Accedere ai dati dall'archiviazione nel cloud di Azure durante lo sviluppo interattivo
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Un progetto di apprendimento automatico in genere inizia con l'analisi esplorativa dei dati, la pre-elaborazione dei dati (pulizia, ingegneria delle funzionalità) e lo sviluppo di prototipi di modelli di ML per convalidare le ipotesi. Questa fase di creazione di prototipi del progetto è altamente interattiva e si presta allo sviluppo in un notebook Jupyter o in un IDE con una console interattiva Python. Questo articolo descrive come:
- Accedere ai dati da un URI degli archivi dati di Azure Machine Learning come se fosse un file system.
- Materializzare i dati in Pandas usando la libreria Python
mltable. - Materializzare gli asset di dati di Azure Machine Learning in Pandas usando la libreria Python
mltable. - Materializzare i dati tramite un download esplicito con l'utilità
azcopy.
Prerequisiti
- Un'area di lavoro di Azure Machine Learning. Per altre informazioni, vedere Gestire le aree di lavoro di Azure Machine Learning nel portale o con Python SDK (v2).
- Un archivio dati di Azure Machine Learning. Per altre informazioni, vedere Creare archivi dati.
Suggerimento
Le indicazioni contenute in questo articolo descrivono l'accesso ai dati durante lo sviluppo interattivo. Si applicano a qualsiasi host in grado di eseguire una sessione Python. Possono essere inclusi il computer locale, una VM nel cloud una codespace GitHub e così via. È consigliabile usare un'istanza di ambiente di calcolo di Azure Machine Learning, ovvero una workstation nel cloud completamente gestita e preconfigurata. Per altre informazioni, vedere Creare un'istanza di ambiente di calcolo di Azure Machine Learning.
Importante
Assicurarsi di avere installato le librerie Python azure-fsspec e mltable più recenti nell'ambiente Python:
pip install -U azureml-fsspec mltable
Accedere ai dati da un URI dell'archivio dati, ad esempio un file system
Un archivio dati di Azure Machine Learning funge da riferimento per un account di archiviazione di Azure esistente. I vantaggi della creazione e dell'uso di un archivio dati includono:
- Un'API comune e facile da usare che interagisce con diversi tipi di archiviazione (BLOB/file/ADLS).
- Individuazione semplice di archivi dati utili nelle operazioni del team.
- Supporto dell'accesso ai dati basato su credenziali (ad esempio, token di firma di accesso condiviso) e basato su identità (uso di Microsoft Entra ID o di un'identità gestita).
- Per l'accesso basato su credenziali, le informazioni di connessione sono protette per evitare l'esposizione delle chiavi negli script.
- Esplorare i dati e copiare/incollare gli URI degli archivi dati nell'interfaccia utente dello studio.
Un URI (Uniform Resource Identifier) di archivio dati è un riferimento a una posizione (percorso) di archiviazione nell'account di archiviazione di Azure. Un URI di archivio dati ha questo formato:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Questi URI di archivio dati sono un'implementazione nota della specifica del file system (fsspec): un'interfaccia unificata di Python per file sistemi locali, remoti e incorporati e per l'archiviazione di byte.
Installare con pip il pacchetto azureml-fsspec e il pacchetto azureml-dataprep delle relative dipendenze. È quindi possibile usare l'implementazione fsspec dell'archivio dati di Azure Machine Learning.
L'implementazione fsspec dell'archivio dati di Azure Machine Learning gestisce automaticamente il pass-through di credenziali/identità usate dall'archivio dati di Azure Machine Learning. È possibile evitare sia l'esposizione di chiavi dell'account negli script che le procedure di accesso aggiuntive in un'istanza di ambiente di calcolo.
