Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come usare Apache Spark MLlib per creare un'applicazione di Machine Learning. L'applicazione esegue l'analisi predittiva su un set di dati aperto. Dalle librerie di Machine Learning integrate di Spark, questo esempio usa la classificazione tramite la regressione logistica.
MLlib è una libreria Spark di base che offre molte utilità utili per le attività di Machine Learning, ad esempio:
- Classificazione
- Regressione
- Cluster
- Modellazione
- Scomposizione di valori singolari e analisi in componenti principali
- Testing e calcolo ipotetici di statistiche di esempio
Informazioni sulla classificazione e la regressione logistica
La classificazione, un'attività comune di apprendimento automatico, è il processo di ordinamento dei dati in categorie. È il processo di un algoritmo di classificazione per capire come assegnare "etichette" ai dati di input forniti. Ad esempio, si potrebbe pensare a un algoritmo di Machine Learning che accetta le informazioni sulle scorte come input. Quindi divide il titolo in due categorie: azioni che dovresti vendere e azioni che dovresti mantenere.
La regressione logistica è l'algoritmo usato per la classificazione. L'API di regressione logistica di Spark è utile per la classificazione binaria, ovvero la classificazione di dati di input in uno di due gruppi. Per altre informazioni sulle regressioni logistiche, vedere Wikipedia.
In sintesi, il processo di regressione logistica produce una funzione logistica. Usare la funzione per stimare la probabilità che un vettore di input appartenga a un gruppo o all'altro.
Esempio di analisi predittiva dei dati di ispezione alimentare
In questo esempio si usa Spark per eseguire un'analisi predittiva sui dati di ispezione alimentare (Food_Inspections1.csv). Dati acquisiti tramite il portale dati City of Chicago. Questo set di dati contiene informazioni sulle ispezioni degli stabilimenti alimentari condotte a Chicago. Incluse le informazioni su ogni stabilimento, le violazioni rilevate (se presenti) e i risultati dell'ispezione. Il file di dati in formato CSV è già disponibile nell'account di archiviazione associato al cluster in /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
Nei passaggi seguenti si sviluppa un modello per vedere cosa serve per passare o non eseguire un'ispezione degli alimenti.
Creare una pipeline di apprendimento automatico MLlib Apache Spark
Creare un Jupyter Notebook usando il kernel PySpark. Per istruzioni, vedere Creare un file di Jupyter Notebook.
Importare i tipi richiesti per l'applicazione. Copiare e incollare il codice seguente in una cella vuota, quindi premere MAIUSC + INVIO.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Dato che è stato usato il kernel PySpark, non è necessario creare contesti in modo esplicito. I contesti Spark e Hive vengono creati automaticamente quando si esegue la prima cella di codice.
Creare il frame di dati di input
Usare il contesto spark per eseguire il pull dei dati CSV non elaborati in memoria come testo non strutturato. Usare quindi la libreria CSV di Python per analizzare ogni riga dei dati.
Eseguire le righe seguenti per creare un set di dati RDD (Resilient Distributed Dataset) tramite importazione e analisi dei dati di input.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Eseguire il codice seguente per recuperare una riga da RDD, in modo da poter esaminare lo schema dei dati:
inspections.take(1)L'output è il seguente:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]L'output dà un'idea dello schema del file di input. Include il nome di ogni istituzione e il tipo di stabilimento. Inoltre, l'indirizzo, i dati delle ispezioni e la posizione, tra le altre cose.
Eseguire il codice seguente per creare un frame di dati (df) e una tabella temporanea (CountResults) con alcune colonne che sono utili per l'analisi predittiva.
sqlContextviene usato per eseguire trasformazioni su dati strutturati.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Le quattro colonne di interesse per il dataframe sono ID, nome, risultati e violazioni.
Eseguire il codice seguente per ottenere un piccolo campione dei dati:
df.show(5)L'output è il seguente:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Informazioni sui dati
Ora si determinerà il contenuto del set di dati.
Eseguire il codice seguente per visualizzare i valori distinti nella colonna results:
df.select('results').distinct().show()L'output è il seguente:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Eseguire il codice seguente per visualizzare la distribuzione di questi risultati:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsIl comando speciale
%%sqlseguito da-o countResultsdfassicura che l'output della query venga mantenuto in locale nel server Jupyter, di solito il nodo head del cluster. L'output viene conservato come frame di dati Pandas con il nome specificato countResultsdf. Per altre informazioni sulla%%sqlmagia e altri magic disponibili con il kernel PySpark, vedere Kernel disponibili nei notebook di Jupyter con cluster HdInsight Apache Spark.L'output è il seguente:
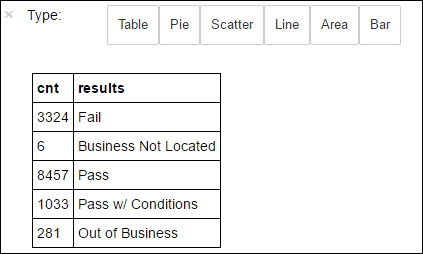
È anche possibile creare un tracciato tramite Matplotlib, una libreria che consente di creare visualizzazioni di dati. Poiché il tracciato deve essere creato dal frame di dati countResultsdf conservato in locale, il frammento di codice deve iniziare con
%%local. Questa azione garantisce che il codice venga eseguito localmente nel server Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Per stimare il risultato di un controllo di prodotti alimentari, è necessario sviluppare un modello basato sulle violazioni. Dato che la regressione logistica è un metodo di classificazione binaria, è consigliabile raggruppare i dati dei risultati in due categorie: Fail e Pass:
Riuscito
- Riuscito
- Pass w/ conditions
Errore
- Errore
Discard
- Business not located
- Out of Business
I dati con gli altri risultati ("Business Not Located" o "Out of Business") non sono utili e costituiscono comunque una piccola percentuale dei risultati.
