Valutare gli errori nei modelli di Machine Learning
Una delle principali sfide con le attuali procedure di debug del modello consiste nell'usare metriche di aggregazione per assegnare punteggi ai modelli in un set di dati di benchmark. L'accuratezza del modello potrebbe non essere uniforme tra sottogruppi di dati e potrebbe verificarsi una coorte di input per cui il modello ha esito negativo più spesso. Le conseguenze dirette di questi errori sono la mancanza di affidabilità e sicurezza, la presenza di problemi di equità e una perdita di fiducia nell'apprendimento automatico in generale.

L'analisi degli errori si allontana dalle metriche di accuratezza aggregate. Espone la distribuzione degli errori agli sviluppatori in modo trasparente e consente loro di identificare e diagnosticare gli errori in modo efficiente.
Il componente di analisi degli errori del dashboard di intelligenza artificiale responsabile offre ai professionisti di apprendimento automatico una conoscenza più approfondita della distribuzione degli errori del modello e consente loro di identificare rapidamente coorti errate dei dati. Questo componente identifica le coorti di dati con una frequenza di errore più elevata rispetto alla frequenza di errore complessiva del benchmark. Contribuisce alla fase di identificazione del flusso di lavoro del ciclo di vita del modello tramite:
- Un albero delle decisioni che rivela coorti con tassi di errore elevati.
- Una mappa termica che mostra il modo in cui le funzionalità di input influiscono sulla frequenza degli errori tra coorti.
Le discrepanze negli errori possono verificarsi quando il sistema è sottoperformante per gruppi demografici specifici o coorti di input raramente osservate nei dati di training.
Le funzionalità di questo componente provengono dal pacchetto di analisi degli errori, che genera profili di errore del modello.
Usare l'analisi degli errori quando è necessario:
- Acquisire una conoscenza approfondita circa il modo in cui gli errori del modello vengono distribuiti in un set di dati e in diverse dimensioni di input e funzionalità.
- Suddividere le metriche delle prestazioni aggregate per individuare automaticamente coorti errate per informare i passaggi di mitigazione mirati.
Albero degli errori
Spesso, i modelli di errore sono complessi e coinvolgono più di una o due funzionalità. Gli sviluppatori potrebbero avere difficoltà a esplorare tutte le possibili combinazioni di funzionalità per individuare porzioni di dati nascosti con errori critici.
Per ridurre il carico di lavoro, la visualizzazione ad albero binario esegue automaticamente la partizione i dati di benchmark in sottogruppi interpretabili con percentuali di errore inaspettatamente elevate o basse. In altre parole, l'albero usa le funzionalità di input per separare al massimo l'errore del modello dall'esito positivo. Per ogni nodo che definisce un sottogruppo di dati, gli utenti possono analizzare le informazioni seguenti:
- Frequenza di errore: una porzione delle istanze nel nodo per cui il modello non è corretto. Viene mostrato con il colore rosso a intensità variabile.
- Copertura degli errori: una porzione di tutti gli errori che rientrano nel nodo. Viene visualizzato tramite la frequenza di riempimento del nodo.
- Rappresentazione dei dati: il numero di istanze in ogni nodo dell'albero degli errori. Viene visualizzato attraverso lo spessore del bordo in ingresso al nodo, insieme al numero totale di istanze nel nodo.