Ad esempio, è possibile usare direttamente gli URI degli archivi dati in Pandas. Questo esempio illustra come leggere un file CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Suggerimento
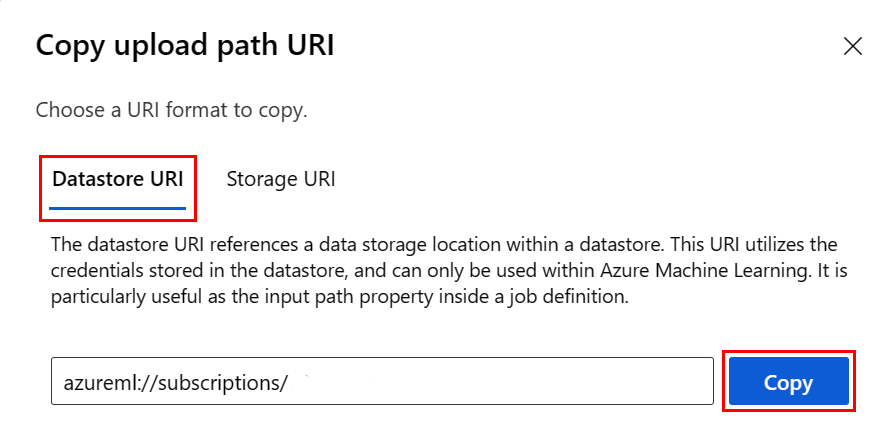
Invece di ricordare il formato dell'URI dell'archivio dati, è possibile copiare/incollare l'URI dall'interfaccia utente dello studio con questa procedura:
- Selezionare Dati nel menu a sinistra e quindi selezionare la scheda Archivi dati.
- Selezionare il nome dell'archivio dati e quindi Sfoglia.
- Trovare il file o la cartella da leggere in Pandas e selezionare i puntini di sospensione (...). Scegliere Copia URI dal menu. È possibile selezionare l'URI dell'archivio dati da copiare nel notebook o nello script.
È anche possibile creare un'istanza di un file system di Azure Machine Learning per gestire comandi di tipo file system, ad esempio ls, glob, exists, open.
- Il metodo
ls()elenca i file in una directory specifica. È possibile usare ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) per elencare i file. Sono supportati sia '.' che '.', nei percorsi relativi. - Il metodo
glob()supporta il i caratteri jolly '*' e '**'. - Il metodo
exists()restituisce un valore booleano che indica se un file specificato esiste o meno nella directory radice corrente. - Il metodo
open()restituisce un oggetto simile a un file, che può essere passato a qualsiasi altra libreria che prevede di usare file Python. Il codice può anche usare questo oggetto come se fosse un normale oggetto file Python. Questi oggetti simili a file rispettano l'uso dei contesti diwith, come illustrato in questo esempio:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Caricare file tramite AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath è il percorso locale e rpath è il percorso remoto.
Se le cartelle specificate in rpath non esistono ancora, verranno create automaticamente.
Sono supportate tre modalità di sovrascrittura:
- APPEND: se nel percorso di destinazione esiste un file con lo stesso nome, viene mantenuto il file originale
- FAIL_ON_FILE_CONFLICT: se nel percorso di destinazione esiste un file con lo stesso nome, viene generato un errore
- MERGE_WITH_OVERWRITE: se nel percorso di destinazione esiste un file con lo stesso nome, il file esistente viene sovrascritto con il nuovo file
Scaricare file tramite AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Esempi
Questi esempi illustrano l'uso della specifica del file system in scenari comuni.
Leggere un singolo file CSV in Pandas
È possibile leggere un singolo file CSV in Pandas, come illustrato di seguito:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Leggere una cartella di file CSV in Pandas
Il metodo read_csv() di Pandas non supporta la lettura di una cartella di file CSV. È necessario concatenare i percorsi dei file CSV in un dataframe con il metodo concat() di Pandas. L'esempio di codice seguente illustra come ottenere questa concatenazione con il file system di Azure Machine Learning:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Lettura di file CSV in Dask
Questo esempio illustra come leggere un file CSV in un dataframe Dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Leggere una cartella di file Parquet in Pandas
Nell'ambito di un processo ETL, i file Parquet vengono in genere scritti in una cartella, che può quindi generare file pertinenti l'ETL, ad esempio lo stato di avanzamento, i commit e così via. Questo esempio mostra i file creati da un processo ETL (file che iniziano con _) che generano quindi un file Parquet di dati.