Eseguire il codice seguente per convertire il frame di dati esistente (
df) in un nuovo frame di dati in cui ogni controllo è rappresentato come coppia etichetta-violazioni. In questo caso, un'etichetta di0.0rappresenta un errore, un'etichetta di1.0rappresenta un esito positivo e un'etichetta di-1.0rappresenta alcuni risultati oltre a questi due risultati.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Eseguire il codice seguente per visualizzare una riga dei dati con etichetta:
labeledData.take(1)L'output è il seguente:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Creare un modello di regressione logistica dal frame di dati di input
L'attività finale consiste nel convertire i dati etichettati. Convertire i dati in un formato analizzato dalla regressione logistica. L'input di un algoritmo di regressione logistica richiede un set di coppie di vettori di caratteristiche etichetta. Dove il "vettore di funzionalità" è un vettore di numeri che rappresentano il punto di input. È quindi necessario convertire la colonna "violazioni", che è semistrutturata e contiene molti commenti in testo libero. Convertire la colonna in una matrice di numeri reali che un computer potrebbe comprendere facilmente.
Un approccio di Machine Learning standard per l'elaborazione del linguaggio naturale consiste nell'assegnare a ogni parola distinta un indice. Passare quindi un vettore all'algoritmo di Machine Learning. In modo che il valore di ogni indice contenga la frequenza relativa di tale parola nella stringa di testo.
MLlib offre un modo semplice per eseguire questa operazione. In primo luogo, suddividere in token ogni stringa di violazione per ottenere le parole singole in ogni stringa. Quindi, usare un HashingTF per convertire ogni set di token in un vettore di funzione da passare successivamente all'algoritmo di regressione logistica per creare un modello. Si eseguono tutti questi passaggi in sequenza usando una pipeline.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Valutare il modello usando un altro set di dati
È possibile usare il modello creato in precedenza per stimare i risultati delle nuove ispezioni. Le stime sono basate sulle violazioni osservate. Il training di questo modello è stato eseguito sul set di dati Food_Inspections1.csv. È possibile usare un secondo set di dati, Food_Inspections2.csv, per valutare l'efficacia di questo modello sui nuovi dati. Questo secondo set di dati (Food_Inspections2.csv) si trova nel contenitore di archiviazione predefinito associato al cluster.
Eseguire il codice seguente per creare un nuovo frame di dati, predictionsDf contenente la stima generata dal modello. Il frammento di codice crea anche la tabella temporanea Predictions basata sul dataframe.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsVerrà visualizzato un output simile al testo seguente:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Esaminare una delle stime. Eseguire questo frammento di codice:
predictionsDf.take(1)Esiste una stima per la prima voce nel set di dati di test.
Il metodo
model.transform()applicherà la stessa trasformazione ai nuovi dati con lo stesso schema e formulerà una stima per la classificazione dei dati. È possibile eseguire alcune statistiche per ottenere un'idea del modo in cui le stime erano:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")L'output ha un aspetto simile al testo seguente:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateL'uso della regressione logistica con Spark offre un modello della relazione tra le descrizioni delle violazioni in inglese. E se un determinato business avrebbe superato o fallito un'ispezione alimentare.
Creare una rappresentazione visiva della stima
È ora possibile creare una visualizzazione finale per comprendere meglio i risultati di questo test.
Iniziare dall'estrazione delle diverse stime e dei vari risultati dalla tabella temporanea Predictions creata in precedenza. Le query seguenti separano l'output in true_positive, false_positive, true_negative e false_negative. Nelle query seguenti disattivare la visualizzazione usando
-qe, tramite-o, salvare l'output come frame di dati utilizzabili con il comando speciale%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Usare infine il frammento di codice seguente per generare il tracciato con Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Verrà visualizzato l'output seguente:

In questo grafico un risultato positivo indica il controllo degli alimenti non superato, mentre un risultato negativo indica un controllo superato.
Arrestare il notebook
Dopo aver eseguito l'applicazione, è necessario arrestare il notebook per rilasciare le risorse. Per fare ciò, dal menu File del notebook fare clic su Close and Halt (Chiudi e interrompi). Questa azione spegne e chiude il notebook.