostazioni
sqlContextche è possibile usare per eseguire query Hive usando Spark SQL.%%sqlindica a Jupyter Notebook di usare il set di impostazionisqlContextper eseguire la query Hive. La query recupera le prime 10 righe da una tabella Hive (hivesampletable) fornita con tutti i cluster HDInsight per impostazione predefinita. Per ottenere i risultati sono necessari circa 30 secondi. L'output è simile al seguente: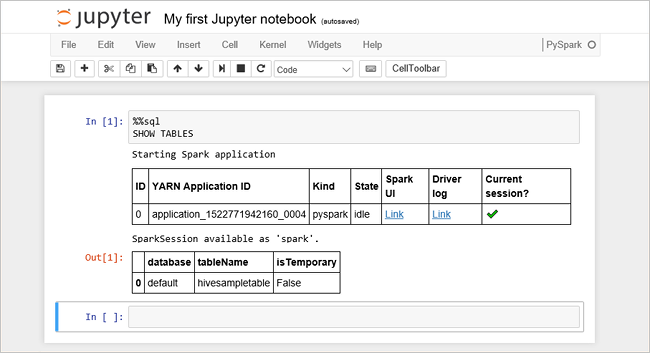 is quickstart." border="true":::
is quickstart." border="true":::Ogni volta che si esegue una query in Jupyter, il titolo della finestra del Web browser mostra uno stato (Occupato) insieme al titolo del notebook. È anche visibile un cerchio pieno accanto al testo PySpark nell'angolo in alto a destra.
Eseguire un'altra query per visualizzare i dati in
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10La schermata verrà aggiornata per visualizzare l'output della query.
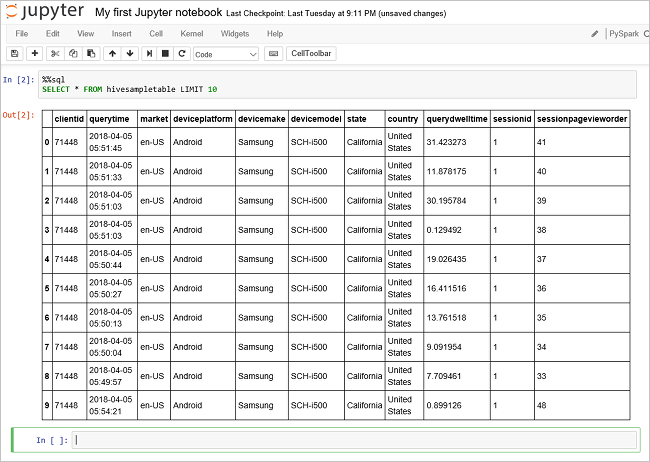 Insight" border="true":::
Insight" border="true":::Dal menu File del notebook selezionare Chiudi e arresta. Spegnere il notebook rilascia le risorse del cluster.
Pulire le risorse
HDInsight salva i dati in Archiviazione di Azure o In Azure Data Lake Storage, in modo da poter eliminare in modo sicuro un cluster quando non è in uso. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente. Se si prevede di svolgere subito l'esercitazione elencata nei passaggi successivi, si può mantenere il cluster.
Tornare al portale di Azure e selezionare Elimina.
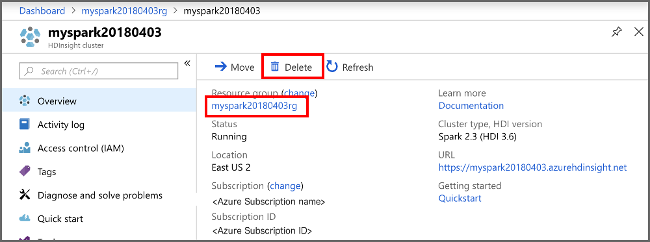 sight cluster" border="true":::
sight cluster" border="true":::
È anche possibile selezionare il nome del gruppo di risorse per aprire la pagina del gruppo di risorse e quindi selezionare Elimina gruppo di risorse. Eliminando il gruppo di risorse, si eliminano sia il cluster HDInsight che l'account di archiviazione predefinito.
Passaggi successivi
In questa guida introduttiva si è appreso come creare un cluster Apache Spark in HDInsight ed eseguire una query Spark SQL di base. Passare all'esercitazione successiva per imparare come usare un cluster HDInsight per eseguire query interattive su dati di esempio.