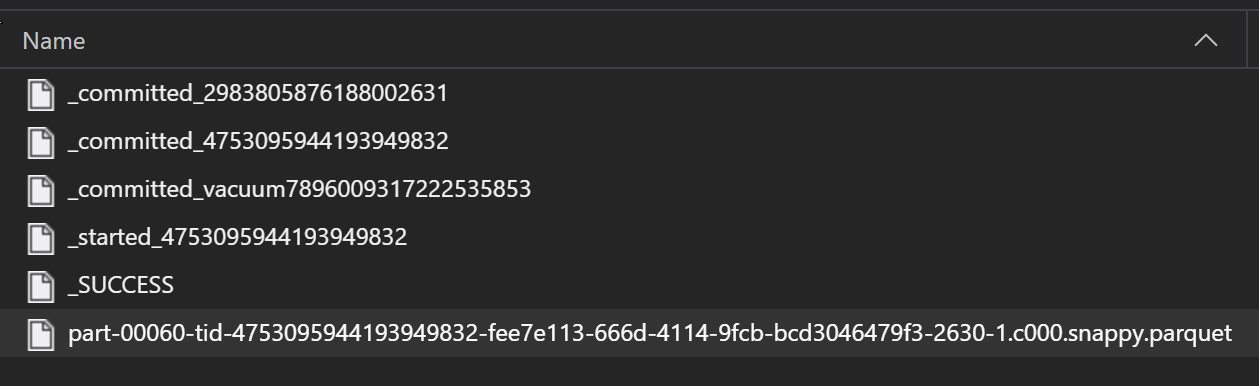
In questi scenari si leggeranno solo i file Parquet nella cartella e si ignoreranno i file del processo ETL. Questo esempio di codice dimostra che i criteri GLOB possono traferire solo file Parquet in una cartella:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Accesso ai dati dal file system di Azure Databricks (dbfs)
La specifica del file system (fsspec) include un intervallo di implementazioni note , incluso il file system di Databricks (dbfs).
Per accedere ai dati da dbfs è necessario:
- Nome istanza, sotto forma di
adb-<some-number>.<two digits>.azuredatabricks.net. È possibile trovare questo valore nell'URL dell'area di lavoro di Azure Databricks. - Token di accesso personale; per altre informazioni sulla creazione di un token di accesso personale, vedere Eseguire l'autenticazione con token di accesso personale di Azure Databricks
Con questi valori, è necessario creare una variabile di ambiente nell'istanza di ambiente di calcolo per il token di accesso personale:
export ADB_PAT=<pat_token>
È quindi possibile accedere ai dati in Pandas, come illustrato in questo esempio:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Lettura di immagini con pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Esempio di set di dati personalizzato PyTorch
In questo esempio viene creato un set di dati personalizzato PyTorch per l'elaborazione delle immagini. Si presuppone che esista un file di annotazioni (in formato CSV), con questa struttura complessiva:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Le sottocartelle archiviano queste immagini, in base alle relative etichette:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Una classe personalizzata di set di dati PyTorch deve implementare tre funzioni: __init__, __len__ e __getitem__, come illustrato di seguito:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
È quindi possibile creare un'istanza del set di dati come illustrato di seguito:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materializzare i dati in Pandas usando la libreria mltable
La libreria mltable consente anche di accedere ai dati nell'archiviazione nel cloud. La lettura di dati in Pandas con mltable ha questo formato generale:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Percorsi supportati
La libreria mltable supporta la lettura di dati tabulari da tipi di percorso diversi:
| Ufficio | Esempi |
|---|---|
| Un percorso nel computer locale | ./home/username/data/my_data |
| Un percorso in uno o più server HTTP pubblici | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Un percorso in Archiviazione di Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Un archivio dati di Azure Machine Learning | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Nota
mltable esegue il pass-through delle credenziali utente per i percorsi negli archivi dati di Archiviazione di Azure e Azure Machine Learning. Se non si dispone dell'autorizzazione per accedere ai dati nella risorsa di archiviazione sottostante, non è possibile accedervi.