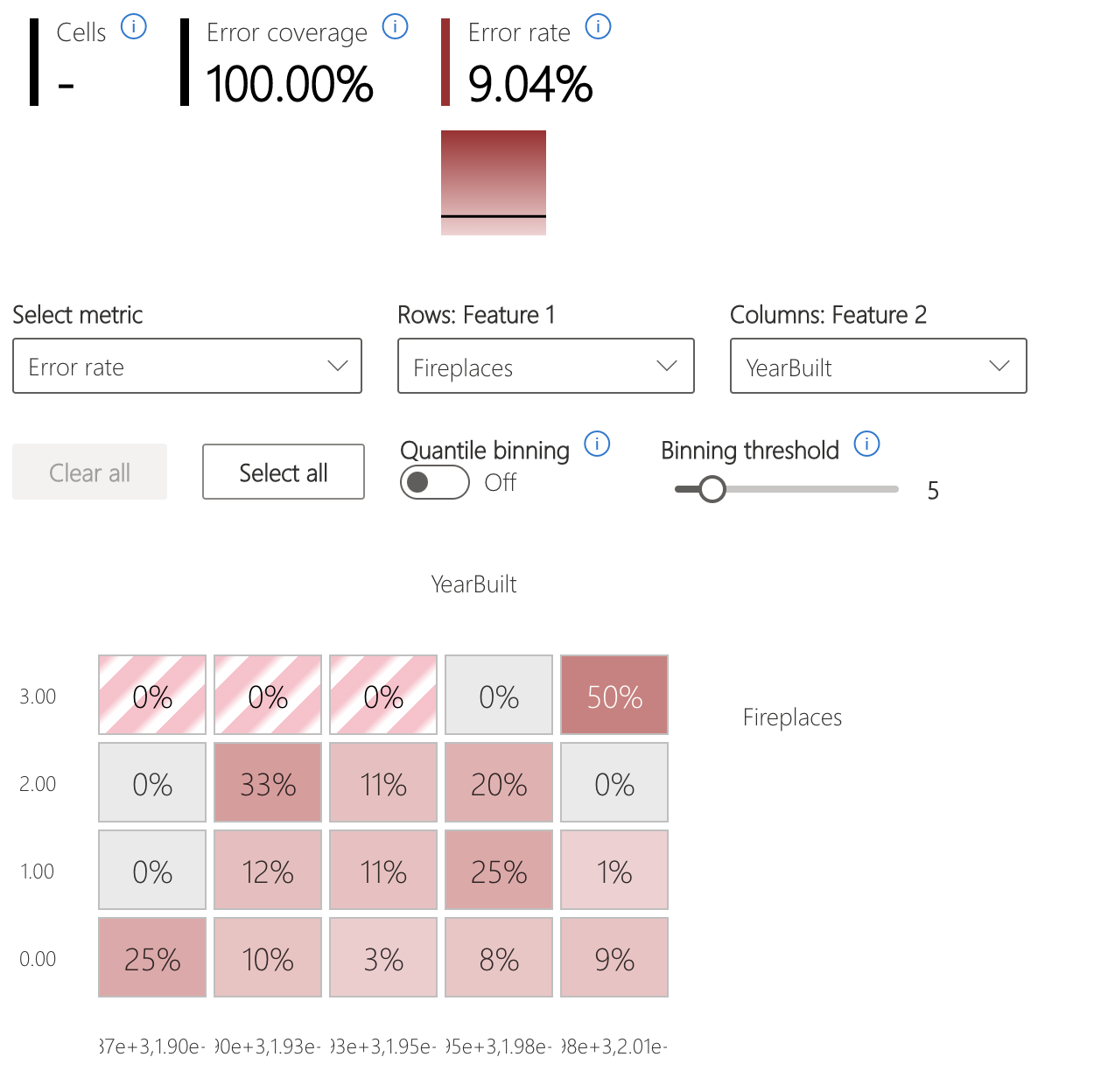
Mappa termica degli errori
La vista consente di filtrare i dati in base a una griglia unidimensionale o bidimensionale delle funzionalità di input. Gli utenti possono scegliere le funzionalità di input di interesse per l'analisi.
La mappa termica visualizza le celle con un errore elevato usando un colore rosso più intenso per rivolgere l'attenzione dell'utente a tali aree. Questa funzionalità è particolarmente utile quando i temi di errore sono diversi tra le partizioni, che si verificano spesso a livello pratico. In questa visualizzazione di identificazione degli errori, l'analisi è altamente guidata dagli utenti e dalle proprie conoscenze o ipotesi su quali funzionalità potrebbero essere più importanti per la comprensione degli errori.
Passaggi successivi
- Informazioni su come generare il dashboard di intelligenza artificiale responsabile tramite l'interfaccia della riga di comando e l'SDK o l'interfaccia utente dello studio di Azure Machine Learning.
- Esplorare le visualizzazioni di analisi degli errori supportate.
- Informazioni su come generare un punteggio di intelligenza artificiale responsabile in base alle informazioni dettagliate osservate nel dashboard di intelligenza artificiale responsabile.