File, cartelle e GLOB
mltable supporta la lettura da:
- file, ad esempio
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - cartelle, ad esempio
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - criteri GLOB, ad esempio
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - una combinazione di file, cartelle e/o criteri GLOB
La flessibilità di mltable consente la materializzazione dei dati, in un singolo dataframe, da una combinazione di risorse di archiviazione locali e nel cloud e da combinazioni di file/cartelle/GLOB. Ad esempio:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Formati di file supportati
mltable supporta i formati di file seguenti:
- Testo delimitato (ad esempio: file CSV):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Formato di righe JSON:
mltable.from_json_lines_files(paths=[path])
Esempi
Leggere un file CSV
Aggiornare i segnaposto (<>) in questo frammento di codice con i dettagli specifici:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Leggere i file Parquet in una cartella
Questo esempio mostra come mltable può usare criteri GLOB, ad esempio caratteri jolly, per assicurarsi che vengano letti solo i file Parquet.
Aggiornare i segnaposto (<>) in questo frammento di codice con i dettagli specifici:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lettura degli asset di dati
Questa sezione illustra come accedere agli asset di dati di Azure Machine Learning in Pandas.
Asset di tabella
Se in precedenza è stato creato un asset di tabella in Azure Machine Learning (mltableo TabularDataset v1), è possibile caricarlo in Pandas con questo codice:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Asset di file
Se è stato registrato un asset di file (ad esempio un file CSV), è possibile leggerlo in un dataframe Pandas con questo codice:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Asset di cartella
Se è stato registrato un asset di cartella (uri_folder o FileDataset v1), ad esempio una cartella contenente un file CSV, è possibile leggerlo in un dataframe Pandas con questo codice:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Nota sulla lettura e l'elaborazione di volumi di dati di grandi dimensioni con Pandas
Suggerimento
Pandas non è progettato per gestire set di dati di grandi dimensioni: può elaborare solo i dati che rientrano nella memoria dell'istanza di ambiente di calcolo.
Per set di dati di grandi dimensioni, è consigliabile usare Spark gestito da Azure Machine Learning. In questo caso viene fornita l'API PySpark Pandas.
È possibile eseguire rapidamente l'iterazione in un subset più piccolo di un set di dati di grandi dimensioni prima di passare a un processo asincrono remoto. mltable offre funzionalità predefinite per ottenere esempi di dati di grandi dimensioni usando il metodo take_random_sample:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
È anche possibile accettare subset di dati di grandi dimensioni con queste operazioni:
Download dei dati tramite l'utilità azcopy
Usare l'utilità azcopy per scaricare i dati nell'unità SSD locale dell'host (computer locale, macchina virtuale nel cloud, istanza di ambiente di calcolo di Azure Machine Learning) nel file system locale. L'utilità azcopy, preinstallata in un'istanza di ambiente di calcolo di Azure Machine Learning, gestirà questa operazione. Se non si usa un'istanza di ambiente di calcolo di Azure Machine Learning o una Data Science Virtual Machine (DSVM), potrebbe essere necessario installare azcopy. Per altre informazioni, vedere azcopy.
Attenzione
Non è consigliabile scaricare i dati nella posizione /home/azureuser/cloudfiles/code in un'istanza di ambiente di calcolo. Questa posizione è progettata per archiviare notebook e artefatti di codice, non dati. La lettura dei dati da questa posizione comporta un sovraccarico significativo delle prestazioni durante il training. È invece consigliabile archiviare i dati in home/azureuser, ovvero l'unità SSD locale del nodo di calcolo.
Aprire un terminale e creare una nuova directory, ad esempio:
mkdir /home/azureuser/data
Accedere ad azcopy usando:
azcopy login
Successivamente, è possibile copiare i dati usando un URI di archiviazione
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST